简介
Hive 是一个离线数据数据仓库工具,用于解决海量结构化数据的日志的数据统计,其作用将结构化的数据文件映射成一张数据库表,并能提供简单的 SQL 的查询功能。Hive 的本质是将 HQL 语句转化为 MapReduce,所以其依赖于 HDFS,但是计算处理却依赖于 MapReduce。
- hive 是通过类 SQL 来分析数据,从而避免写 java 程序代码;
- hive 不具备存储数据的功能,其主要依赖 hdfs存储数据,这点与 mysql 不同;
- hive 仅是将数据映射成一张张表;
- hive 适合于离线数据分析,而不适合实时数据分析。
HQL 与 SQL 的区别
| HQL | SQL | |
|---|---|---|
| 数据存储 | HDFS,Hbase | Local FS |
| 数据格式 | 用户自定义 | 系统决定 |
| 数据更新 | 不支持 | 支持 |
| 索引 | 有 | 有 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高(UDF,UDAF,UDTF) | 低 |
| 数据规模 | 大(数据大于 TB) | 小 |
| 数据检查 | 读时模式 | 写时模式 |
Hive 架构
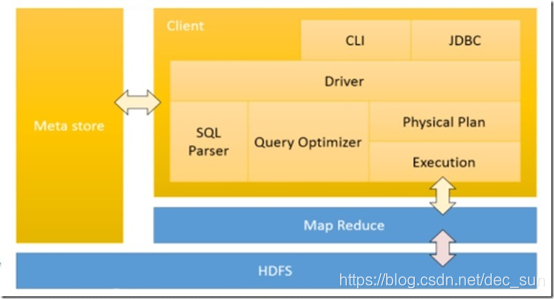
- 用户接口(Client):主要包含 CLI (commad language interface),JDBC 或 ODBC,WEBUI;
- 元数据(metastore):包括表名,表所属的数据库,表的拥有者,列 / 分区字段,表的类型,表的数据所在目录等内容;
- HDFS & MapReduce:Hive 使用 HDFS 进行存储,使用 MapReduce 进行计算;
- 解释器:将 SQL 字符串转化成抽象语法树 AST;
- 编译器:将 AST 编译成逻辑执行计划;
- 优化器:将逻辑执行计划转化成可执行的物理计划,如 MR / Spark
Hive 所有的数据都是存储在 HDFS 文件系统中,由于 HADOOP 由 Java 编写, Hive 中的数据类型也是源于 Java。 Hive 的所有 SQL 分析操作都转换成 MapReduce 中的 Job 任务来处理。所以 Hive 是 HADOOP 的数据仓库,运行 hive 也必须启动 hadoop来支撑存储,否则 hive 启动失败!
基本操作
hive操作
// 启动 hive
./bin/hive
(如果启动失败,可以是因为 hive service 需要启动,需要先执行吓一条命令)
./bin/hive --service metastore &
// 帮助
./bin/hive --help
// 指定默认连接的数据库
hive --database dbName
eg:hive --database db01
// 在 linux 终端中执行 SQL 或者 HQL 语句
hive -e '命令'
eg: hive -e 'show databases'
// 在 linux shell 命令中执行一个写有 SQL 语句的文件
hive -f /opt/app/hive.sql (hive.sql是sql语句文件)
// 使当前 shell 配置临时生效
hive --hiveconf hive.cli.print.current.db=false
数据库操作
// 查看数据库
show databases;
// 使用数据库
use dbname
// 创建 db01 数据库
create database if not exists db01;
// 在 hdfs 上指定目录 “dblocate” 来数据库的目录
create database if not exists db02 LOCATION '/dblocate';
//如果不指定目录,那么数据库的目录为:hdfs: /user/hive/warehouse/。这也是 hive 创建数据库的默认存储路径。
// 如果数据库为空,那么可以采用此命令来删除
drop database db01;
// 如果数据库不为空,那么需要采用如下方式来删除
drop database db01 CASCADE;
表操作
// 建表之前需要指定数据库
use databaseName;
// 与 mysql 一样,创建一个 student 的表,包括两个字段: num,name
create table if not exists student(
num int,
name string
); (第一种创建表方式)
// 设置分隔符, 即导入的数据,以该分隔符一一对应相应的column.所以这个属性需要根据数据来设置.
row format delimited fields terminated by '\t'
eg:
create table if not exists student(
num int,
name string
) row format delimited fields terminated by '\t' stored as textfile; //设置存储格式, 默认为 textfile
// 创建一个与 tb01 一模一样的表
create table tb_name like tb01; (第二种创建表方式)
// 根据 tb01 的某些字段来创建表 tb02
create table table02 as select name from tb01; (第三种创建表方式)
// 根据 tb01 表来创建一个新表 tb02 -- 复制表结构,
create table tb02 like tb01; (第四种创建表方式)
// 删除表
drop table if exists tb01;
// 清空表内容, 但保留表结构
truncate table tb01;
// 查看表
show tables in databaseName;
// 修改表的名称
alter table tableName rename to newTableName;
// 增加列
alter table tableName add columns(col type[int,string]);
// 替换全部的列
alter table tableName replace columns(col1 type1, col2 type2, col3 type3);
// 修改列
alter table tableName change oldColName newColName type;
> 加载数据
// 加载数据, local 表示从本地路径, 必须根据表的格式来处理数据, 特别是 row format delimited fields terminated by '\t' 的属性, 比如 '\t', 数据之间必须是制表符. 否则显示 null。 [overwrite,覆盖重写,之前的 hive 的数据不存在被覆盖了]
load data local inpath '/opt/datas/student.txt' [overwrite] into table tb01;
// 去掉 local,数据时从 hdfs 上加载
load data inpath '/student.txt' into table student;
虽然都是加载数据,但是他们的操作是不同的:本地加载为复制,HDFS加载为数据文件移动到对应的表目录下
// 查询数据
select * from tb01;
// 描述表信息
desc tableName
// 查看函数
show functions
// 描述函数
desc function methodName;
hive 的临时参数设置
set hive.cli.print.current.db=false; # 否显示当前数据库名
set -v # 显示所有设置
set set hive.cli.print.header=true # 显示表头
// 查看本地目录信息
hive -> !ls /; (hive 终端)
// 查看 HDFS 目录信息
hive -> dfs -ls / ;
基本数据类型
| 数据类型 | 长度 | 备注 |
|---|---|---|
| Tinyint | 1字节的有符号整数 | -128 ~ 127 |
| SmallInt | 1字节的有符号整数 | -32768 ~ 32767 |
| Int | 4字节的有符号整数 | -2147483648 ~ 2147483647 |
| BigInt | 8字节的有符号整数 | -9223372036854775808 ~ 9223372036854775807 |
| Boolean | bool类型 | true,false |
| Float | 单精度浮点型 | |
| Double | 双精度浮点型 | |
| String | 字符串 | |
| TimeStamp | 整数 | 支持 unix timestamp |
| Binary | 字节数组 | |
| Date | 日期 | 可用 String 代替 |