三、Hive高级进阶
1. HiveServer2、Beeline、JDBC的使用
hive是CLI,HiveServer2(HS2)是一种能使客户端执行Hive查询的服务。 HiveServer2是HiveServer1的改进版,需要和beeline结合使用。一个终端启动hiveserver2,另一个终端启动beeline。
启动hiveserver2并用beeline连接:
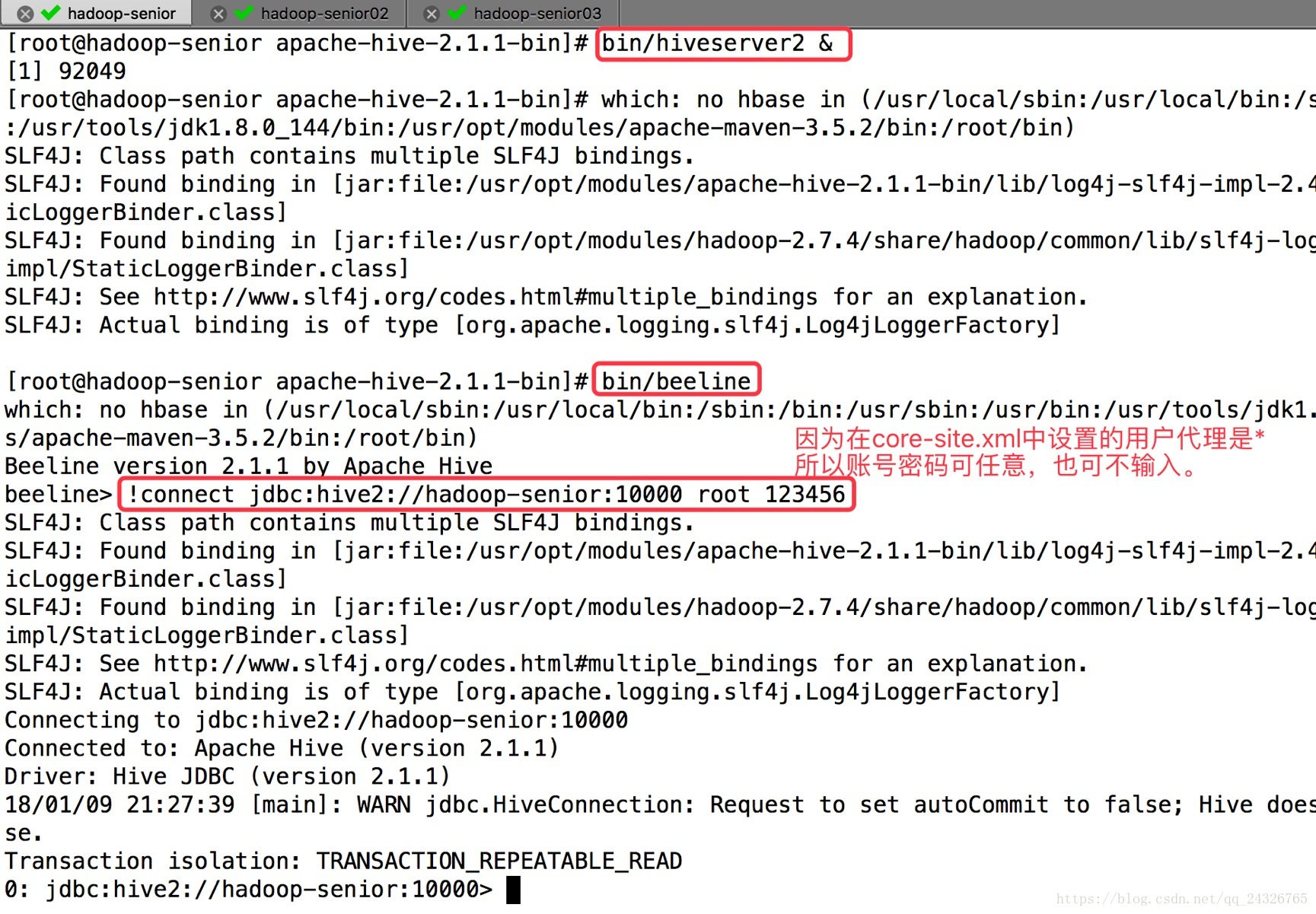
[root@hadoop-senior apache-hive-2.1.1-bin]# bin/hiveserver2 & [root@hadoop-senior apache-hive-2.1.1-bin]# bin/beeline beeline> !connect jdbc:hive2://hadoop-senior:10000 root 123456 |
beeline连接hiveserver2方式二:
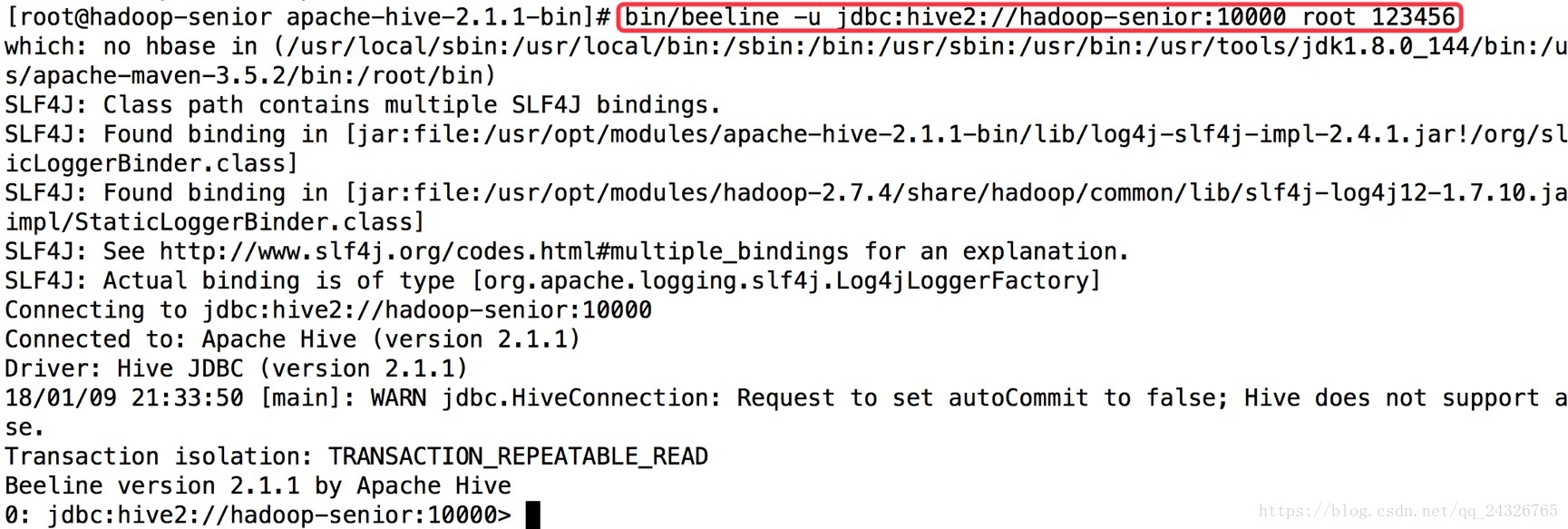
[root@hadoop-senior apache-hive-2.1.1-bin]# bin/beeline -u jdbc:hive2://hadoop-senior:10000 root 123456 |
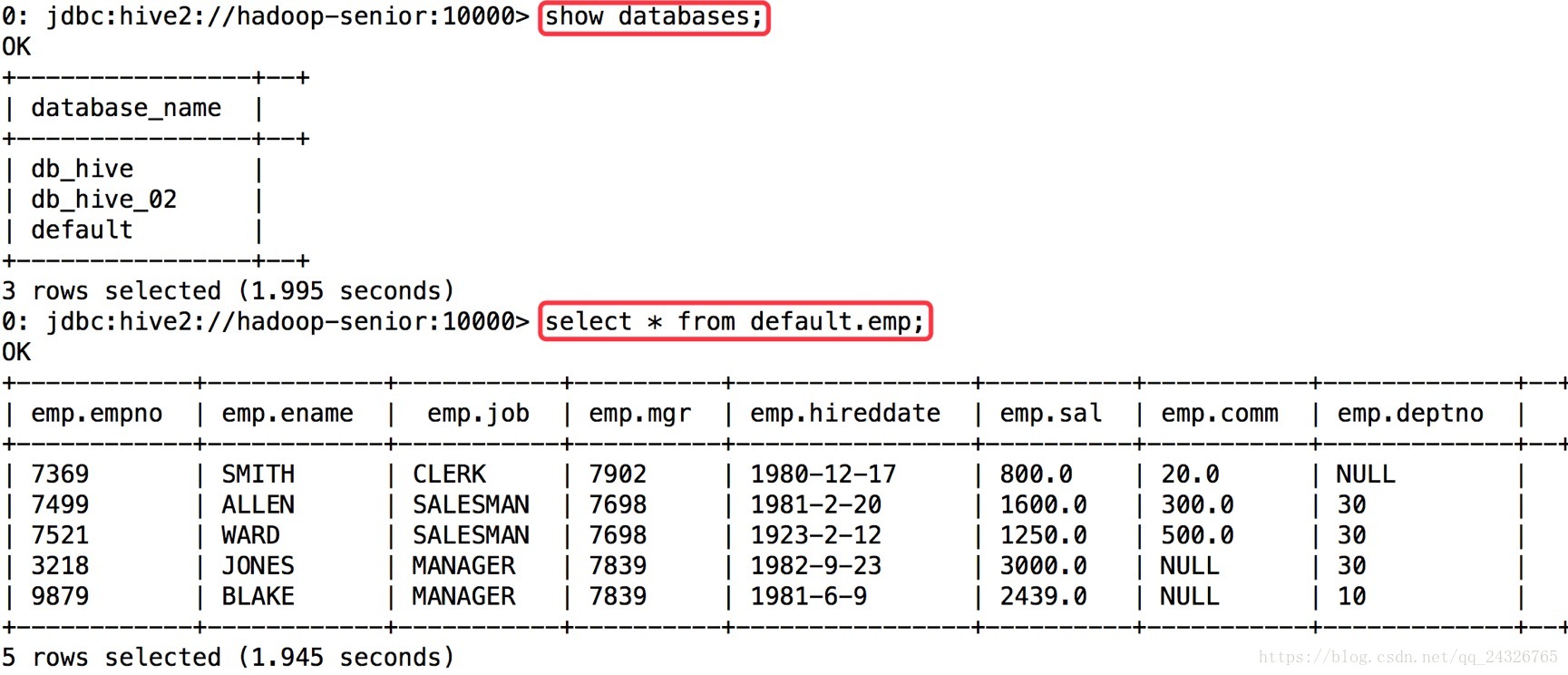
HIVE JDBC:
使用hive或hiveserver2都可以
public class HiveJdbcClient {
private static final String DRIVERNAME = "org.apache.hive.jdbc.HiveDriver";
/**
* @param args
* @throws SQLException
*/
public static void main(String[] args) throws SQLException {
try {
Class.forName(DRIVERNAME);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
Connection con = DriverManager.getConnection("jdbc:hive2://hadoop-senior:10000/default", "root", "123456");
Statement stmt = con.createStatement();
String tableName = "emp";
// 查看所有表
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
ResultSet res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
// 查看表结构
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
// 查询*
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
}
// 查询count(*)
sql = "select count(1) from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
}
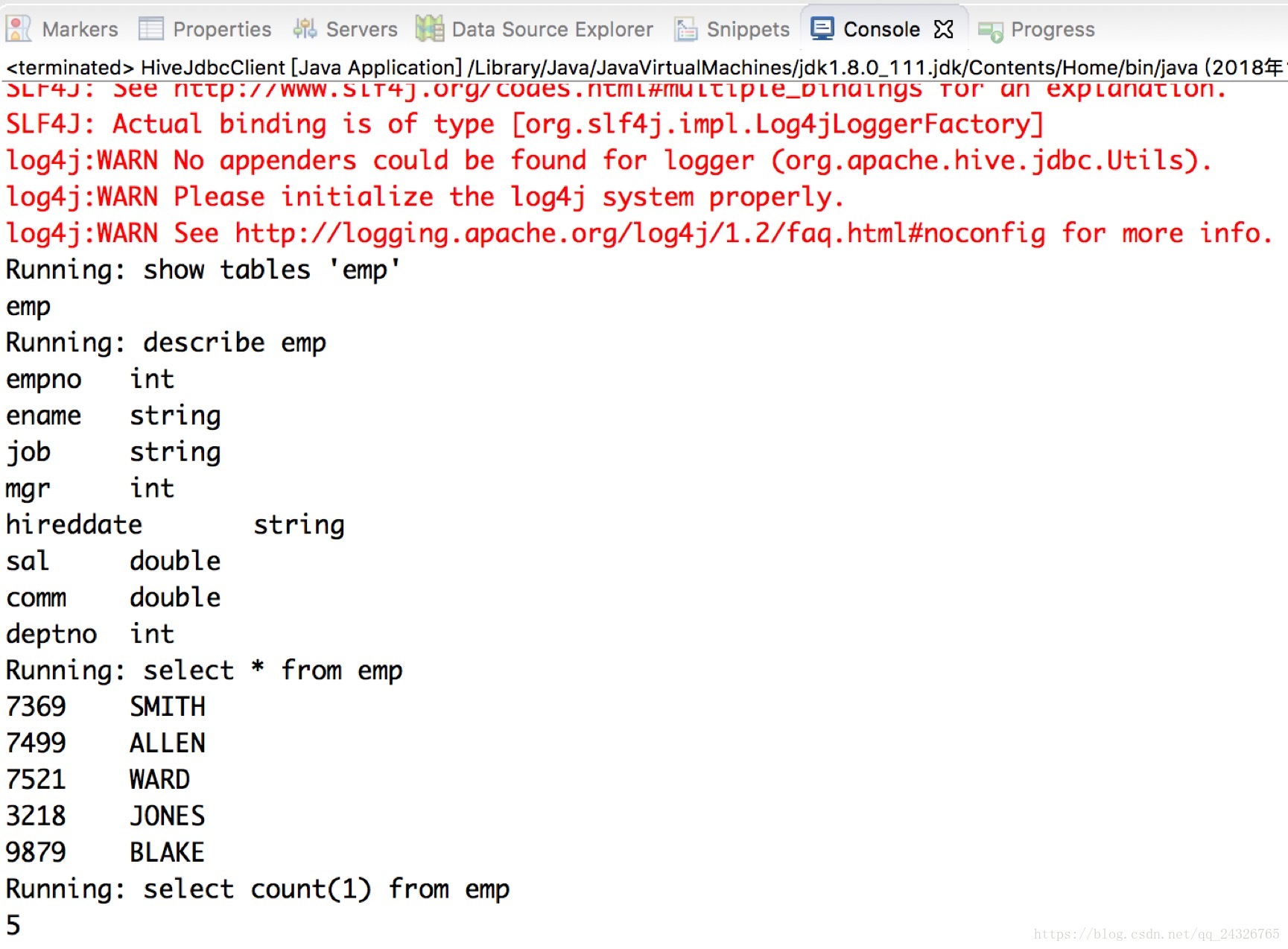
}运行结果:
异常1:
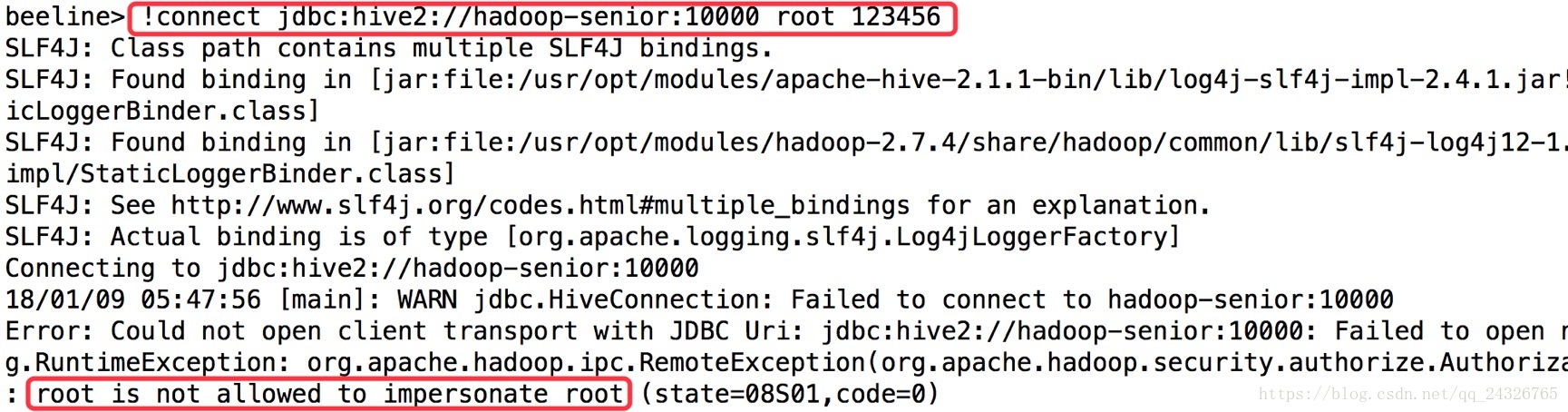
解决:
加上如下配置
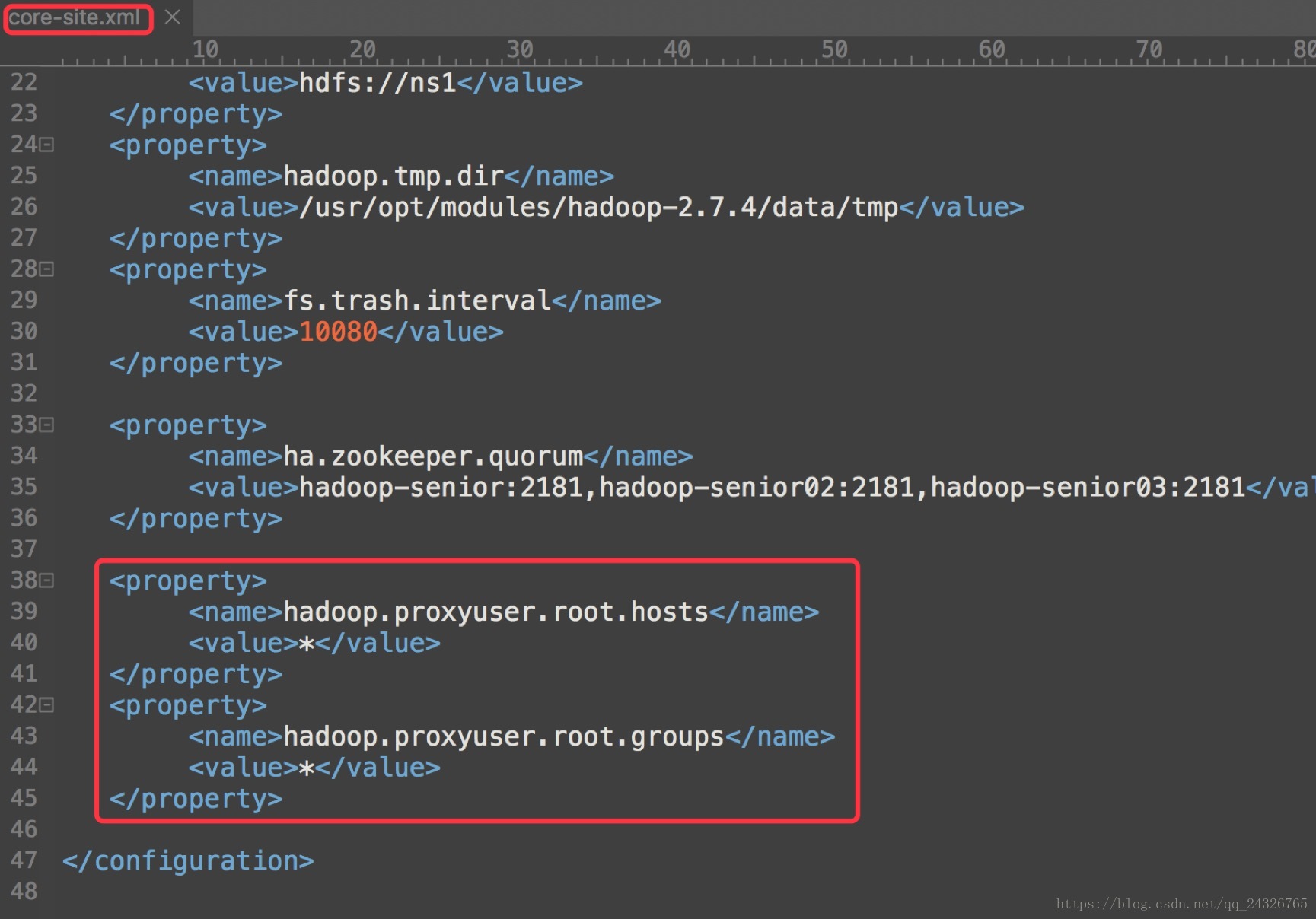
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
异常2:java代码连接hive jdbc报错
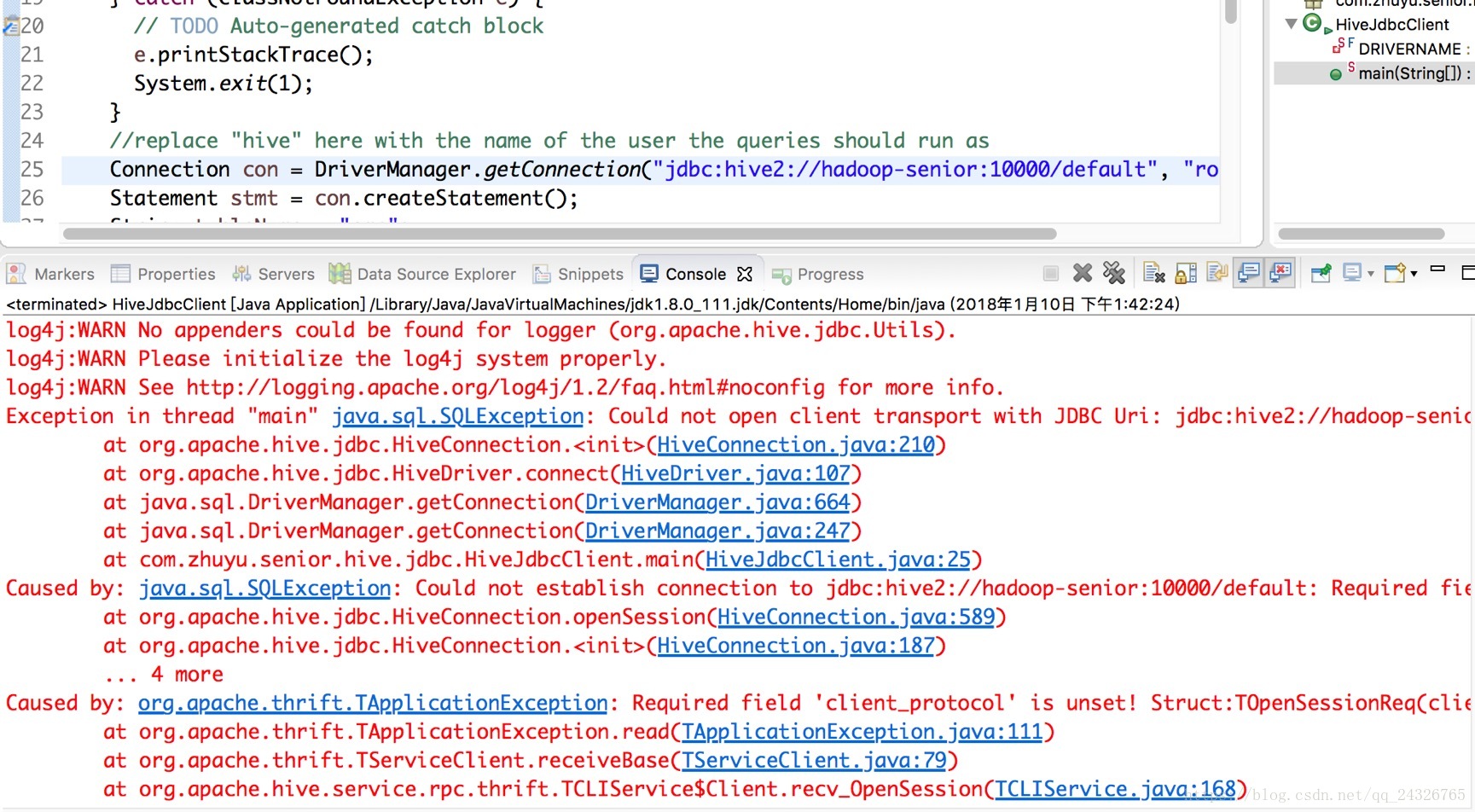
解决:项目中导入的依赖和hive的安装版本不一致。
异常3:
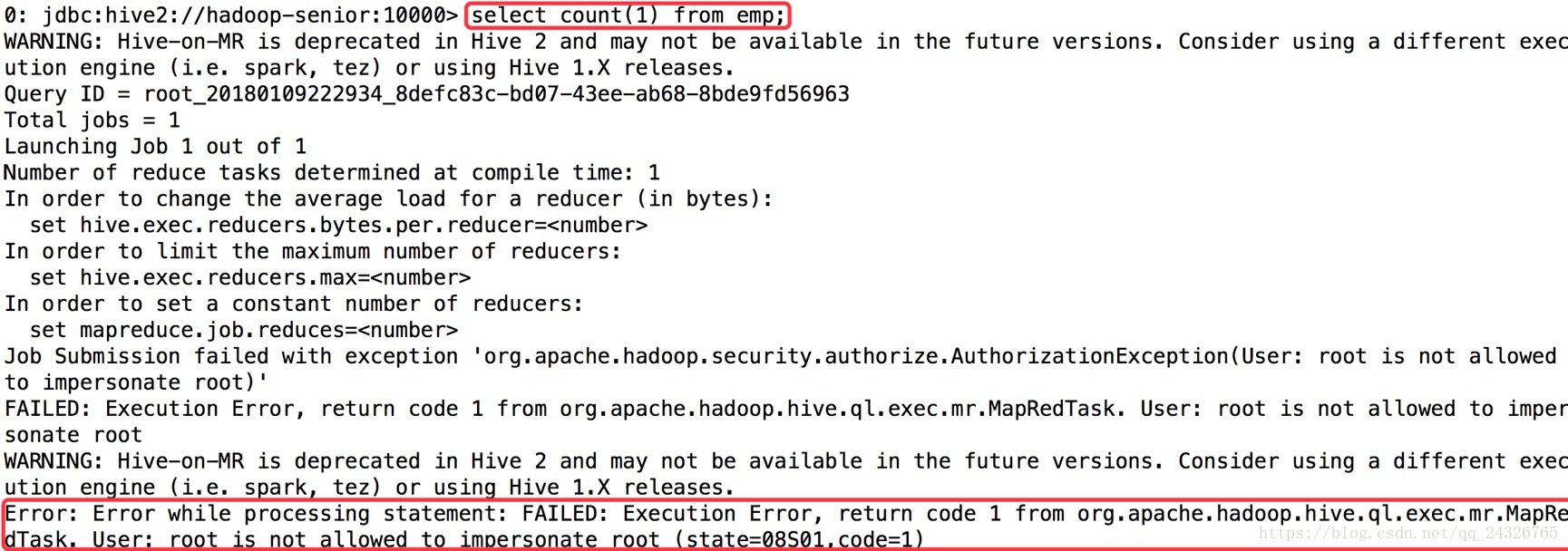
解决:没有将修改的core-site.xml分发到其他节点。
2. Hive中常见的数据压缩
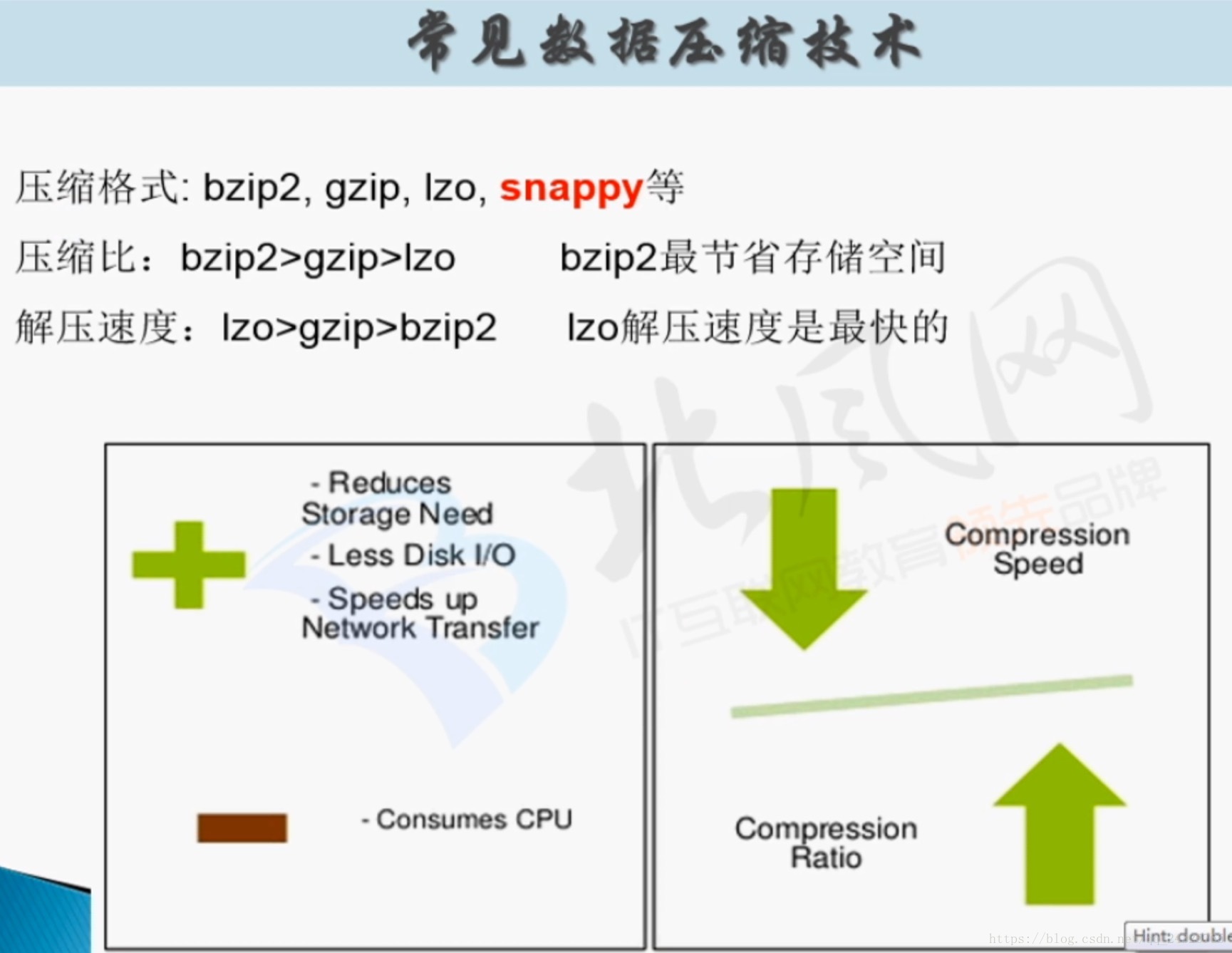
snappy谷歌开源的,解压耗的是CPU。

可分割性指的是:压缩完的分片可单独解压,而是一个大文件,必须所有分割的压缩包同时解压。
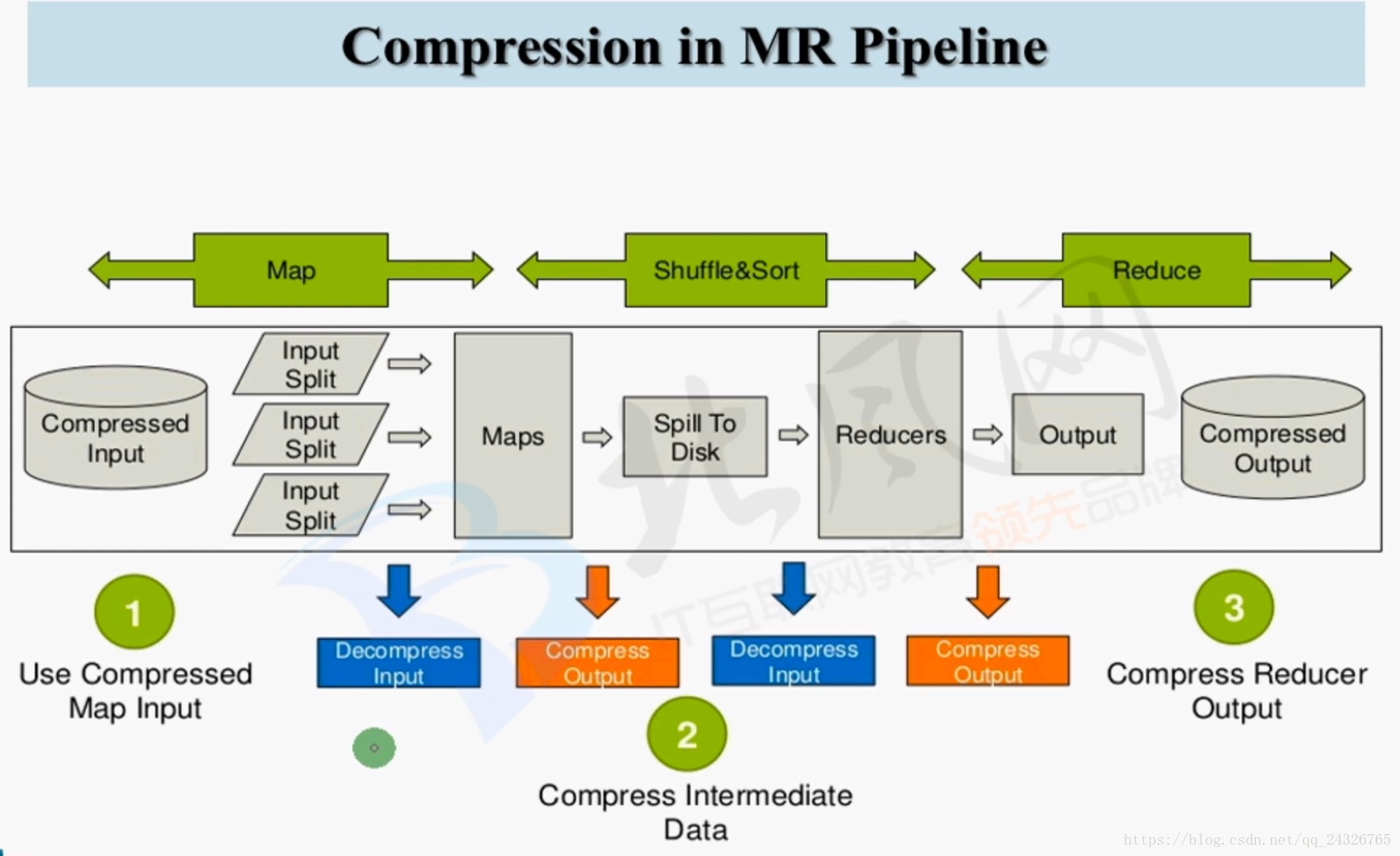
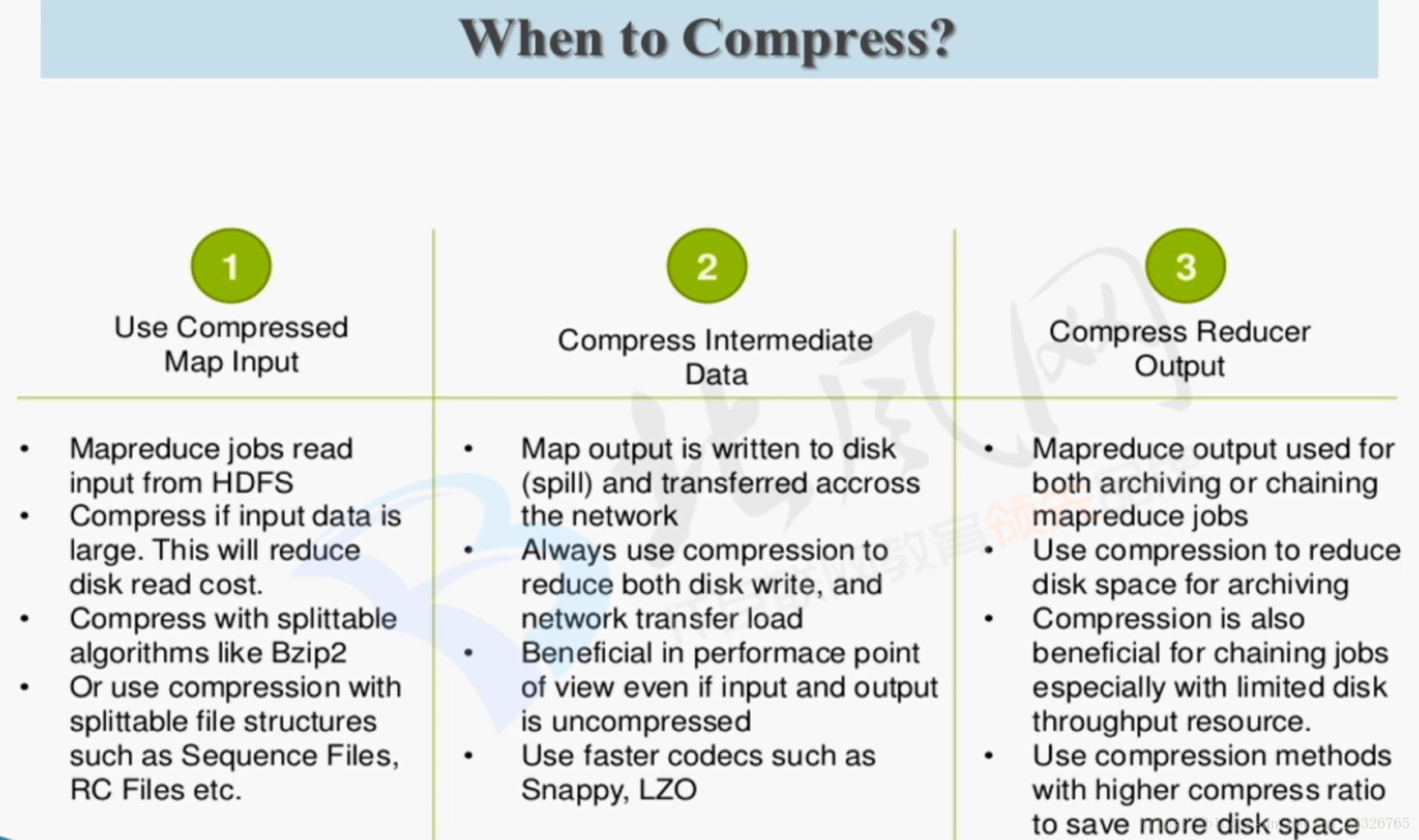



在yarn的管理界面(History)查看job的配置:
查看mapreduce的配置

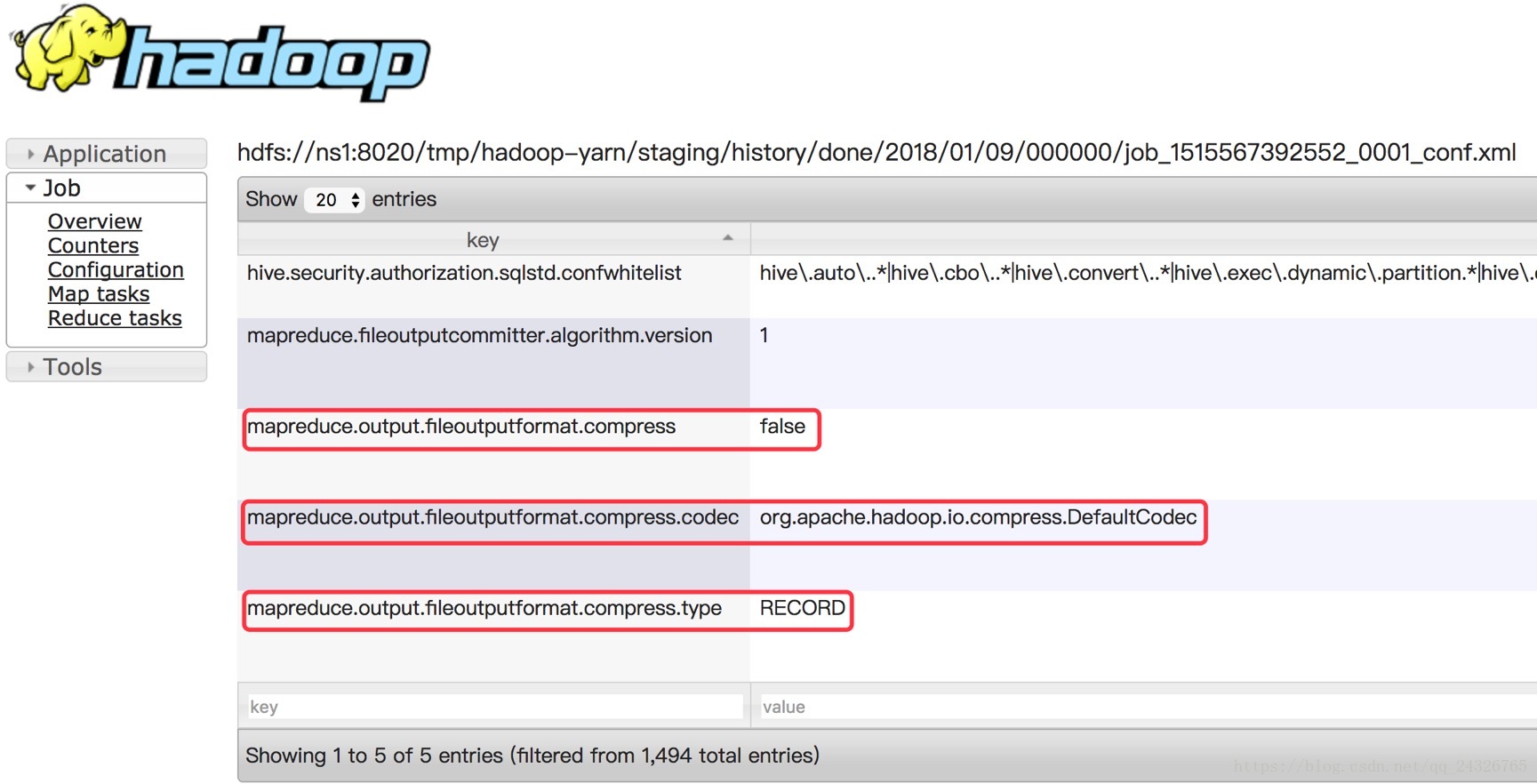
在mapreduce中修改了之后,hive自然也就修改了。因为hive的底层是mapreduce。
查看hadoop支持哪些压缩格式:
在yarn上设置mapreduce加上临时参数:

3. hive数据存储格式
数据存储
* 按行存储数据
* 按列存储数据
file_format:
| SEQUENCEFILE
| TEXTFILE -- (Default, dependingon hive.default.fileformat configuration)
| RCFILE -- (Note:Available in Hive 0.6.0 andlater)
| ORC -- (Note: Available inHive 0.11.0 andlater)
| PARQUET -- (Note:Available in Hive 0.13.0 andlater)
| AVRO --(Note: Available in Hive 0.14.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAToutput_format_classname
按行存储和按列存储的比较:
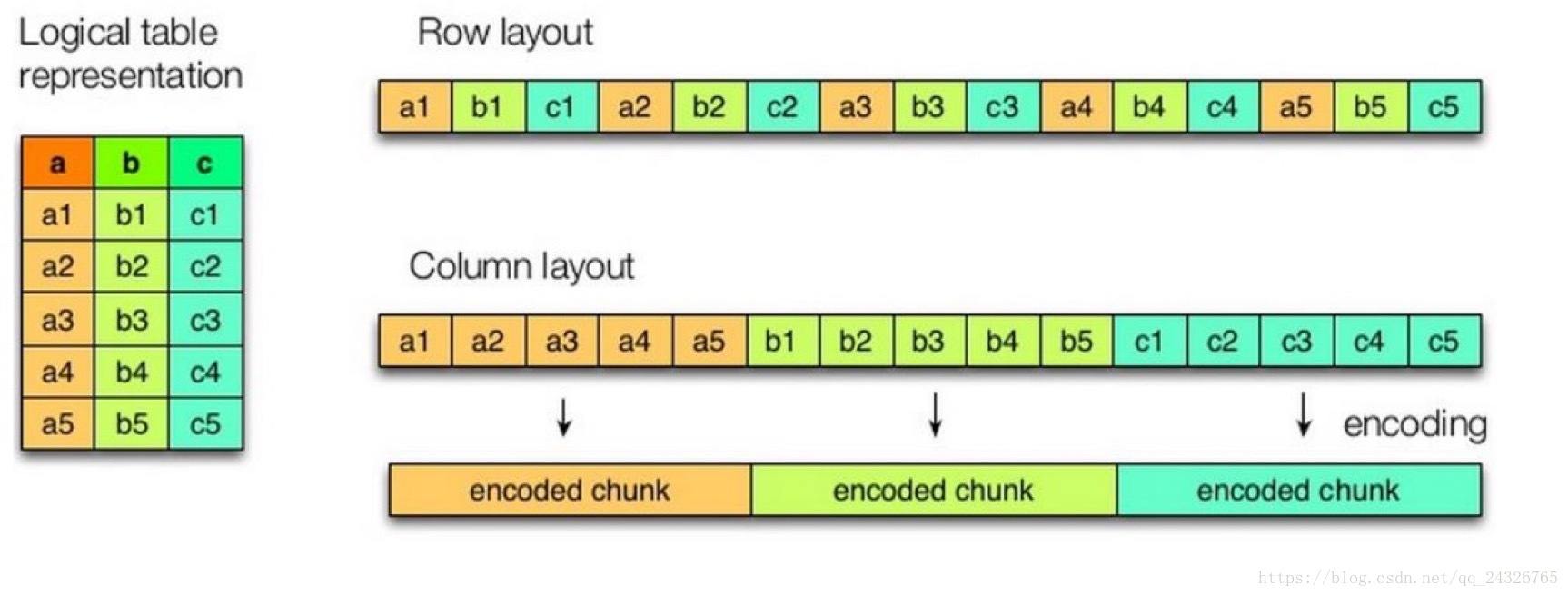
几种压缩格式的比较:


加入了索引,所以查询比较快。
TEXTFILE测试:
create table page_views(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
加载数据

ORC测试:
create table page_views_orc(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS ORC; orc文件如何生成?
insert into table page_views_orc select * from page_views;3个job:select+orc格式转换+insert。
PARQUET测试:
create table page_views_parquet(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS PARQUET; 如何生成parquet文件?
insert into table page_views_parquet select * from page_views;对比生成的文件大小:
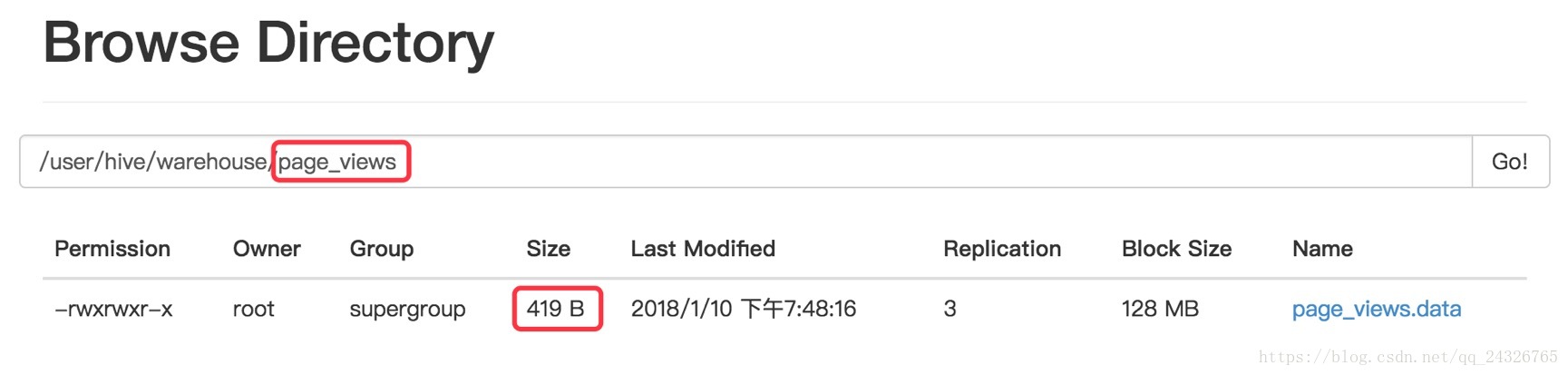
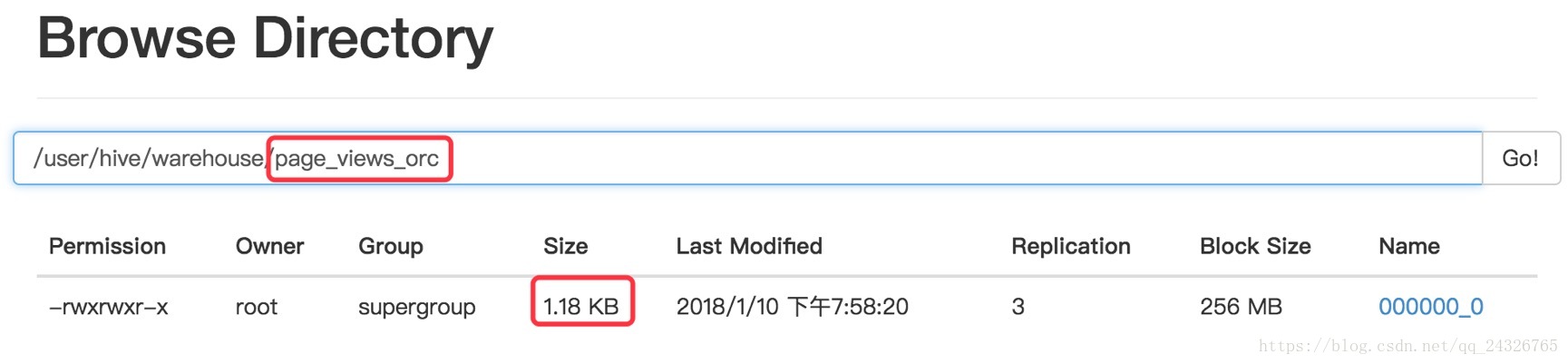
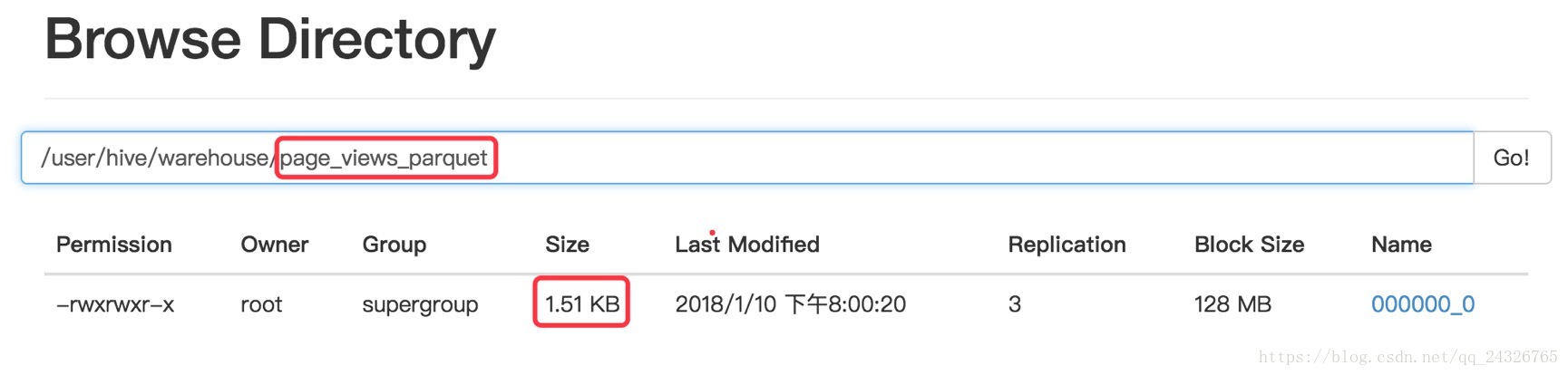
测试查询效率:
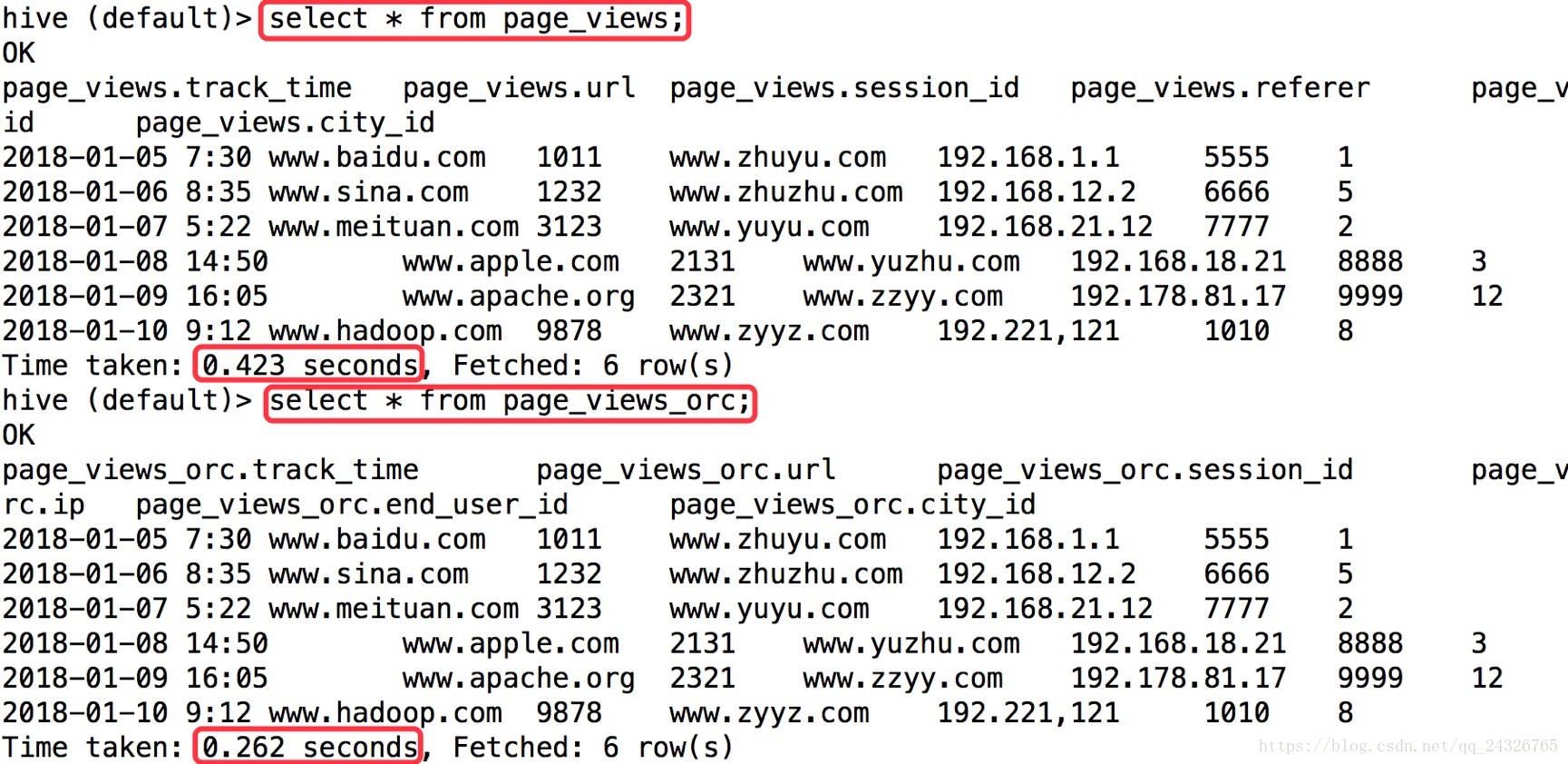
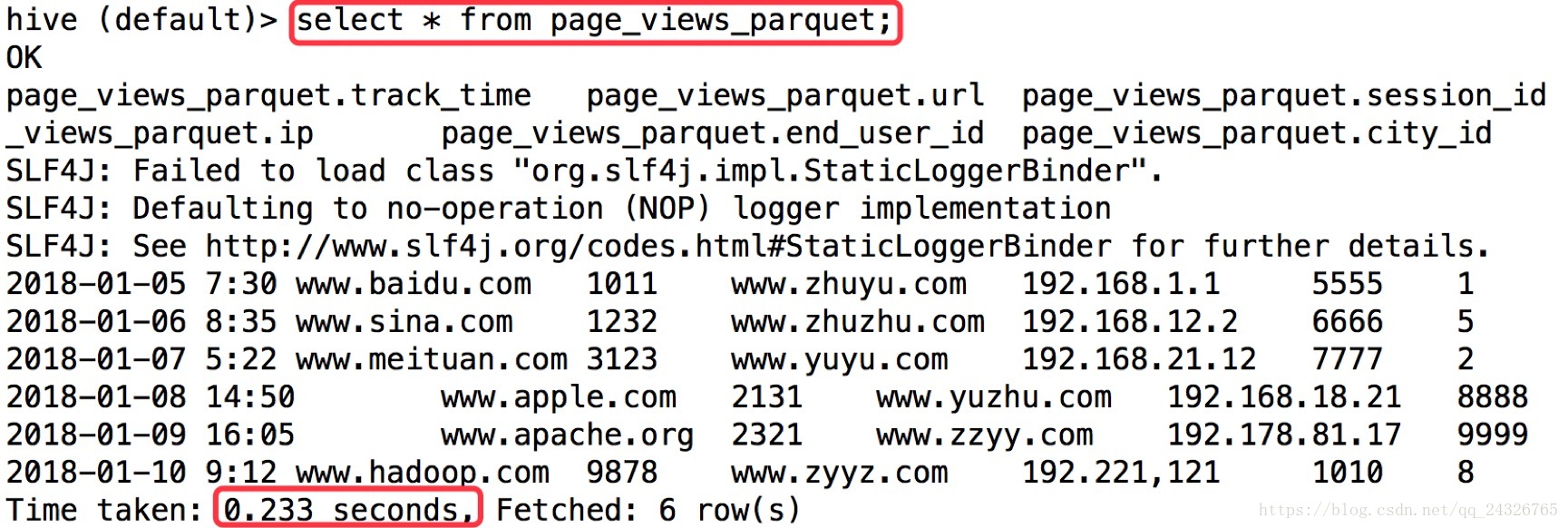
这面这两个查询由于这里数据不多,就不做测试了。

生成的mapreduce有两个job:group by一个,order by一个。
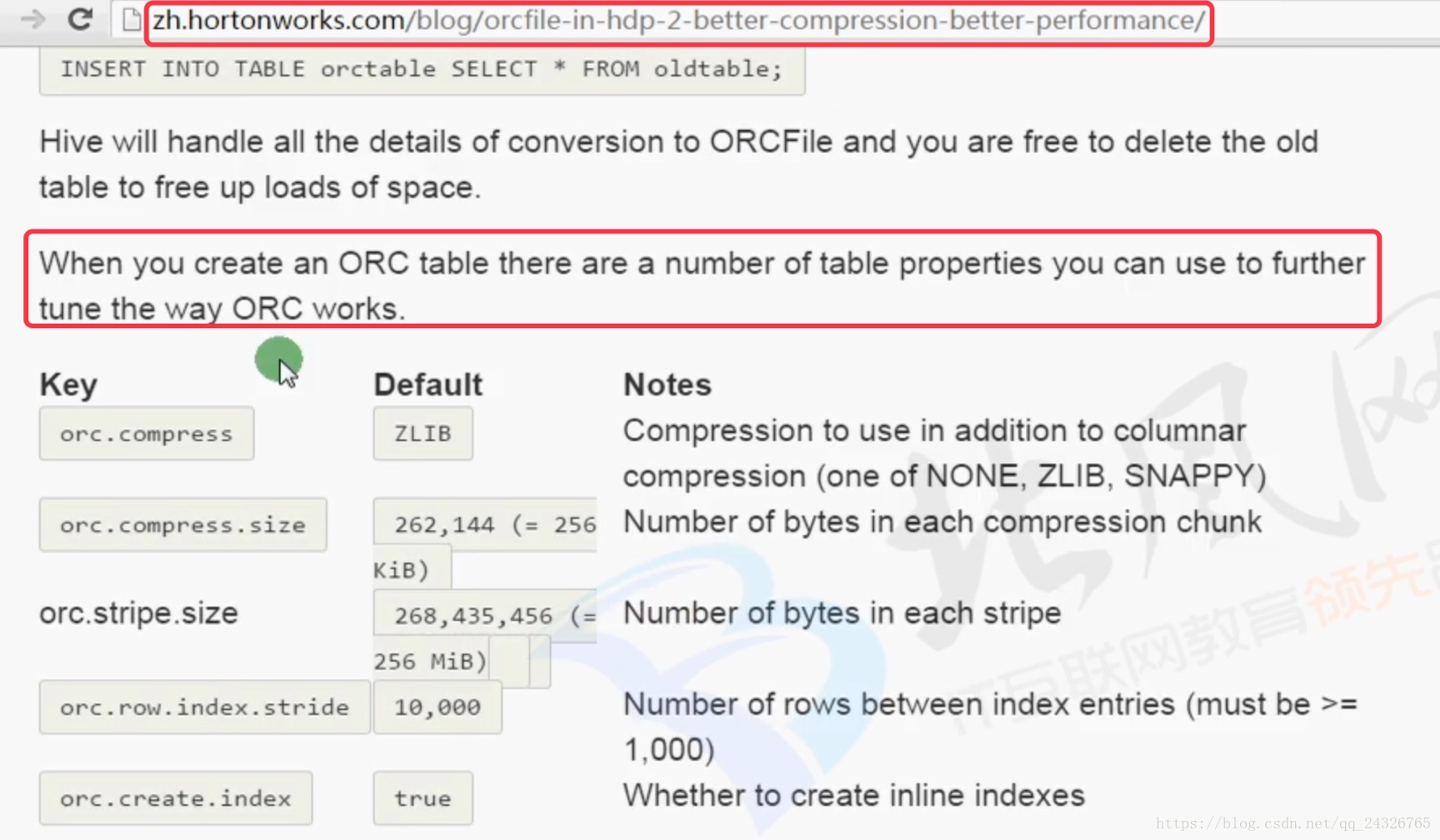
对比不压缩和默认的zlib压缩:
create table page_views_orc_none(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS PARQUET TBLPROPERTIES("orc.compress"="none");
insert into table page_views_none select * from page_views;
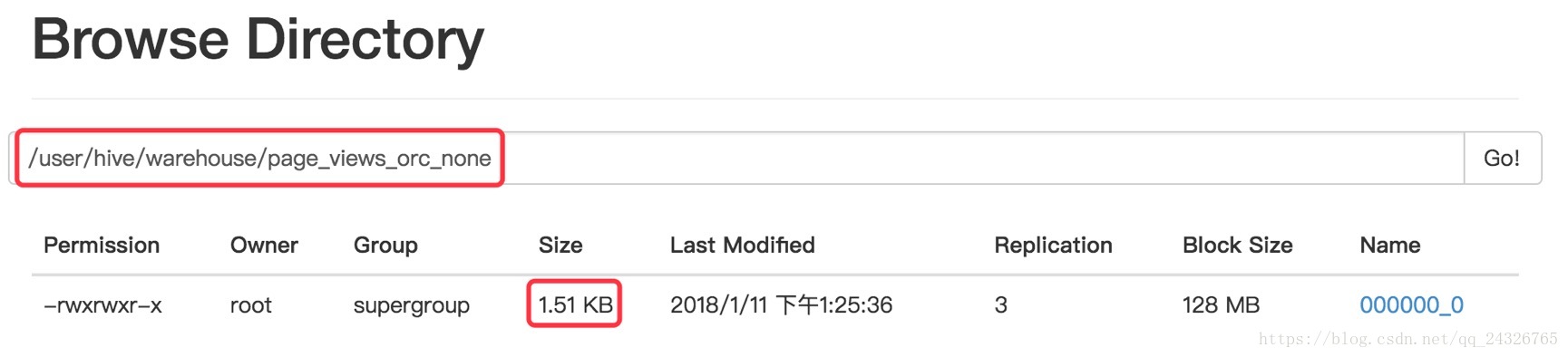

总结:
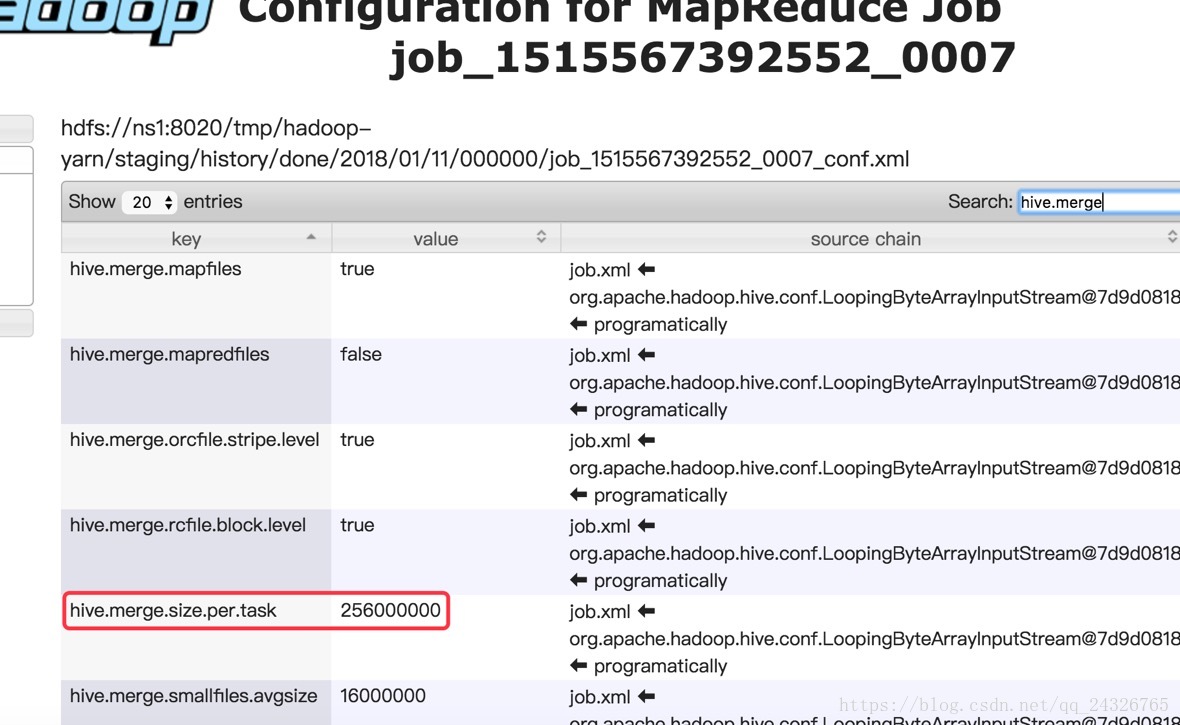
4. Hive 企业使用优化
直接把task抓取过来,不经过mapreduce:

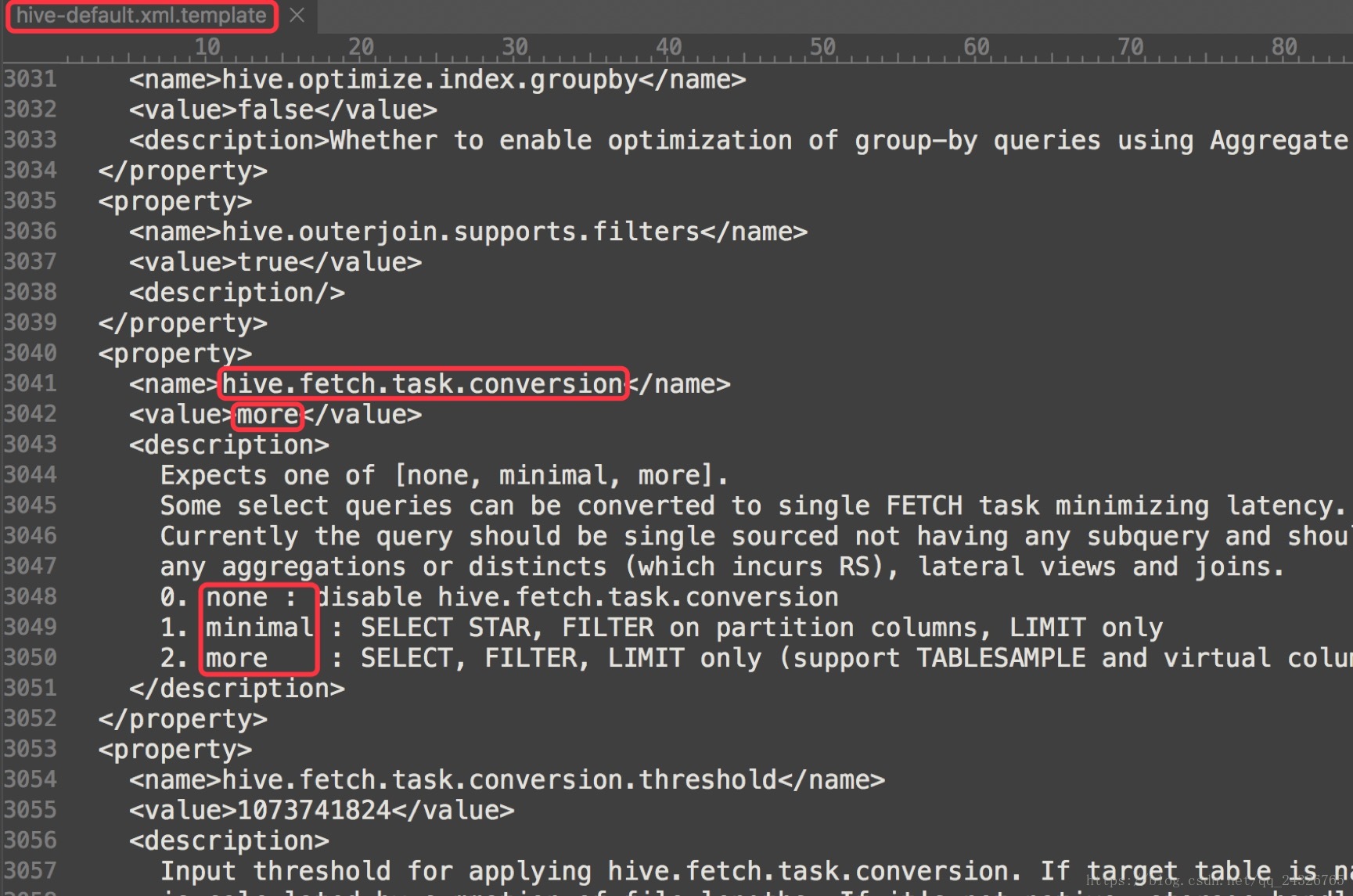

大表拆分:
假如只需要大表中的某几个字段,可以将这些字段提取出来创建一个子表(create table IF NOT EXISTS default.bf_log_20180107_sa AS select ip,req_url frombf_log_20180107;),这样查询速度就会得到提升。

当需要转换存储格式的时候:
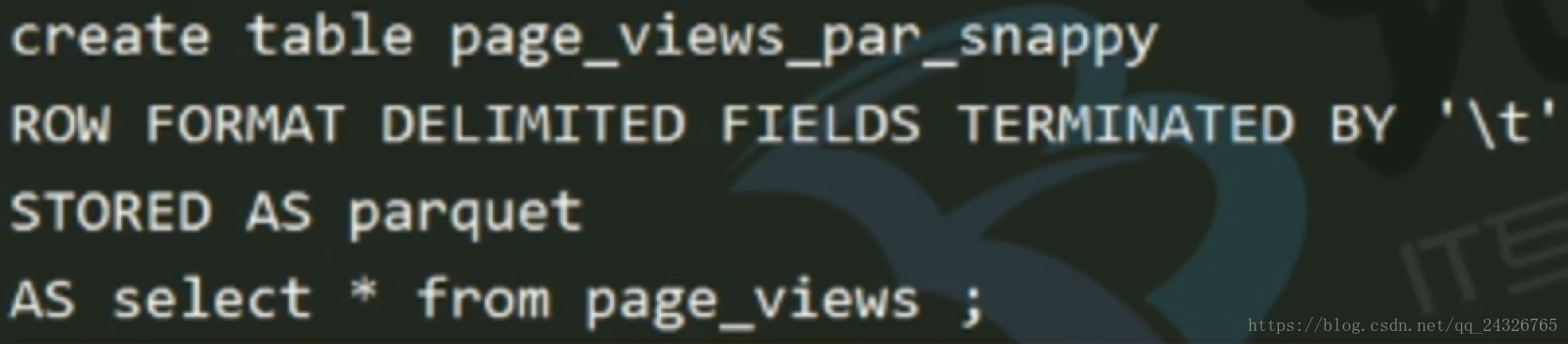
外部表、分区表:
外部表:多个部门同时使用。分区表:二级分区表用的比较多。二者通常结合使用。

sql优化:

过滤掉部分数据再join(30亿数据和50亿数据join肯定不一样):
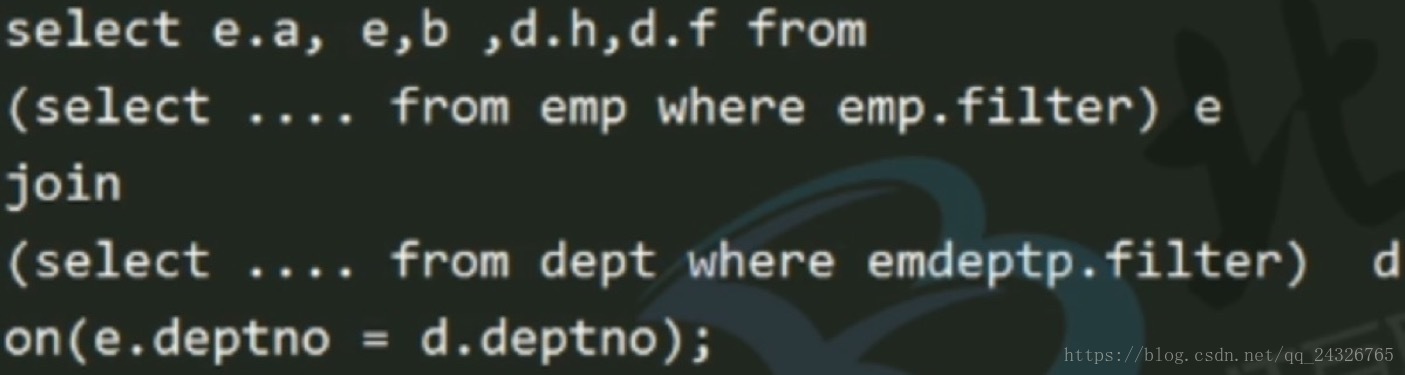
join优化:



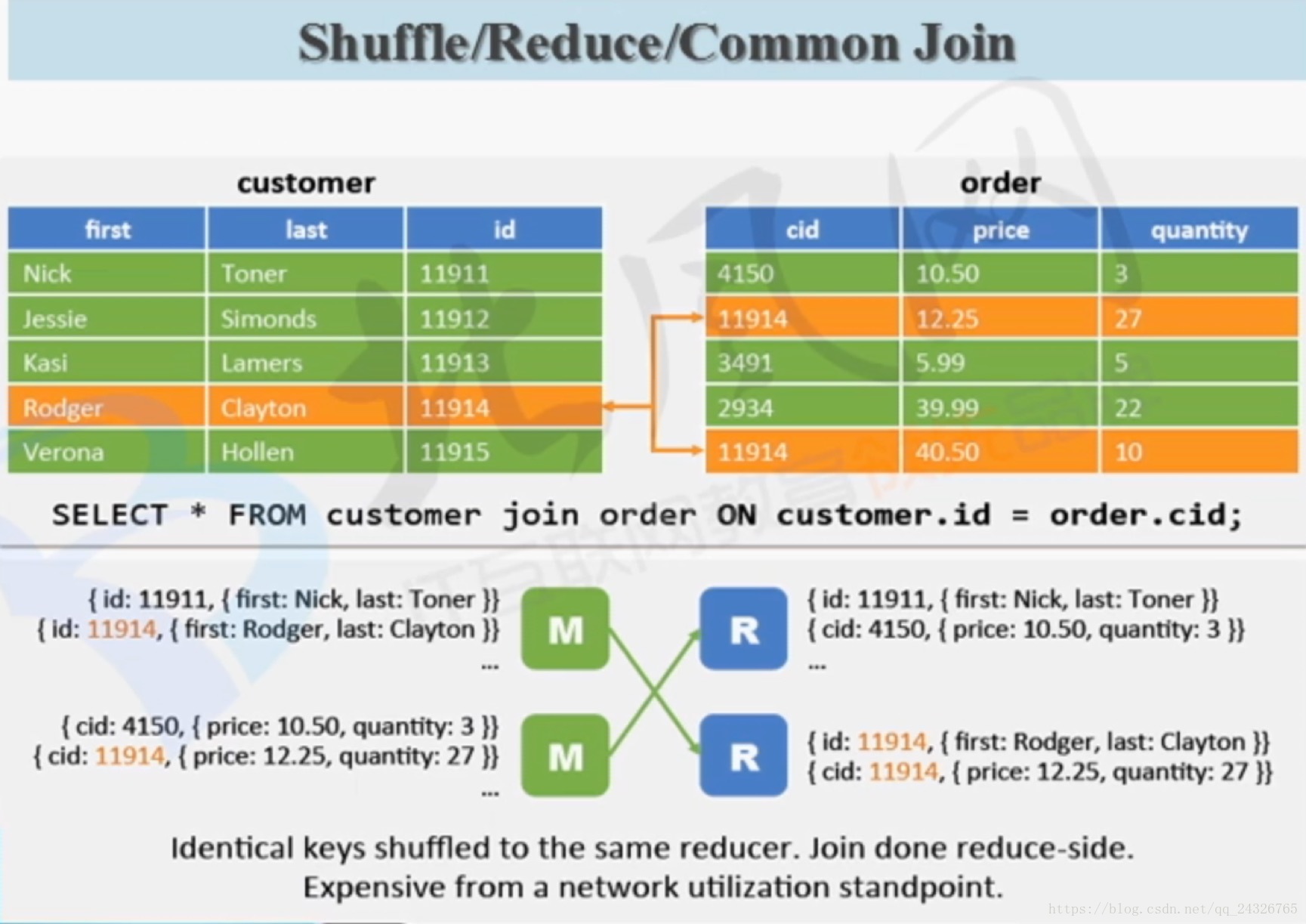

有了clustered by后面的sorted by其实可以不要了。
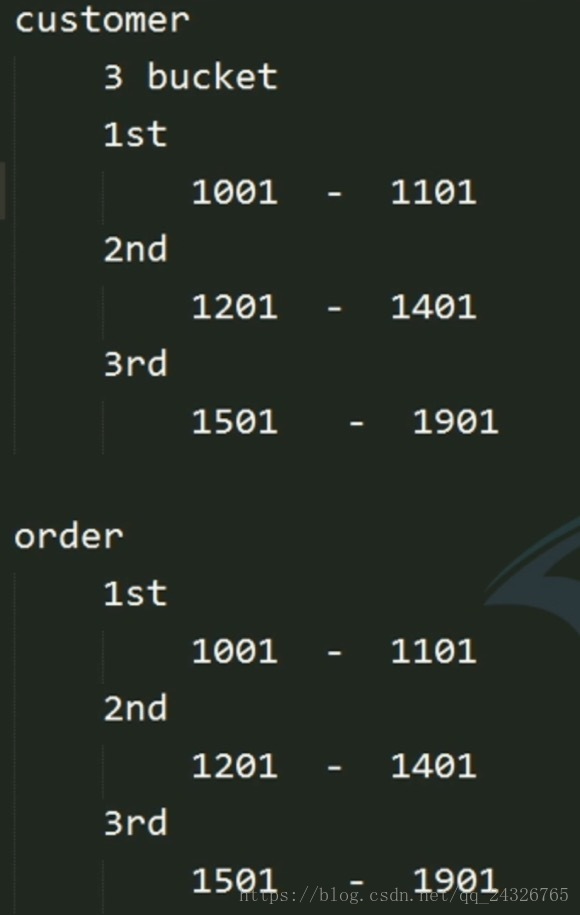
相当于桶和桶join,因为id范围是一样的。
一个桶一个map处理,共有6个map。
桶之间两两合并,所以三个reduce。
一般大公司用,实际上是对“大表对大表”的优化。
手动和自动设置join的方式:
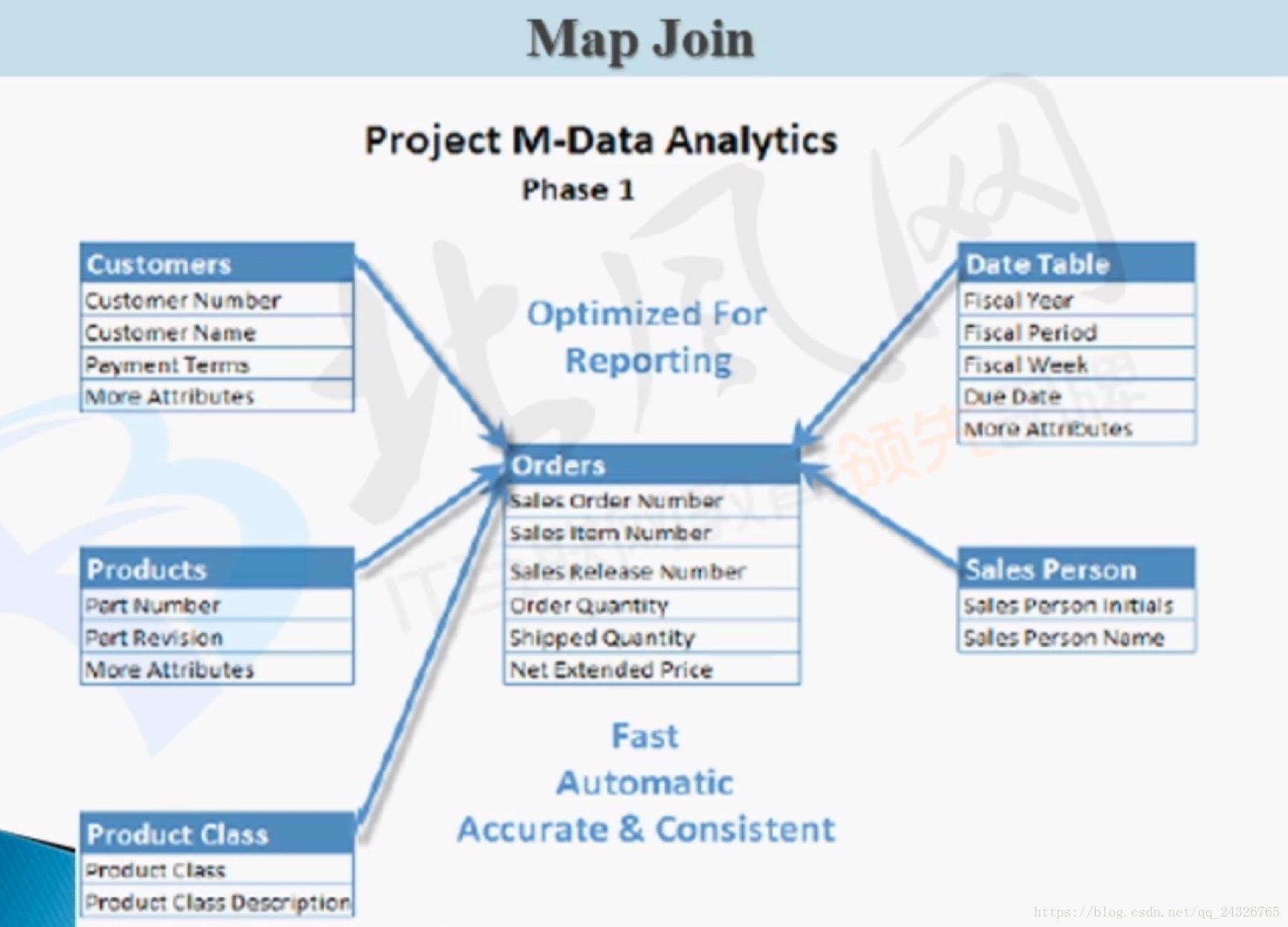
Map Join:
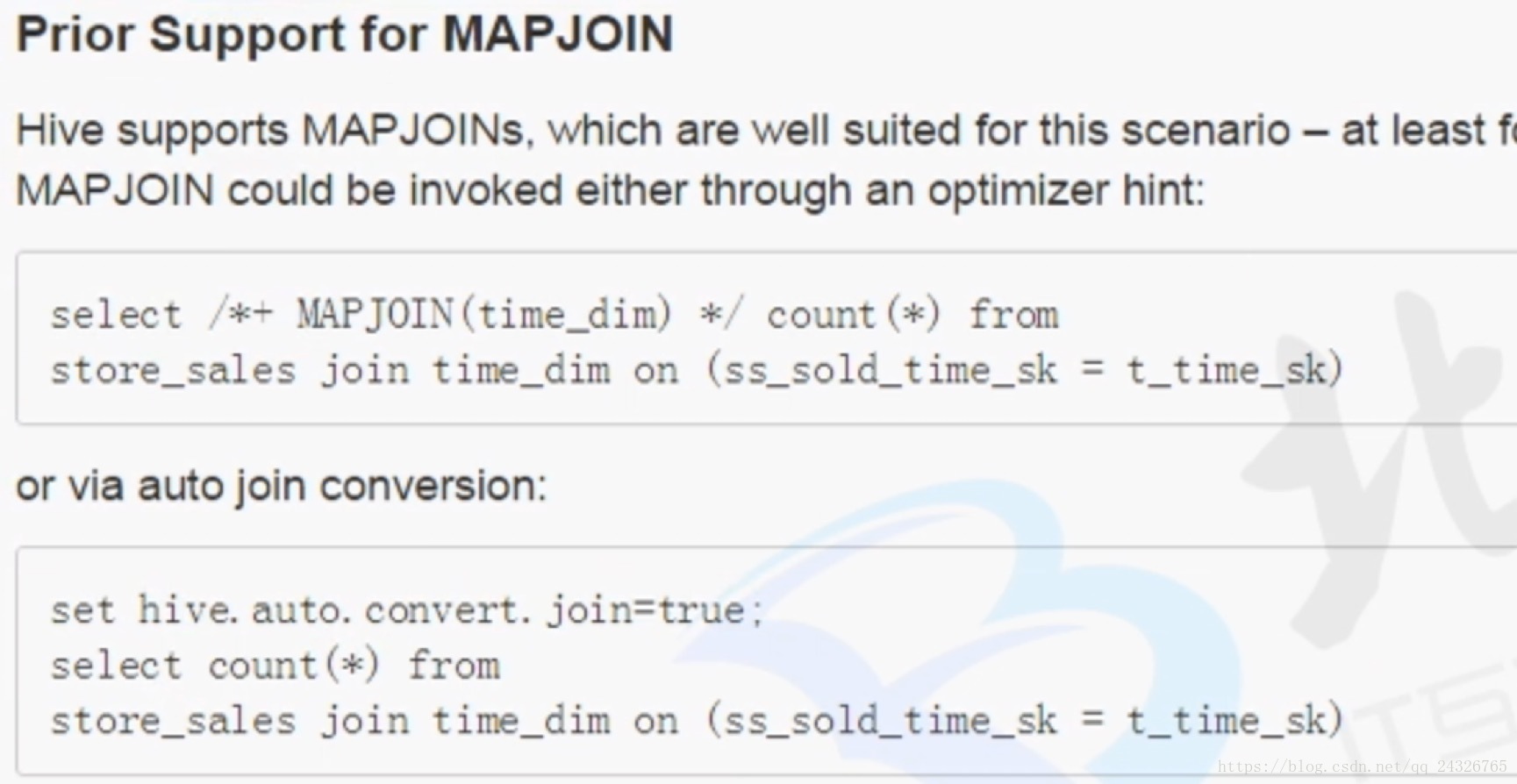
第二种自动判断哪张是大表,哪张是小表。
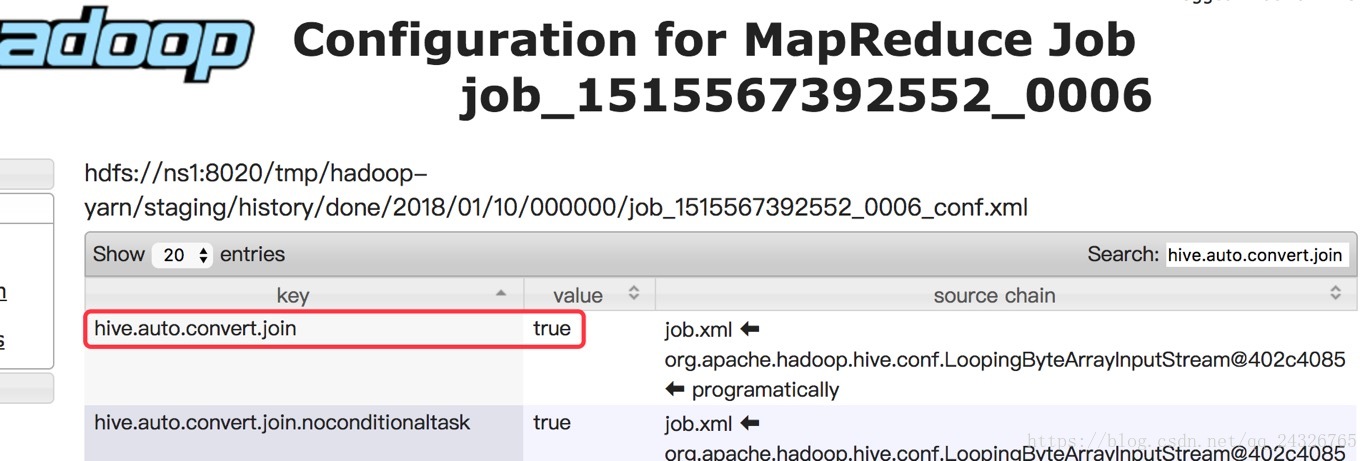
SMB Map Join:

