SVM简介
支持向量机(Support Vector Machines)是一种二分类模型,对于多分类通常将其分解为多个二元分类问题,再进行分类。SVM 的基本模型是定义在特征空间上的间隔最大的线性分类器,SVM 还包括核技巧,这使它成为实质上的非线性分类器。SVM 的学习策略就是间隔最大化,最终可转化为一个凸二次规划问题的求解。
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分隔超平面。如下图所示, 即为分隔超平面。
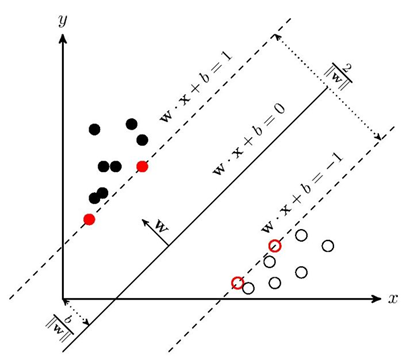
距离分隔超平面最近的点,即空心和实心的红色圆圈即为支持向量(Support Vector)。SVM的目标就是最大化支持向量所在的超平面之间的几何距离,两条平行直线的距离公式推广到高维可求得图中几何间隔距离:
margin=∣∣ω∣∣2
使得 margin 最大,也就等价于使得
2∣∣ω∣∣2 最小,这里的
21 只是为了后续求导后刚好能消去,没有其他特殊意义。再加上使得所有数据能被分开的条件,转换成数学表达即是:
{min2∣∣ω∣∣2s.t. yi(ωxi+b)≥1 i=1,...,m
这是一个凸二次规划问题,一般的优化方法求解不够高效,可以使用拉格朗日乘子法,转换成它的对偶问题求解。其对偶形式如下:
{max∑i=1mαi−21∑i=1m∑j=1mαiαjy(i)y(j)(x(i))Tx(j)s.t. ∑i=1mαiy(i)=0 αi≥0 i=1,...,m
在原始问题下,求解的复杂度与样本的维度有关,即
ω 的维度。在对偶问题下,只与样本数量有关,即改变了问题的复杂度。因为只用求解
α 系数,而
α 系数只有支持向量才非
0,其它全部为
0,使得求解更高效。
对于得到的最优解
α∗ 可以求得:
ω∗=i=1∑mαi∗y(i)x(i)b∗=yj−i=1∑mαi∗y(i)(x(i))Txj
其中式中的
j 是任意一个
αj∗>0 时的
j。此外,当样本点是非支持向量时,因为
ai∗=0,所以,SVM 的解只与支持向量有关,与非支持向量无关,即在决定最佳超平面时只有支持向量起作用,而其他数据点并不起作用。
对于线性不可分的情况,引入“软间隔(soft margin)”允许少量样本不满足约束,将目标函数改为:
minω,b2∣∣ω∣∣2+Ci=1∑mmax(0,1−y(i)(ωTx(i)+b))
其中 C>0 称为惩罚参数,C 越小时对误分类惩罚越小,越大时对误分类惩罚越大,当 C 取正无穷时就变成了硬间隔。实际上应用时需要合理选取 C,C 越小越容易欠拟合,C 越大越容易过拟合。
