Hive是建立在Hadoop上的数据仓库基础框架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),可以使用HiveSQL这种类SQL语句对存储在HDFS上的数据进行查询分析;构建在Hadoop之上,提供对大数据的分析;Hive转换HiveSQL查询为标准的MapReduce jobs(MapReduce上的高度抽象)
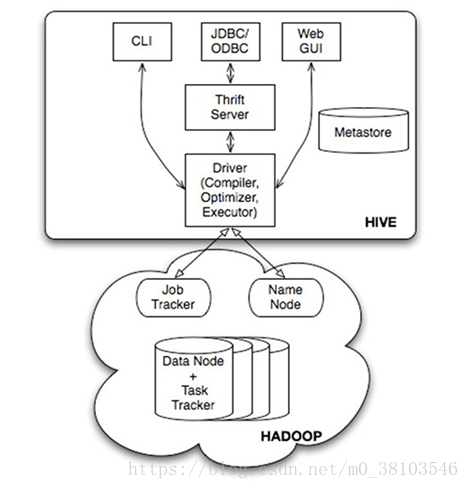
Hive系统架构
提供用户接口,包括CLI,shell命令行,JDBC/ODBC(Hive的Java,与使用传统JDBC的方式类似),WebUI(通过浏览器访问Hive);
Hive将元数据(Hive中创建的数据库和表的信息)存储在数据库中(metastore),目前只支持mysql,derby,Hive元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等;
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并随后有MapReduce调用执行
Hive的数据存储在HDFS中,大部分的查询由MapReduce完成(不包含*的查询,比如select * from table不会生成MapReduce任务)
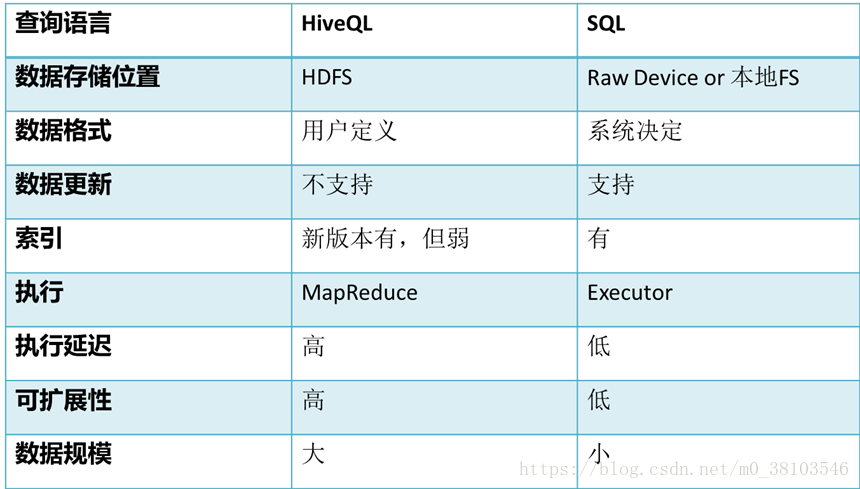
Hive和传统数据库之间的区别
数据类型
基本数据类型
复杂数据类型Array/Map/Struct
没有date/datetime
Hive的数据存储
Hive的数据存储基于Hadoop HDFS
Hive没有专门的数据存储格式
存储结构主要包括:数据库、文件、表、视图
Hive默认可以直接加载文本文件,还支持sequence file、RC file
创建表时,指定Hive数据额列分隔符与行分隔符,Hive即可解析数据
Hive数据模型--表
Table内部表
External Table外部表
指向已经在HDFS中存在的数据,可以创建Partition。它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异。内部表的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据的访问将会直接在数据仓库目录中完成,删除表时,表中的数据和元数据将会被同时删除;外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接;
Partition分区表
Partition对应于数据库的Partition列的密集索引;在Hive中,表中的一个Partition对应于表下的一个目录,所有的Partition的数据都存储在对应的目录中;当表中的数据较多时,可以将其分到不同的表目录中去。
Bucket Table桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储;数据加载到桶表时,会对字段取hash值,然后与桶的数量取模,把数据放到对应的文件中;
Hive使用时,类似于mysql,可以创建数据库和表
Hive创建数据库
create database test 创建的数据库会在HDFS的、user/hive/warehouse/test.db的目录下;所创建的数据库实际上是HDFS下的一个目录,数据库的名称是以元数据的形式存储的。
Hive创建表
创建内部表,语法类似于MySql,create table inner_table(int id, string name) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';创建表的时候,需要指定行的格式化信息,也就是以什么样的分隔符进行分割,因为hive处理的是普通文本数据,但是数据有一定的格式。
加载数据 load data local inpath '/.....' into table inner_table;如果数据在本地,需要加关键字local,如果数据在HDFS,不需要加关键字local;
查看数据 select * from inner_table select count(*) from inner_table;
数据查询的时候会将HQL语句转化为MR程序执行,创建内部表的时候,会在指定的数据库目录下创建一个和表名称相同的目录;外部表和内部表的区别就是数据不在表目录中,类似于表的快捷方式;
创建分区表,当表中的数据较多时,可以将其分到不同的表目录中去,例如对于日志文件log表 、user/hive/warehouse/log/ 分为 /user/hive/warehouse/log/2017-7-1 /user/hive/warehouse/log/2017-7-2
create table partition_table(log string) partitioned by (daytime string) row format delimited fields terminated by '\t' stored as TEXTFILE;
load data local inpath '/home/hadoop/localhost_2017-04-17.txt' into table partition_table partition (daytime='2017-04-13');
hive解析json
首先将解析json的jar包复制到hive的lib下,重新进入hive建表create table user_movie(custid string,movieid string,activity string,recommended string,time string ....)row format serde 'org.openx.data.jsonserde.JsonSerDe' STORED AS TEXTFILE;
Hive查询
ORDER BY与SORT BY的不同
ORDER BY 全局排序,只有一个Reduce任务(多个reducer无法保证全局有序)
SORT BY 不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序
lLimit 可以限制查询的记录数
ldistribute by, 按照指定的字段对数据进行划分到不同的输出reduce 文件中,insert overwrite local directory '/home/hadoop/out' select * from test order by name distribute by length(name); 此方法会根据name的长度划分到不同的reduce中,最终输出到不同的文件中。
lCluster By,cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能,但是排序只能是倒序排序,不能指定排序规则为asc 或者desc。
group by,按照某些字段的值进行分组,有相同值放到一起;select后面非聚合列,必须出现在group by中;select后面除了普通列就是一些聚合操作;group by后面也可以跟表达式,比如substr(col)
select col1 [,col2] ,count(1),sel_expr(聚合操作)from table
where condition -->Map端执行
group by col1 [,col2] -->Reduce端执行
[having] -->Reduce端执行
基于Partition的查询 ,一般 SELECT 查询是全表扫描。但如果是分区表,查询就可以利用分区剪枝(input pruning)的特性,类似“分区索引“”,只扫描一个表中它关心的那一部分。Hive 当前的实现是,只有分区断言(Partitioned by)出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝。例如,如果 page_views 表(按天分区)使用 date 列分区,以下语句只会读取分区为‘2008-03-01’的数据。SELECT page_views.* FROM page_views WHERE page_views.date >= '2013-03-01' AND page_views.date <= '2013-03-01'
LIMIT Clause ,Limit 可以限制查询的记录数。查询的结果是随机选择的。下面的查询语句从 t1 表中随机查询5条记录:
SELECT * FROM t1 LIMIT 5
Top N查询,下面的查询语句查询销售记录最大的 5 个销售代表。SET mapred.reduce.tasks = 1 SELECT * FROM sales SORT BY amount DESC LIMIT 5
表连接
在多表查询的时候,由于表与表之间有关联性,所有hive提供了join的语法,基本类似sql的join语法。主要分为以下五类
内连接(JOIN)
外链接({LEFT|RIGHT|FULL} [OUTER] JOIN)
半连接(LEFT SEMI JOIN)
笛卡尔连接(CROSS JOIN)
其他连接方式(eg. mapjoin等)
内连接(JOIN)主要作用是获取连接的两张表全部匹配的数据,如果不给定join_condition的话,会进行笛卡尔乘积。笛卡尔连接(CROSS JOIN)和内连接语法一样,区别在于:笛卡尔连接是对内连接的一种优化。语法格式为:
table_reference [cross] join table_factor [join_condition]
外连接的主要作用是保留一部分没有匹配的数据。左外连接(LEFT OUTER JOIN)的结果是包括左表中的所有行,如果左表中的某一个行在右表中不存在,那么则在相关联的结果集中右表的所有选择列值均设置为空值。右外连接(RIGHT OUTER JOIN)就是左外连接的反先连接,将返回右表的所有行,左表进行空值填充。全外连接(FULL OUTER JOIN)返回左表和右表的所有行,关联表中没有匹配值的直接设置为空值。语法格式为:table_reference {left|right|full} [outer] join table_factor join_condition
半连接(LEFT SEMI JOIN)是hive特有的,所以hive提供了一个替代方案。需要注意的是,被连接的表(右表),不能出现在查询列/其他部分(where等)中,只能出现在on字句中。(出现也是无效的)。提出半连接的主要作用其实是提高查询效率,真正来讲的话,hive中可以使用其他连接方式来代替半连接,但是就效率而已的话,还是半连接比较高效。语法格式:table_reference LEFT SEMI JOIN table_factor join_condition原来:SELECT a.key, a.value FROM a WHERE a.key in (SELECT b.key FROM B);替换为:SELECT a.key, a.val FROM a LEFT SEMI JOIN b on (a.key = b.key)
mapjoin,如果所有被连接的表都是小表,那么可以使用mapjoin,将需要连接的表数据全部读入mapper端内存中。也就是说你使用mapjoin的前提就是你的连接数据比较小,mapjoin需要和其他join方式一起使用,一般情况下使用mapjoin的时候,推荐使用内连接。语法格式为:select /*+ MAPJOIN(table_ref1) */ ... from table_ref join table_ref1 on ....;
使用join的问题
等值连接:hive中的所有连接条件必须为等值连接条件,不支持<>等非等值连接方式。
多表连接:多表连接的时候,一般先进行left semi join,然后再进行join, 再进行外连接。(减少数据量)。
join过滤条件,可以将where的过滤条件移动到join的过滤条件中去,这样可以减少网络数据量。
join执行顺序都是从左到右,不管是那种join方式,那么一般将大的表放到右边,这样可以节省内存&减少网络传输。
mapjoin只适合连接表是小表的情况,是一种空间换时间的解决方案。
子查询
导Hive对子查询的支持有限,只支持嵌套select子句,而且只能在from和with语句块中使用子查询。语法规则如下
.... from (select statement) [[as] tmp_name]....