文章目录
复习:
- 检查Linux配置
1、防火墙关闭
2、/etc/hosts的IP映射
3、/etc/hostname 主机名
4、ntp时间服务器
5、网卡信息配置 - 检查HDFS\检查YARN\检查MR
export JAVA_HOME
hadoop.env.sh
yarn-env.sh
mapred-env.sh
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-senior01.itguigu.com:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 指定数据冗余份数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-senior03.itguigu.com:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop-senior01.itguigu.com:50070</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-senior02.itguigu.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 任务历史服务 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop-senior01.itguigu.com:19888/jobhistory/logs/</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.adress</name>
<value>hadoop-senior01.itguigu.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.adress</name>
<value>hadoop-senior01.itguigu.com:19888</value>
</property>
</configuration>
准备
slaves
hadoop-senior01.itguigu.com
hadoop-senior02.itguigu.com
hadoop-senior03.itguigu.com
- 检查Maven
1、$ tar -zxf /opt/softwares/apache-maven-3.0.5-bin.tar.gz -C /opt/modules/
2、配置MAVEN_HOME
#MAVEN_HOME
MAVEN_HOME=/opt/modules/apache-maven-3.0.5
export PATH= MAVEN_HOME/bin - 检查离线仓库
1、创建maven默认的离线仓库文件夹.m2
$ mkdir ~/.m2/
2、解压离线仓库到默认位置
$ tar -zxf /opt/softwares/hbase+hadoop_repository.tar.gz -C ~/.m2/ - 检查Eclipse
1、解压安装Eclipse
$ tar -zxf /opt/softwares/eclipse-jee-kepler-SR1-linux-gtk-x86_64.tar.gz -C /opt/modules/
2、配置MAVEN选项
window - preferences - maven - installtions - add - filesystem - 找到你的maven安装路径 - 如何创建Maven项目
1、file - new - maven project - quickstart
2、pom.xml
org.apache.hadoop
hadoop-client
2.5.0
3、创建resource文件夹
右键项目 - new - source folder - src/main/resourece
一键启动/关闭脚本的编写
HDFS
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start namenode
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start datanode
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/hadoop-daemon.sh start secondarynamenode
YARN
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/yarn-daemon.sh start resourcemanager
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/yarn-daemon.sh start nodemanager
HistoryServer
$ /opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/sbin/mr-jobhistory-daemon.sh start historyserver
#!/bin/bash
echo "========正在开启集群服务======"
ech0 "========正在开启 Namenode节点========"
# 意思就是ssh到这个主机上之后执行后面的启动命令,下面同理
ssh admin@hadoop-senior01.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh start namenode`
echo "========在开启 DataNode节点========"
for i in adminghadoop-seniorol.itguigu.com admin@hadoop-senior02itguigu.com adminghadoop-senior03.itguigu.com
do
ssh $i `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh start datanode`
done
echo "========在开启 SecondaryNamenode节点========"
ssh admin@hadoop-senior03.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh start secondarynamenode`
echo "========正在开启 ResourceManager节点========"
ssh admin@hadoop-senior02.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/yarn-daemon.sh start resourcemanager`
echo "========正在开启 NodeManager节点========"
for $i in admin@hadoop-senior0l.itguigu.com admin@hadoop-senior02.itguigu.com admin@hadoop-senior03.itguigu.com
do
ssh i `/opt/modules/cdh/hadoop-2 5 0-cdh5 3 6/sbin/yarn-daemon.sh start nodemanager`
done
echo "========正在开启 JobHistory Server节点========"
ssh adminghadoop-senior01.itguigu.com `/opt/modules/cdh/hadoop-2 5 0-cdh5 3 6/sbin/mr-jobhistory-daemon.sh start historyserver`
#!/bin/bash
echo "========正在关闭集群服务======"
# 意思就是ssh到这个主机上之后执行后面的启动命令,下面同理
echo "========正在关闭JobHistory Server节点========"
ssh adminghadoop-senior01.itguigu.com `/opt/modules/cdh/hadoop-2 5 0-cdh5 3 6/sbin/mr-jobhistory-daemon.sh stop historyserver`
echo "========正在关闭 ResourceManager节点========"
ssh admin@hadoop-senior02.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/yarn-daemon.sh stop resourcemanager`
echo "========正在关闭 NodeManager节点========"
for $i in admin@hadoop-senior0l.itguigu.com admin@hadoop-senior02.itguigu.com admin@hadoop-senior03.itguigu.com
do
ssh i `/opt/modules/cdh/hadoop-2 5 0-cdh5 3 6/sbin/yarn-daemon.sh stop nodemanager`
done
ech0 "========正在关闭 Namenode节点========"
ssh admin@hadoop-senior01.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh stop namenode`
echo "========在关闭 SecondaryNamenode节点========"
ssh admin@hadoop-senior03.itguigu.com `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh stop secondarynamenode`
echo "========在关闭 DataNode节点========"
for i in adminghadoop-seniorol.itguigu.com admin@hadoop-senior02itguigu.com adminghadoop-senior03.itguigu.com
do
ssh $i `/opt/modules/ cdh/hadoop-2 5 0-cdh5 3 6/sbin/hadoop-daemon.sh stop datanode`
done
注意:上面的stop脚本,在start中谁后启动,在stop中谁就先关闭,但是注意ResourceManager和NameNode,中的主节点先关闭,即如先关闭NameNode再关闭DataNode,防止出现先关闭DataNode后,NameNode出现不必要的错误。
如果没有配置java环境变量上面的脚本也是不能运行的。
有shell
粗放来讲,你手动使用CRT登录某个Linux系统时,是有shell的
无shell
当你使用ssh访问某个系统的时候,是无shell的,也就意味着如果使用ssh命令登录到其他系统的时候,是无法加载另一台系统的环境变量的,只能加载哪个用户的用户变量,所以java_home应该配置在用户变量上

//将系统变量里面所有的东西追加到.bashrc中,这里是追加不是覆盖
//每一台机器都执行
//这样每个机器的java环境变量都有了。
cat /etc/profile >> ~/.bashrc
然后将所有机器的所有hadoop服务都关闭掉
sh start-cluster.sh
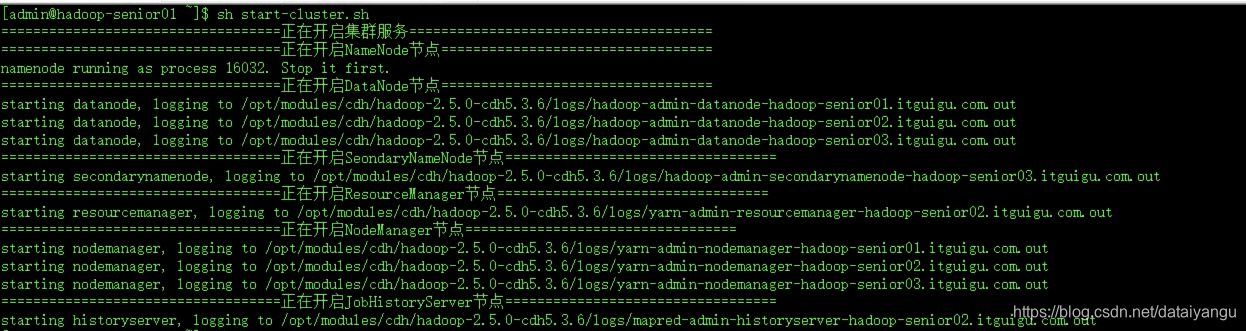
然后到相应的机器上jps看是否开启
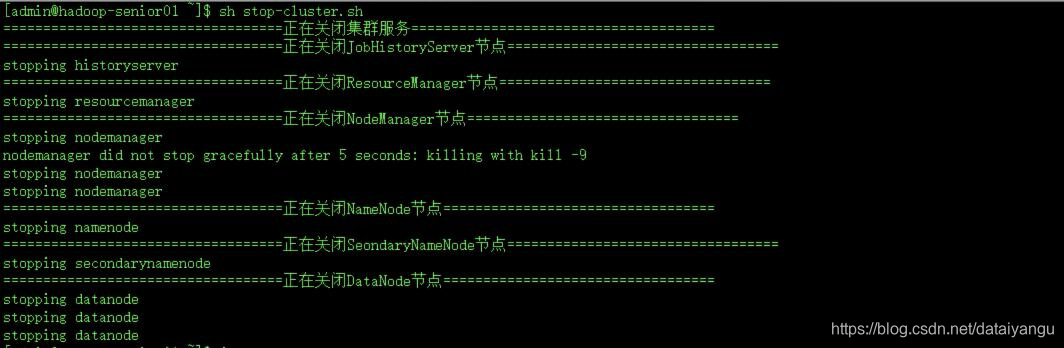
然后到相应的机器上jps看是否关闭