编译原理——词法分析
编译原理课程上的一次实验
也是本小白自学Python编译出的第一个程序
程序实现的是:
分析指定txt文件中的代码,将其按照保留字、运算符、界符、常数、字母分为五大类,结果显示为1~5。(课本要求。emmmm无奈.jpg)
只完成了最基本的功能,第一次发博客,有问题欢迎指出哈可探讨~
txt文件内容:
main()
{
int a,b;
a=10;
b=a+20;
}
源代码:
#保留字列表:
reserved_word=['if','int','for','while','do','return','break','continue']
#运算符列表:
operater=['+','-','*','/','=']
#界符列表:
boundary_symbol=[',',';','{','}','(',')']
#常数列表:
constant=['0','1','2','3','4','5','6','7','8','9']
#字母列表:
letter=['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z','A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z']
#预处理:
#readline():每次读出一行内容,返回一个字符串对象。
#readlines():读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素。
#join():连接字符串数组。将字符串、元组、列表中的元素以指定的字符(默认分隔符)连接生成一个新的字符串。
#strip():用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列,不能删除中间部分的字符。
with open(r'D:\PC\txt\code.txt') as f:
#print(f.read())
#lines=f.readlines()
#print(lines[2])
#print(lines[2].split())
codes = [] #使用codes来记录所有词,以列表的形式
while True:
line = f.readline().split() #按行读取并去掉空格
codes=codes+line
if not line:break
print("预处理后:",codes) #预处理结束
#保留字匹配函数:
def reserved_word_matching(p):
for word in reserved_word:
if p==word:
return 1
#运算符匹配函数:
def operater_matching(p):
for word in operater:
if p==word:
return 1
#界符匹配函数:
def boundary_symbol_macthing(p):
for word in boundary_symbol:
if p==word:
return 1
#常数匹配函数:
def constant_matching(p):
for word in constant:
if p==word:
return 1
#字母匹配函数:
def letter_matching(p):
for word in letter:
if p==word:
return 1
#扫描:
for code in codes: #按元素扫描
s=code
i=0
while(i<len(s)): #按元素中的字符扫描
#界符(分隔符)判断:
if boundary_symbol_macthing(s[i])==1:
print("(5,",s[i],")")
i+=1 #识别下一个字符
#运算符判断:
elif operater_matching(s[i])==1:
print("(4,", s[i], ")")
i+=1 #是被下一个字符
#开头是字母的标识符或关键字判断:
elif letter_matching(s[i])==1: #是字母的情况
t=i+1 #用t(整型)来记录i的后一位
p=s[i] #用p(字符串)来记录字符(或字符串)
while(t<len(s)):
if letter_matching(s[t])==1:
p=p+s[t]
t=t+1
else:
break
i=t #识别下一个该扫描的字符
#保留字判断:
if reserved_word_matching(p)==1:
print("(1,", p, ")")
#标识符判断:
else:
print("(2,", p, ")")
#常数判断
elif constant_matching(s[i])==1: #是常数的情况
t=i+1
p=s[i]
while(t<len(s)):
if constant_matching(s[t])==1:
p=p+s[t]
t=t+1
else:
break
i=t #识别下一个该扫描的字符
print("(3,", p, ")")
print("词法分析完成!")
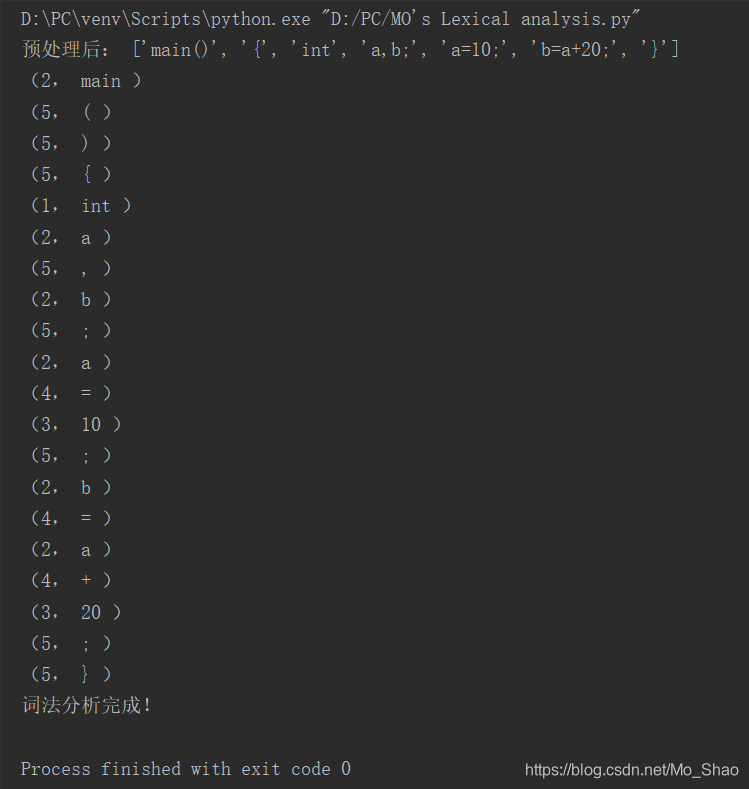
运行后截图: