版权声明:本文为博主原创文章,转载请标明出处 https://blog.csdn.net/C2681595858/article/details/82791478
3.5词法分析器生成工具Lex
- lex中的冲突解决:当输入的多个前缀与一个或多个模式匹配时,Lex用如下规则选择正确的词素。
- ①总是选择最长的前缀。
- ②如果最长的前缀与多个模式匹配,总是选择在lex程序中先被列出的模式。
3.6 有穷自动机
整体思路
有穷自动机分为两类:
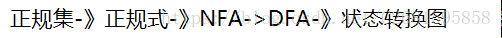
- ①不确定的有穷自动机(NFA)
- ②确定的有穷自动机(DFA)
3.6.1不确定的有穷自动机
- 组成:
- 一个有穷的状态集合S
- 一个输入状态集合 ,即输入字母表。假设 不是 中的元素。
- 一个转换函数,它为每个状态和 中的每个符号都给出了相应的后继状态的集合。
- S中的一个状态 被记为开始状态。或者说初始状态。
- S的一个子集F被指定为接受状态的集合。
- NFA转换图特征
- 同一个符号可以表示从同一状态出发到多个目标状态的多条边。
- 一条边的标号不仅可以是输入字母表中的符号,也可以是空符号串。
【课堂补充笔记】

3.6.2转换表
可以将一个NFA表示为一张表。
表的各行对应于各个状态,各列对应于输入符号和
.
3.6.3自动机中输入字符串的接受
接受符号串一定需要其最后一个状态是接受状态
3.6.4确定有穷自动机
- 是不确定有穷自动机的一个特例。
- 没有输入 之上的转换动作。
- 每个状态s和每个输入符号a,有且只有一条标号为a的边离开s。
【课堂补充笔记】

3.7从正则表达式到状态机
3.7.1从NFA到DFA的转化
- 定义基本运算:

考点:从正规式到DFA的转换。
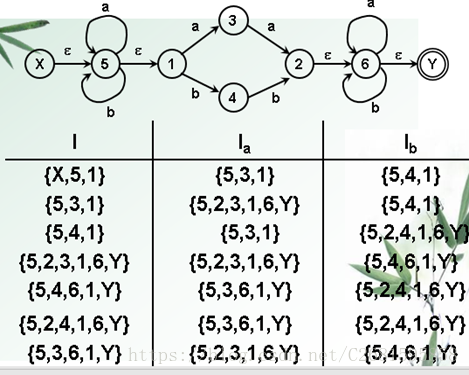
- 转换过程:
- 首先求初态的E-closure().
- 把求得的新集合当做DFA的初态。
- 然后从这个初态集合出发,判断接受一个字符a以后能够到达哪些状态(定义为状态集合J)。
- 在求E-closure(j),求得的新状态作为DFA的第二个状态。
继续循环这个过程
| I | Ia | Ib |
|---|---|---|
| S0 | A=E-closure(Move(s0,a)) | B=E-closure(Move(s0,b)) |
| A | C=E-closure(Move(A,a)) | D=E-closure(Move(A,b)) |
| B | E=E-closure(Move(B,a)) | F=E-closure(Move(B,b)) |
- 化简:
- 如果从两个状态s和t出发,沿着标有相同符号x的路径到达两个状态,且只有一个状态是接受状态,那么就说串x区分状态s和t。
- 化简的算法:
① 首先包含两个状态组一个是接受状态F,另一个组是非接受状态S-F.
② 然后对每个小组中的成员进行依次输入符号集中的符号,如果同一小组中的一些成员通过符号集中的符号,可以到达同一状态组(一定注意),那么将他们分为新的小组。
③ 原先的组变成新组。
④ 重复上述过程,直到所有小组不能再划分成新的小组。
最后一定要进行化简。
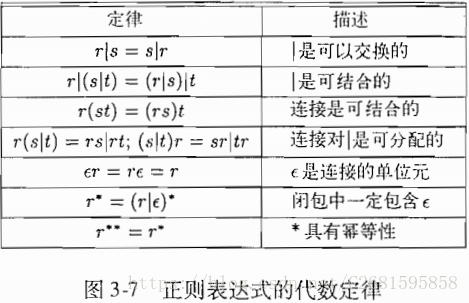
正规式的等价转化(等价公式)
3.7.4从正则表达式构造NFA
- 将正则表达式按照如下规则进行拆分即可,并且要注意优先级。