1.定义:
在Hadoop上的数据仓库基础架构
2.兼容性:
Hadoop生态圈
3.依赖:
JDK,Hadoop.
4.适用的场景:
hive并不适合那些需要低延迟的应用,例如联机事物处理(OLTP),Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业。
5.Hive原理:
Hive 依赖于 HDFS 存储数据,Hive 将 HQL 转换成 MapReduce 执行,所以说 Hive 是基于 Hadoop 的一个数据仓库工具,实质就是一款基于 HDFS 的 MapReduce 计算框架,对存储在 HDFS 中的数据进行分析和管理。
执行流程:
HiveQL 通过命令行或者客户端提交,经过 Compiler 编译器,运用 MetaStore 中的元数 据进行类型检测和语法分析,生成一个逻辑方案(Logical Plan),然后通过的优化处理,产生 一个 MapReduce 任务。
6.设计特征:
Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。
7.Hive的设计特点:
● 支持索引,加快数据查询。
● 不同的存储类型,例如,纯文本文件、HBase 中的文件。
● 将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
● 可以直接使用存储在Hadoop 文件系统中的数据。
● 内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。
● 类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行
8.体系结构:
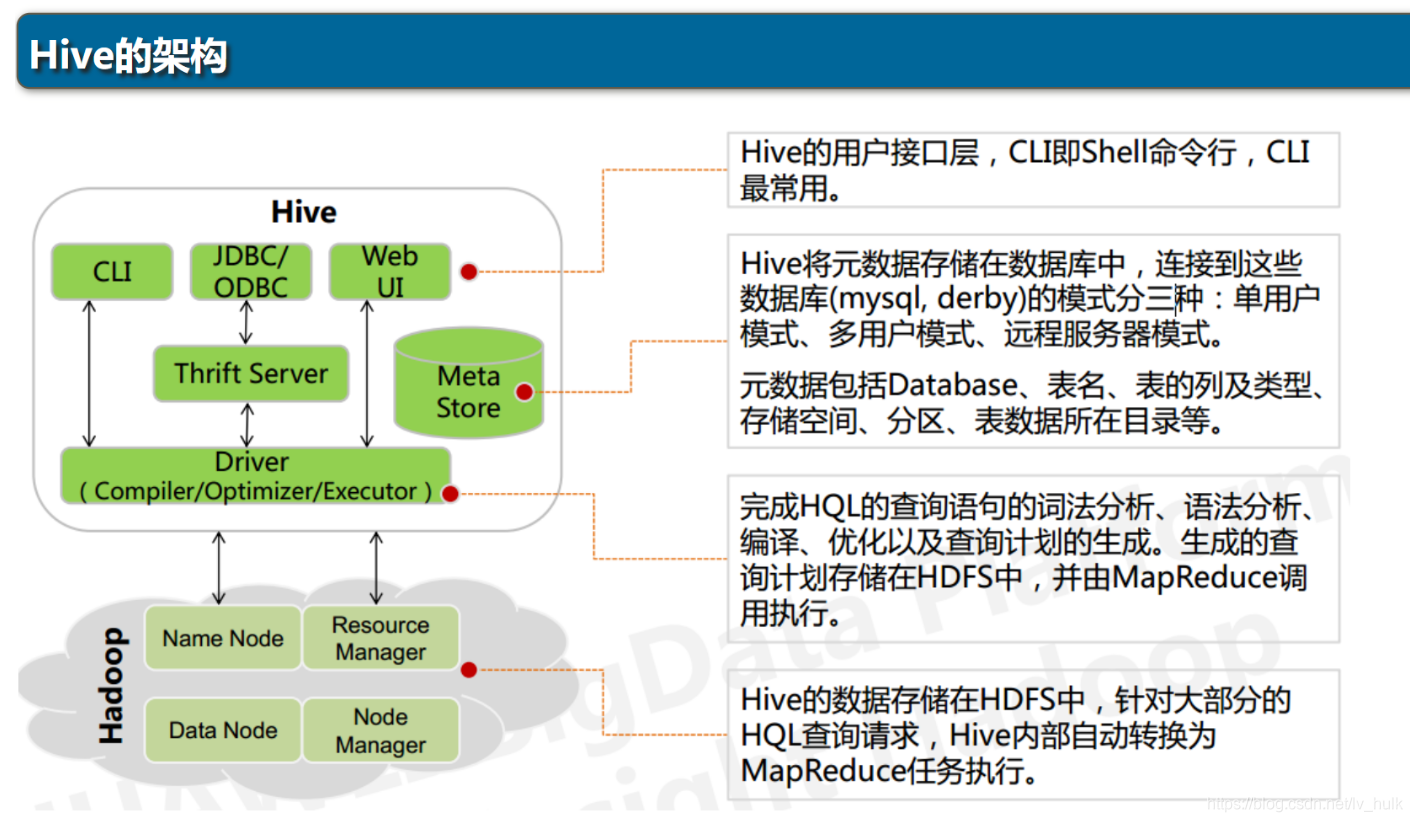
1、用户接口: shell/CLI, jdbc/odbc, webui Command Line Interface
CLI,Shell 终端命令行(Command Line Interface),采用交互形式使用 Hive 命令行与 Hive 进行交互,最常用(学习,调试,生产)
JDBC/ODBC,是 Hive 的基于 JDBC 操作提供的客户端,用户(开发员,运维人员)通过 这连接至 Hive server 服务
Web UI,通过浏览器访问 Hive
2、跨语言服务 : thrift server 提供了一种能力,让用户可以使用多种不同的语言来操纵hive
Thrift 是 Facebook 开发的一个软件框架,可以用来进行可扩展且跨语言的服务的开发, Hive 集成了该服务,能让不同的编程语言调用 Hive 的接口
3、底层的Driver: 驱动器Driver,编译器Compiler,优化器Optimizer,执行器Executor
Driver 组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成逻辑执行 计划的生成。生成的逻辑执行计划存储在 HDFS 中,并随后由 MapReduce 调用执行
Hive 的核心是驱动引擎, 驱动引擎由四部分组成:
(1) 解释器:解释器的作用是将 HiveSQL 语句转换为抽象语法树(AST)
(2) 编译器:编译器是将语法树编译为逻辑执行计划
(3) 优化器:优化器是对逻辑执行计划进行优化
(4) 执行器:执行器是调用底层的运行框架执行逻辑执行计划
4、元数据存储系统 : RDBMS MySQL
元数据,通俗的讲,就是存储在 Hive 中的数据的描述信息。
Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和 外部表),表的数据所在目录
Metastore 默认存在自带的 Derby 数据库中。缺点就是不适合多用户操作,并且数据存 储目录不固定。数据库跟着 Hive 走,极度不方便管理
解决方案:通常存我们自己创建的 MySQL 库(本地 或 远程)
Hive 和 MySQL 之间通过 MetaStore 服务交互
9.数据存储
首先,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织 Hive 中的表,只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
其次,Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
1、Hive 的存储结构包括数据库、表、视图、分区和表数据等。数据库,表,分区等等都对 应 HDFS 上的一个目录。表数据对应 HDFS 对应目录下的文件。
2、Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式,因为 Hive 是读模式 (Schema On Read),可支持 TextFile,SequenceFile,RCFile 或者自定义格式等
3、 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据
Hive 的默认列分隔符:控制符 Ctrl + A,\x01 Hive 的
Hive 的默认行分隔符:换行符 \n
4、Hive 中包含以下数据模型:
**database:**在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
**table:**在 HDFS 中表现所属 database 目录下一个文件夹
**external table:**与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径
**partition:**在 HDFS 中表现为 table 目录下的子目录
**bucket:**在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散 列之后的多个文件
**view:**与传统数据库类似,只读,基于基本表创建
5、Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情 况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的 测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
6、Hive 中的表分为内部表、外部表、分区表和 Bucket 表
内部表和外部表的区别:
删除内部表,删除表元数据和数据
删除外部表,删除元数据,不删除数据
内部表和外部表的使用选择:
大多数情况,他们的区别不明显,如果数据的所有处理都在 Hive 中进行,那么倾向于 选择内部表,但是如果 Hive 和其他工具要针对相同的数据集进行处理,外部表更合适。
使用外部表访问存储在 HDFS 上的初始数据,然后通过 Hive 转换数据并存到内部表中
使用外部表的场景是针对一个数据集有多个不同的 Schema
通过外部表和内部表的区别和使用选择的对比可以看出来,hive 其实仅仅只是对存储在 HDFS 上的数据提供了一种新的抽象。而不是管理存储在 HDFS 上的数据。所以不管创建内部 表还是外部表,都可以对 hive 表的数据存储目录中的数据进行增删操作。
分区表和分桶表的区别:
Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同 时表和分区也可以进一步被划分为 Buckets,分桶表的原理和 MapReduce 编程中的 HashPartitioner 的原理类似。
分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所 以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列 形成的多个文件,所以数据的准确性也高很多
10.hive的数据倾斜
容易数据倾斜情况
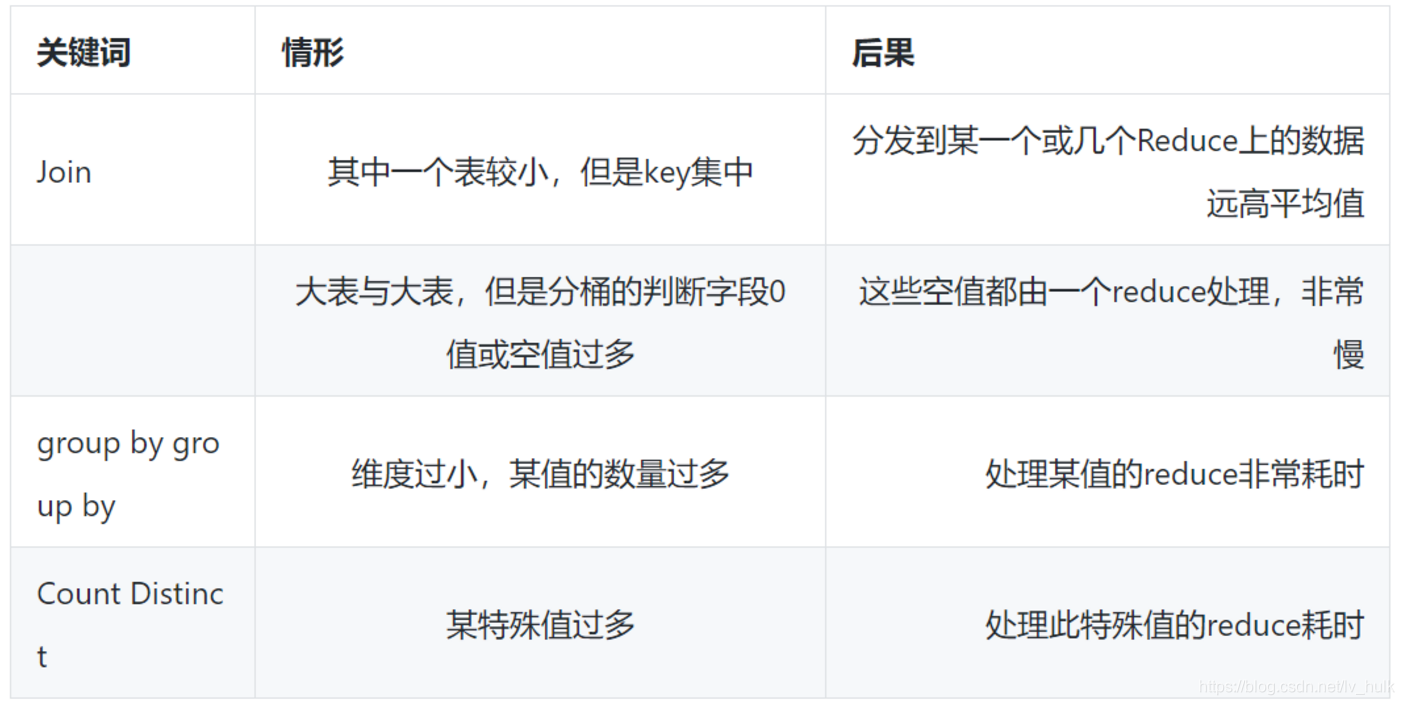
A、group by 不和聚集函数搭配使用的时候
B、count(distinct),在数据量大的情况下,容易数据倾斜,因为 count(distinct)是按 group by 字段分组,按 distinct 字段排序
C、 小表关联超大表 join
产生数据倾斜的原因
A:key 分布不均匀
B:业务数据本身的特性
C:建表考虑不周全
D:某些 HQL 语句本身就存在数据倾斜
11.hive优化
1、join连接时的优化:当三个或多个以上的表进行join操作时,如果每个on使用相同的字段连接时只会产生一个mapreduce。
2、join连接时的优化:当多个表进行查询时,从左到右表的大小顺序应该是从小到大。原因:hive在对每行记录操作时会把其他表先缓存起来,直到扫描最后的表进行计算
3、在where字句中增加分区过滤器。
4、当可以使用left semi join 语法时不要使用inner join,前者效率更高。原因:对于左表中指定的一条记录,一旦在右表中找到立即停止扫描。
5、如果所有表中有一张表足够小,则可置于内存中,这样在和其他表进行连接的时候就能完成匹配,省略掉reduce过程。设置属性即可实现,set hive.auto.covert.join=true; 用户可以配置希望被优化的小表的大小 set hive.mapjoin.smalltable.size=2500000; 如果需要使用这两个配置可置入$HOME/.hiverc文件中。
6、同一种数据的多种处理:从一个数据源产生的多个数据聚合,无需每次聚合都需要重新扫描一次。
例如:insert overwrite table student select * from employee; insert overwrite table person select * from employee;
可以优化成:from employee insert overwrite table student select * insert overwrite table person select *
7、limit调优:limit语句通常是执行整个语句后返回部分结果。set hive.limit.optimize.enable=true;
8、开启并发执行。某个job任务中可能包含众多的阶段,其中某些阶段没有依赖关系可以并发执行,开启并发执行后job任务可以更快的完成。设置属性:set hive.exec.parallel=true;
9、hive提供的严格模式,禁止3种情况下的查询模式。
a:当表为分区表时,where字句后没有分区字段和限制时,不允许执行。
b:当使用order by语句时,必须使用limit字段,因为order by 只会产生一个reduce任务。
c:限制笛卡尔积的查询。
10、合理的设置map和reduce数量。
11、jvm重用。可在hadoop的mapred-site.xml中设置jvm被重用的次数。