查看执行计划:
EXPLAIN [EXTENDED|DEPENDENCY|AUTHORIZATION] query

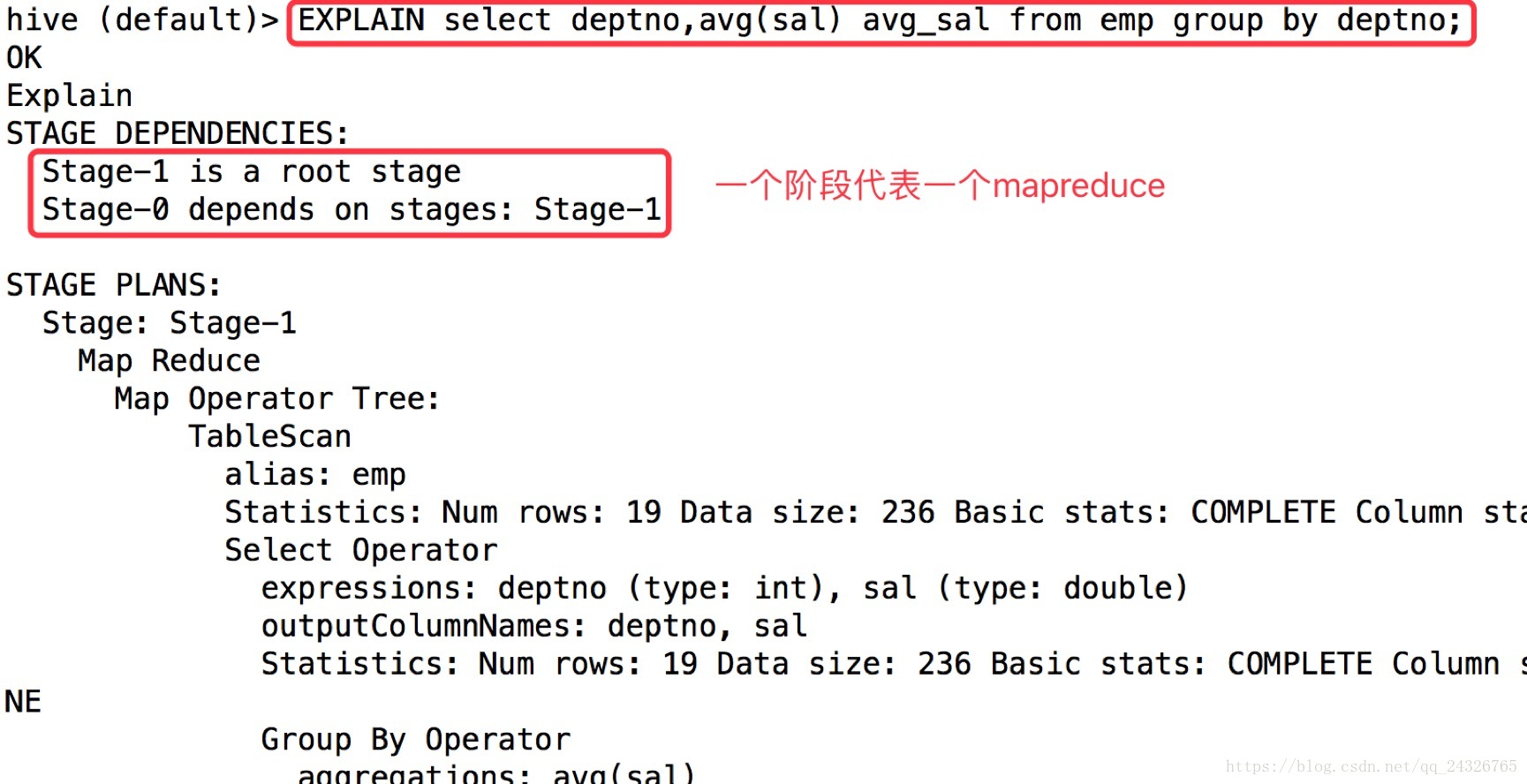
5. hive高级优化

Map的数目:
map的数目由块的大小决定的。
并行执行:

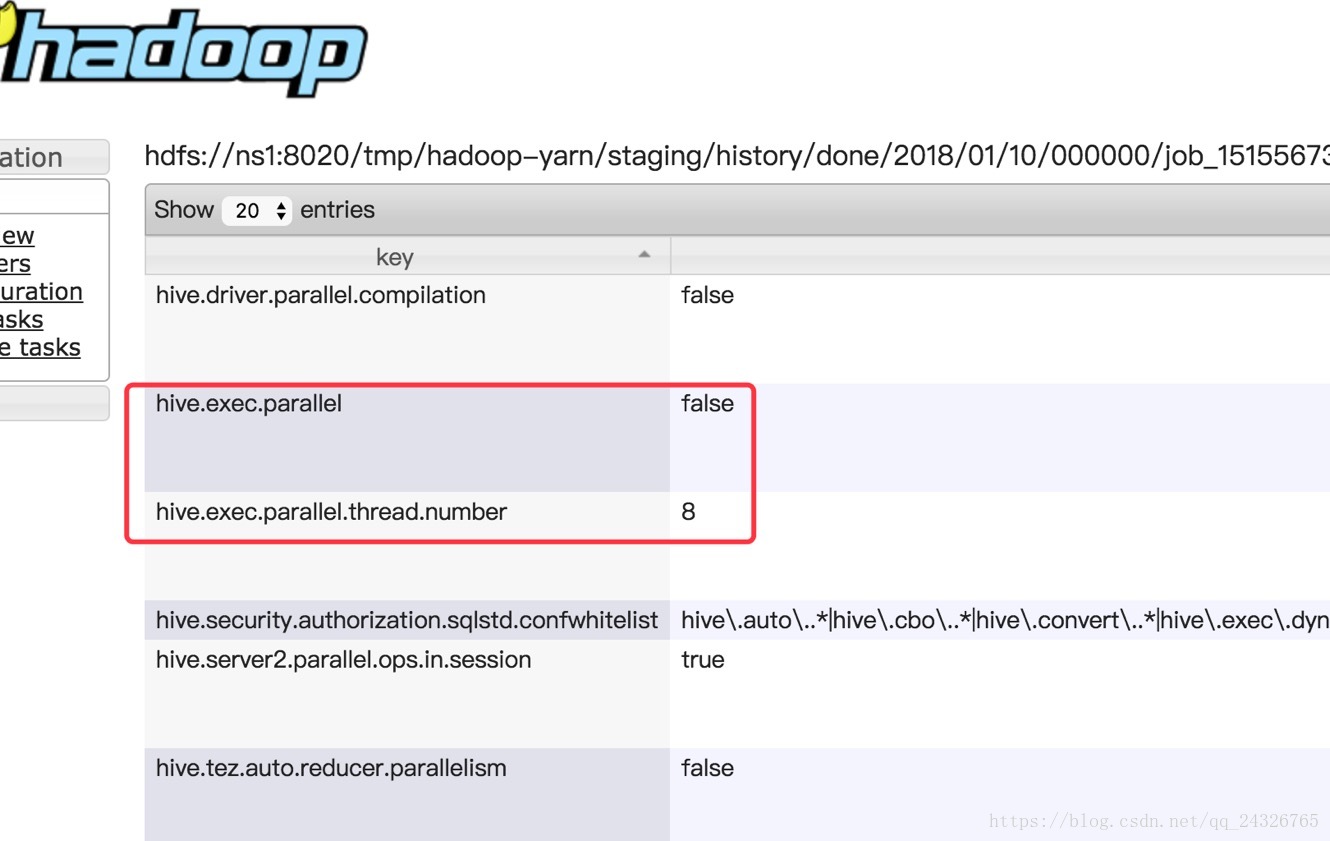
一般设置并行数为10—20。
JVM重用:
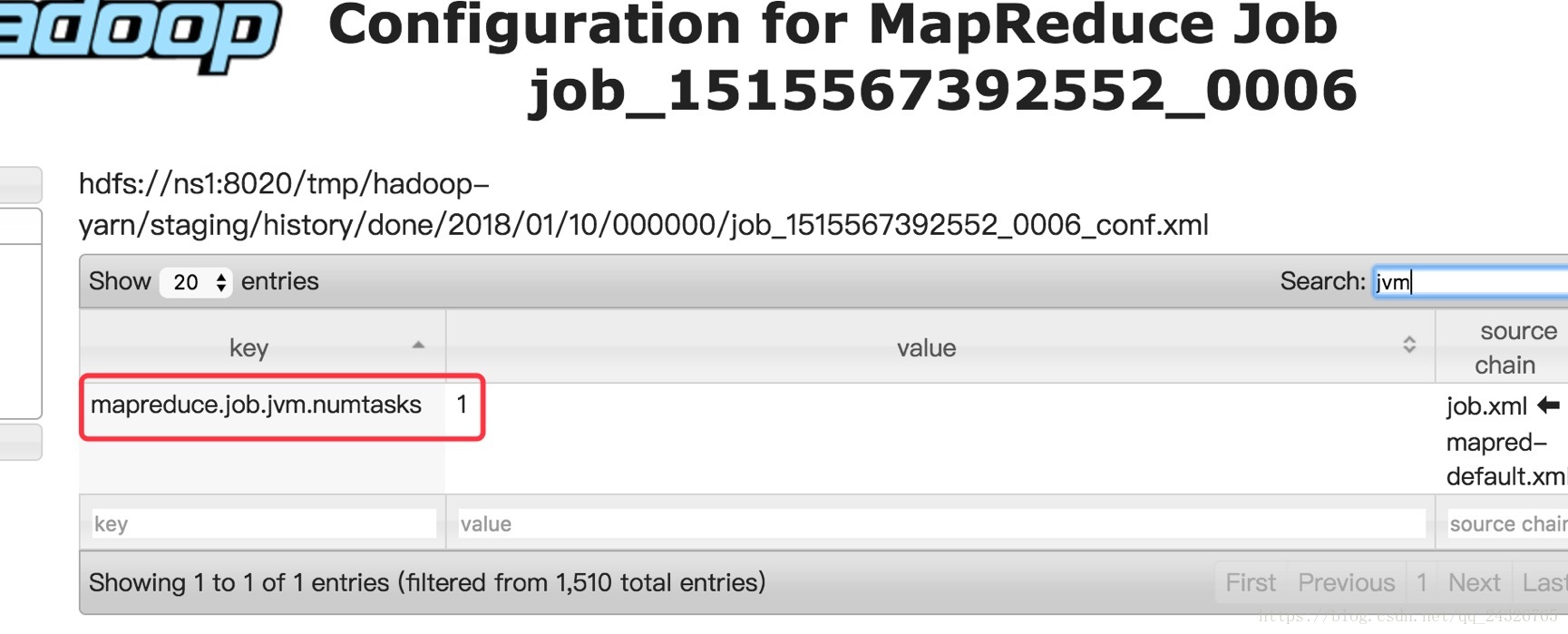

通常一个Map或Reduce任务需要启用一个jvm容器,现在使一个jvm可以运行多个任务(不要超过9个)。
以上属于map调优。
Reduce数目:
reduce的数目由认为决定的(需要测试运行时间)。
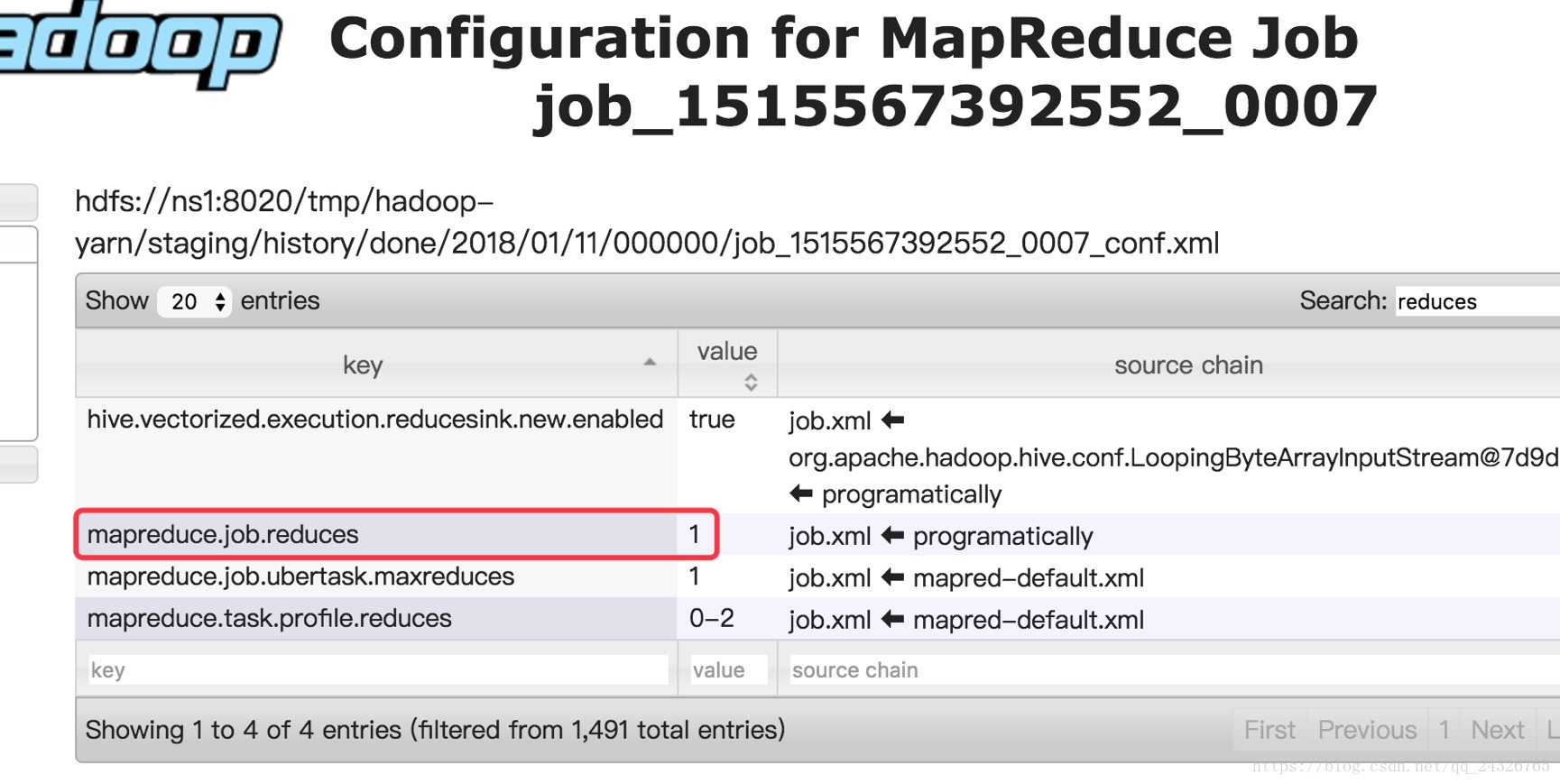
以上属于reduce调优。
推测执行:
他有一个执行标准,看你任务没有执行完,超过标准了,会再启动一个相同的任务。
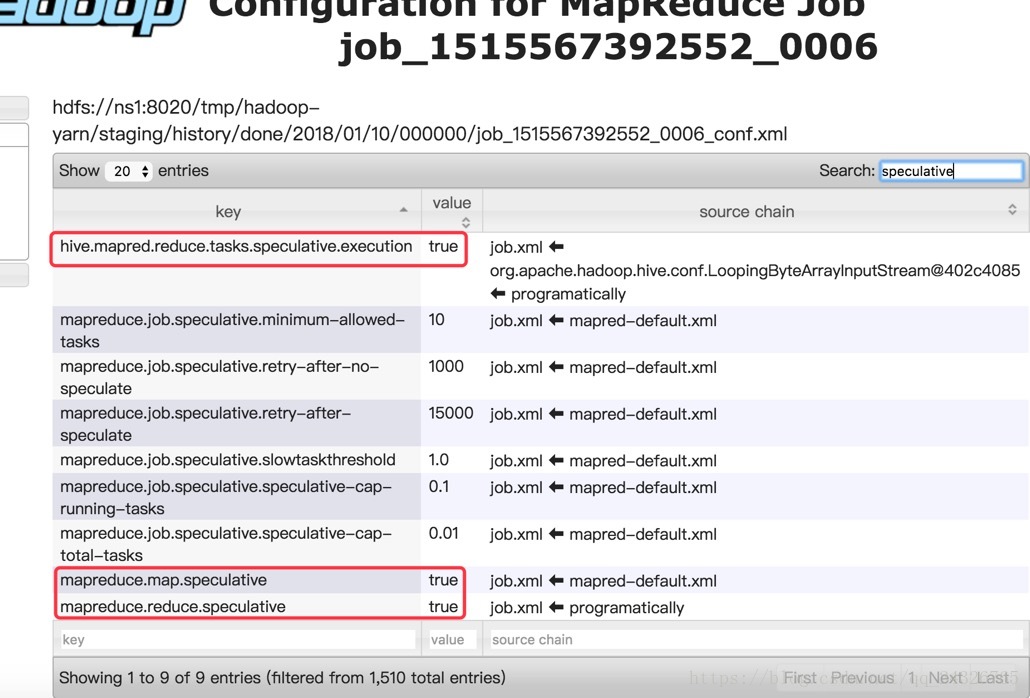
执行hive要设置为false,因为hive分析数据时,数据量大的话,时间肯定有时候会比较慢,如果打开推测执行,hive看超过了标准,就会再开启一个相同的任务。这样特别浪费集群资源。
可在map的task页面中查看:
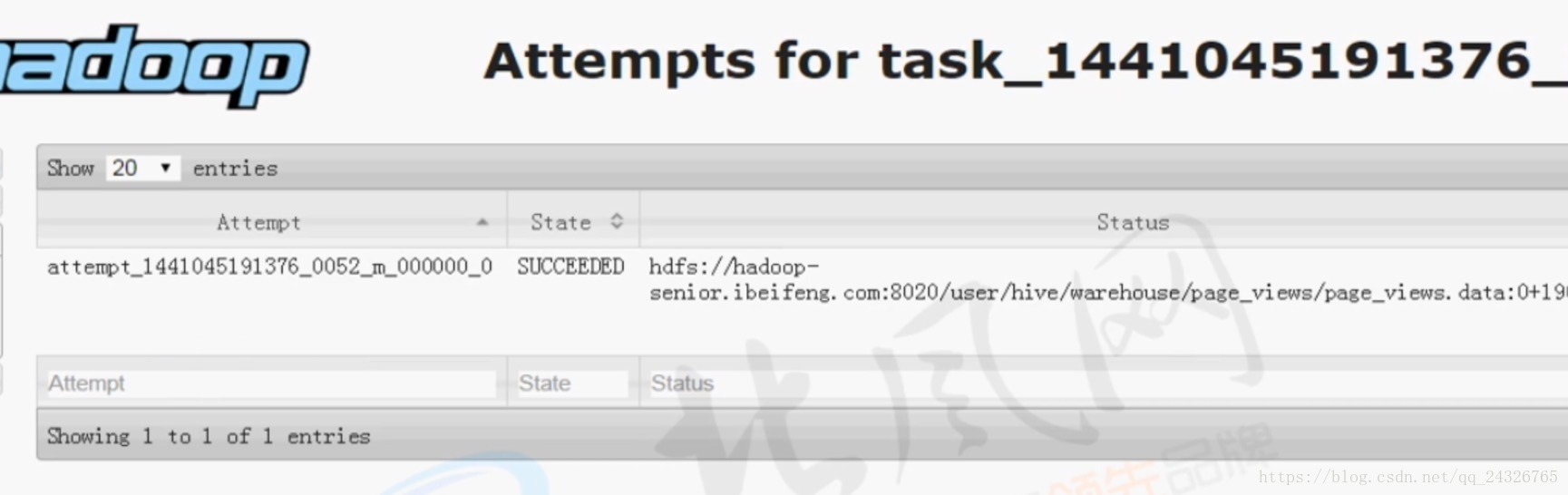
如果一个map执行了好多次,就说明进行了推测执行。
以上属于mapreduce调优。
动态分区调整:
实例:

每天的数据加载到表中:

按月加载还好,按天的话太麻烦,所以引出了动态分区。
设置动态分区:
实例:
创建一个带分区的test表:
hive > create table test(
> id int, name string
> ,tel string)
> partitioned by
> (age int)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS TEXTFILE;
OK
Time taken: 0.261 seconds我们这里有有一张test_data表,数据如下:
hive (hive)> select * from wyp;
OK
id name age tel
1 lavimer 23 13878789088
2 liaozhongmin 24 13787896578
3 liaozemin 25 13409876785
Time taken: 1.704 seconds现在我们从test_data表中查询出数据插入到test表中,第一种方式是指定分区:
hive (hive) > insert into table test
> partition (age='23')
> select id,name,tel
> from test_data; 如果每一个年龄我们都要指定一个分区的话,就非常的麻烦,还好Hive提供了动态分区,如下:
hive (hive) > set hive.exec.dynamic.partition=true;
hive (hive) > set hive.exec.dynamic.partition.mode=nonstrict;
hive (hive) > insert into table test
> partition (age)
> select id,name,tel,age
> from test_data; 
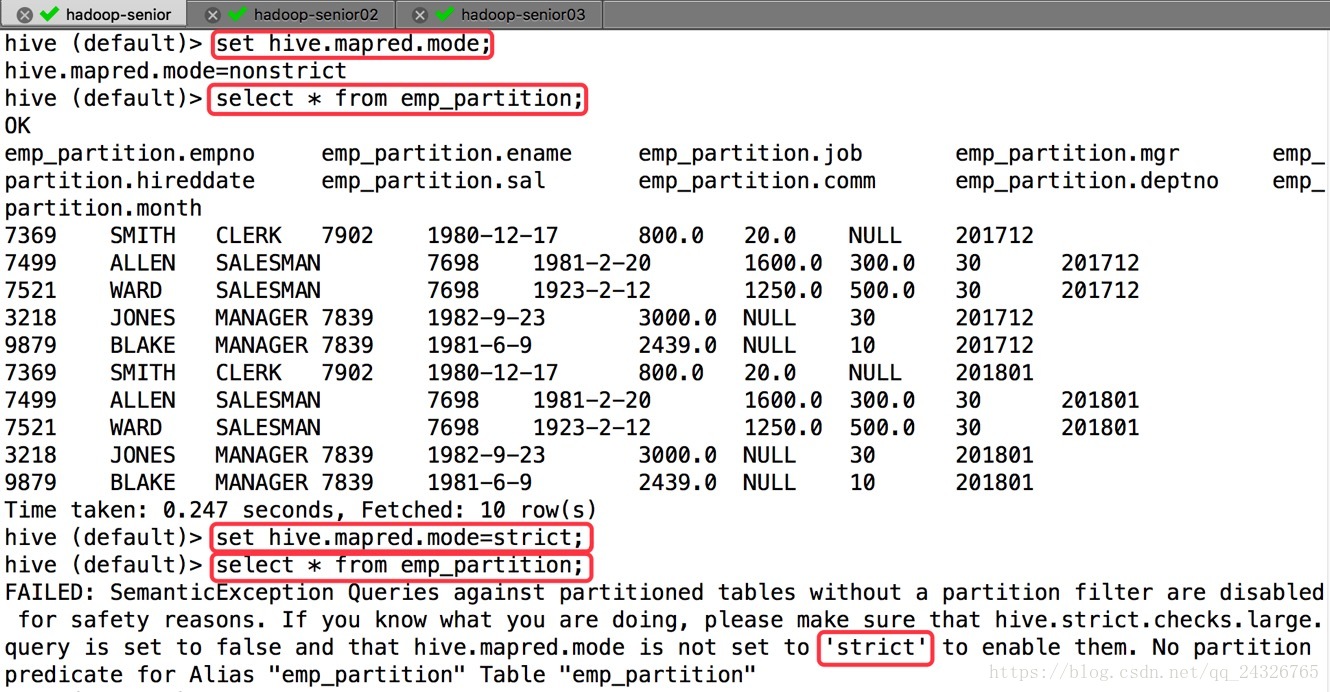
严格模式:

