版权声明:欢迎转载,注明出处即可 https://blog.csdn.net/yolohohohoho/article/details/87627127
Hive架构图
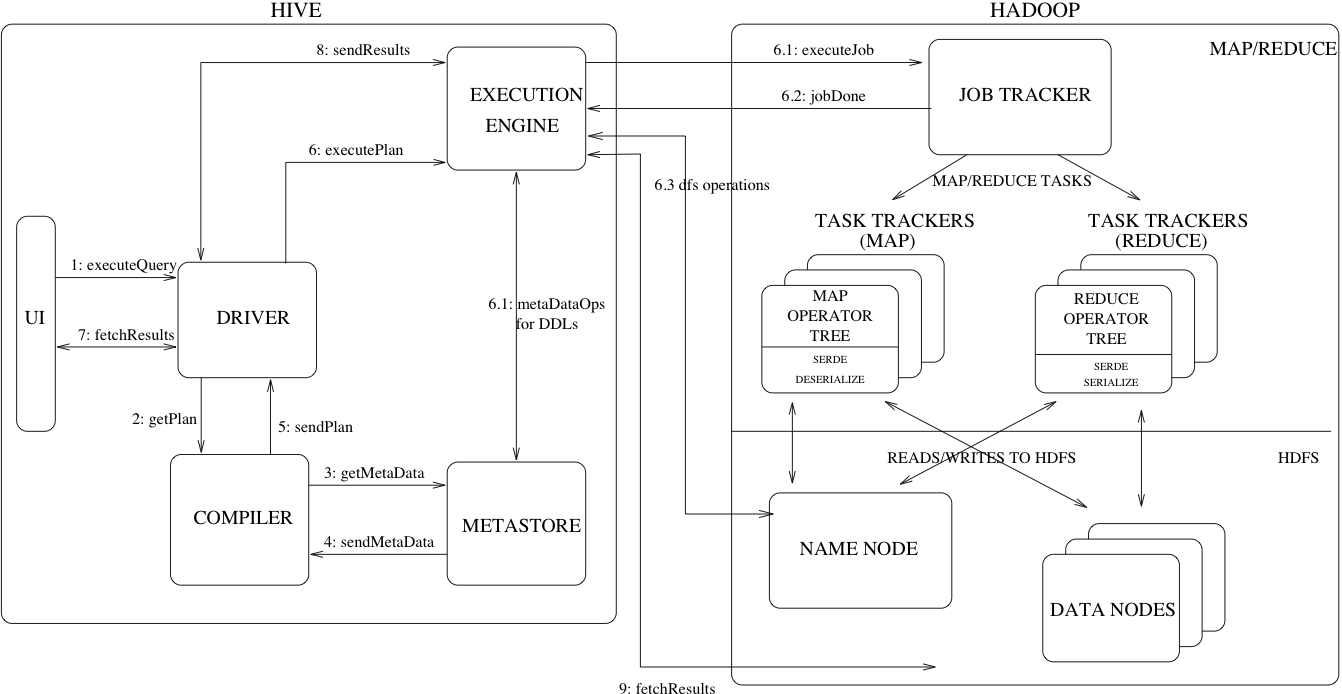
Hive主要组件
- UI 用户界面
用户通过用户界面(CLI或则Web UI)向系统提交查询或者其他操作 - Driver 驱动器
接受查询的组件,提供了JDBC/ODBC接口。 - Compiler 编译器
解析查询的组件,对不同的查询块或查询语句进行语义解析,并配合表和分区的元数据生成执行计划。 - Metastore 元数据存储
该组件负责存储所有表和分区的所有结构信息:列和列类型,序列化/反序列化类型,对应存储数据的HDFS文件等 - Execution Engine 执行引擎
该组件执行编译器创建的执行计划。执行计划是由一个个stage组成的DAG。它负责管理这些stages之间的依赖关系,并在适当的系统组建上执行相应stage。
工作原理
- 执行查询:从Hive的UI界面发送查询语句或操作命令给驱动程
- 获得计划:驱动程序请求编译器解析查询语句,检查语法,生成查询计划或所需资源。
- 获取元数据:编译器向元数据存储库请求元数据
- 发送元数据:元数据存储库向编译器发送元数据
- 发送计划:编译器检查所需资源,并把查询计划发送给驱动器
- 执行计划:驱动器向执行引擎发送计划
6.1 执行作业
执行引擎向Namenode上的JobTracker发送作业,JobTracker把作业分配给Datanode上的TaskTracker,开始执行MapReduce作业。
6.1.b
如果是DDL语句,执行引擎会与元数据存储数据库交互,执行元数据操作
6.2
作业完成
6.3
dfs 操作 - 取回结果
[未完待续…]