词法分析负责将字符流转为符号流(单词流)

注意:空格已经被删掉,因为没有具体的意义,在文末追加eof。

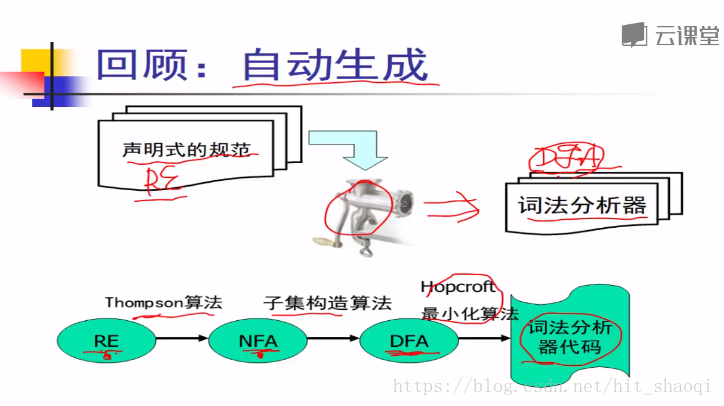
词法分析的实现方案: 1. 手工编码 GCC LLVM 2. 词法分析器的生成器 自动生成
手工构造:
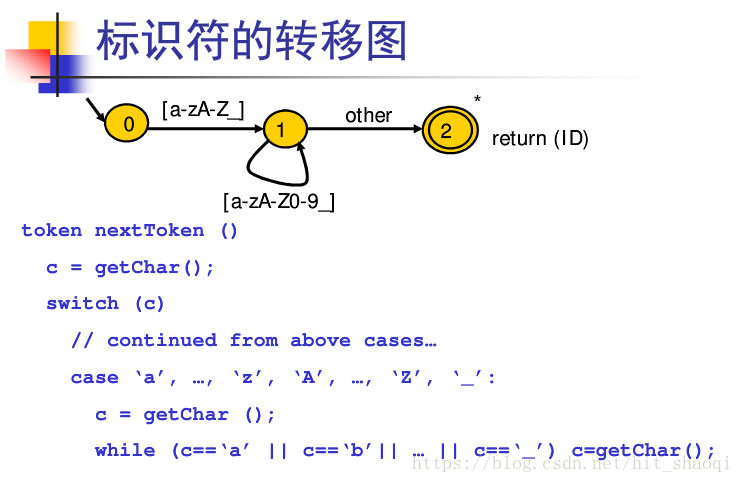
代码实现:
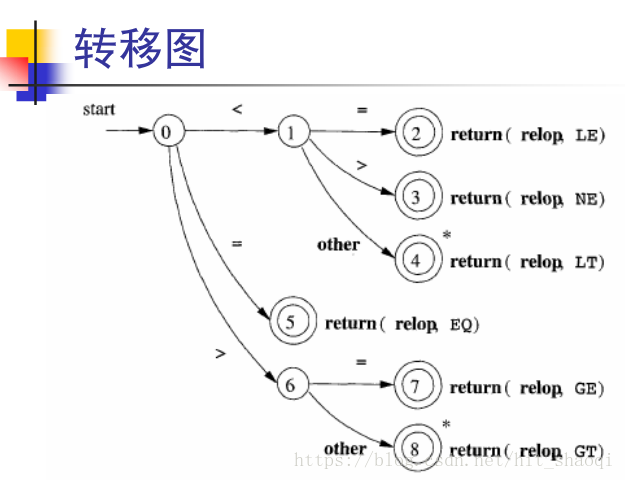
通过状态转移图进行识别,如果识别到了其他字符,如>a,识别到了a,那么需要回滚,即*处。

自动生成的方式:
输入声明式的规范,经过工具如c(lex flex),可以自动产生一个词法分析器。
1)如何获得声明式的规范? 正则表达式


如何使用正则表达式表示程序语言设计中的词法?

语法糖 syntax sugar

语法糖简化了编写。
声明式的规范即是re 正则表达式
2)如何实现该工具?
3)词法分析器
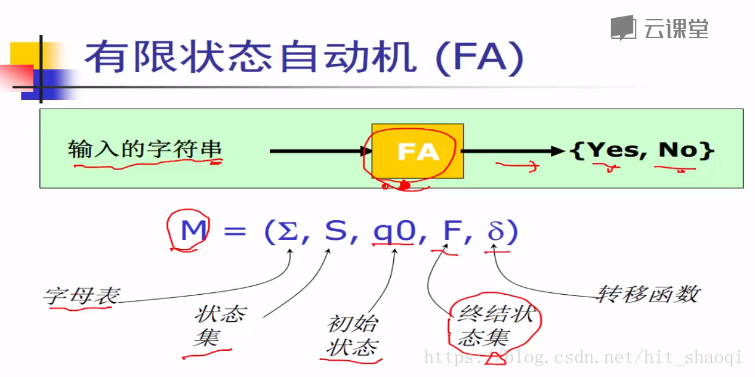
有限状态自动机

状态转移函数(q0,a)->q1,即当在q0状态遇到a时,转移到q1状态
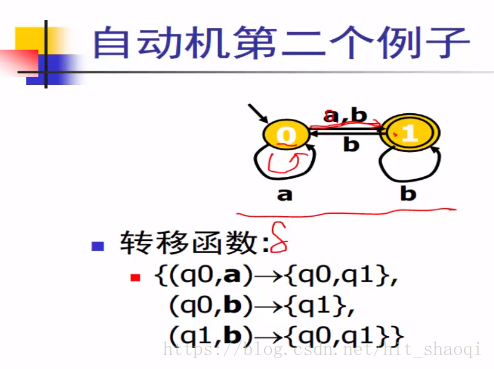
从q0经过a,可以走到q0,q1即下一状态是一个状态集合(NFA 非确定)。
如果在所有状态上对于单一字符,下一个状态是确定的,则是DFA(确定的)。

NFA对于一个字符是否能走到可接受状态并不确定,因此可能需要回溯。

注意,NFA存在空串,即表示从一个状态转移到另一个状态可以通过空串转移,即直接跳转。
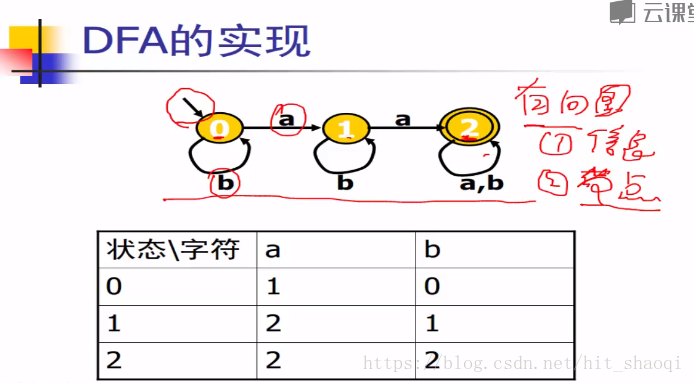
DFA的实现:有向图 1. 边上的信息 (字符)2.节点信息(如输入节点,输出节点)
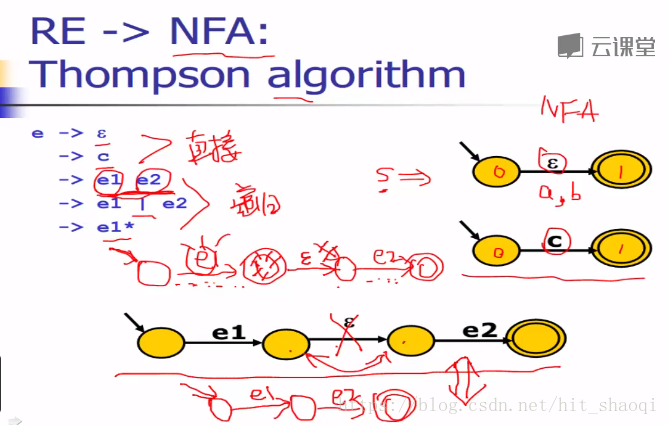
如何从RE转换到NFA?
1. Thompson 算法 RE-> NFA
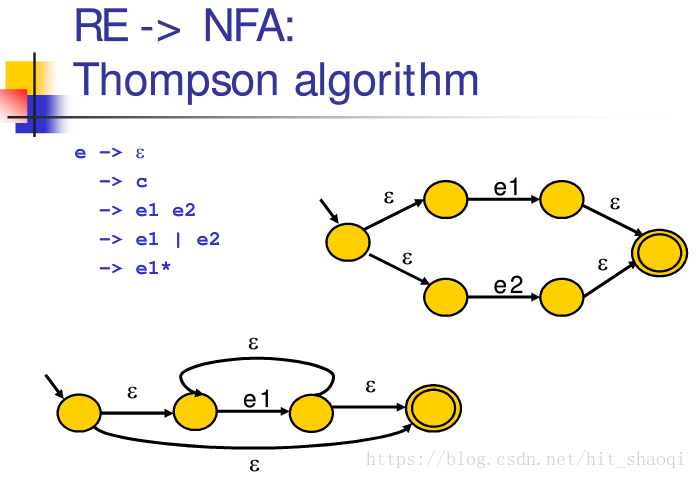
如下图所示即为该表达式对应的正则表达式