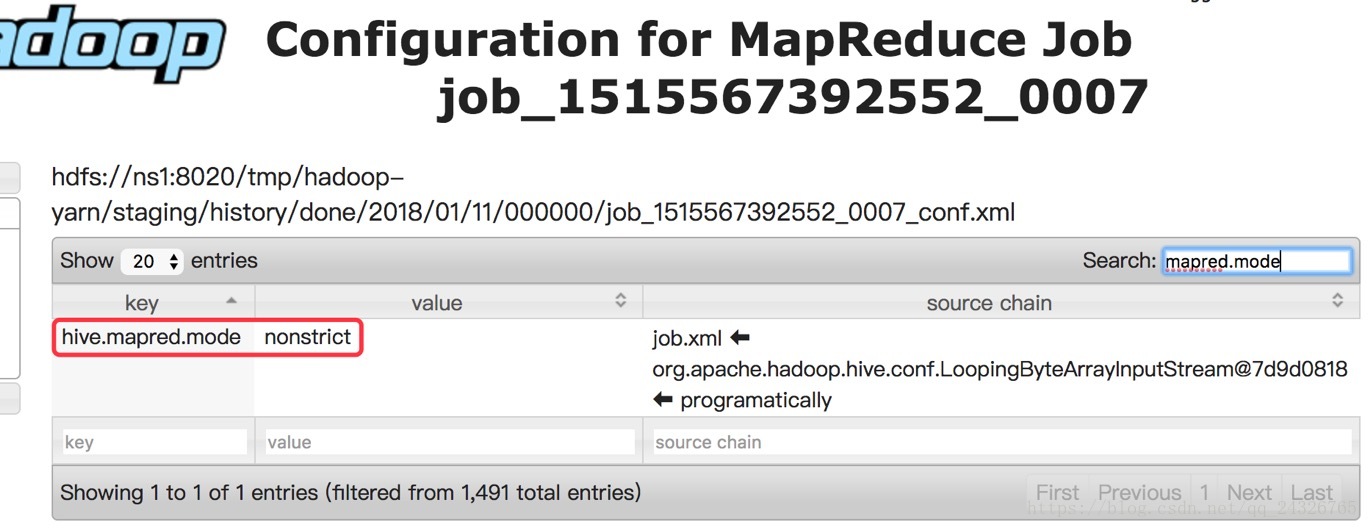
(默认没有开启)
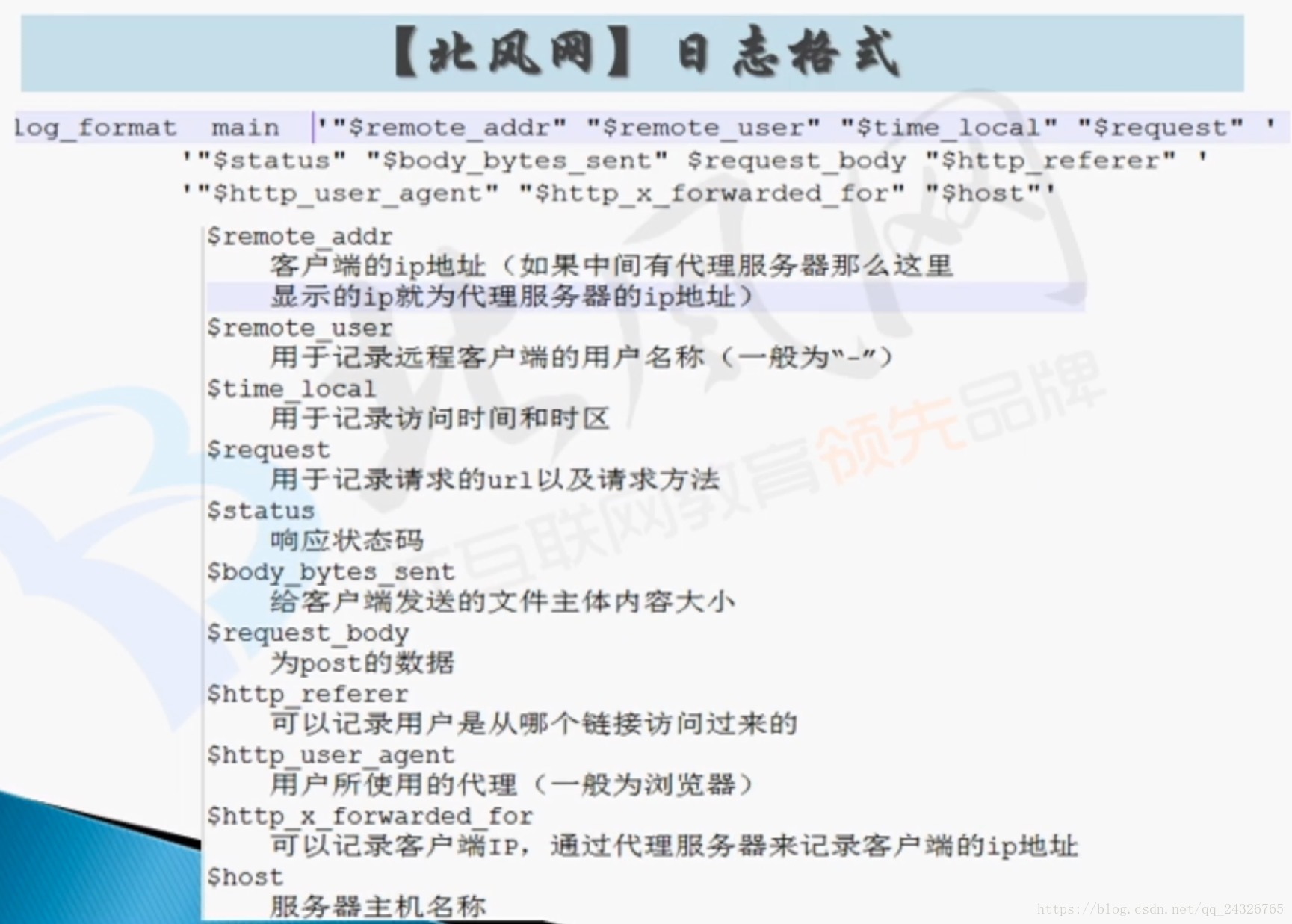
6. Hive项目实战一创建表并导入日志数据,引出问题


create table if not exists default.bf_log_src(
remote_addr string,
remote_user string,
time_local string,
request string,
`status` string,
body_bytes_sent string,
request_body string,
http_referer string,
http_user_agent string,
http_x_forwarded_for string,
`host` string
)
row format delimited fields terminated by ' '
stored as textfile;
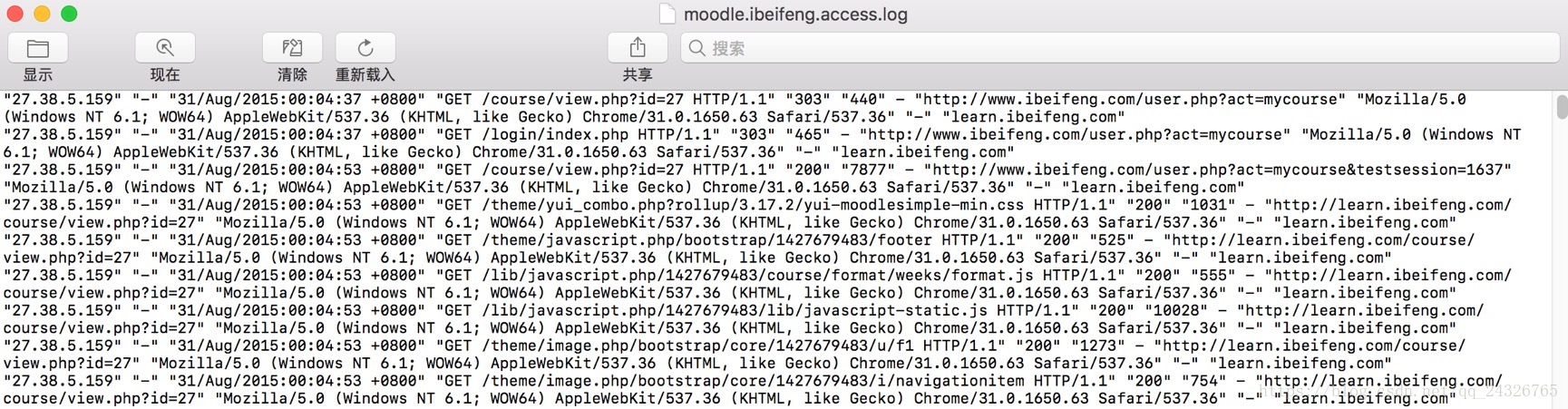
load data local inpath '/opt/datas/moodle.ibeifeng.access.log' into table default.bf_log_src;发现问题:
格式不对,因为有的字段内带空格:
解决:① mapreduce进行解析② 建表时用正则表达式
7. Hive 项目实战二使用RegexSerDe处理Apache或者Ngnix日志文件
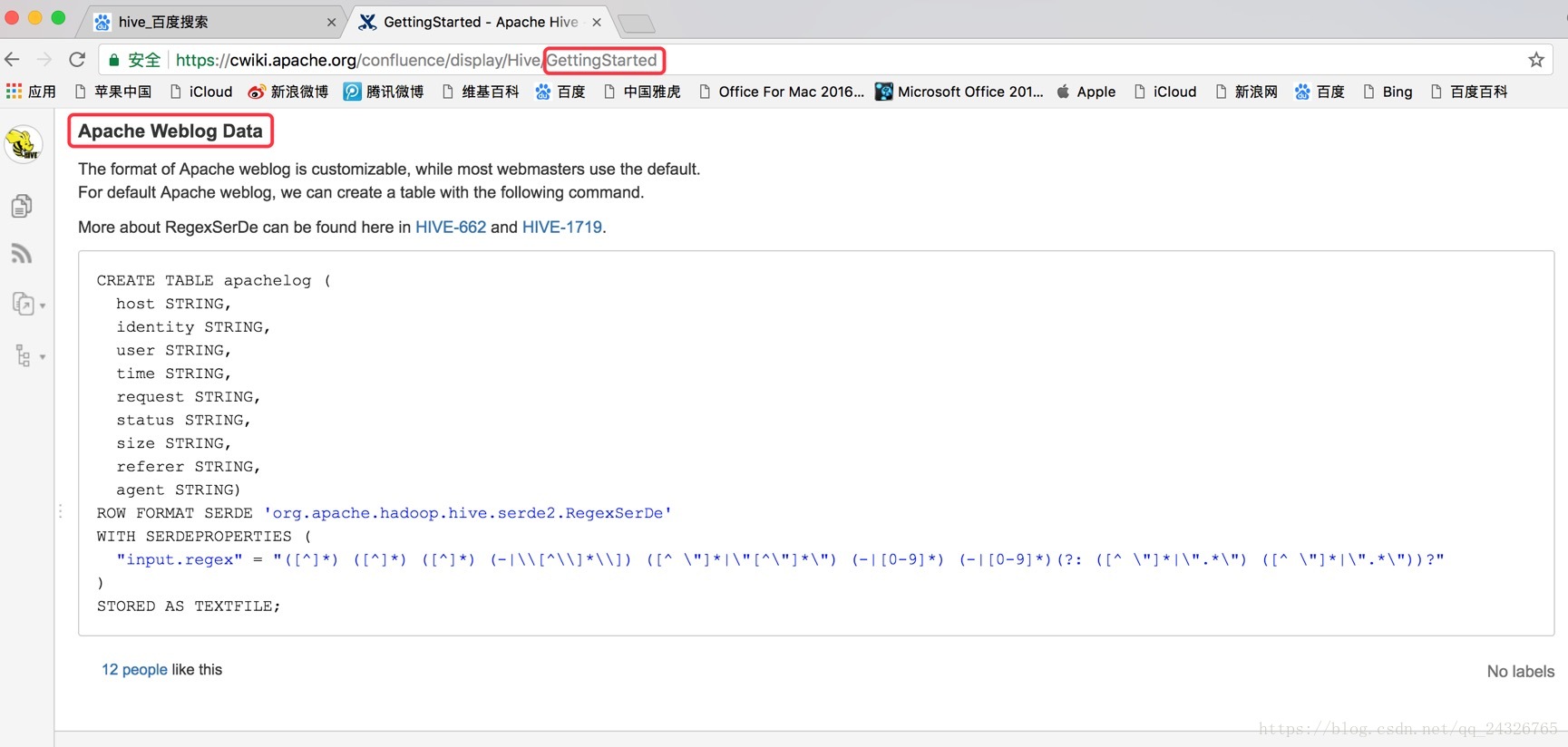
因为字段不同,所以改用如下正则表达式:
(\"[^ ]*\") (\"-|[^ ]*\") (\"[^\"]*\") (\"[^\"]*\") (\"[0-9]*\") (\"[0-9]*\") (-|[^ ]*) (\"[^ ]*\") (\"[^\"]*\") (\"-|[^ ]*\") (\"[^ ]*\")一个括号代表一个字段。
正则表达式讲解:
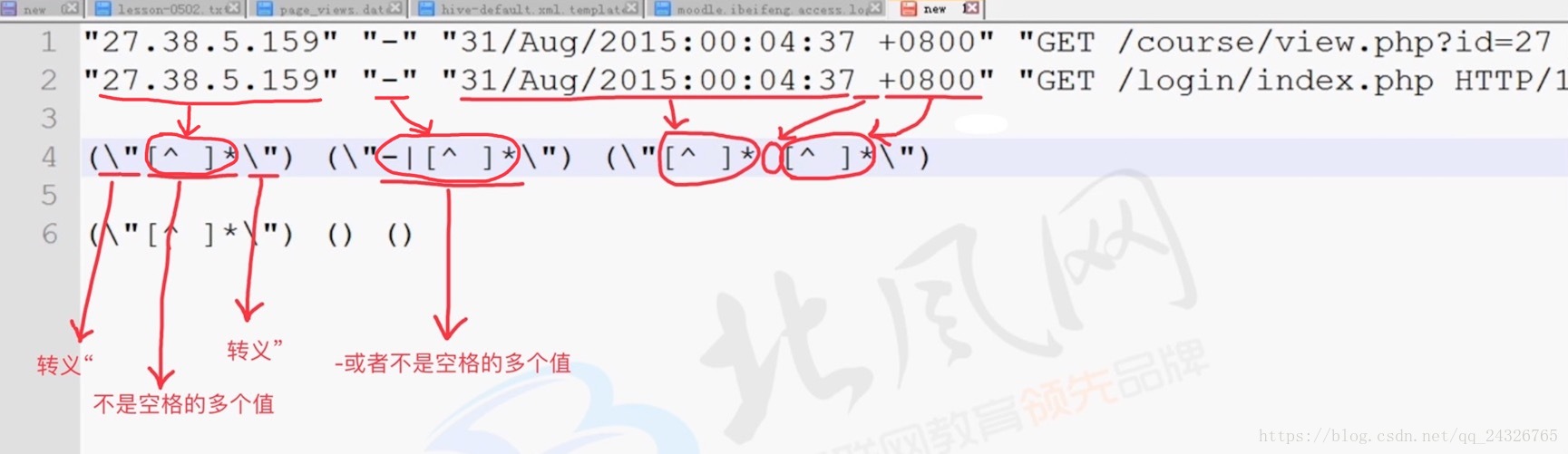
"27.38.5.159" "-" "31/Aug/2015:00:04:37 +0800" "GET /course/view.php?id=27 HTTP/1.1" "303" "440" - "http://www.ibeifeng.com/user.php?act=mycourse" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" "-" "learn.ibeifeng.com"
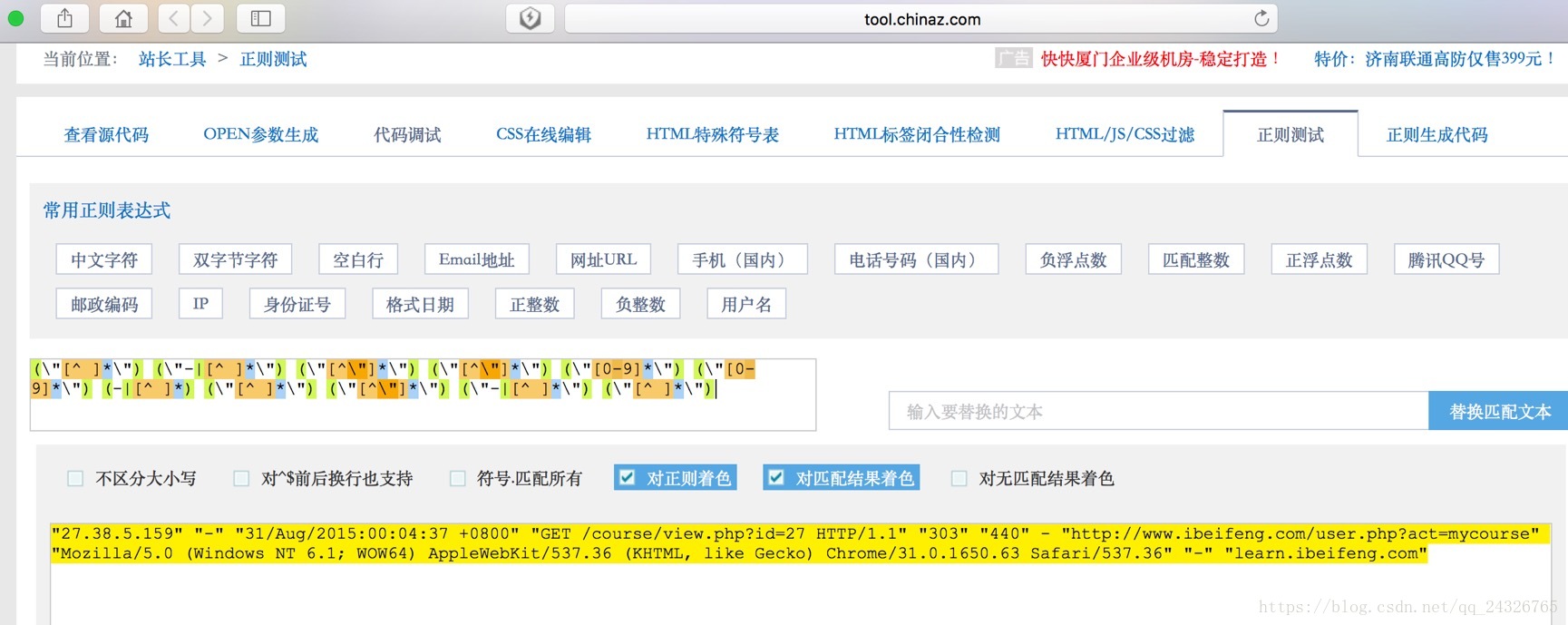
验证正则表达式是否正确的网站:
创建原表,并导入数据:
drop table if exists default.bf_log_src;
create table default.bf_log_src(
remote_addr string,
remote_user string,
time_local string,
request string,
`status` string,
body_bytes_sent string,
request_body string,
http_referer string,
http_user_agent string,
http_x_forwarded_for string,
`host` string
)
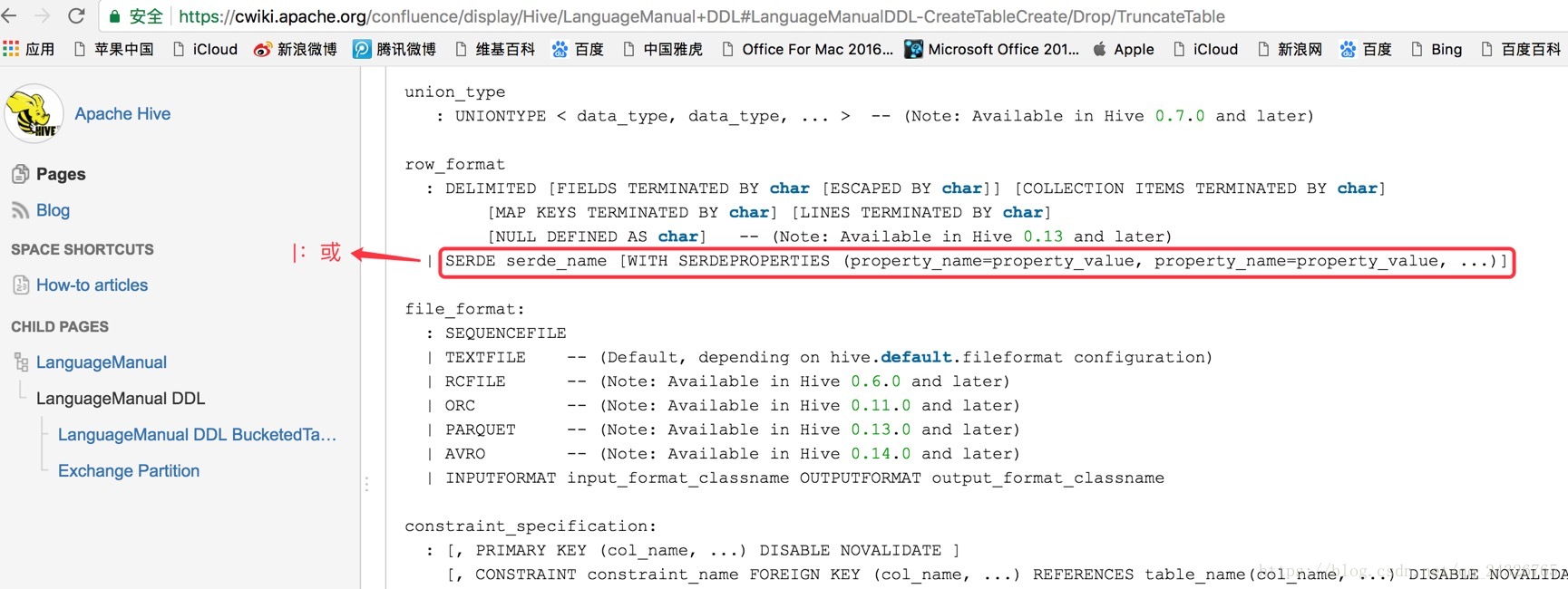
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "(\"[^ ]*\") (\"-|[^ ]*\") (\"[^\"]*\") (\"[^\"]*\") (\"[0-9]*\") (\"[0-9]*\") (-|[^ ]*) (\"[^ ]*\") (\"[^\"]*\") (\"-|[^ ]*\") (\"[^ ]*\")"
)
stored as textfile;
load data local inpath '/opt/datas/moodle.ibeifeng.access.log' into table default.bf_log_src;
注意:建表时每行前面不能有空格。
根据原表创建子表,并加载数据:
drop table if exists default.bf_log_comm;
create table default.bf_log_comm(
remote_addr string,
time_local string,
request string,
http_referer string
)
row format delimited fields terminated by '\t'
stored as orc tblproperties("orc.compress"="snappy");
insert into table default.bf_log_comm select remote_addr,time_local,request,http_referer from default.bf_log_src;8. Hive项目实战四数据清洗之自定义UDF去除数据双引号
① 编写UDF
public class RemoveQuotesUDF extends UDF{
public Text evaluate(Text str) {
//避免报空指针异常
if(null== str) {
return null;
}
if(null==str.toString()) {
return null;
}
return new Text(str.toString().replaceAll("\"", ""));
}
public static void main(String[] args) {
System.out.println(new RemoveQuotesUDF().evaluate(new Text("\"192.168.1.1\"")));
}
}
② 打成jar包
③上传到linux下
④ 添加jar并创建function
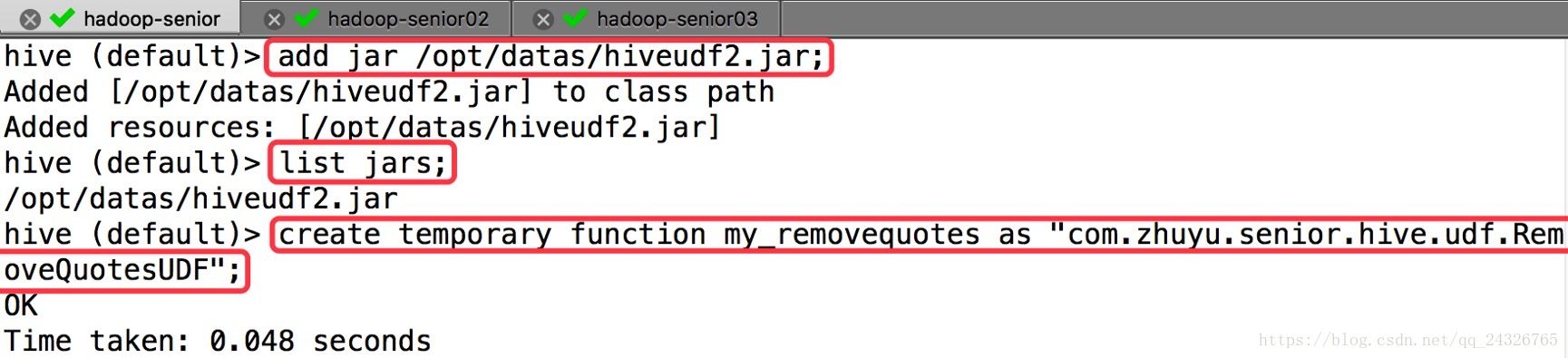
⑤ 使用函数导入并覆盖原来的数据
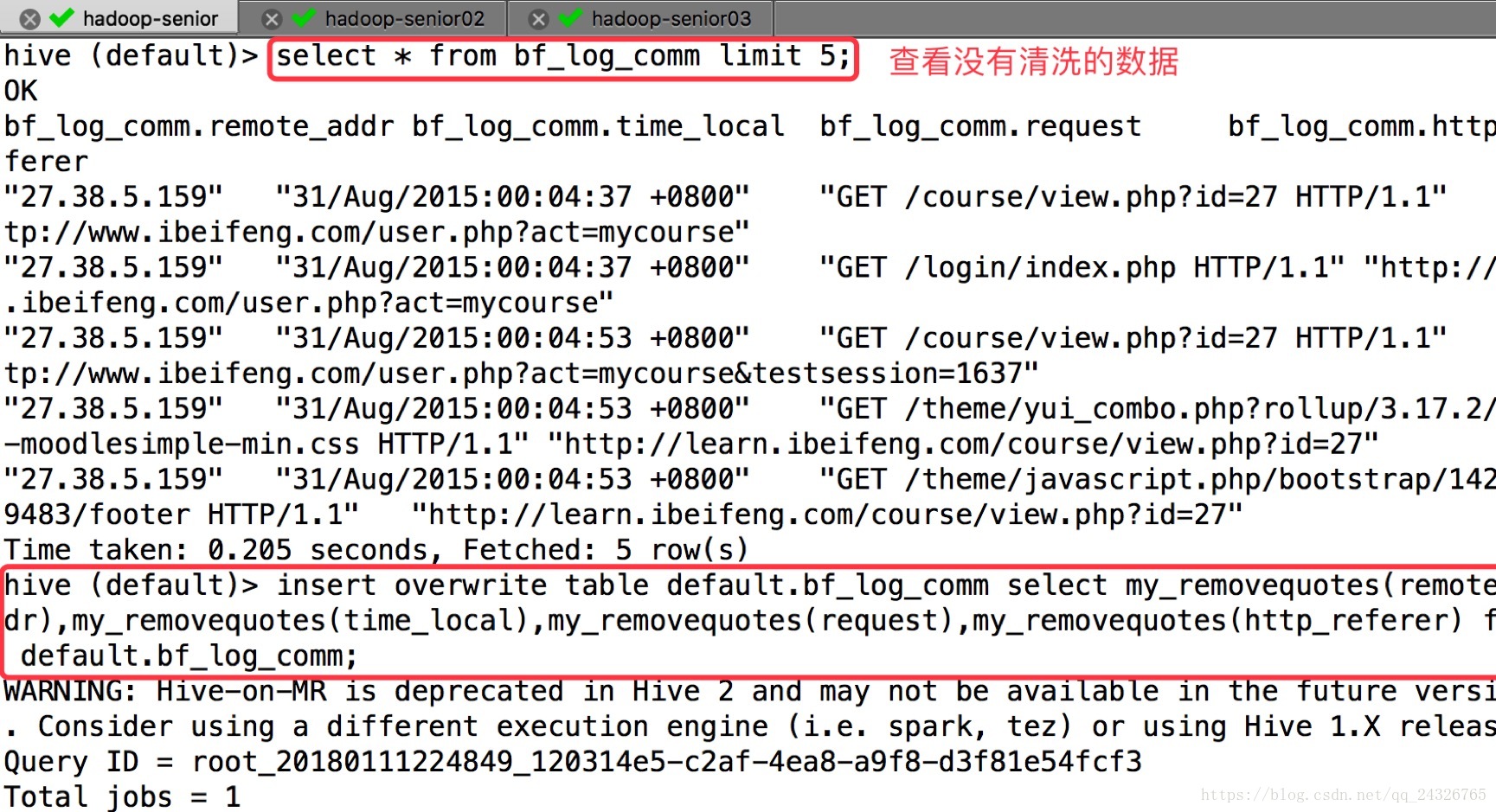
insert overwrite table default.bf_log_comm select my_removequotes(remote_addr),my_removequotes(time_local),my_removequotes(request),my_removequotes(http_referer) from default.bf_log_src;
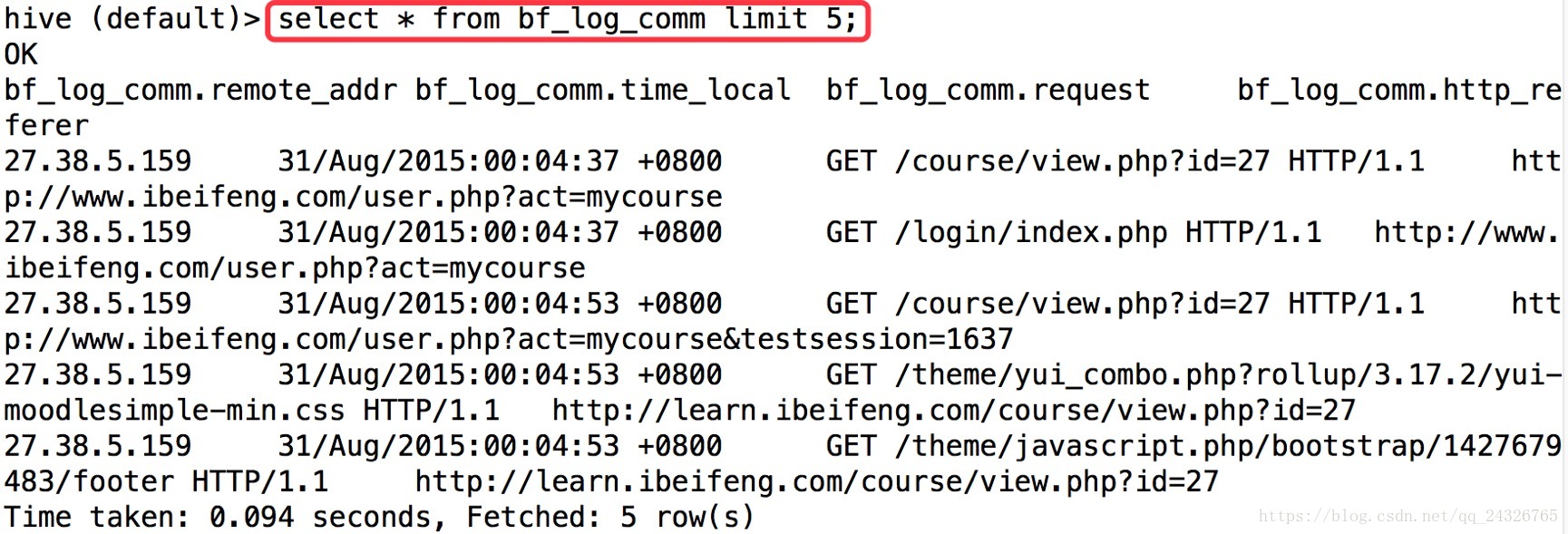
⑥ 查看
9. Hive 项目实战五数据清洗之自定义UDF转换日期时间数据
① 编写UDF
public class DateTransformUDF extends UDF {
private final SimpleDateFormat inputFormat = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss",Locale.ENGLISH);
private final SimpleDateFormat outputFormat = new SimpleDateFormat("yyyyMMddHHmmss");
/**
* 31/Aug/2015:00:04:37 +0800 ==> 20150831000437
*
* @param input
* @return
*/
public Text evaluate(Text input) {
Text output = new Text();
if (null == input) {
return null;
}
String inputDate = input.toString().trim();
if (null == inputDate) {
return null;
}
try {
Date parseDate = inputFormat.parse(inputDate);
String outputDate = outputFormat.format(parseDate);
output.set(outputDate);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return output;
}
public static void main(String[] args) {
System.out.println(new DateTransformUDF().evaluate(new Text("31/Aug/2015:00:04:37 +0800")));
}
}
② 打包(实际工作中把多个UDF类打成一个包)
③ 上传到linux下
④ 添加类并创建function
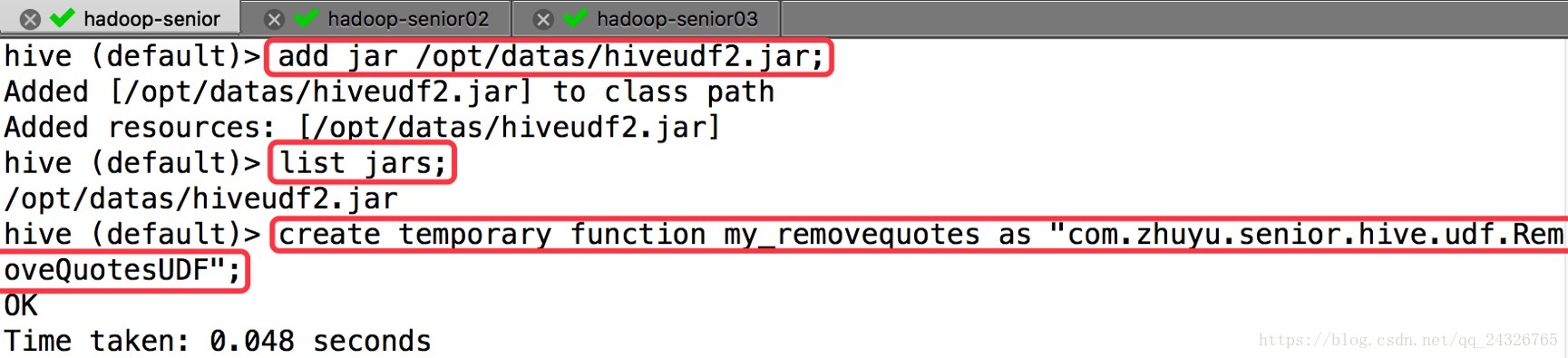
⑤ 调用function重新载入子表
insert overwrite table default.bf_log_comm select my_removequotes(remote_addr),my_datetransform(my_removequotes(time_local)),my_removequotes(request),my_removequotes(http_referer) from default.bf_log_src;
⑥ 查看数据

