根据龙书《编译原理》和 网易云课堂华保健的《编译原理》整理而成的。


下面是思维导图的笔记
- 主要工作
- 识别词素
- 过滤注释和空白
- 将编译器生成的错误消息与源程序的位置联系起来
- 技术过程
- 1. 正则表达式
- 2. NFA
- 3. DFA
- 4. 词法分析器
- 词法分析的整体流程
- 1. 源代码输入
- 预读
- 输入缓存,使用双缓冲区方案;
- 通常只需预读一个字符,而且在必要时才进行预读
- 预读
- 2. 词法分析
- 扫描阶段:不需要生成词法单元的简单处理
- 删除注释
- 处理空白
- 词法分析阶段:生成词法单元
- 扫描阶段:不需要生成词法单元的简单处理
- 1. 源代码输入
- 一些基础概念
- 词法单元:
- 由一个词法单元名和一个可选的属性值组成
- 词法单元名表示某种词法单位的抽象符号
- 模式
- 描述一个词法单元的词素可能具有的形式
- 词素
- 词素是源程序中的一个字符序列,它和某个词法单元的模式匹配,并被词法分析器识别为该词法单元的一个实例
- 词法单元:
- 词法单元的规约
- 串和语言
- 字母表 alphabet
- 是一个有限的符号集合
- 串 string
- 是该字母表中的有序序列
- 语言 language
- 是某个字母表上任意的可数的串集合
- 字母表 alphabet
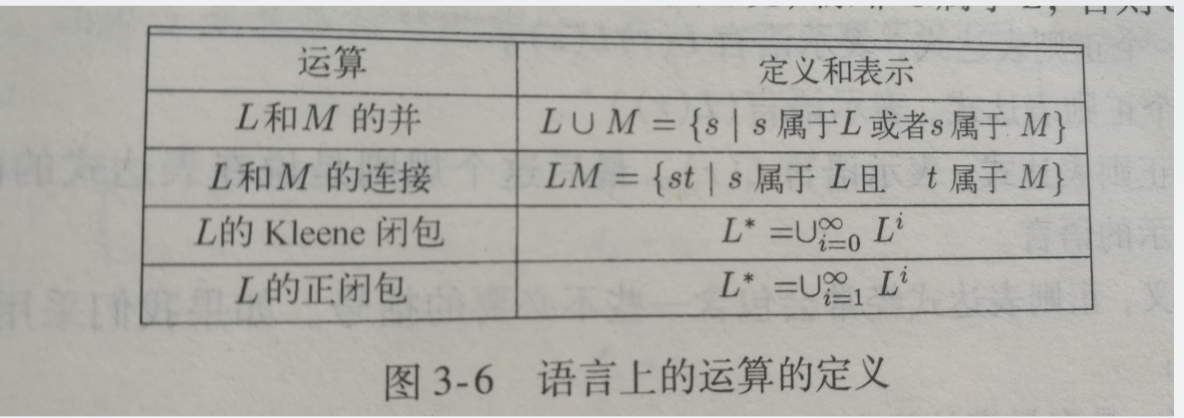
- 语言上的运算
- 基本运算
- 并、连接和闭包运算
- * 号代表 0 次或多次; + 号 代表 1 次或多次
- 定义
- 基本运算
- 正则表达式
- 定义:
- 作用:
- 描述所有通过对某个字母表上的符号应用这些运算符而得到的语言
- 正则集合
- 正则表达式定义的语言叫正则集合(regular set)
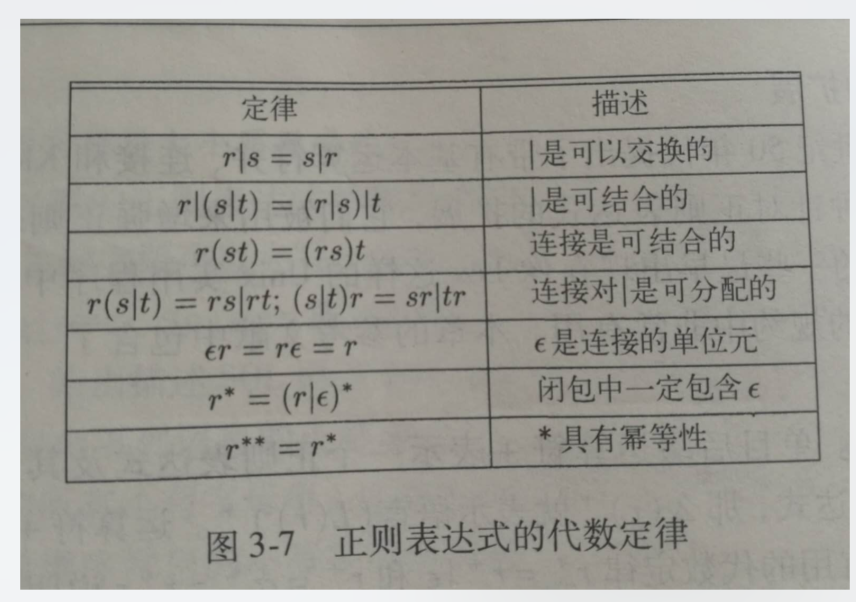
- 正则表达式的代数定律
- 串和语言
- 词法单元的识别
- 状态转换图
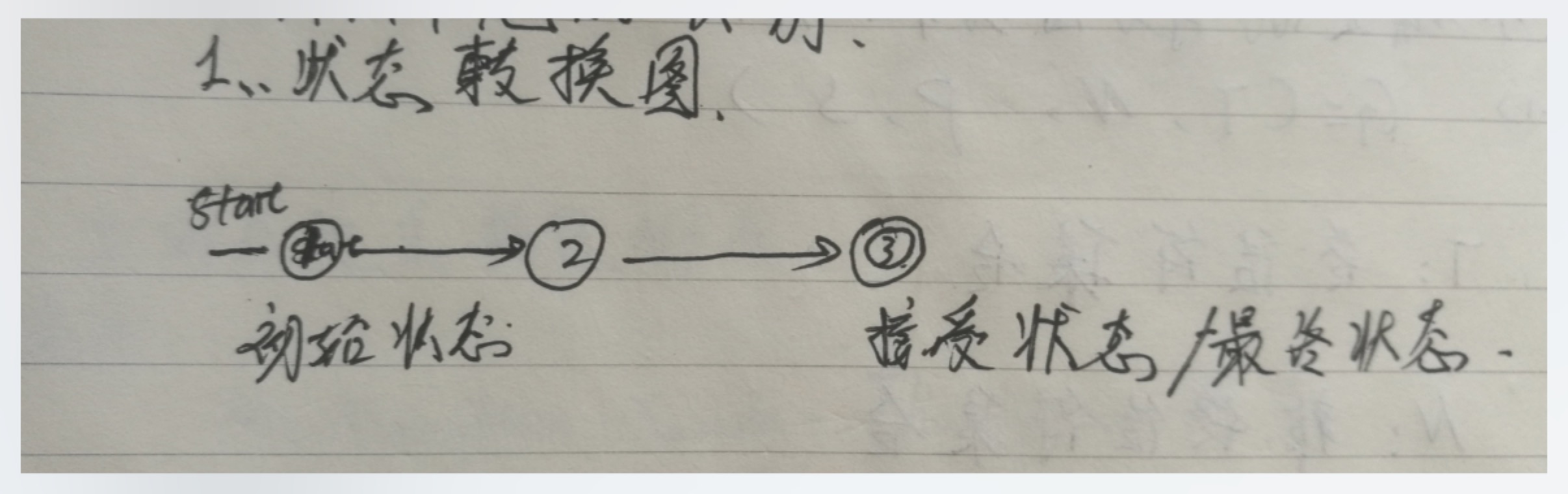
- 双圈表示接受状态
- 保留字和标识符的识别
- 方法
- 初始化时将保留字填入符号表中
- 为每个关键字建立单独的状态转换图
- 方法
- 状态转换图
- 词法单元分析器生成工具 Lex
- 核心
- 使用正则表达式来描述各个词法单元的模式,由此给出一个词法分析器的规约
- Lex 编译器将输入的模式转换成一个状态图,并生成相应的实现代码,并存放到文件 lex.yy.c 中
- Lex 中的冲突解决规则
- 总是选择最长的前缀
- 如果最长的可能前缀与多个模式匹配,总是选择在 Lex 程序中先被列出的模式
- 核心
- 有穷自动机(finite automata)
- 不确定的有穷自动机(Nondeterministic Finite Automata, NFA)
- 特点
- 多条边,包括空串 ε , 离开
- 组成

- 转换图
- 只要存在某条其标号序列为某个符合串的路径能够从开始状态到某个接受状态,NFA 接受这个符号串,存在某些到达非接受状态的路径不影响这个结论
- 特点
- 确定的有穷自动机 (Deterministic Finite Automata, DFA)
- 特点
- 只有一条边离开
- 特点
- 不确定的有穷自动机(Nondeterministic Finite Automata, NFA)
- 从正则表达式到自动机涉及的算法
- Tompson 算法
- 子集构造算法(subset construction)
- Hopcroft 最小化优化算法
