版权声明:本文为博主原创文章,转载请标明出处 https://blog.csdn.net/C2681595858/article/details/82776489
文章目录
3.1词法分析器的作用
词法分析器的作用
①生成词素。
②过滤掉注释和空白。
③将编译器生成的错误消息与源程序的位置联系起来。
将词法分析和语法分析阶段分开的原因:
①简化编译器设计。
②提高编译器的效率。
③增强编译器的可移植性。
- 一个标识符的属性值是一个指向符号表中该标识符对应条目的指针。
- 词法分析器很难发现程序中的错误。
3.2输入缓冲
- 快速找到正确词素
3.2.1 缓冲区对
- 用两个指针,一个指向开头,另一个开始向前扫描,直到发现一个词素。
- 并且还要注意是否达到缓冲区末尾。
- 两个缓冲区,一个结束,马上开始另一个缓冲区的读取,加快处理速度。
- 每个词素的长度不能超过N.
3.2.2哨兵标记
- 扩展每个缓冲区的长度,并在其末尾设置哨兵,将对缓冲区末端的测试和对当前字符的测试合二为一。
3.3词法单元的规约
3.3.1串和语言
- 空串用ξ表示.
- 前缀、后缀、子串(包括空串和本身)
- 真前缀,真后缀,真子串(不包括空串和本身)
- 连接:将两个串连在一起。
- 任何串和空串连接后得到该串本身。
- 指数运算:就是将多个该串连接。
- 一个串的0次方是空串,1次方是它本身。
3.3.2语言上的运算
- 并:类似于集合的并
- 连接:就是从一个集合中任取一个串和另一个集合中的任意一个串连接得到的所有串的集合。
- 闭包:就是将无穷多个该串进行连接操作。包括空串。
- 正闭包:和闭包的区别就是不包括空串。
3.3.3正则表达式
- 每个正则表达式都可以由较小的正则表达式按照如下规则递归的构建:
每个正则表达式r表示一个语言L( r ),- 归纳基础:
- ① 是一个正则表达式,L( ) = { },即该语言只包含空串。
- ②如果a是 上的一个符号,那么a是一个正则表达式,并且L(a) = {a}, .
- 归纳步骤:r和s是正则表达式,L(r)和L(s)是对应的语言。
- ①(r)|(s)是一个正则表达式,表示L( r) U L(s)
- ② (r)(s)是一个正则表达式,表示L( r )L(s).
- ③ (r)*是一个正则表达式,表示(L( r ))*.
- ④ (r)是一个正则表达式,表示L( r ).
- 正则表达式运算优先级:
- *优先级最高,并且是左结合的。
- 连接具有次优先级。
- 并(|)的优先级最低。
- 可以用一个正则表达式表示的集合叫做正则集合。
- 正则表达式遵循的代数定律:
定律 描述 r|s = s|r |是可以交换的 r|(s | t) = (r|s)|t |是可以结合的 r (st) = (rs)t 连接是可结合的 r(s | t) = rs | rt 连接对并(|)是可分配的 r = r r* = (r| )* 闭包一定包含 r ** = r* 闭包具有幂等性
- 归纳基础:
3.3.4正则定义
用一个新的符号表示一个正则表达式。
3.3.5正则表达式的扩展
- ①一个或多个实例(+): 和
- ②零个或一个实例(?):
? + *具有同样的优先级 - ③字符类:
3.4词法单元的识别
- 词法分析器返回词法单元名和属性值。
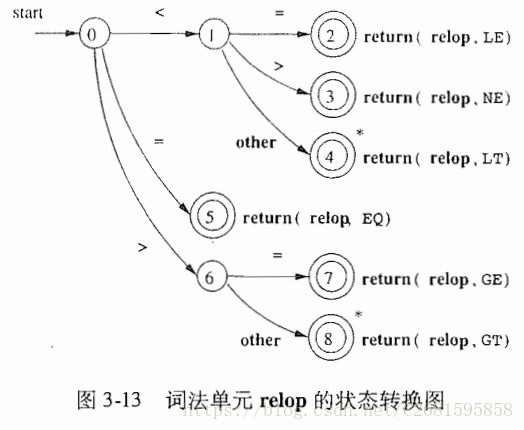
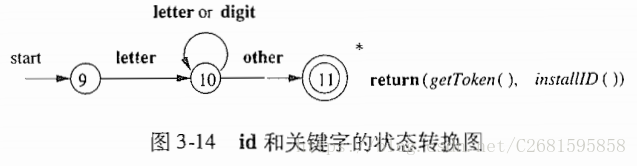
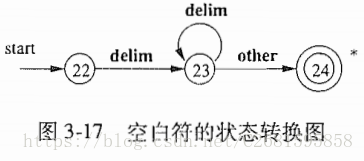
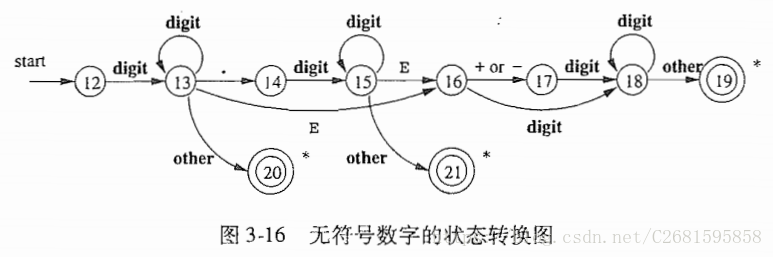
3.4.1状态转换图
- 关于状态转换图的要求:
- 某些状态称为最终转态或者接受状态。这些状态表明已经找到了一个词素。用双圈表示。该状态可以向语法分析器返回一个词法单元和对应属性值。
- 如果需要回退一个位置,那么在状态附近加上一个*.
- 有一个状态被指定为开始状态,该状态由一条没有出发节点的、标号为start的边指明。
3.4.2保留字和标识符的识别
- 各个部分的状态转换图: