实验内容描述
根据给定的文法设计并实现词法分析程序,从源程序中识别出单词,记录其单词类别和单词值,输入输出及处理要求如下:
(1)数据结构和与语法分析程序的接口请自行定义;类别码需按下表格式统一定义;
(2)为了方便进行自动评测,输入的被编译源文件统一命名为testfile.txt;输出的结果文件统一命名为output.txt,结果文件中每行按如下方式组织:
单词类别码 单词的字符/字符串形式(中间仅用一个空格间隔)
单词的类别码请统一按如下形式定义:

实验设计
输入输出形式
【输入形式】testfile.txt中的符合文法要求的测试程序。
【输出形式】要求将词法分析结果输出至output.txt中。
样例输入和样例输出
【样例输入】
const int const1 = 1, const2 = -100;
const char const3 = ‘_’;
int change1;
char change3;
int gets1(int var1,int var2){
change1 = var1 + var2;
return (change1);
}
void main(){
printf(“Hello World”);
printf(gets1(10, 20));
}
【样例输出】
CONSTTK const
INTTK int
IDENFR const1
ASSIGN =
INTCON 1
COMMA ,
IDENFR const2
ASSIGN =
MINU -
INTCON 100
SEMICN ;
CONSTTK const
CHARTK char
IDENFR const3
ASSIGN =
CHARCON _
SEMICN ;
INTTK int
IDENFR change1
SEMICN ;
CHARTK char
IDENFR change3
SEMICN ;
INTTK int
IDENFR gets1
LPARENT (
INTTK int
IDENFR var1
COMMA ,
INTTK int
IDENFR var2
RPARENT )
LBRACE {
IDENFR change1
ASSIGN =
IDENFR var1
PLUS +
IDENFR var2
SEMICN ;
RETURNTK return
LPARENT (
IDENFR change1
RPARENT )
SEMICN ;
RBRACE }
VOIDTK void
MAINTK main
LPARENT (
RPARENT )
LBRACE {
PRINTFTK printf
LPARENT (
STRCON Hello World
RPARENT )
SEMICN ;
PRINTFTK printf
LPARENT (
IDENFR gets1
LPARENT (
INTCON 10
COMMA ,
INTCON 20
RPARENT )
RPARENT )
SEMICN ;
RBRACE }
实验设计原理(步骤)
1.先打开源文件testfile.txt,读取文件内容,直至读取不到字符,最终读取结束。
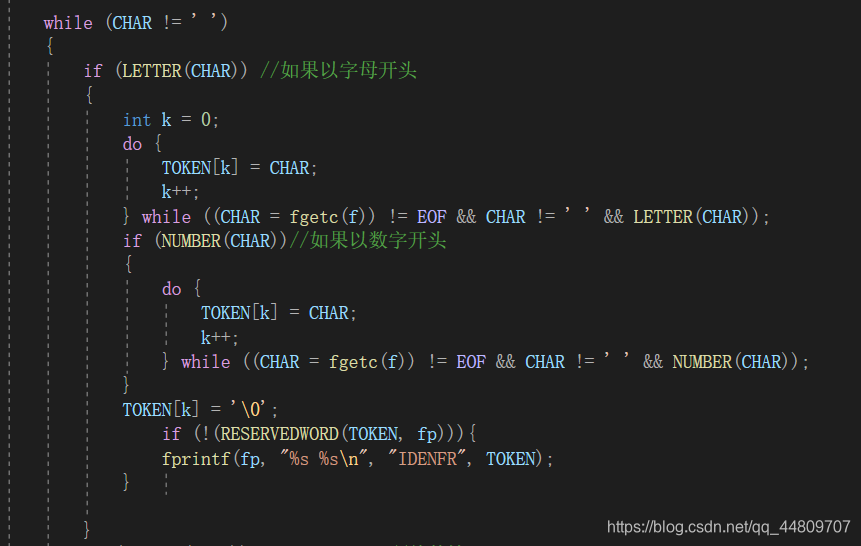
2.判断标识符:对读取的字符做判断,如果字符不为空格,则执行while循环里面的语句。While里面先判断是否为字母,如果是则进入do-while循环,直到读入的不是字母则跳出循环。
这里会有一个问题:比如str3这个标识符,判断的时候会把它拆开为str和3,所以我们要在里面加判断是否为数字,再判断这个标识符是否为保留字,这样才最终完成标识符的判断。
3.判断整型常量:如果读取的字符为整数情况,则进入do-while循环,直到读入的不是整数为止,当然这里的整数指的是‘1’这种str类型的整数。因为读的时候全部按照字符串来读的。
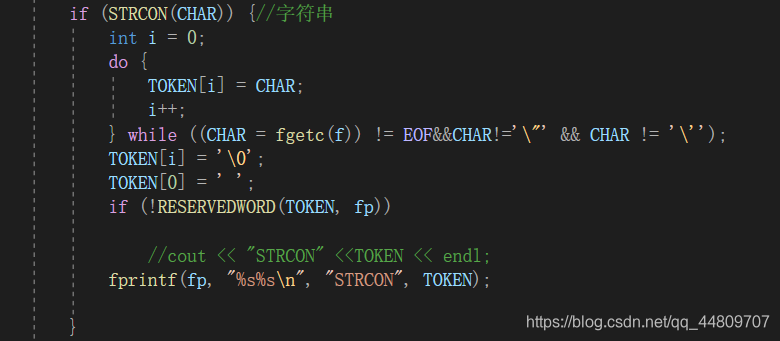
4.判断是否为字符常量或者字符串,字符常量以‘’包含,字符串以“”包含,判断读入的字符是否为‘或者“,进入do-while循环,直到读到以‘或者“结尾,至此就能提取出字符常量或者字符串。
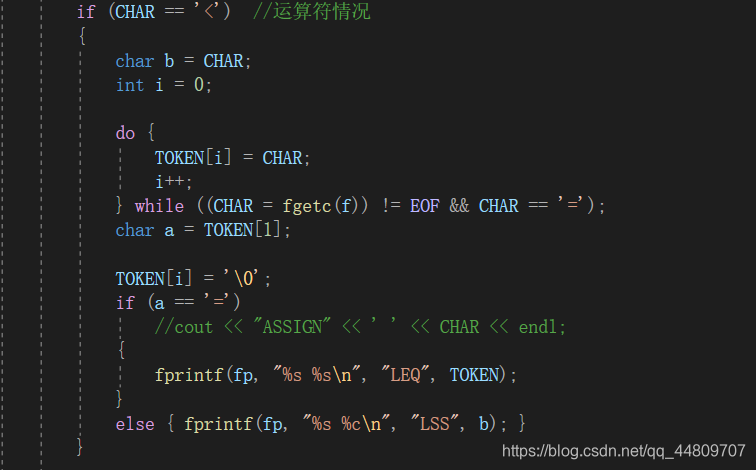
5.判断是否为运算符或界符,对于单个字符,例如‘/’、‘*’等很好判断,判断是否相等就行,但对于‘>=’、‘!=’这种运算符就需要在if语句里面写do-while循环,判断到底是>还是>=。
6.判断是否为保留字,这就涉及到两个字符串的比较,用到了strcmp函数。
主要函数和辅助函数
主要函数:
main()主函数;
最外面是一个大的while循环,判断文件是否读取完成,里面有一个小的while循环,判断读入的字符是否为空格,之后按照下面步骤进行。
- k=0,如果读取的字符是字母(LETTER函数判断),则k++,继续读字符,并把读的字符传给数组TOKEN,直到读到的不是字母;最后读完字符串,还要与关键字做比较(RESERVEDWORD函数)如果字母后面是数字,则把它定义为标识符。
- i=0,如果一开始就是数字(NUMBER函数判断),则k++,继续读数字,直到读不到数字。
- 如果是字符常量或者是字符串,前面字符是’或者”,在while循环里面,判断下面读取的字符是否为’或者”,如果是则跳出循环,在TOKEN数组里面的就是字符常量或者字符串。
- 最后是运算符判断,比如>=这个运算符,先读取的是>,然后再判断后面是否为=,如果为=,则定义为GEQ;否则为GRE,即=。
其他辅助函数:
bool NUMBER(char A)判断是否为数字
bool LETTER(char A)判断是否为字母
bool CHARCON(char A)判断是否为字符常量
bool STRCON(char A)判断是否为字符串
bool RESERVEDWORD(char* a, FILE* fp)判断是否为关键字
核心代码截图



调试过程
我先在自己电脑上用平台上的样例输入进行调试,调试到完全正确后再到cg平台上调试,调试过程中遇到一些问题。
比如对于str3这种标识符,我一开始没写判断语句,导致程序把它拆开为str和3,之后我在判断是否为标识符的里面加了判断是否有数字的语句,便成功输出。
调试前:
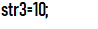

调试完后:
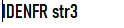
还有对于a=10,的判断,我输出的整型量是0而不是10,我找了很久才发现是‘=’判断的问题,里面的do-while循环有点问题,导致读‘=’的时候已经读到以一个‘1’上了,所以‘1’直接没了。
调试前:
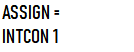

调试后:
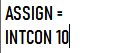
实验结果
这是在cg平台上的测试结果,完全正确!
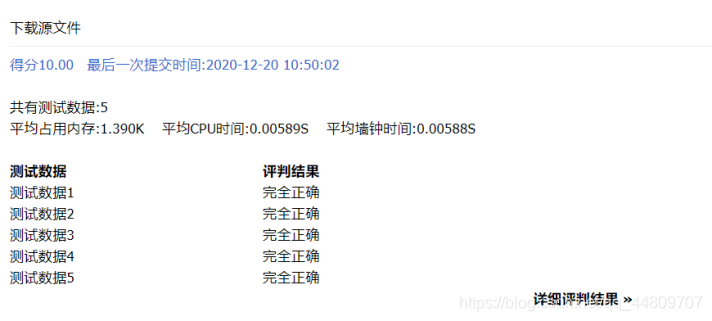
整个项目代码和实验报告在我的资源里面。词法分析实验代码和报告
有需要的可以下载。