文章目录
一、数据定义语言(DDL)概述
1、SQL中DDL语法的作用
- 数据定义语言(Data Definition Language,DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言,这些数据库对象包括database(schema)、table,view,index等;
- DDL核心语法由CREATE(创建),ALTER(修改)与DROP(删除)三个所组成。DDL并不涉及表内部数据的操作;
- 在某些上下文中,该术语也称为数据描述语言,因为它描述了数据库表中的字段和记录。
2、Hive中DDL语法的使用
- Hive SQL(HQL)与标准SQL的语法大同小异,基本相通,注意差异即可;
- 基于live的设计、使用特点,HQL中create语法(尤其create table)将是学习掌握Hive DDL语法的重中之重;建表是否成功直接影响数据文件是否映射成功,进而影响后续是否可以基于SQL分析数据。
二、建表语法

注意事项:
- 蓝色字体是建表语法的关键字,用于指定某些功能;
- [ ]中括号的语法表示可选;
- | 表示使用的时候,左右语法二选一;
- 建表语句中的语法顺序要和语法树中顺序保持一致。
三、Hive数据类型
1、整体概述
(1)Hive数据类型是指表中列的字段类型;
(2)整体分为:原生数据类型(primitive data type)和复杂数据类型(complex data type)两类,其中:
- 原生数据类型包括:数值类型、时间日期类型、字符串类型、杂项数据类型;
- 复杂数据类型包括:array数组、map映射、struct结构、union联合体。
2、数据类型的注意事项
- Hive SQL中,数据类型英文字母大小写不敏感;
- 除SQL数据类型外,还支持Java数据类型,比如字符串string;
- 复杂数据类型的使用通常需要和分隔符指定语法配合使用;
- 如果定义的数据类型和文件不一致,Hive会尝试隐式转换,但是不保证成功。
转换类型:
(1)转换与标准的SQL相似,支持隐式和显式类型转换;显式类型转换使用CAST()函数;
(2)原生类型从窄类型到宽类型的转换称为隐式转换,反之,则不允许。
四、Hive读写件机制
1、SerDe
(1)SerDe是Serializer、Deserializer的简称,目的是用于序列化和反序列化。其中序列化是对象转化为字节码的过程;而反序列化是字节码转换为对象的过程。
(2)Hive使用SerDe(包括FileFiormat)读取和写入表行对象。需要注意的是,"key"部分在读取时会被忽略,而在写入时key始终是常数。基本上行对象存储在"value"中。
(3)可以通过desc formatted tablename查看表的相关SerDe信息。
2、Hive读写件流程
(1)Hive读取文件机制:
- 首先调用InputFormat(默认Text InputFormat),返回一条一条kv键值对记录(默认是一行对应一条键值对);
- 然后调用SerDe(默认LazySimpleSerDe)的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
(2)Hive写文件机制:
- 将Row写入文件时,首先调用SerDe(默认LazySimpleSerDe)的Serializer将对象转换成字节序列;
- 然后调用OutputFormat将数据写入HDFS文件中。
3、SerDe相关语法
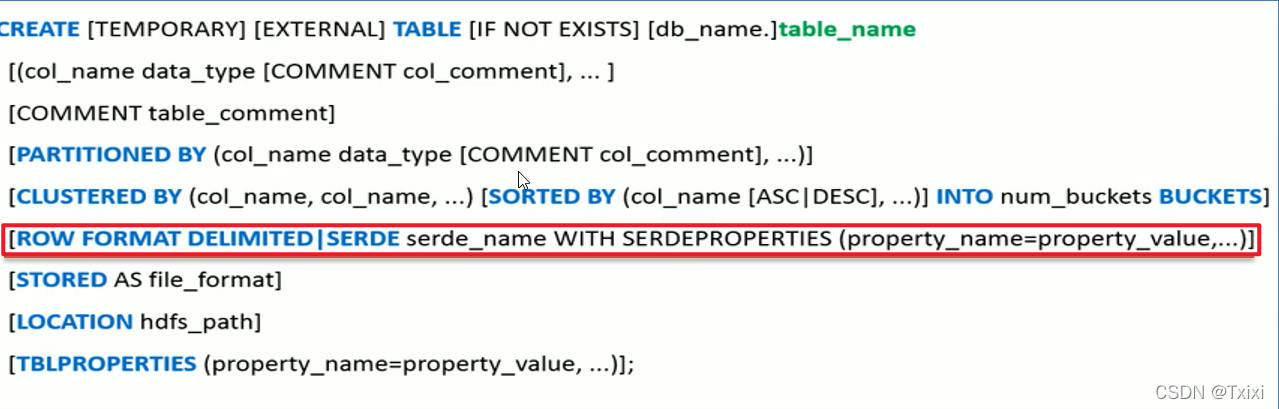
SerDe相关语法就是上图红色框ROW FORMAT这一行所代表的是跟读写文件、序列化SerDe相关的语法,功能有二:
(1)使用哪一个SerDe类进行序列化;
(2)如何指定分隔符。
根据上图:
(1)ROW FORMAT是语法关键字,DELIMITED和SERDE二选其一。
(2)如果使用delimited表示使用默认的LazySimpleSerle类来处理数据。
(3)如果数据文件格式比较特殊可以使用ROW FORMAT SERDE serde_name指定其他的Serde类来处理数据,甚至支持用户自定义SerDe类。
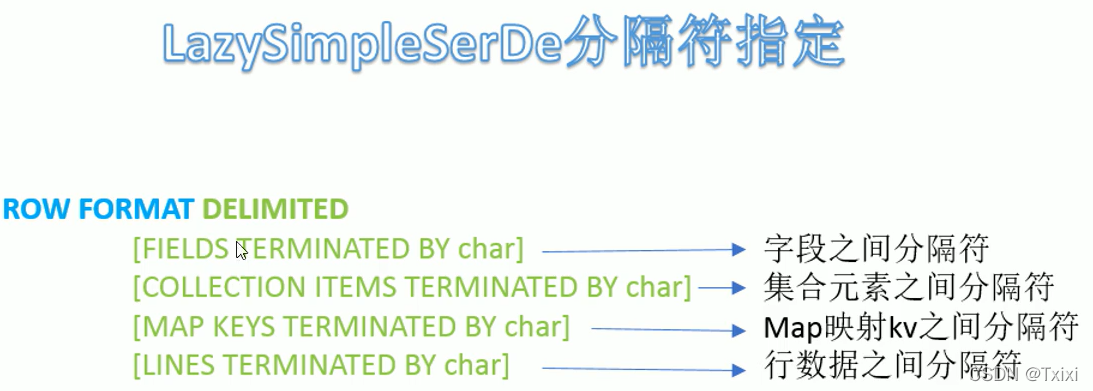
其中: LazySimpleSerDe分隔符指定
(1)LazySimpleSerDe是Hive默认的序列化类,包含4种子语法,分别用于指定字段之间、集合元素之间、map映射kv之间、换行的分隔符号。
(2)在建表的时候可以根据数据的特点灵活搭配使用。