10. Hive 项目实战六依据业务编写HiveQL分析数据
需求1:

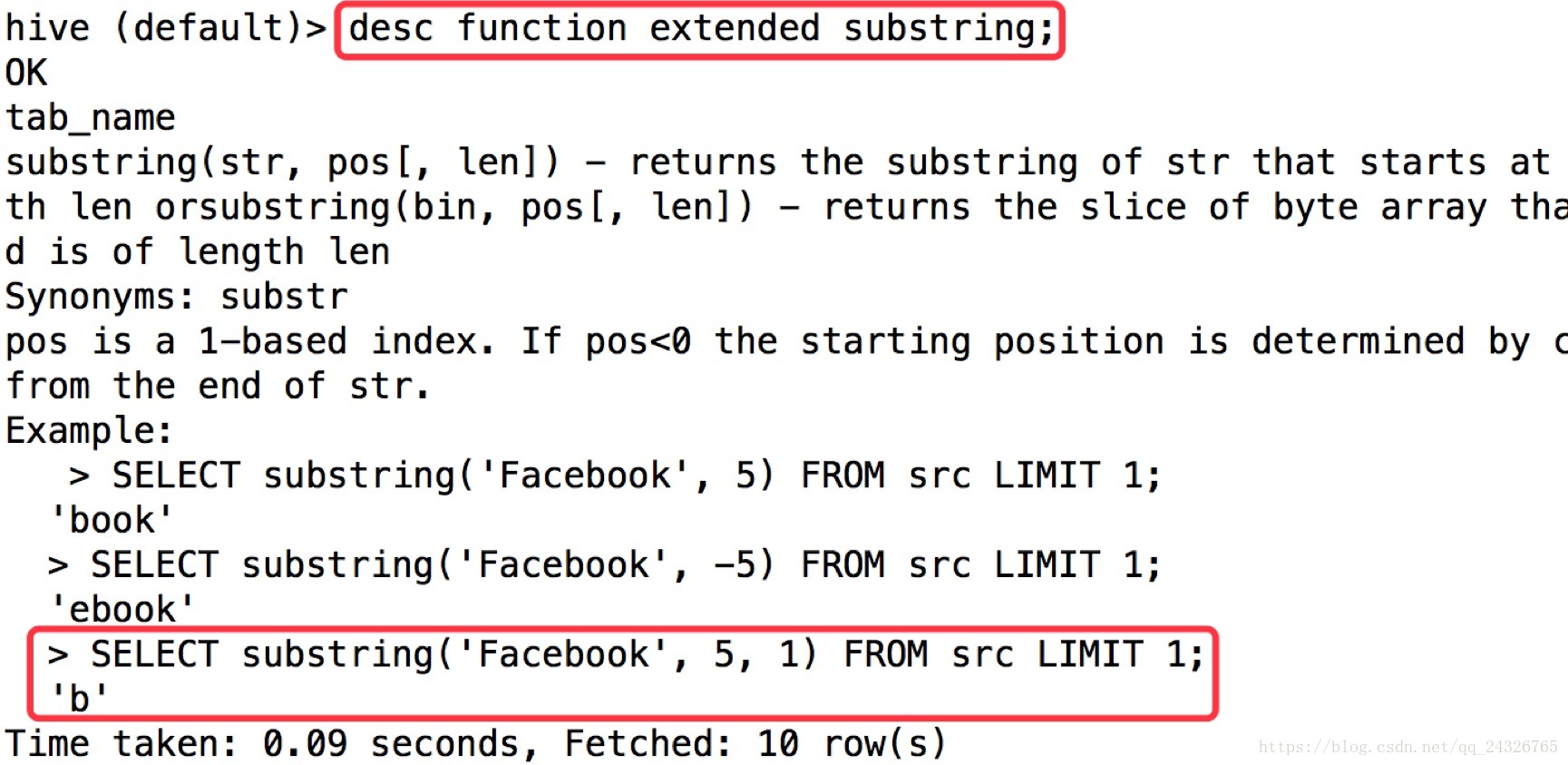
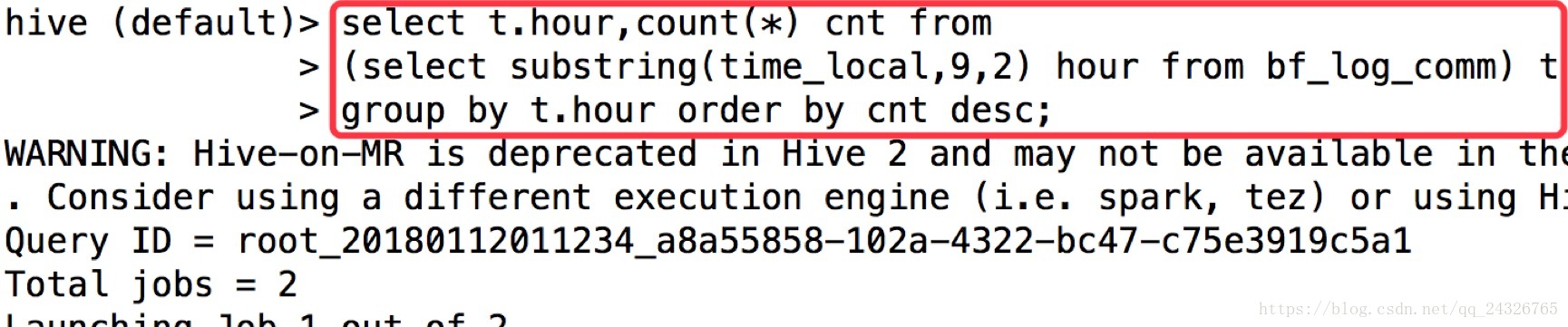
select t.hour,count(*) cnt from
(select substring(time_local,9,2) hour from bf_log_comm) t
group by t.hour order by cnt desc;
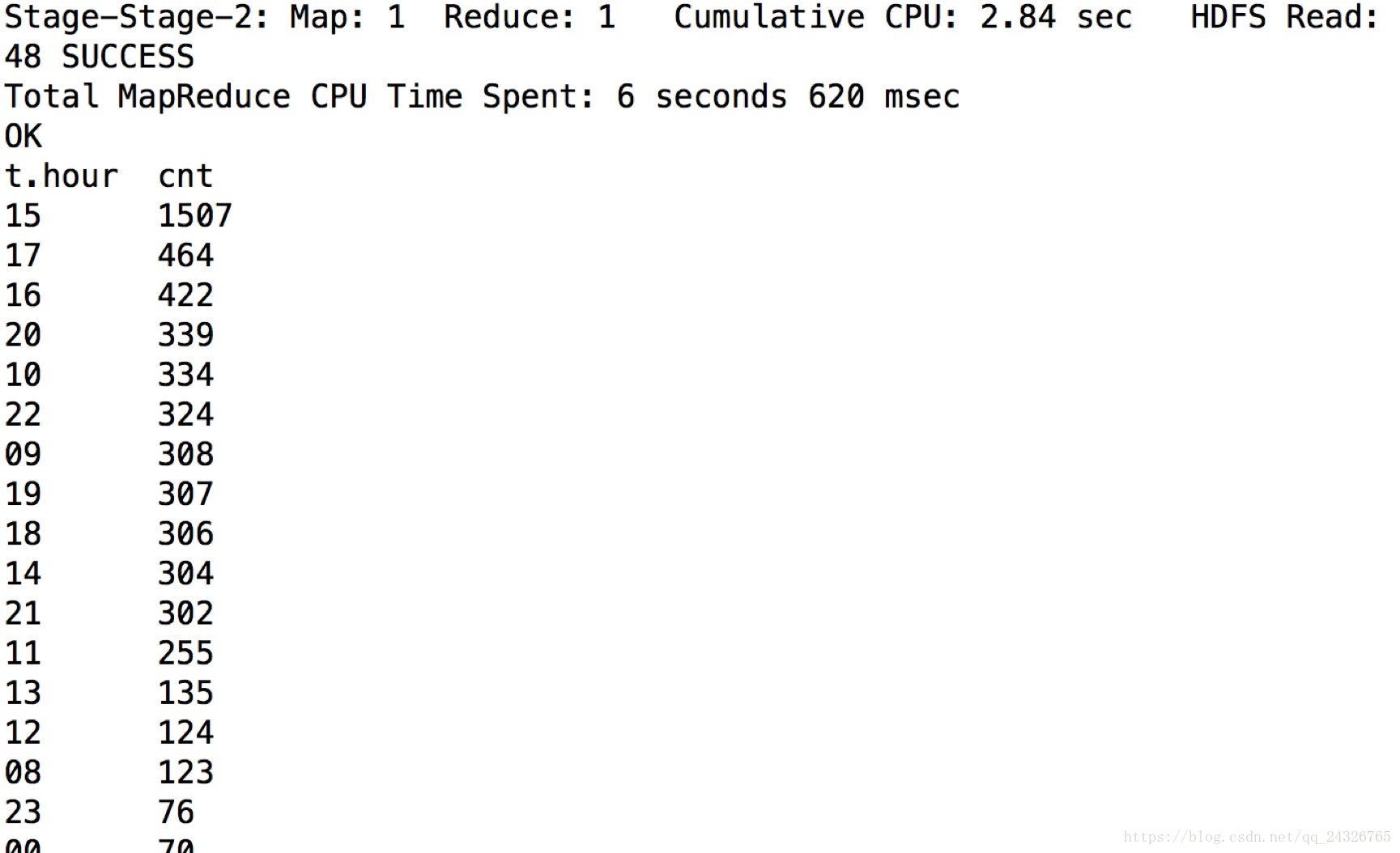
说明用户下午3点到晚上10点看视频较多。
需求2:

因为ip段有的两位有的三位,为了全部都是3位,可用mapreduce进行字符串拼接补0,但是字符串拼接太耗内存。所以还是用UDF方便。这里暂且用系统自带的函数。
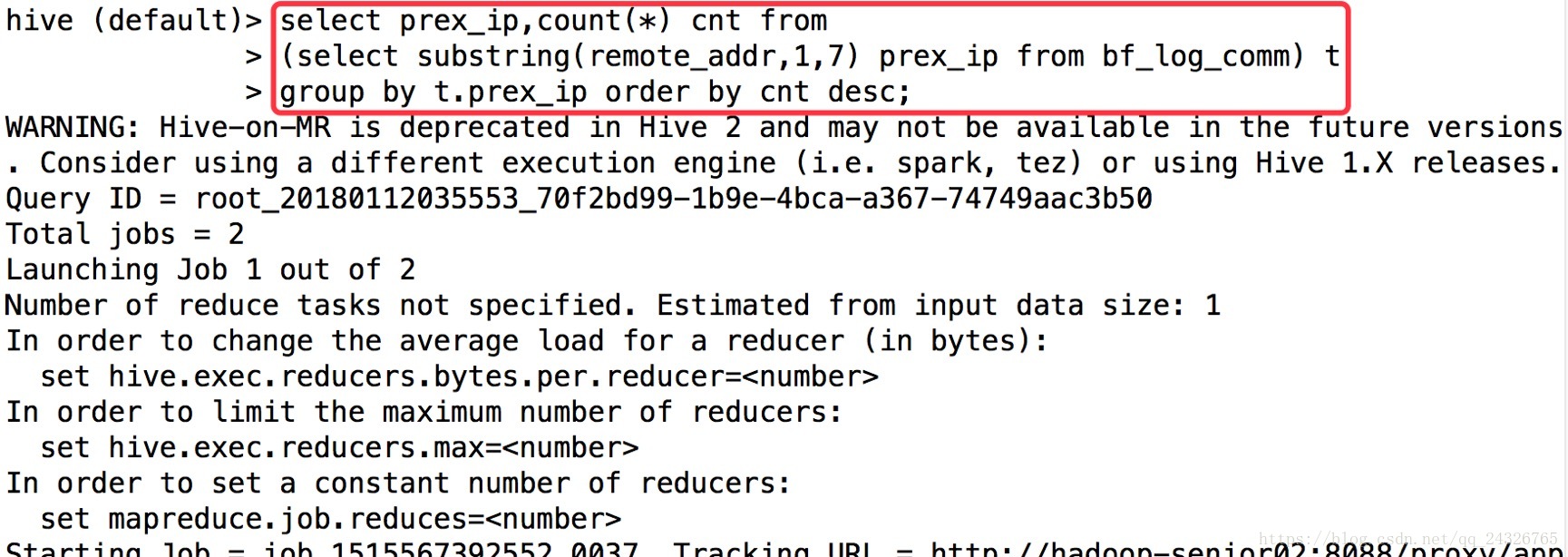
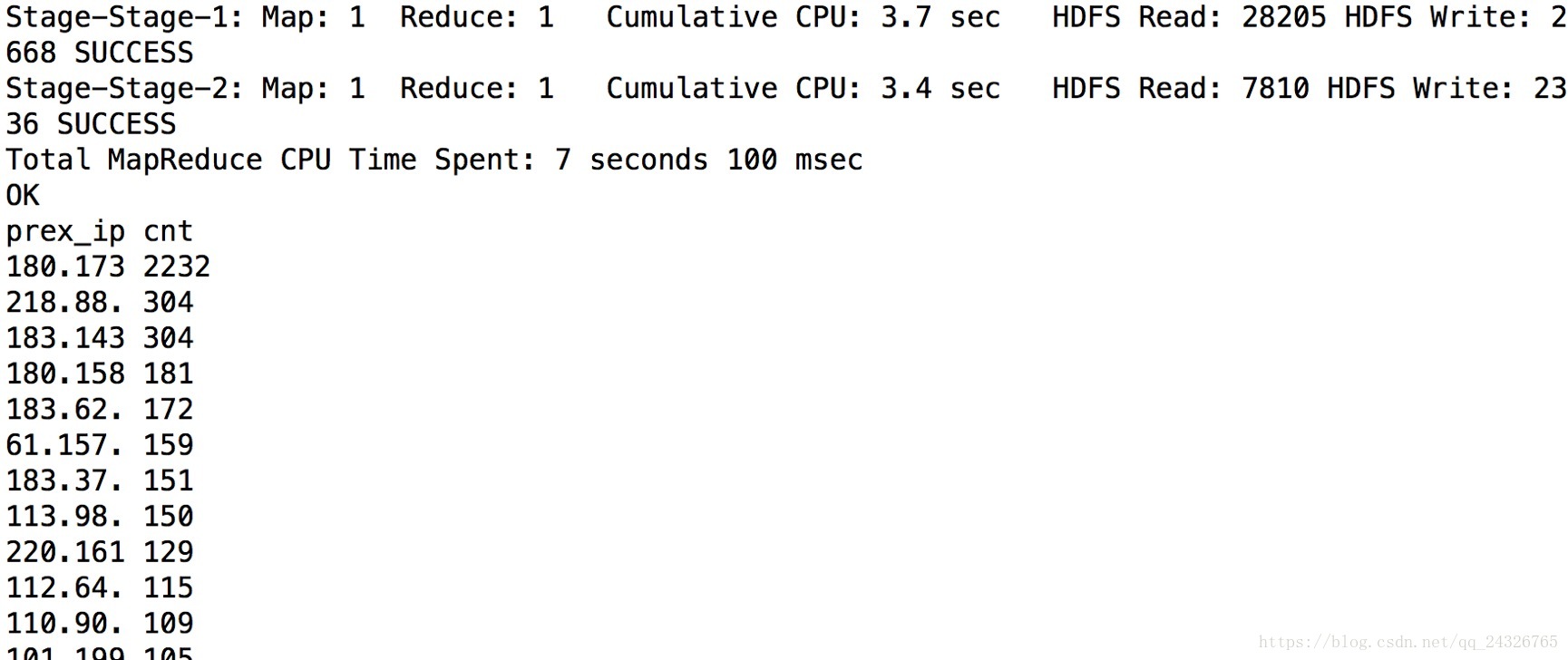
select prex_ip,count(*) cnt from
(select substring(remote_addr,1,7) prex_ip from bf_log_comm) t
group by t.prex_ip order by cnt desc;
11.Hive项目实战七MovieLens数据分析采用python脚本进行数据清洗和统计
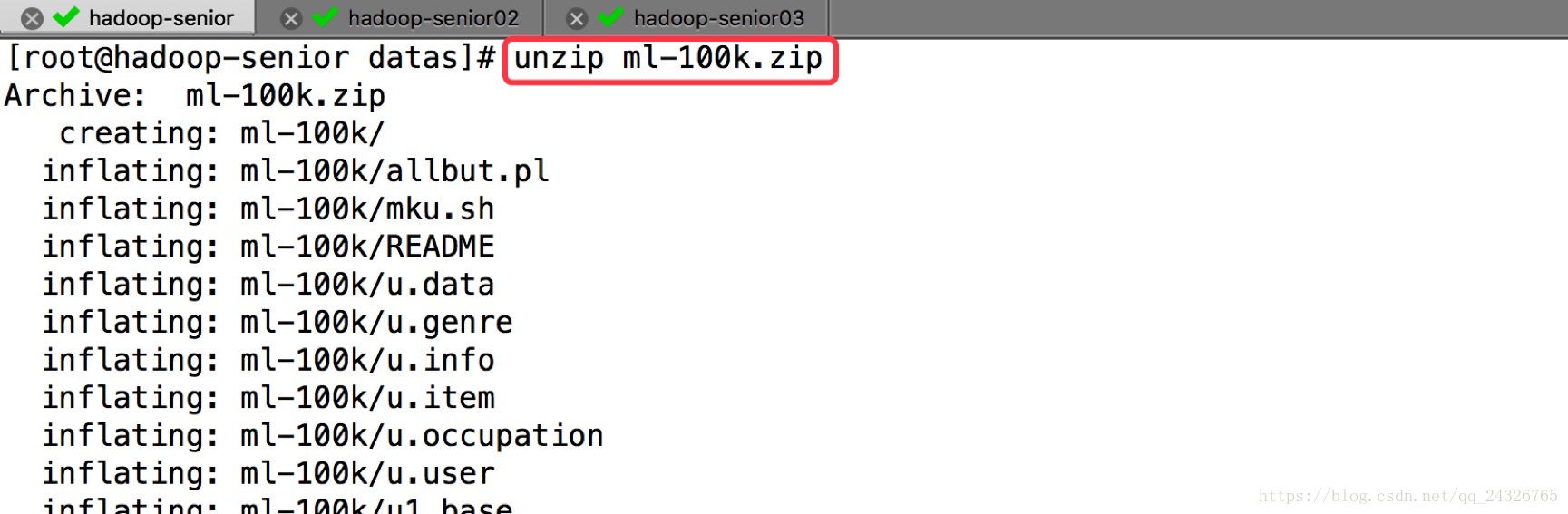
① 下载数据集并解压
https://grouplens.org/datasets/movielens/
( 电影评分网站 )

② 创建原表,并加载数据
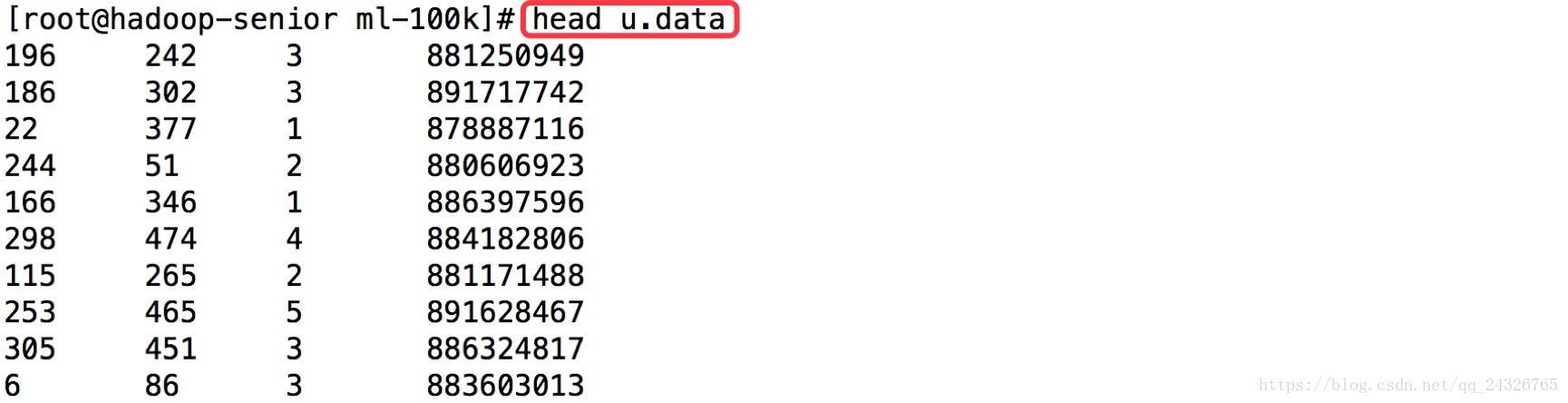
CREATE TABLE u_data (
userid INT,
movieid INT,
rating INT,
unixtime STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
LOAD DATA LOCAL INPATH '/opt/datas/ml-100k/u.data' OVERWRITE INTO TABLE u_data;
③ 创建一个python脚本
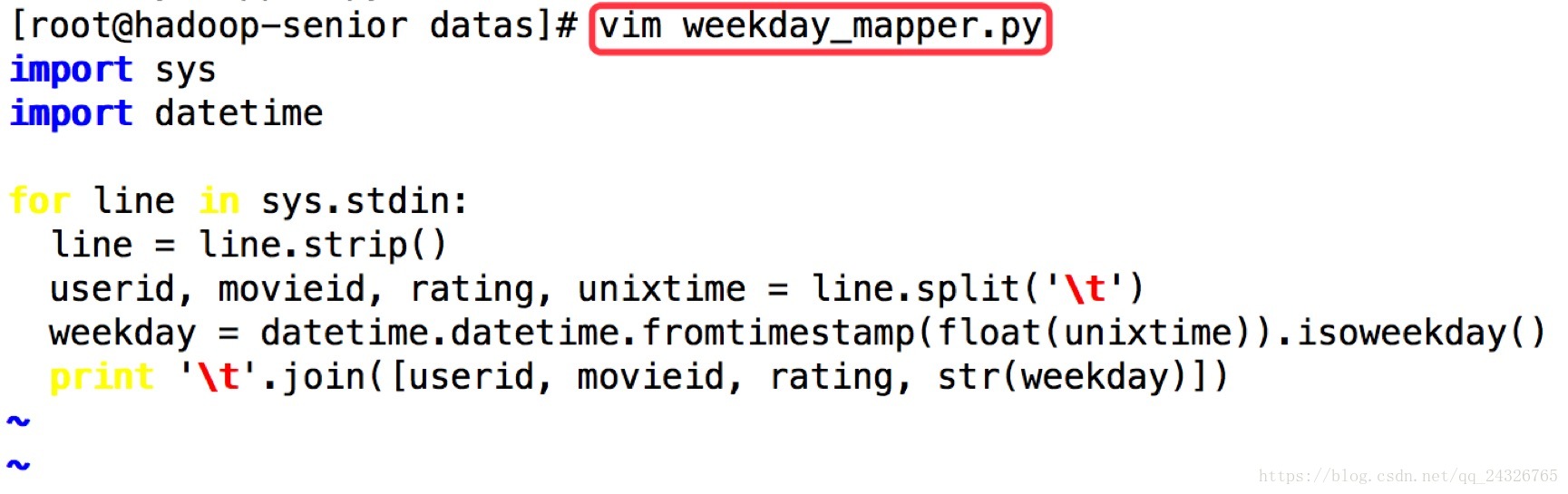
import sys
import datetime
for line in sys.stdin:
line = line.strip()
userid, movieid, rating, unixtime = line.split('\t')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([userid, movieid, rating, str(weekday)])
④ 创建一个hive脚本
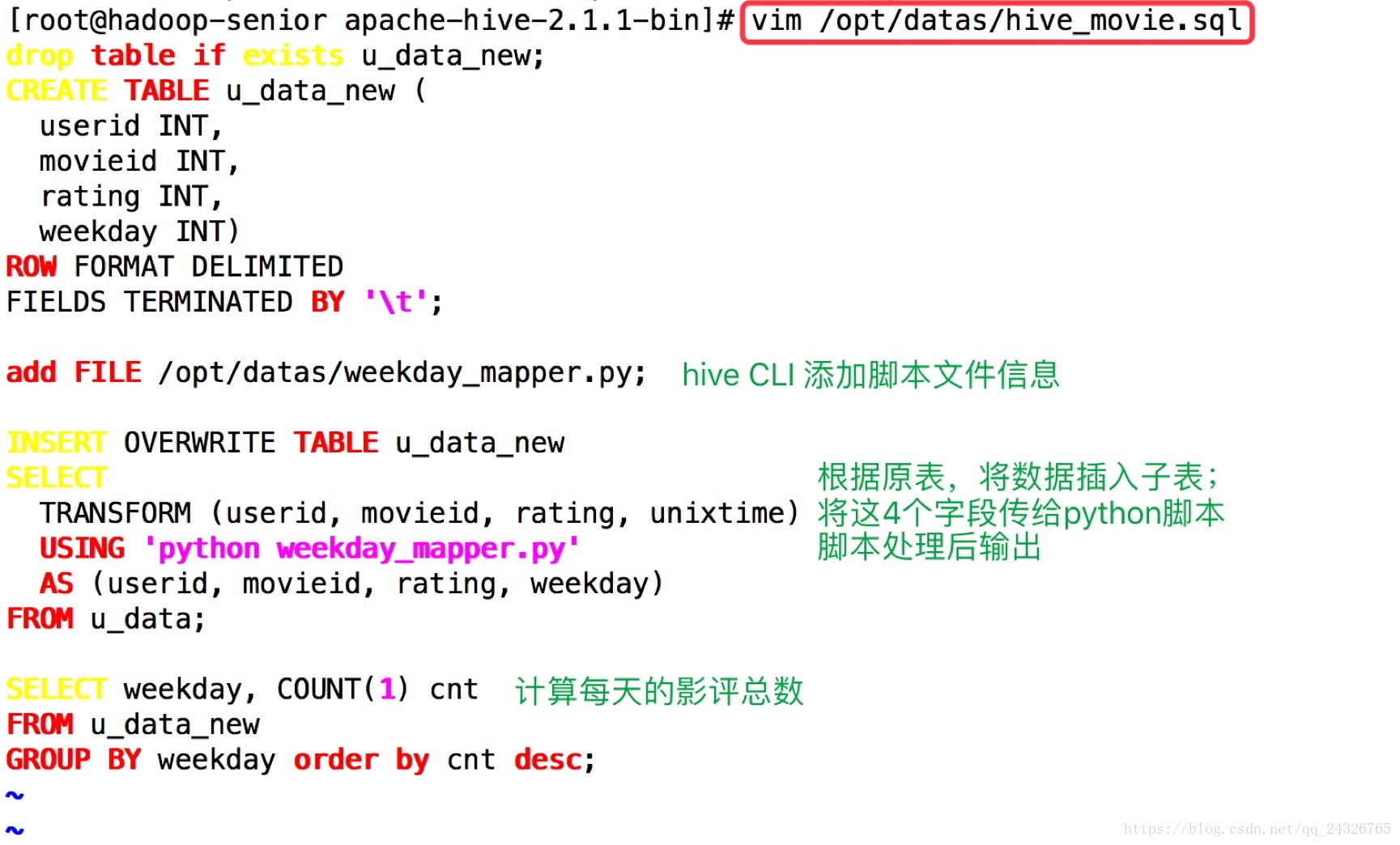
drop table if exists u_data_new;
CREATE TABLE u_data_new (
userid INT,
movieid INT,
rating INT,
weekday INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
add FILE /opt/datas/weekday_mapper.py;
INSERT OVERWRITE TABLE u_data_new
SELECT
TRANSFORM (userid, movieid, rating, unixtime)
USING 'python weekday_mapper.py'
AS (userid, movieid, rating, weekday)
FROM u_data;
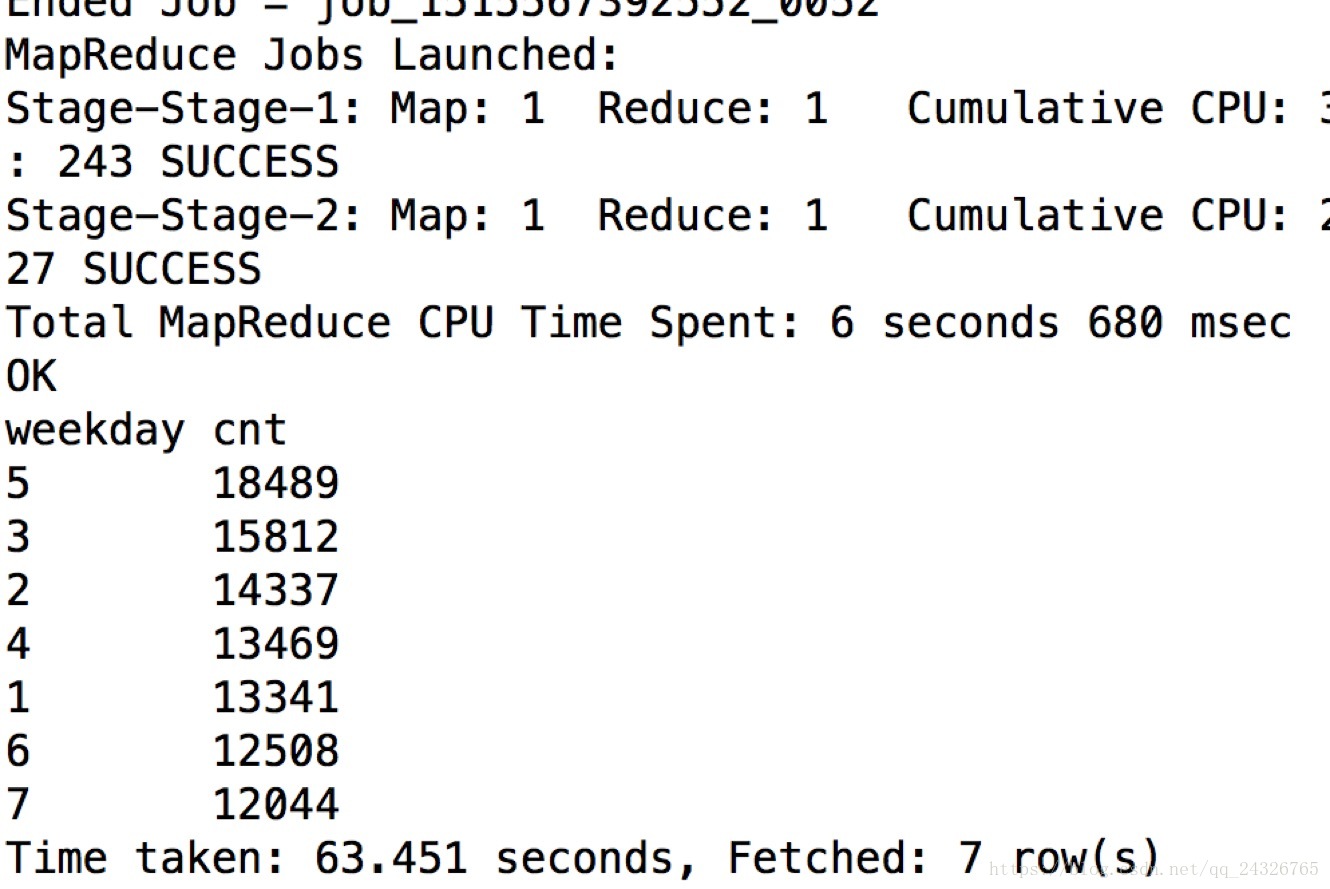
SELECT weekday, COUNT(1) cnt
FROM u_data_new
GROUP BY weekday order by cnt desc;⑤ 执行脚本
bin/hive -f /opt/datas/hive_movie.sql
执行结果: