主要内容:
1、Hive的基本工能机制和概念
2、hive的安装和基本使用
3、HQL
1. 什么是hive
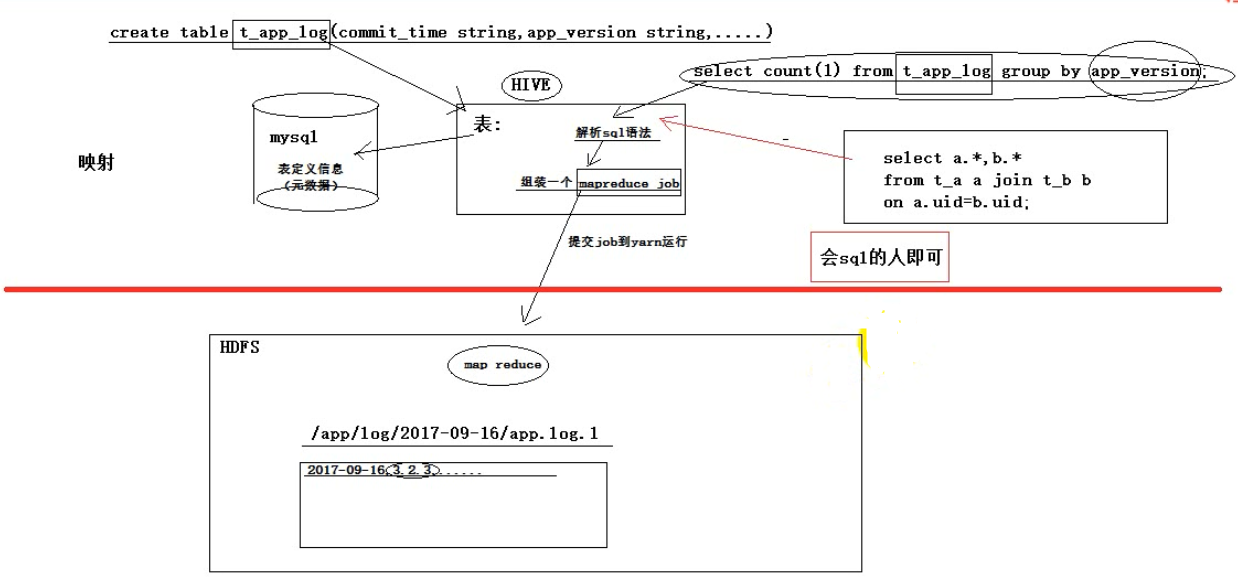
hive本身是一个单机程序。转在哪里都行,相对于hadoop来说就是一个hdfs的客户端和yarn的客户端,放在哪一台linux机器都无所谓,只要能链接上hadoop集群就可以,hive本身没有负载,无非就是接收一个sql然后翻译成mr,提交到yarn中去运行。
hive数据分析系统(数据仓库,像一个仓库一样,存放着很多数据,而且可以做各种查询、统计和分析,将结果放入新生的表中),的正常使用,需要
1、mysql:用来存放hdfs文件到二维表的描述映射信息,也就是元数据
2、hadoop集群
hdfs集群
yarn集群
1.1. hive基本思想
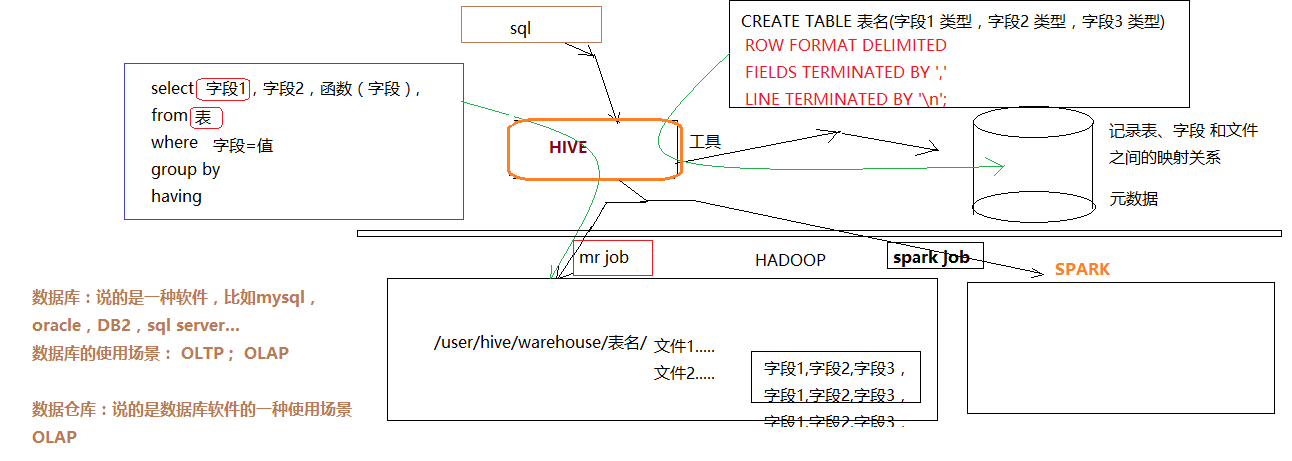
Hive是基于Hadoop的一个数据仓库工具(离线),可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
1.2. 为什么使用Hive
- 直接使用hadoop所面临的问题
人员学习成本太高
项目周期要求太短
MapReduce实现复杂查询逻辑开发难度太大
- 为什么要使用Hive
操作接口采用类SQL语法,提供快速开发的能力。
避免了去写MapReduce,减少开发人员的学习成本。
功能扩展很方便。
1.3. Hive的特点
- 可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
- 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 容错
良好的容错性,节点出现问题SQL仍可完成执行。
2. hive的基本架构
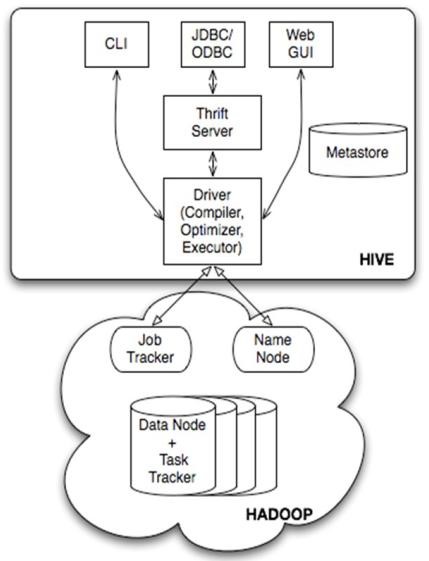
Jobtracker是hadoop1.x中的组件,它的功能相当于:
Resourcemanager+MRAppMaster
TaskTracker 相当于:
Nodemanager + yarnchild
hive 2.0 以后的版本,底层的运算引擎已经不是mr了,而是spark
3. hive安装
3.1. 最简安装:用内嵌derby作为元数据库
准备工作:安装hive的机器上应该有HADOOP环境(安装目录,HADOOP_HOME环境变量)
安装:直接解压一个hive安装包即可
此时,安装的这个hive实例使用其内嵌的derby数据库作为记录元数据的数据库
此模式不便于让团队成员之间共享协作
3.2. 标准安装:将mysql作为元数据库
mysql装在哪里都可以,只要能提供服务,能被hive访问就可以。
下载mysql的rpm安装包

.tar .gz .tar.gz的区别
.tar是讲多个文件打包成一个文件,没有压缩,
.gz是压缩
3.2.1. mysql安装
① 上传mysql安装包
② 解压:
tar -xvf MySQL-5.6.26-1.linux_glibc2.5.x86_64.rpm-bundle.tar
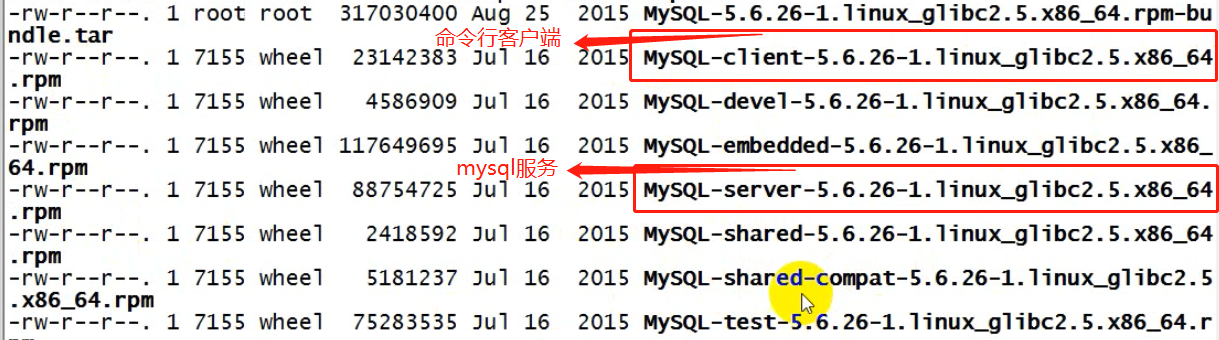
③ 安装mysql的server包
rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
依赖报错:
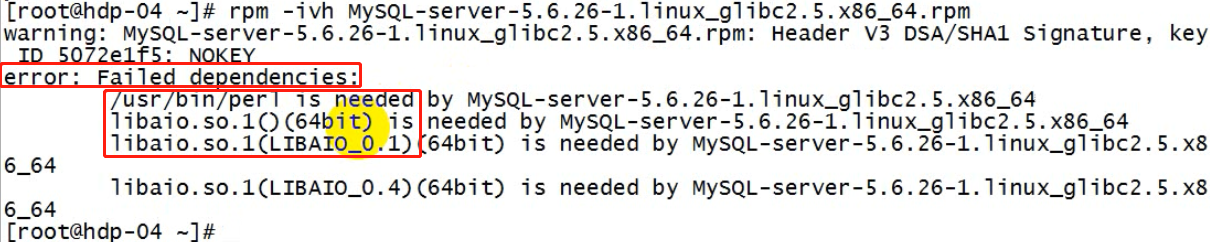
缺perl(是一中编程语言,好比java编程缺少jdk一样)
安装perl

yum install perl
安装libaio

安装完perl以及libaio后 ,继续重新安装mysql-server
(可以配置一个本地yum源进行安装:
1、先在vmware中给这台虚拟机连接一个光盘镜像
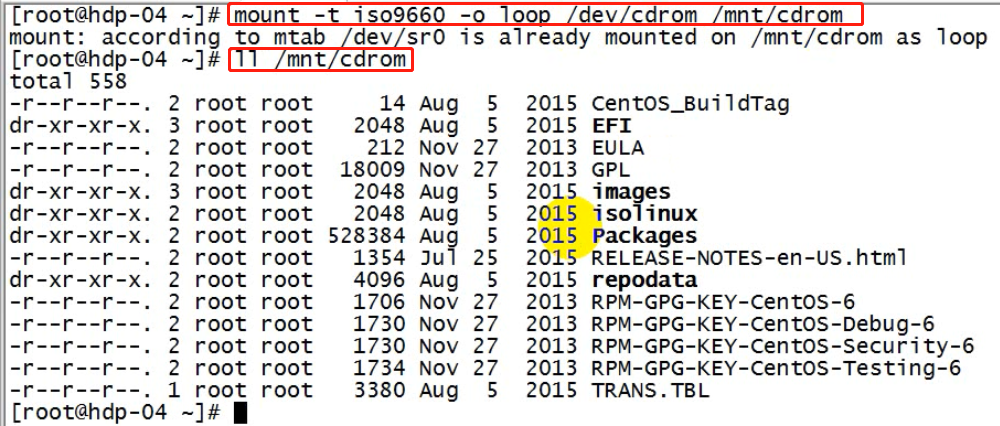
2、挂载光驱到一个指定目录:mount -t iso9660 -o loop /dev/cdrom /mnt/cdrom
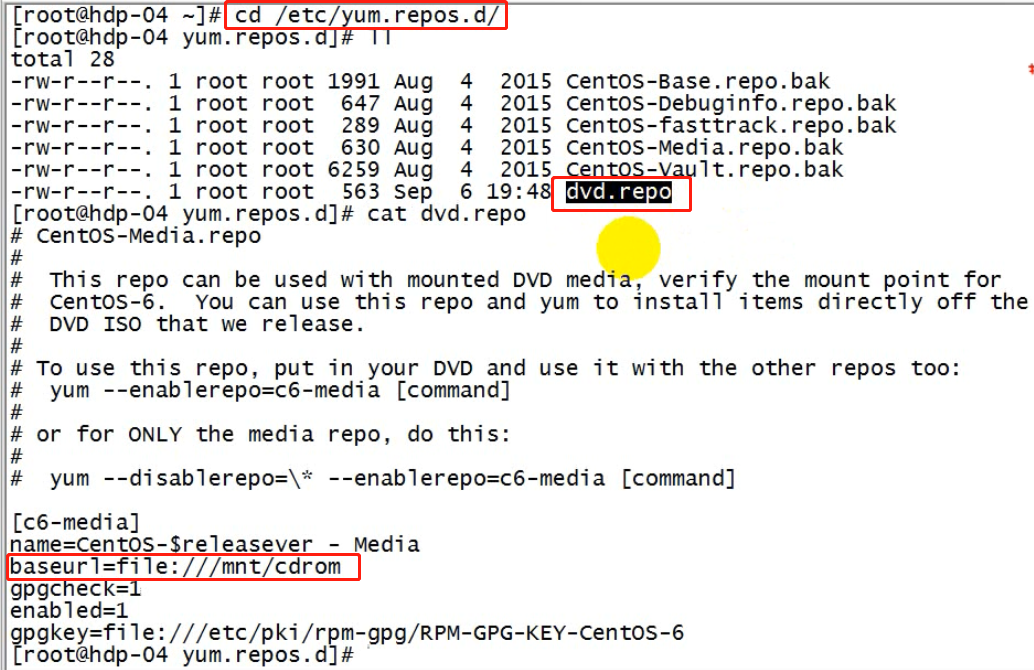
3、修改yum源;将yum的配置文件中baseURL指向/mnt/cdrom
)
1、链接光盘镜像
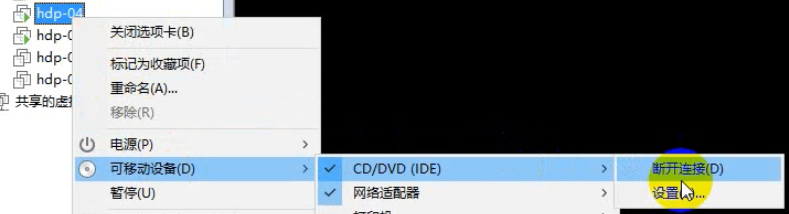
2、挂载光驱
3、修改yum源
rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
又出错:包冲突conflict with

移除老版本的冲突包:mysql-libs-5.1.73-3.el6_5.x86_64
rpm -e mysql-libs-5.1.73-3.el6_5.x86_64 --nodeps
继续重新安装mysql-server
rpm -ivh MySQL-server-5.6.26-1.linux_glibc2.5.x86_64.rpm
成功后,注意提示:里面有初始密码及如何改密码的信息
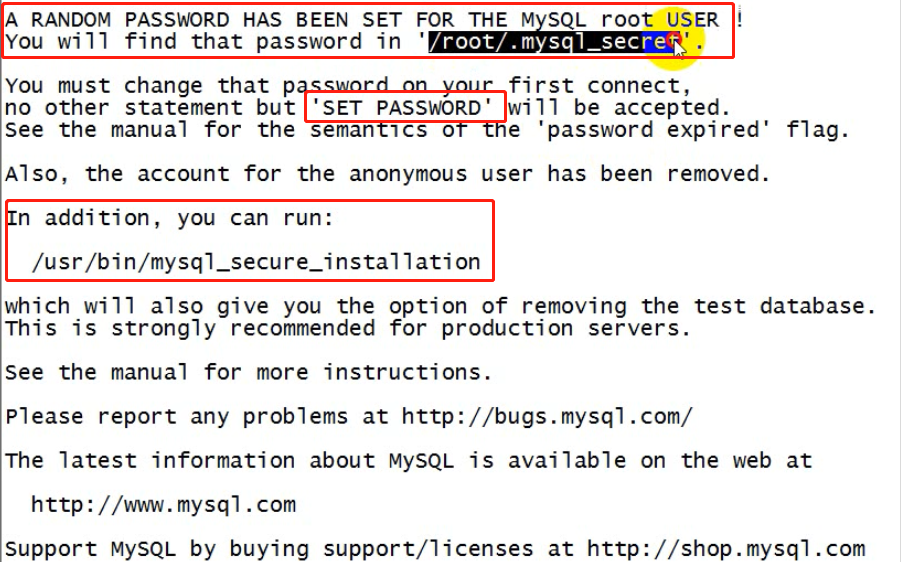
初始密码:
/root/.mysql_secret

改密码脚本:需要mysql客户端
/usr/bin/mysql_secure_installation

④ 安装mysql的客户端包:
rpm -ivh MySQL-client-5.6.26-1.linux_glibc2.5.x86_64.rpm
⑤ 启动mysql的服务端:
service mysql start
Starting MySQL. SUCCESS!

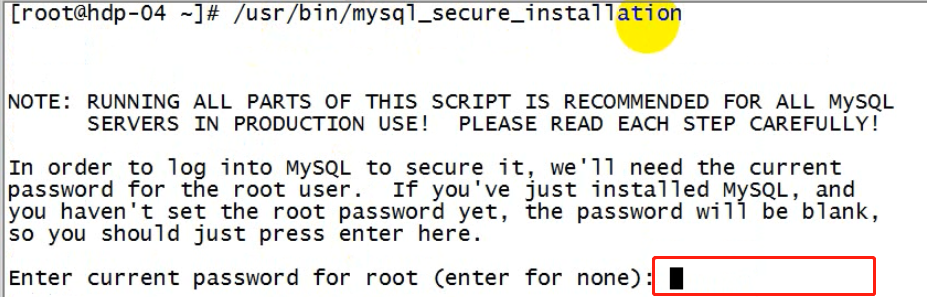
⑥ 修改root的初始密码:
/usr/bin/mysql_secure_installation
按提示,输入生成的随机密码

⑦ 测试:
用mysql命令行客户端登陆mysql服务器看能否成功
[root@mylove ~]# mysql -uroot -proot mysql> show databases;
mysql>exit
⑧ 给root用户授予从任何机器上登陆mysql服务器的权限:
mysql用户权限控制比较严苛,光有用户名,密码还不行,mysql可以限制从哪个机器登录过来的,默认只能从服务器所在的本机登录过来。需要设置某一个用户可以从哪台机器登录过来。
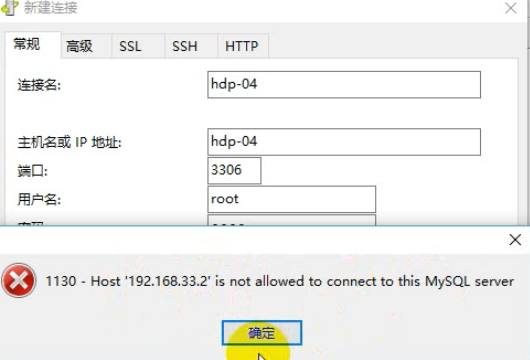
授予root用户,@任何机器,访问任何库的任何表的权限。
mysql> grant all privileges on *.* to 'root'@'%' identified by '你的密码' with grant option; Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
注意点:要让mysql可以远程登录访问
最直接测试方法:从windows上用Navicat去连接,能连,则可以,不能连,则要去mysql的机器上用命令行客户端进行授权:
在mysql的机器上,启动命令行客户端:
mysql -uroot -proot mysql>grant all privileges on *.* to 'root'@'%' identified by 'root的密码' with grant option; mysql>flush privileges;
3.3、开始安装hive
版本说明1.2.1: hive 2.0 以后的版本,底层的运算引擎已经不是mr了,而是spark
3.3.1、上传并解压缩安装包

3.3.2、修改配置文件—元数据库配置
目的:告知mysql在哪里;以及用户名,密码
原因:hive是java程序,需要使用jdbc去连接mysql数据库
hive-site.xml
vi conf/hive-site.xml
<configuration> <property>
<!-- 连接url --> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property>
<!-- 连接的驱动类 --> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property>
<!-- 用户名 -->
<name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property>
<!-- 密码 --> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property> </configuration>
3.3.3、jdbc驱动包
上传一个mysql的驱动jar包到hive的安装目录的lib中

3.3.4、配置环境变量
因为,hive要访问hdfs,还要提交job到yarn。
1、配置HADOOP_HOME 和HIVE_HOME到系统环境变量中:
/etc/profile

2、刷新配置文件
source /etc/profile
3.3.4、启动hive
然后用命令启动hive交互界面:
[root@hdp20-04 ~]# hive-1.2.1/bin/hive

4、hive使用方式
1、直接在交互界面输入sql进行交互。
2、sql里可以直接使用java类型。
3、hive中建立数据库后,会在hdfs中出现对象的库名.db的文件夹
4、建表的目的是为了和数据文件进行映射;建立表之后(默认建立在default库中),hive会在hdfs上建立对应的文件夹,文件夹的名字就是表名称;
4.1、只要hdfs文件夹中有了数据即文件,对应的表中就会有了记录
4.2、hdfs文件中的数据是按照分隔符进行切分的(value.toString().split("分割符"))(默认分隔符\001:ctrlA--不可见,cat命令下看不见);表的定义是保存在mysql中的。
以下是简单的实例:hive中的数据库,数据表——建库,建表
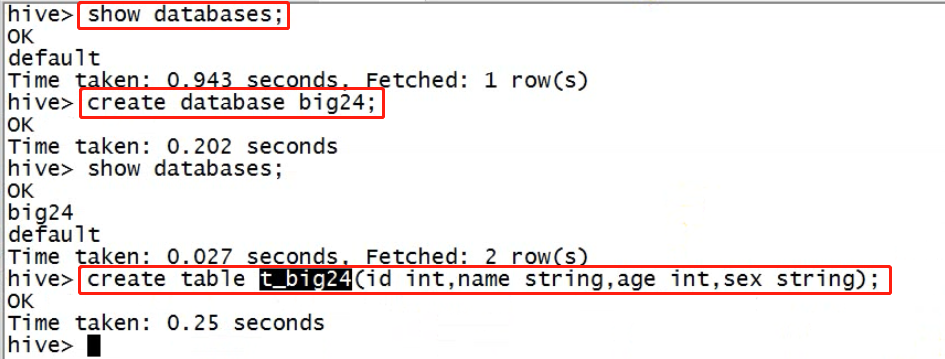
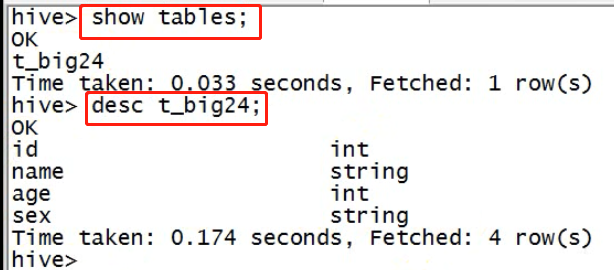
创建数据文件,上传到hdfs对应的目录下;

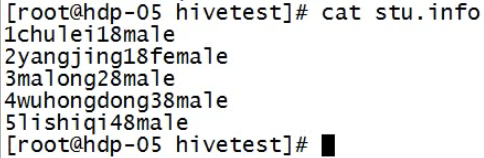
上传到hdfs
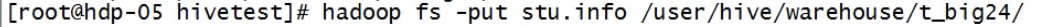
hive查询
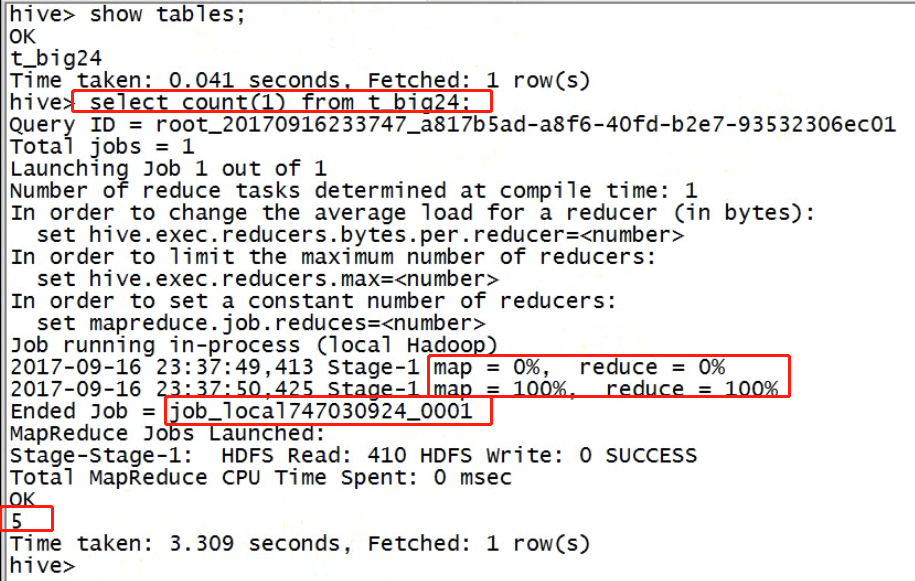
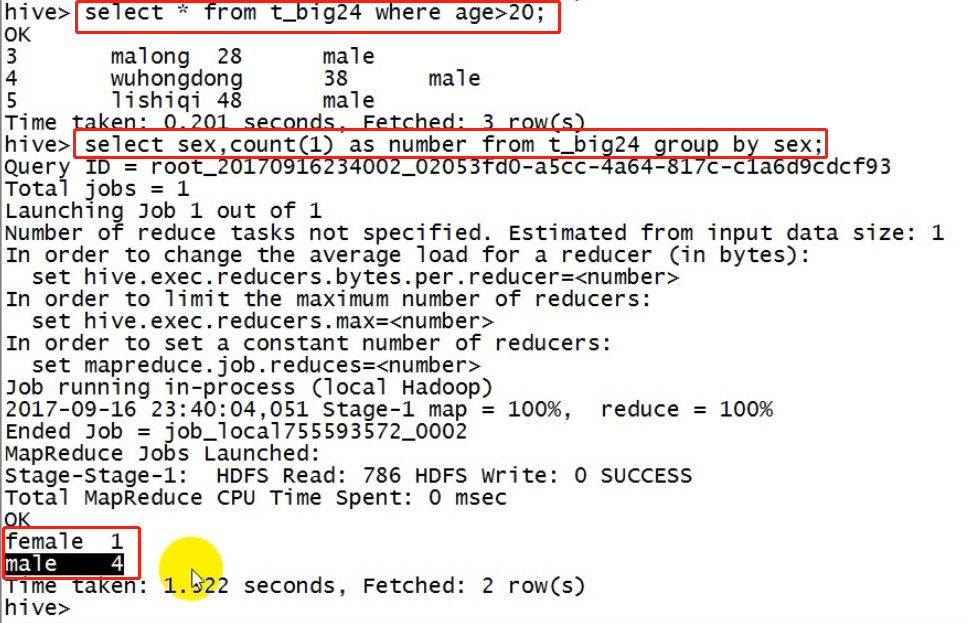
hive有hdfs的对应
hdfs中的user文件夹下有hive,hive下有warehouse(仓库),warehouse下有对应于表名的文件夹




现在看一下mysql中的元数据信息(内部工作机制)

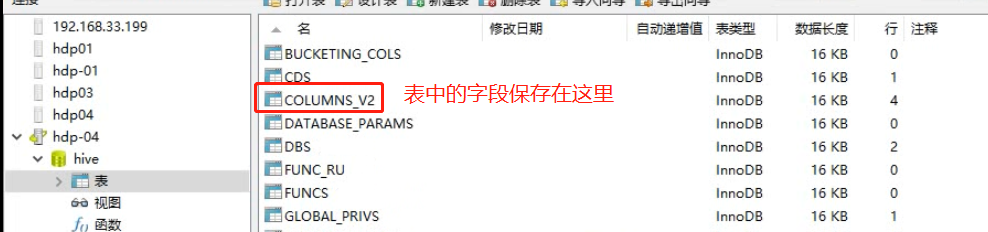
新建数据库的描述信息

新建数据表的描述信息

表中的字段信息

总结:
hive建立一张表的内在机制:
1、在mysql中记录这张表的定义;
2、在hdfs中创建目录;
3、只要把数据文件都到目录下,就可以在hive中进行查询了;
4、因此,不同的hive只要是操作的同一个mysq,同一个hdfs集群,看到的数据是一致的;
4.1、最基本使用方式
启动一个hive交互shell,写sql拿响应,写sql看结果,如上所示。
bin/hive
hive>
以下是一些便捷技巧设置
设置一些基本参数,让hive使用起来更便捷,比如:
1、让提示符显示当前库:
hive>set hive.cli.print.current.db=true;

2、显示查询结果时显示表的字段名称:
hive>set hive.cli.print.header=true;
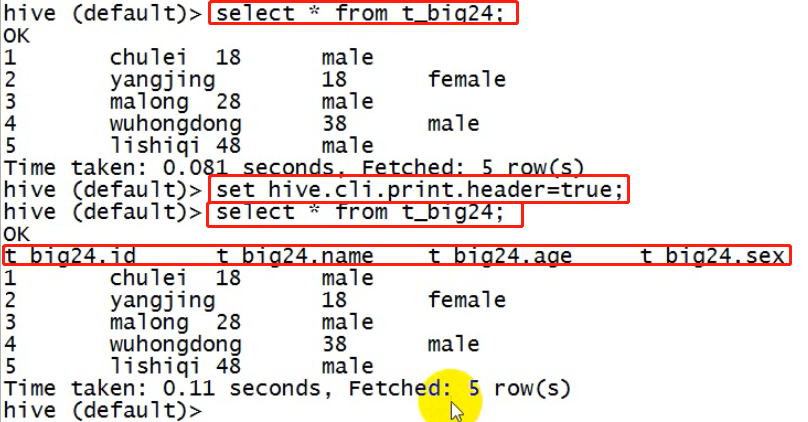
3、但是这样设置只对当前会话有效,重启hive会话后就失效,
解决办法:
在linux的当前用户主目录中,编辑一个.hiverc(隐藏文件)文件,将参数写入其中:
vi .hiverc(hive启动的时候会自动去当前用户目录下加载这个文件)
set hive.cli.print.header=true; set hive.cli.print.current.db=true;
4.2、启动hive服务使用
hive服务程序和hive本身不一样的;hive本身就是一个单机版的交互式程序;而hive服务可以在后台运行,它监听端口1000(默认);
此时有需要另个程序:
1、hive服务程序
2、hive服务的客户端程序

hive服务以及hive服务客户端

4.2.1、启动hive服务
1、前台启动
2、后台启动
# 前台方式 bin/hiveserver2
# 或者
bin/hiveserver2 -hiveconf hive.root.logger=DEBUG,console
上述启动,会将这个服务启动在前台,如果要启动在后台,则命令如下:
& 表示在后台运行,但是标准输出任然是在控制台
1 代表:标准输出
> 代表:重定向
2 代表:错误输出
jobs可以找到在后台运行的程序,然后 fg 1 将其切换到前台,ctrl ^ c 结束进程
若不想要任何的输入,可以将标准输入重定向到linux中的黑洞中。
&1 表示:引用
# nobup表示就算启动该进程的linux用户退出,该进程仍然运行
nohup bin/hiveserver2 1>/dev/null 2>&1 &
# 除了root用户,只要当前linux用户退出,该进程就会被杀死
bin/hiveserver2 1>/dev/null 2>&1 &
4.2.2、启动hive服务客户端beeline
1、连接命令 !connect
2、链接方式2,启动beeline时给出参数链接
3、输入hdfs用户密码认证
4、关闭连接,退出客户端
启动成功后,可以在别的节点上用beeline去连接
方式(1)
[root@hdp20-04 hive-1.2.1]# bin/beeline
回车,进入beeline的命令界面
输入命令连接hiveserver2
beeline> !connect jdbc:hive2//mini1:10000
(hadoop01是hiveserver2所启动的那台主机名,端口默认是10000)
方式(2)
启动时直接连接:
bin/beeline -u jdbc:hive2://mini1:10000 -n root
接下来就可以做正常sql查询了
hive服务客户端连接hive服务用户身份:因为要访问hdfs,填入启动hdfs的用户身份,访问hdfs不需要密码

使用实例(界面比上面的单机版hive交互界面好多了)
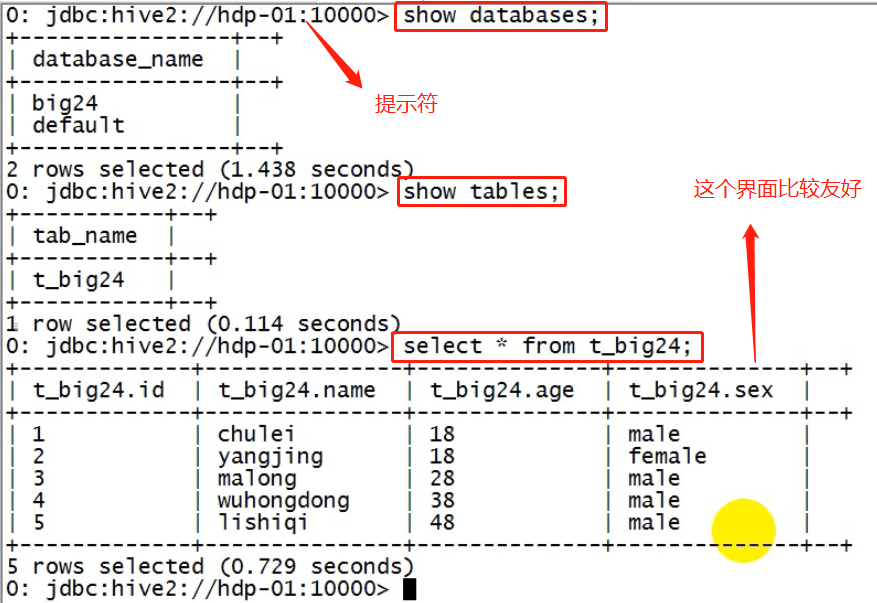
关闭connect,并没有退出客户端

退出hive服务的客户端

4.3、脚本化运行
大量的hive查询任务,如果用交互式shell(hive本身,或者hive服务的客户端都是交互式shell)来进行输入的话,显然效率及其低下,因此,生产中更多的是使用脚本化运行机制:
该机制的核心点是:hive可以用一次性命令的方式来执行给定的hql语句
[root@hdp20-04 ~]# hive -e "insert into table t_dest select * from t_src;"
然后,进一步,可以将上述命令写入shell脚本中,以便于脚本化运行hive任务,并控制、调度众多hive任务,示例如下:
vi t_order_etl.sh
#!/bin/bash hive -e "select * from db_order.t_order" hive -e "select * from default.t_user" hql="create table default.t_bash as select * from db_order.t_order" hive -e "$hql"
4.3.1、hive -e
hive -e:这是linux命令,而不是hive交互式shell,用来执行hive脚本;压根不会进入hive的命令提示符界面,运行结束后回到linux的命令提示符中,这样可以将很多hive操作,写入一个脚本中。
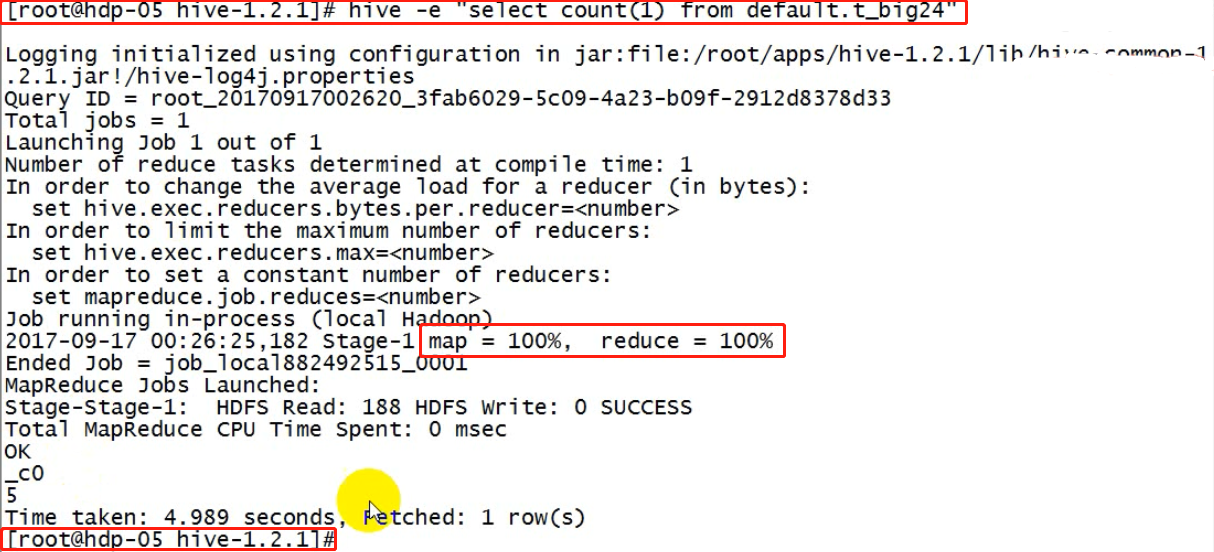
例如:
把一张表中的数据查出来,插入到另外的一张数据表中
sql语法:
create table tt_A(......) insert into tt_A select a,b,c form tt_B ....
新建脚本

执行脚本

查看hive中的结果
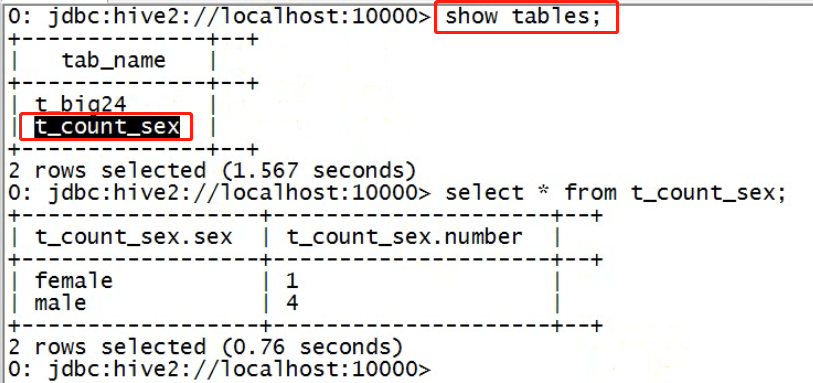
查看hdfs中的结果


4.3.2、hive -f
如果要执行的hql语句特别复杂,那么,可以把hql语句写入一个文件:
vi x.hql
select * from db_order.t_order; select count(1) from db_order.t_user;
然后,用hive -f /root/x.hql 来执行
例子:
vi test.hql


4.3.3、区别
语法不一样
hive -e “sql脚本”
sql太复杂是可以将sql语句写到脚本中,用hive -f来执行。
共同点:
将hive查询语句写到shell脚本。
下面系统学习一下hive的语法(sql的语法极其相似)
5、hive建库建表与数据导入
5.1、建库
hive中有一个默认的库:
库名: default
库目录:hdfs://hdp20-01:9000/user/hive/warehouse
新建库:
create database db_order;
库名:库建好后,在hdfs中会生成一个库目录(库名.db):
库目录:hdfs://hdp20-01:9000/user/hive/warehouse/db_order.db
5.2、建表
5.2.1. 基本建表语句
use db_order; create table t_order(id string,create_time string,amount float,uid string);
表建好后,会在所属的库目录中生成一个表目录
/user/hive/warehouse/db_order.db/t_order
只是,这样建表的话,hive会认为表数据文件中的字段分隔符为 ^A
正确的建表语句为:
create table t_order(id string,create_time string,amount float,uid string) row format delimited fields terminated by ',';
这样就指定了,我们的表数据文件中的字段分隔符为 ","
5.2.2. 删除表
drop table t_order;
删除表的效果是:
hive会从元数据库中清除关于这个表的信息;
hive还会从hdfs中删除这个表的表目录;
细节:
内部表和外部表的删除过程略有不同
内部表:hdfs表目录在warehouse/dbname.db/tableName,数据会放在该目录下(默认:hive中建立的表是映射hdfs的warehouse下的数据)
外部表:外部表可以任意指定表目录的路径,hive里面直接建立一张表去映射该目录下的数据;hive各种操作生成的新表可以是内部表这样就会放到hive默认的数据仓库目录里面,
hdfs表目录不在warehouse;数据不放在该目录下,而是任意目录,因为我们的数据采集程序不一定会把数据直接采集到hdfs下的warehouse中。此时我们也需要在hive找建立一张元数据表和这个hdfs目录进行映射。
外部表的优点:
1、方便
2、避免移走数据从而干扰采集程序的逻辑。
5.2.3. 内部表与外部表
内部表(MANAGED_TABLE):表目录按照hive的规范来部署,位于hive的仓库目录/user/hive/warehouse中
外部表(EXTERNAL_TABLE):表目录由建表用户自己指定
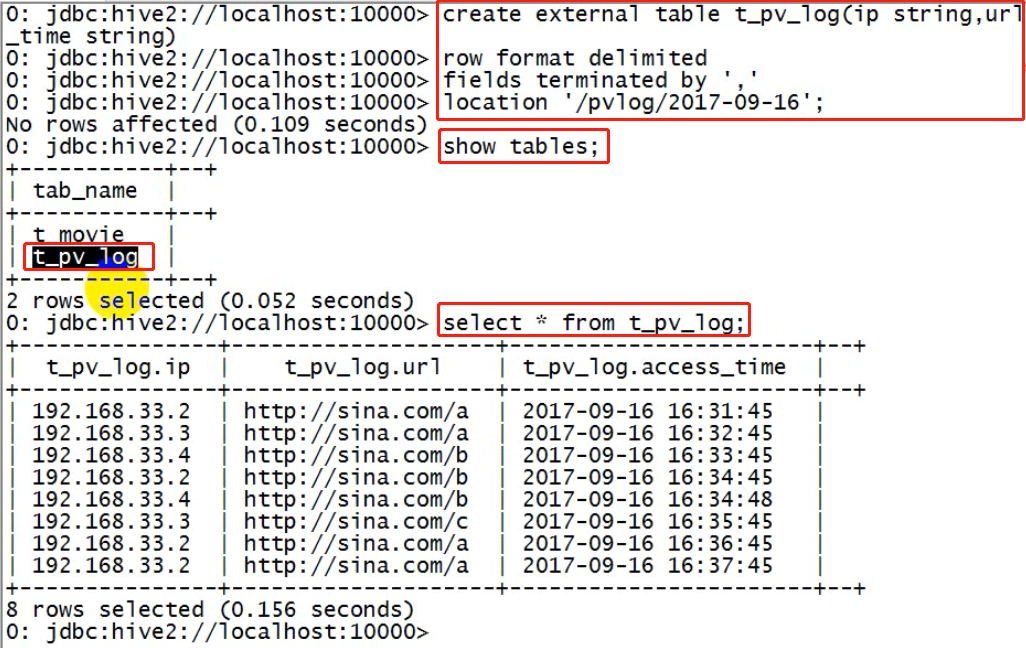
create external table t_access(ip string,url string,access_time string) row format delimited fields terminated by ',' location '/access/log';
外部表和内部表的特性差别:
1、内部表的目录在hive的仓库目录中 VS 外部表的目录由用户指定
2、drop一个内部表时:hive会清除相关元数据,并删除表数据目录
3、drop一个外部表时:hive只会清除相关元数据;
外部表的作用:对接最原始的数据目录,至于后面查询生成的新表,用内部表就好。
一个hive的数据仓库,最底层的表,一定是来自于外部系统,为了不影响外部系统的工作逻辑,在hive中可建external表来映射这些外部系统产生的数据目录;
然后,后续的etl操作,产生的各种表建议用managed_table
演示:
原始数据
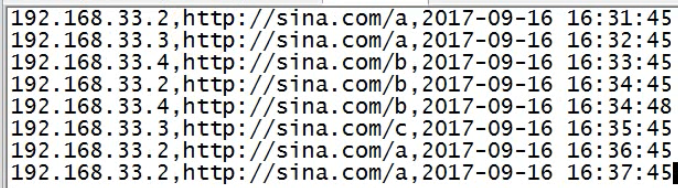
原始数据上传到hdfs非hive数据仓库目录


为了分析数据,需要在hive中建立一张外部表和数据目录进行映射(映射关系:靠元数据来描述)