NFA->DFA
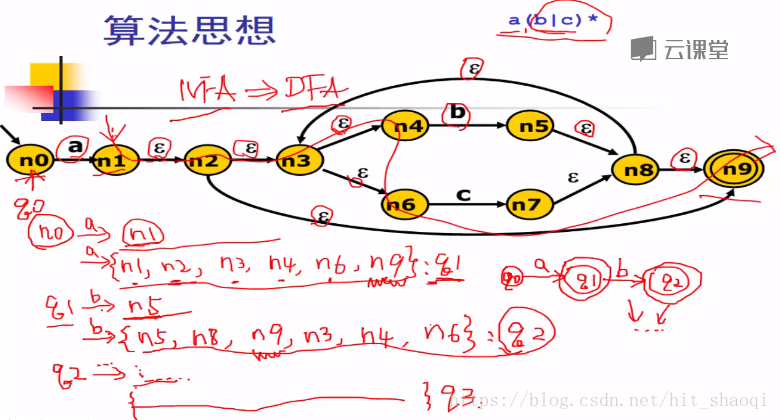
即将一个节点经过一个字符后能够达到的状态集合归纳为一个集合
需要注意的是,接受状态n9包括在了多个集合中,q1,q2都是接受状态。
1. 先对任何一个子集求转换过程,求结果
2.对结果求delta
基于深度优先去做

基于宽度优先去做

NFA转换为DFA
D[q,c]<- t 即为将子集之间字符读取,状态转换关系进行记录
worklist就是每次得到的状态的集合,实际上类似于深度优先节点中的父节点连接其子节点
q1,q2,q3中都有n9,除q0外都是接受状态。
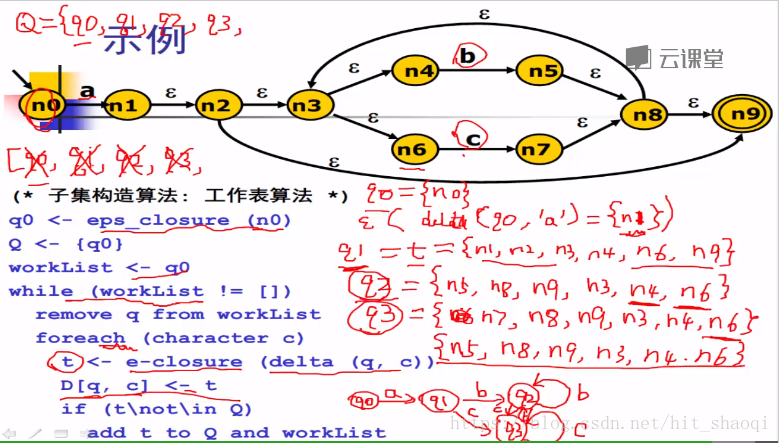
子集构造算法:
1. esp_closure 给定一个集合,确定集合中起始节点经过eps转换能够达到的状态;
2. Q DFA里面所有的有限状态自动机
3. worklist 队列
4. 进入worklist的循环
对于每一个字符,asic码c,
delta(q,c) 经过字符c可以到达的状态,改状态经过e-close,得到t
则将q经过可以到达t的关系记录到D中(DFA)

最终所有的NFA中的状态都被考虑过了。
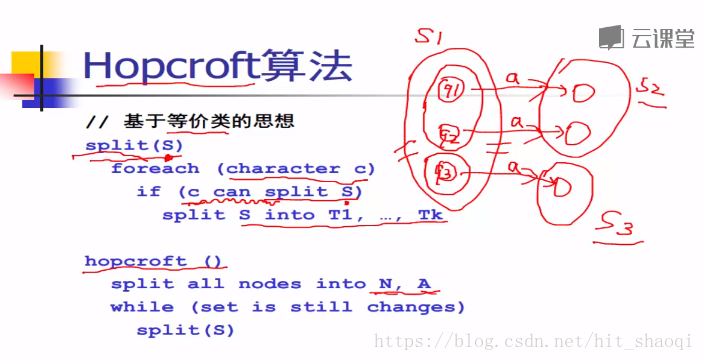
DFA的最小化:
Hopcropft对DFA进行最小化

q2,q3都包括接受状态,可以合并,q1和q4也可以合并
n非接受状态,a接受状态
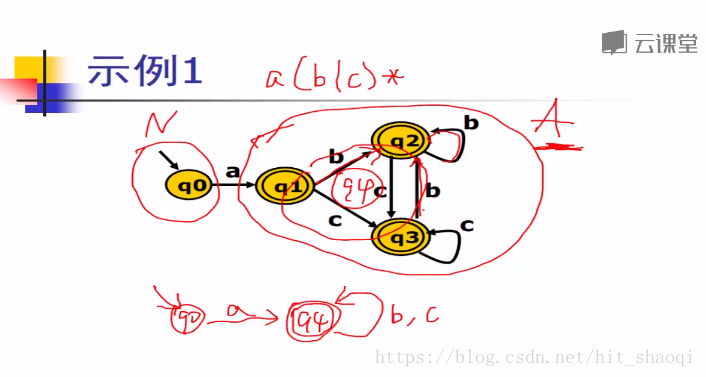
对于所有的char b c A的集合都不会被分割,因此将q1,q2,q3合并为集合A
实际上是将经过输入状态的字符后,仍然跳转到相同状态的状态合并为一个集合

DFA的代码表示:

DFA是一个有向图,图,就可以用表来表示。
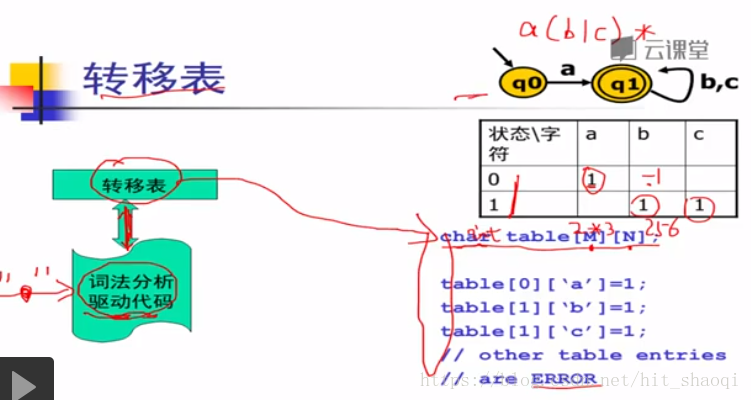
转移表 有n*m,n为状态集合个数,m为字符个数
nextToken 每次返回一个识别的字符
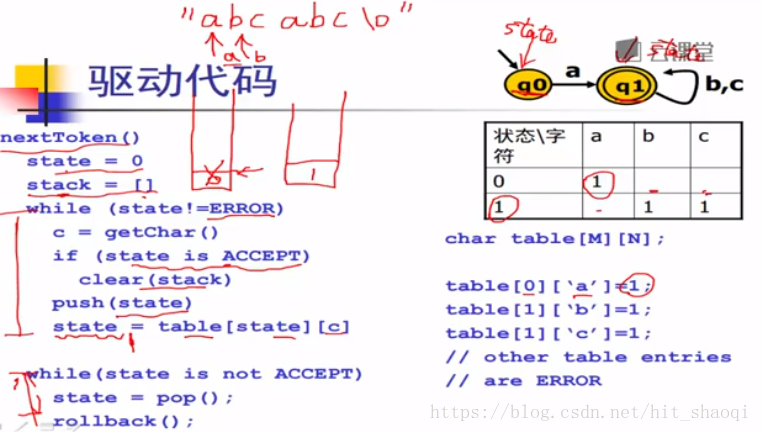
在while循环中,如果是接受状态,则清空,通过table【state】【c】进行查表
当读取到结束字符后面的字符时,将栈弹出,rollback 回退,回退回去
stack用于实现最长匹配
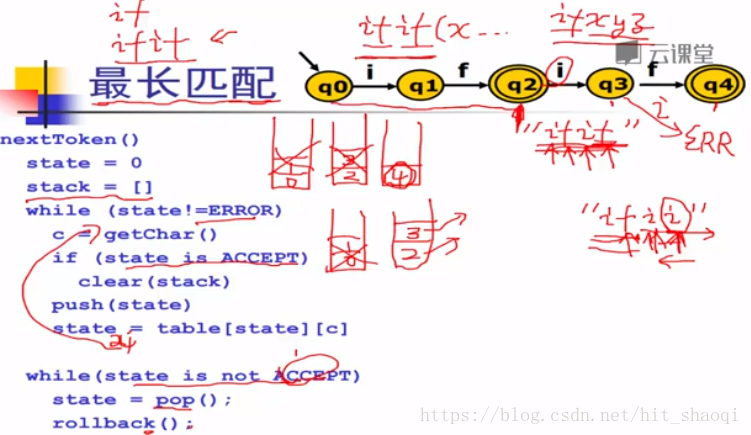
栈底每次都是接受状态,每次接收到接受状态后,清空栈,将接受状态作为栈底。
当接受失败后,回滚,直到回滚到接收到状态弹出栈,即最后一个匹配的,最长匹配。

跳转表每个状态对应一长段代码
当使用代码失陷后,跳转表比转移表局部性更好,转移表可能代码量很大(状态很多),而跳转表每次只执行一段。