知识总结与感受:
第三章词法分析,首先学到了词法分析器的功能和输出形式
源程序—>词法分析器—>单词符号,
单词有基本字,标识符,常数,运算符,界符这五种。
词法分析器输出的单词符号常常用二元式来表示:
<单词种别,单词符号的属性值>
单词符号的识别有超前搜索,直接分析法,状态转换图法这三种。
其中,超前搜索在单词识别的过程中,通过向前多读几个符号的形式,准确的进行单词的识别。一旦确定识别到的单词之后,需要进行扫描指针的回退,保证单词识别工作的顺利进行。
而直接分析法根据读来的第一个字符的种类分别转到各种子程序处理。这些子程序功能就是识别以相应字符开头的各种单词。
状态转换图法通过结点,箭弧和箭弧上的标记来接受一定的符号串。

正规表达式与有限自动机是第三章的重要内容。
我们可以把具有相同特征的字放在一起组成一个集合,即所谓的正规集,然后使用一种形式化的方法来表示正规集,即所谓的正规式。
状态转换图形式化成自动有限机,自动有限机有两种:
确定的有限自动机(Deterministic Finite Automata)
定义:一个确定有限自动机(DFA)M是一个五元式:
M = (S, ∑, f, s0, F),其中
S是一个有限的状态集合,它的每个元素我们称为一个状态
∑是一个有穷的输入符号的字母表,它的每个元素我们称为一个输入字符
f是从 S×∑ →S的单值部分映射
s0是S的一个元素,为初始状态,它是唯一的
状态集合F是终止状态的集合,它是S的子集(可空)
非确定的有限自动机(Non-deterministic Finite Automata)
定义:一个非确定有限自动机(NFA)M是一个五元式
M = (S, ∑, f, S0, F),其中
S是一个有限的状态集合,它的每个元素我们称为一个状态
∑是一个有限的输入符号的字母表,它的每个元素我们称为一个输入字符
f是从S×∑*→2S 的部分映射,其中,2S表示S的幂集合(所有S的子集组成的集合)
(f是非单值的àM是非确定)
状态集合S0是初始状态集合,它是S的子集
状态集合F是终止状态的集合,它是S的子集
有限自动机的等价性:对任何两个有限的自动机M1和M2,若有L(M1)=L(M2),则称M1与M2等价。
正规式与有限自动机的等价性
定理1.对于任何∑上NFA M都可构造一个∑上的正规式V,使得 L(V) = L(M) 其中,L(M)是∑上NFA M所能识别的字的全体L(V)是∑上的正规集。
方法:
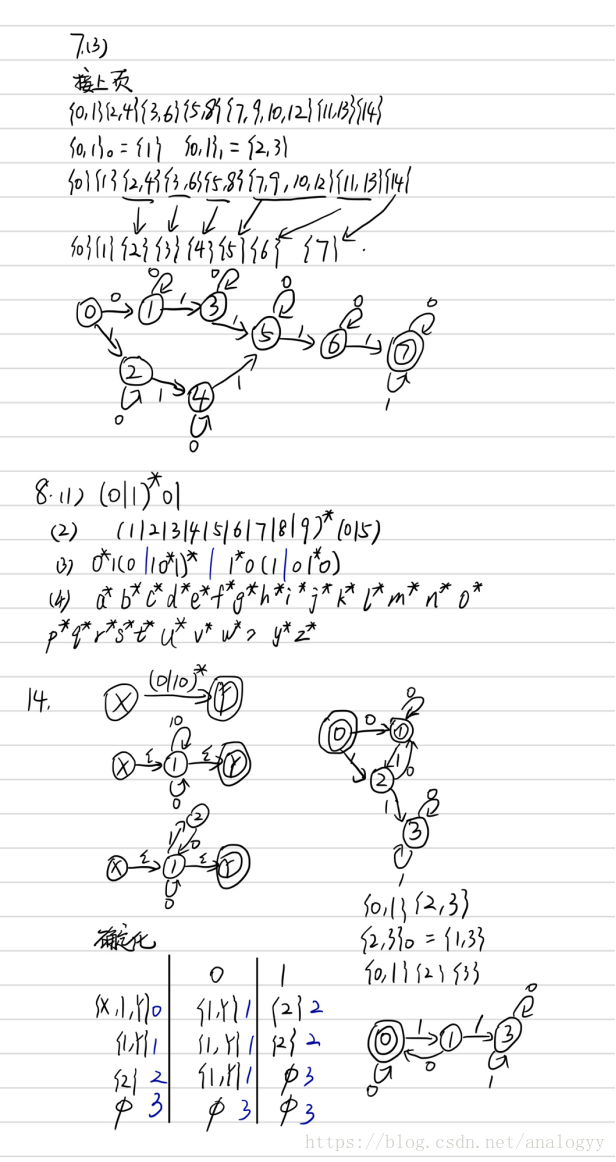
(1)在M转换图上加进X结点和Y结点,从X结点用弧ε连接M的所有初态结点,M的所有终态结点用弧ε连接到Y,得到一个NFA M’,且L(M) = L(M’)
(2)使用替换规则逐步消去M’的所有结点,直到只剩下X结点和Y结点,在消去过程中,逐步使用正规式来标记箭弧
定理2. 对于∑上的每一个正规式V,存在一个∑上的DFA M,使得L(M) = L(V) 。
方法:
第一步,在∑上构造一个NFA M’
(1) 构造一个拓广的转换图
(2) (2)使用分裂规则对V进行分裂,加进新结点,直到把图转换成每条弧上标识为∑上的一个字符或ε,最后得到一个NFA M’且L(M’) = L(V)。
第二步,把M’确定化
两个定义
定义1:假定I是M’的状态集的子集,定义I的ε闭包ε_CLOSURE(I)为:
(a)若q∈I,则q∈ε_CLOSURE(I)
(b)若q∈I,那么从q出发经任意条ε弧而能到达的任何状态q’都属于ε_CLOSURE(I) ;
定义2:假定I是M’的状态集的子集,a ∈ ∑,定义Ia =ε_CLOSURE(J)
其中,J是所有那些可从I中的某一状态结点出发经过一条a弧而到达的状态结点的全体。
化简DFA的一般步骤
(1) 检查状态转换函数是否为全函数。
(2) 用化简算法进行化简
(3) 去掉死状态
通过替换公式和确定化将正规式转换成与之等价的有限自动机,在得出与正规式等价的有限自动机后还要对有限自动机进行化简,寻找一个状态书比M少的DFA M’,使得L(M)=L(M’)。
正规式,有限自动机与DFA的转换时这一章比较复杂的内容,难度对比上一章有明显的提升。这一块内容比较难理解。
课后题总结: