本系列是本人对Hive的学习进行一个整理,主要包括以下内容:
1.HiveQL学习笔记(一):Hive安装及Hadoop,Hive原理简介
2.HiveQL学习笔记(二):Hive基础语法与常用函数
3.HiveQL学习笔记(三):Hive表连接
4.HiveQL学习笔记(四):Hive窗口函数
5.HiveQL学习笔记(五):Hive练习题
接下来对第一个内容进行介绍。说明:本系列主要是Hive的使用,其他Hadoop和Hive的原理仅做简单的描述。
文章参考资料来自:
https://www.bilibili.com/video/BV1L541147tw?p=50
https://www.bilibili.com/video/BV1W4411B7cN?from=search&seid=7987144426054669652
Hive安装
由于Hive在安装前需要安装很多东西,比如虚拟机,Linux系统,Hadoop,MySQL等,这个过程及其繁琐和艰难。由于目的是学习如何使用Hive,而不是搞大数据开发,因此没必要深陷其中。
这里推荐厦大林子雨老师的博客,里面已经安装好了全套的大数据软件,只需要自己安装虚拟机,然后导入即可,非常方便,可以立即展开学习。大数据Linux实验环境虚拟机镜像文件_林子雨
Hadoop原理简介
1.Hadoop是什么
Hadoop是为了解决大数据的存储和计算问题而开发出来的。

关键词:Hadoop是分布式系统。
2.Hadoop生态系统

hadoop:分布式系统框架
hive:数据仓库
mahout:算法库
storm:分布式实时计算框架
hbase:分布式实时列式存储数据库
3.Hadoop架构和组件
hadoop1.x和2.x的区别:
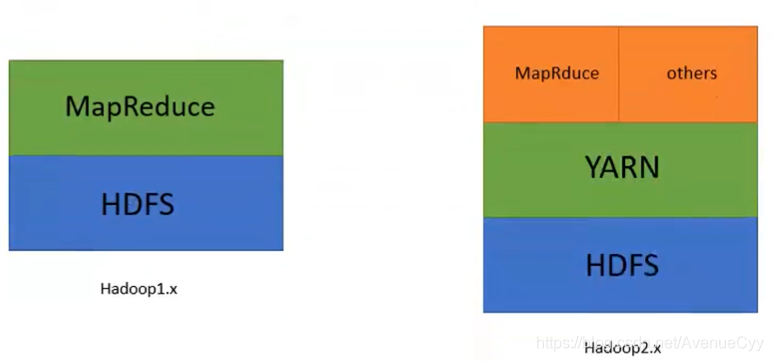
HDFS:分布式文件系统(数据存储)
YARN:资源调度器
MapReduce:分布式计算框架(数据计算 )
4.HDFS分布式文件系统
什么是分布式
单机结构:一个人干一个活(干活的类别一样)
集群结构:很多人干一个活(干活的类别一样)
分布式:很多人干不一个活(干活的类别不一样,分工明确)
什么是文件系统

用户创建一个文件,然后这个文件系统去帮忙干活,记录文件名,大小,位置,占用空间等。
5.HDFS核心设计
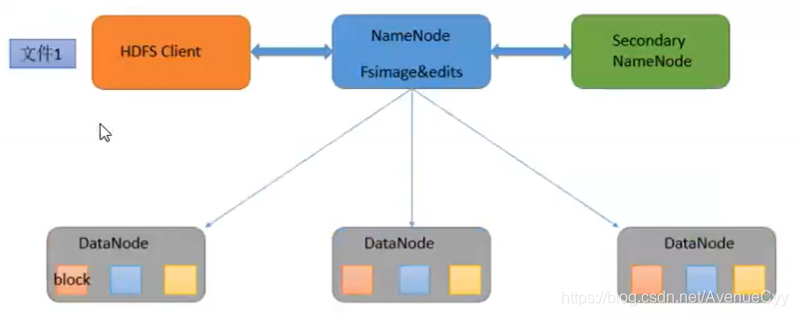
采用分而治之的策略,一个文件分别存储在不同的节点上。
6.HDFS体系结构
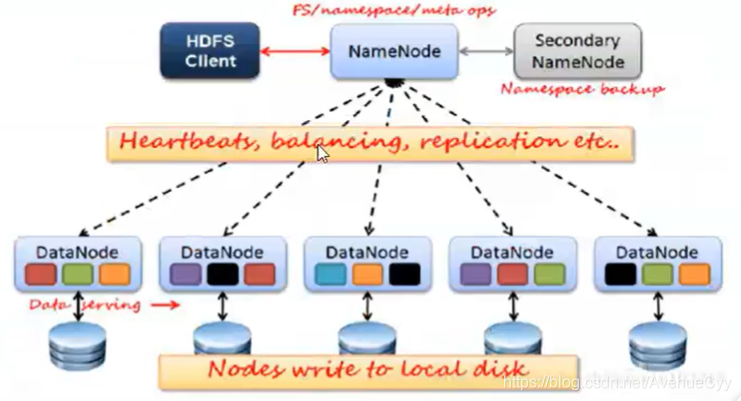
- HDFS Client:客户端,用来操作这个系统的入口。
- NameNode:主节点,接收客户端的读写请求,管理从节点,分配资源,向从节点发送任务。
- NameNode的三种机制:
1.心跳:检查从节点是否还在运行,没有运行的将其任务分配给其他从节点。
2.负载均衡:防止计算/存储资源的不均衡。
3.备份:将其中一个节点的数据在别的节点行进行备份,如图中节点中的黑色方块。
- NameNode的三种机制:
- DataNode:从节点,数据的存储和计算
- Secondary NameNode:辅助,帮NameNode减轻工作压力。
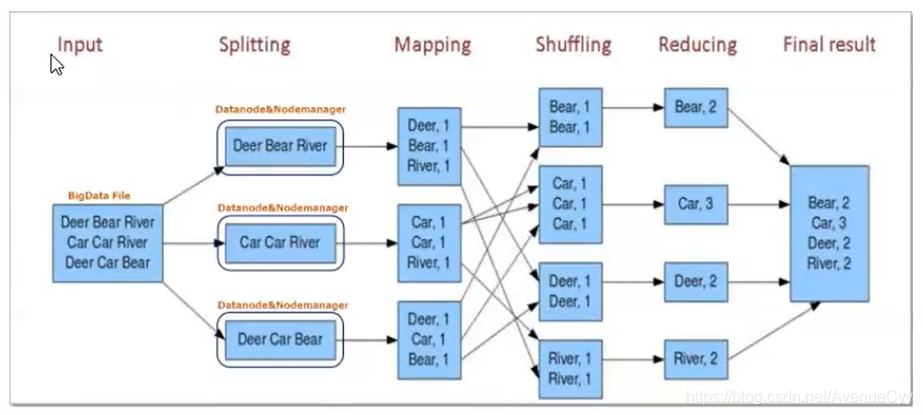
7.MapReduce分布式计算框架



MapReduce编程模型:
8.Hadoop常用命令
hadoop fs所有的文件系统都可以使用
hdfs dfs仅针对hdfs文件系统(hdfs:代表要操作的文件系统,dfs操作命令)


这里的命令跟Linux很像。
数据仓库Hive
1.Hive基本概念

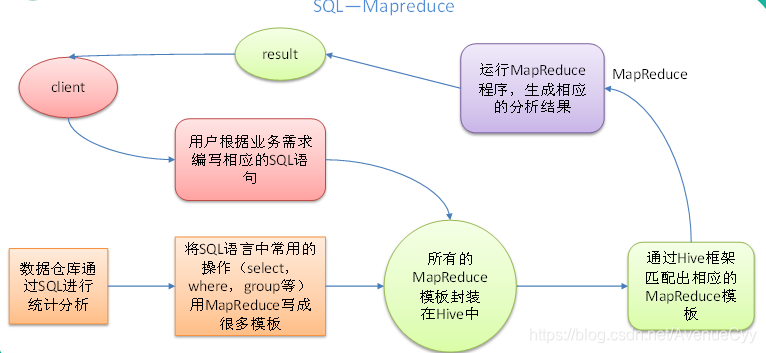
先简单理解,Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,从数据仓库中取数用的,并提供类SQL查询功能,让MapReduce操作可以用SQL语句实现。
本质是:将HQL转化成MapReduce程序
1)Hive处理的数据存储在HDFS
2)Hive分析数据底层的实现是MapReduce
3)执行程序运行在Yarn上
Hive的优缺点
- 优点
1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
2)避免了去写MapReduce,减少开发人员的学习成本。
3)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
4)Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。 - 缺点
1)Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2)Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
Hive架构原理
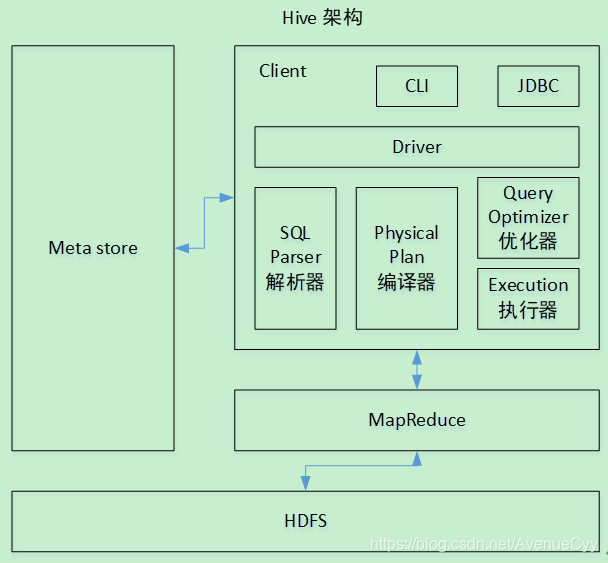
- 1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive) - 2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore - 3.Hadoop
使用HDFS进行存储,使用MapReduce进行计算。 - 4.驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
2.数据仓库与数据库的区别

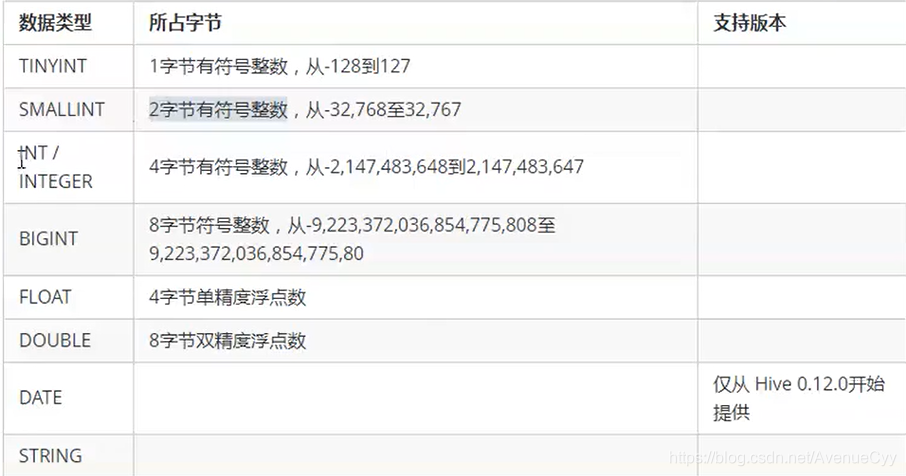
3.Hive数据类型
基本数据类型
复杂数据类型

array:有序数组,其中数据类型必须一致。
map:键值对。键的类型必须相同,值的类型也必须相同。
struct:类似于数组,但是数据类型可以不一致。
4.创建数据库
语法:

例子:

5.使用数据库
语法:
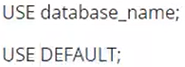
例子:

6.删除数据库
语法:

例子:
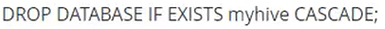
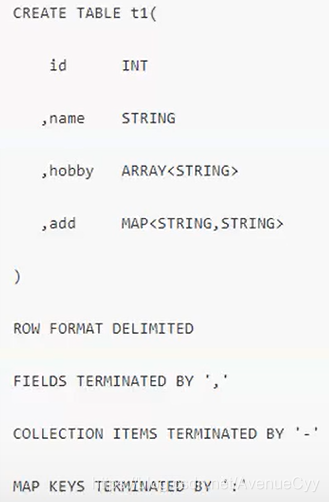
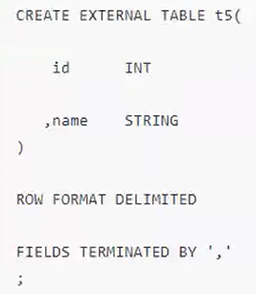
7.创建数据表
直接建表法
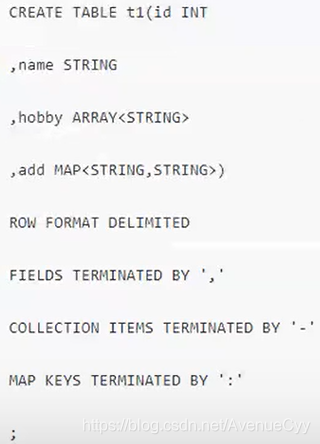
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’:字段之间按逗号分隔;
COLLECTION ITEMS TERMINATED BY ‘_’:array和struct中的元素,按照下划线分隔;
MAP KEYS TERMINATED BY ‘:’:map中的键值对按照冒号进行分隔。
查询建表法:

like建表法:
语法:

例子:

8.管理表(内部表),外部表,分区表
内部表:删除表的时候HDFS上的数据也会删除。
外部表:删除表的时候HDFS上的数据不会删除。
分区表:关系型数据库中的索引作用,不用对所有表进行查看

9.修改表
修改表名:

修改列名:
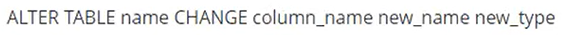
增加列:

10.删除表
语法:

例子:

11.插入数据

从本地导入到hive表:

从hdfs导入到hive表:
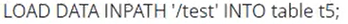
12.导出数据
保存到本地:

保存到hdfs:
