lex快速入门
一.Lex 代表 Lexical Analyzar。
Lex 是一种生成扫描器的工具。扫描器是一种识别文本中的词汇模式的程序。这些词汇模式(或者常规表达式)在一种特殊的句子结构中定义,这个我们一会儿就要讨论。一种匹配的常规表达式可能会包含相关的动作。这一动作可能还包括返回一个标记。当 Lex 接收到文件或文本形式的输入时,它试图将文本与常规表达式进行匹配。它一次读入一个输入字符,直到找到一个匹配的模式。如果能够找到一个匹配的模式,Lex 就执行相关的动作(可能包括返回一个标记)。另一方面,如果没有可以匹配的常规表达式,将会停止进一步的处理,Lex 将显示一个错误消息。
Lex 和 C 是强耦合的。一个 .l 文件(Lex 文件具有 .l 的扩展名)通过 lex 公用程序来传递,并生成 C 的输出文件。这些文件被编译为词法分析器的可执行版本。
二.Lex 的常规表达式
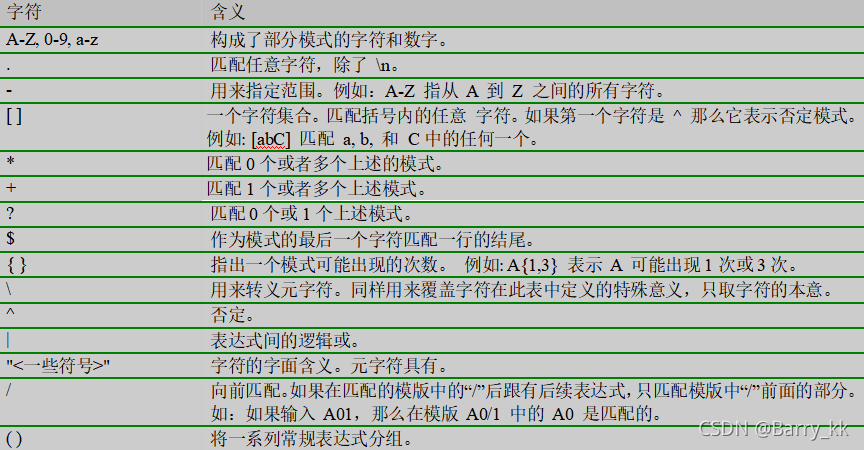
举例
常规表达式 含义
joke[rs] 匹配 jokes 或 joker。
A{1,2}shis+ 匹配 AAshis, Ashis, AAshi, Ashi。
(A[b-e])+ 匹配在A出现位置后跟随的从b到e的所有字符中的0个或1个。
标记声明举例
标记 相关表达式 含义
数字(number) ([0-9])+ 1个或多个数字
字符(chars) [A-Za-z] 任意字符
空格(blank) " " 一个空格
字(word) (chars)+ 1个或多个 chars
变量(variable) (字符)+(数字)(字符)(数字)*
三.lex编程
Lex 编程可以分为三步:
以 Lex 可以理解的格式指定模式相关的动作。在这一文件上运行 Lex,生成扫描器的 C 代码。编译和链接 C 代码,生成可执行的扫描器。
现在让我们来看一看 Lex 可以理解的程序格式。一个 Lex 程序分为三个段:第一段是 C 和 Lex 的全局声明,第二段包括模式(C 代码),第三段是补充的 C 函数。 例如, 第三段中一般都有 main() 函数。这些段以%%来分界。
Lex 变量
yyin FILE* 类型。 它指向 lexer 正在解析的当前文件。
yyout FILE* 类型。 它指向记录 lexer 输出的位置.缺省情况下,yyin和yyout 都指向标准输入和输出。
yytext 匹配模式的文本存储在这一变量中(char*)。
yyleng 给出匹配模式的长度。
yylineno 提供当前的行数信息。
Lex 函数
yylex() 这一函数开始分析。 它由 Lex 自动生成。
yywrap() 这一函数在文件(或输入)的末尾调用。如果函数的返回值是1,就停止解析。 因此它可以用来解析多个文件。代码可以写在第三段,这就能够解析多个文件。 方法是使用 yyin 文件指针(见上表)指向不同的文件,直到所有的文件都被解析。最后,yywrap() 可以返回 1 来表示解析的结束。
四.实验例题
实验一可识别正整数、浮点数、部分基本字、标识符(小写字母开头,字母数字构成的串)、部分运算符等。
lex文件.l
/* scanner for a toy Pascal-like language */
%{
/* need this for the call to atof() below */
#include <math.h>
%}
DIGIT [0-9]
ID [a-z][a-z0-9]*
IDD [A-Z][a-z0-9]*
%%
{DIGIT}+ { printf( "An integer:%s(%d)\n",yytext, atoi( yytext ) ); } /*识别正整数*/
{DIGIT}+"."{DIGIT}* { printf( "A float: %s (%g)\n", yytext,atof( yytext ) ); } /*识别浮点数*/
if|then|begin|end|procedure|function|break|do|while|else|while|void|typedef|static|goto|char|const|short|switch|unsigned|enum|default { printf( "A keyword: %s\n", yytext );}/*识别基本字及更多*/
{ID} printf( "An identifier: %s\n", yytext ); /*识别标识符*/
{IDD} printf( "An Another identifier: %s\n", yytext ); /*识别更多标识符(大写字母开头,字母数字构成的串)*/
"+"|"-"|"*"|"/"|"++"|"%"|"--" printf( "An operator: %s\n", yytext ); /*识别运算符及更多*/
"{"[^}\n]*"}" /* eat up one-line comments */
[ \t\n]+ /* eat up whitespace */
. printf( "Unrecognized character: %s\n", yytext );
%%
main( argc, argv )
int argc;
char **argv;
{
++argv, --argc; /* skip over program name */
if ( argc > 0 )
yyin = fopen( argv[0], "r" );
else
yyin = stdin;
yylex(); /*调用词法分析器*/
}
int yywrap()
{
return 1;
}
验证文本.txt
55;
63.8;
break;
switch;
beaut;
Breakdown;
+;
--
实验结果
