//放暑假了,大三了。开学就要学编译原理、微机原理、操作系统三门大课qnq
//true true beginning
词法分析概述
首先搞清楚词法分析在编译程序中的位置以及作用:
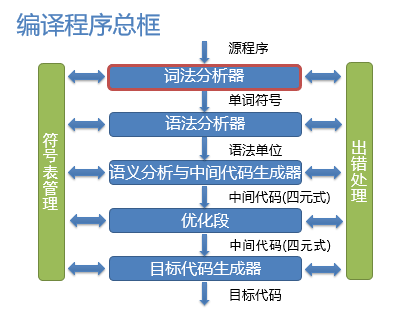
源程序 经过词法分析 得到单词符号(包括单词符号的种别,是标识符啦,还是数据啦,
还是括号或者操作符…),分析出的单词符号供语法分析器进一步处理

词法分析由词法分析器(Lexical Analyzer)完成,词法分析器并不一定先用单独的一遍
分析出所有单词符号,而可能通过语法分析器驱动,每当语法分析器需要下一个单词符号
时,词法分析器才继续向后分析,并将分析出单词符号传递给语法分析器
词法分析器的结构
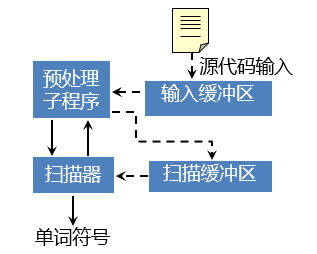
在扫描器的驱动下,预处理子程序将到输入缓冲区中源代码的字符处理后由
扫描缓冲区读入。扫描器在扫描缓冲区中识别单词符号,然后输出
其中预处理子程序的作用是
- 剔除源代码中的空格、回车符、换行符等编辑性字符
- 区分标号区、捻接续行,给出句末符等等
扫描缓冲区
扫描缓冲区的大小是固定的,那么会有一些问题
比如在缓冲区中识别一个单词符号时,这个单词/符号到缓冲区末尾还没有结束
或者说作为缓冲区的是一个容量为128的char型数组,有一个变量名长度为128,
这些情况下是没办法准确识别出单词符号的
因此,将扫描缓冲区一分为二(或者说用两个缓冲区进行缓冲),并限定单词长度不可超过缓冲区长度(两个缓冲区长度相当),这样无论单词从哪里开始截断,都可以识别出来
超前搜索
得到单词符号后要确定单词符号的种别
对于一些设计得不够好的编程语言,可能无法仅仅通过单词本身确定单词的词性
比如FORTRAN语言
FORTRAN出现在编程语言的早期阶段,此时编程语言的设计还不成熟
FORTRAN允许关键字作为变量名,允许关键字变量名间不空格
DO 99 K = 1,10 可以写成 DO99K=1,10,这里的DO均为关键字
但是DO99K=1.10中,(注意是1.10而不是1,10),DO99K是作为一个变量名的
这种情况下,仅仅读到DO是无法判断单词边界与词性的,需要超前搜索,通过后面的单词符号,判断前面的单词及其词性,对于词法分析来说很不友好
所以现代程序语言在设计时遵循一些规则,
- 所有基本字都是保留字,不可再作为标识符
- 基本字作为特殊的标识符处理
- 基本字、标识符和常数间若没有确定的运算符或界符作间隔,必须使用一个空白符作间隔
一方面避免了超前搜索、方便编译程序进行词法分析,另一方面增加代码的可读性
词法分析建立在一些理论上,并使用一些描述工具:
词法分析器的设计:
- 确定语言的单词规范——单词表
- 由单词表得到该语言所有字的状态转换图
- 根据状态转换图是实现词法分析器
由以上步骤,产生了一套自动产生词法分析器的方法:
词法分析器的自动产生工具
2019/7/19
