原文转载于:http://blog.csdn.net/shichaog/article/details/74143427 有所修改 感谢作者
波束形成
beamforming 体现的是声源信号的空域选择性,许多传统波束形成方法具有线性处理结构;
波束形成需要考虑三个方面:
1.麦克风阵列个数;
2.性能;
3.鲁棒性
在麦克风较少时,波束形成的空域选择性差,当麦克风数量较多时,其波束3dB带宽较窄,如果估计的目标声源方向有稍有偏差,带来的影响也更大,鲁棒性不好。通常鲁棒性和性能是对矛盾体,需要均衡来看。通常波束方向图需要随环境的语音/噪声/干扰等统计信息进行调整,以达到最优滤波。
常见波束形成的准则如最大信噪比准则(maximum signal-to-noise ratio MSNR),最小均方误差(minimum mean-squared error, MMSE), 线性约束最小方差(linearly constrained minimum variance, LCMV)。
多通道维纳滤波波束形成使用了最小均方误差MSE准则,波束形成方法使用信号统计特征(一阶,二阶…),信号和噪声的统计特性通常又是变化的,如人走动,屋内物品移动,外界噪声源变动等,这就需要使用短时平稳和自适应方法来进行波束形成。
webrtc使用了如下几个点以提高鲁棒性和性能(其算法性能优先):
1.可以使用多个后置滤波器而非一个,2.每个后置滤波使用新的结构。
每个后置滤波器为每个声学场景的时频域bin在均方误意义上提供了最优实增益。在webrtc中后置滤波器根据声源的空域协方差矩阵,干扰源协方差矩阵,绕射场(零阶贝塞尔函数计算)以及临近麦克风的时频信号信息求得。
这样的话就可以为每个声源和干扰场景计算出不同的最优后置滤波器,也可以使用级联的方式灵活使用多个不同选择性的后置滤波器。
当前现存的波束形成算法的鲁棒性成为它们使用的一道门槛,如MVDR和多通道维纳滤波。
webrtc为了增强鲁棒性,在求最优矩阵时,对声源信号添加了限制条件,使用Gabor frame将声源变成时频bin的系数,对这些bin按照目标声源和干扰声源附加了条件,如果满足条件,则门操作让目标声源通过,而让干扰源乘以零以实现选择最优目标信号。
在webrtc中这些增益系数称为自适应标量(上面的实)乘法增益,均方误差准则被用来做为计算的准则。由于阵列方向响应随频率是变换的,而语音信号又是宽带信号,所以webrtc中使用了gabor变换来表示声音信号。增益源于目标信号和干扰的比例。
波动方程常有波数这个参数,相位的信息是通过实部和虚部表示出来的,列两个重要的参数。
声场
对于中高音,声音在室内以反射和散射为主,这一过程不断重复和往复直到能量变成零(吸收和传输损耗),这一过程约有16次之多。对于低音室内更像一个谐振腔,波长满足谐振条件的声波将会被放大,随着说话位置的位置变化,增强和对消的低音频率也会变化。
Schroeder frequency:
室内声音的谐振腔频率和反射/散射频率的分界点。对于居家室内场景该频率一般在100Hz~200Hz之间,在室内播放一个谐振频率的声波,人在室内不同的位置听到的音量差异是比较明显的,而对于中高音差别并不明显。
散射噪声场:
散射噪声场中,噪声能量向各个方向传播的概率是相等的。
包含若干个来自方向上均匀分布的相位随机的平面波,
假设 在声速为 0 c 的静止介质中,存在 N 个单极子声源,其角频率,对应的波数即为 k=角频率/声速,位置为x,强度为q,空间中任意一点的声波压强表达式如下:
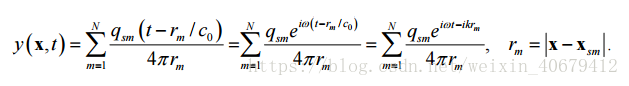
相干和非相干噪声
相干噪声 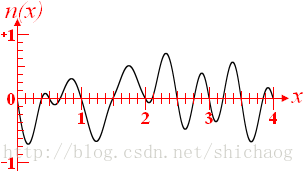
横轴是归一化频率(f=2)
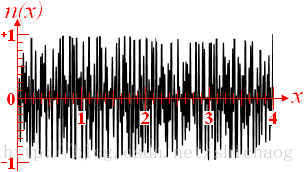
非相干噪声
波动方程
波数(k)
沿着波的传播方向单位长度内波的全周期数。k=1/波长=fck=1/波长=fc,也可定义成k=2π/波长k=2π/波长,这样可以理解成相位随距离的变化率。满足Nyquist抽样准则:Ts≥2fmax
近场和远场
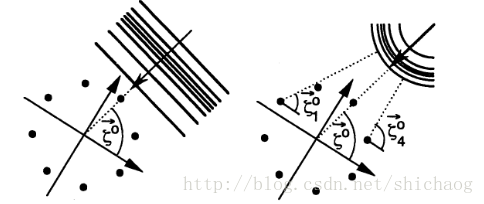
远场模型可以看成是平面波(左),传播方向是ζ0→,远场要看成是球面波(右),传播方向是ζ0m→
由于1.麦克风阵列间距相对于说话人距离1.5m/2.5cm≈601.5m/2.5cm≈60倍,假设符合远场模型。
固定波束形成
滤波器权值固定,方法简单,运算量低,能够抑制背景噪声,对可变噪声场,效果一般。
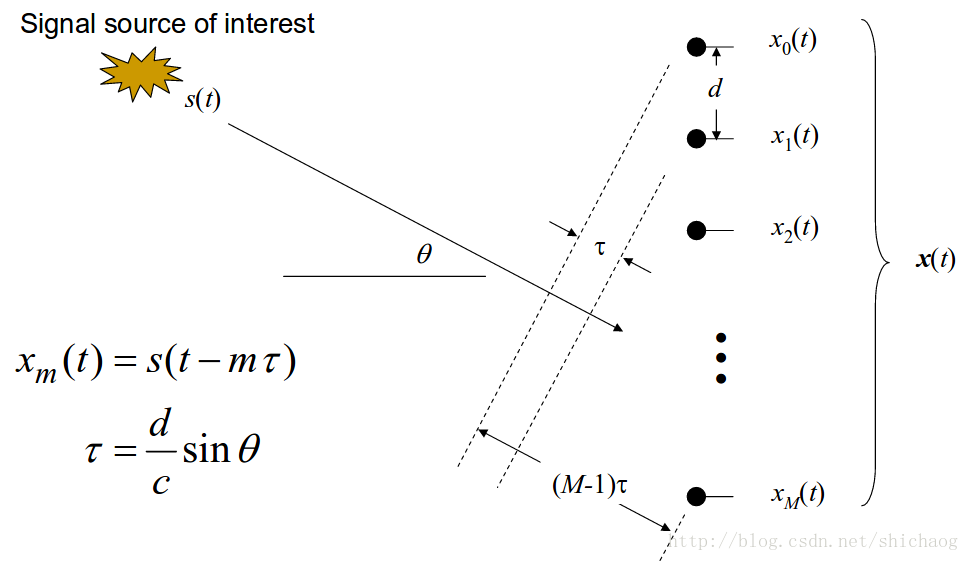
delay-sum
延迟求和 算法是最简单的波束形成方法,通常称为传统波束形成(Conventional BeamingForming)。一般用在电话会议场景,对非相干噪声效果较好,如空间白噪声,然而,如果噪声源是相干的,降噪的程度依赖于噪声的方向,在室内混响场景下,并不能获得很好的效果。
设输入信号是s(t)s(t),叠加噪声是加性的n(t)n(t),则第m个麦克风观测到的信号是:
xm(t)=s(t)+nm(t)xm(t)=s(t)+nm(t)
则将每一路信号经过冲击响应延迟后再相加可以得到时间匹配上的信号。
则延迟和输出是:
y(t)=∑m=0M−1wmxm(t−[M−m−1]T)y(t)=∑m=0M−1wmxm(t−[M−m−1]T)
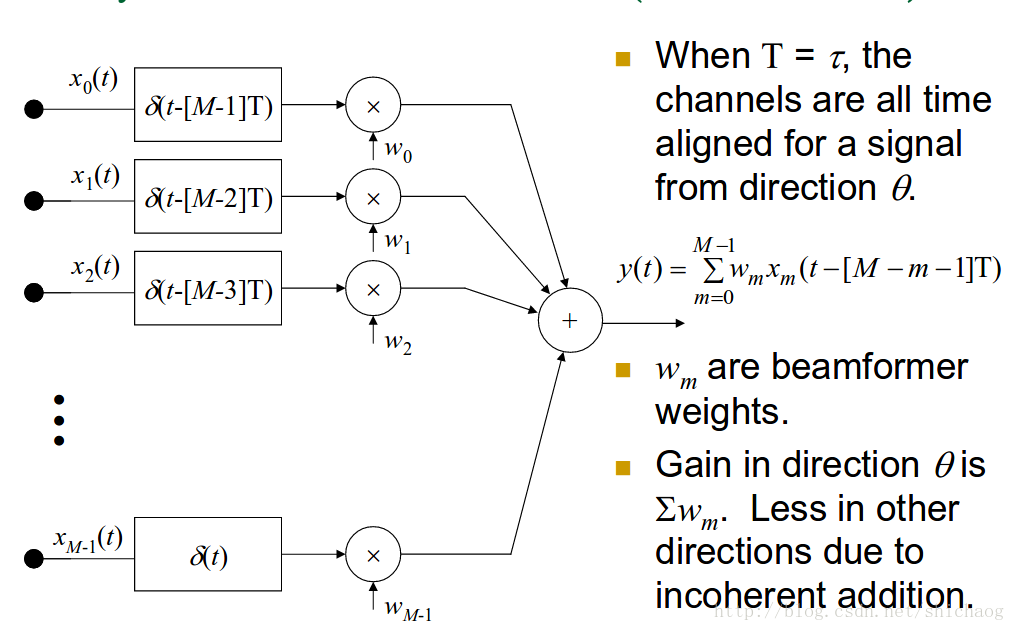
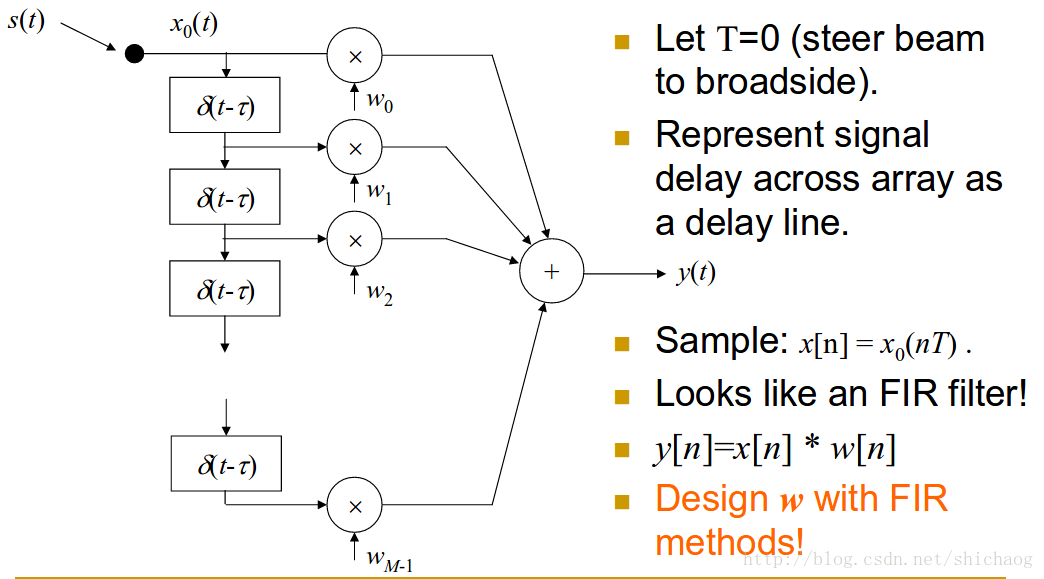
filter-and-sum
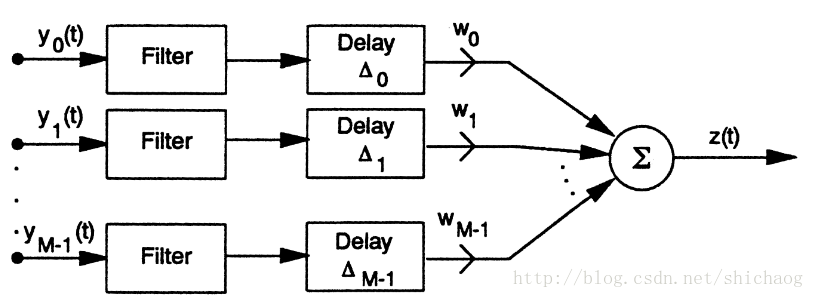
和delay-sum相比其使用了幅度和相位不一致的权重。
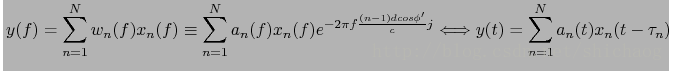
自适应波束形成
如Frost/mvdr等,在相干噪声场,可以得到较高的信噪比改善,但是在弱相干噪声场和在散射噪声场中,性能不如固定波束形成。其一种结构可以如下:

后置滤波作用
可以用来去除非相干噪声,但是在相干噪声情况下性能退化,甚至不可用。zelinski后置滤波器的结构体如下: 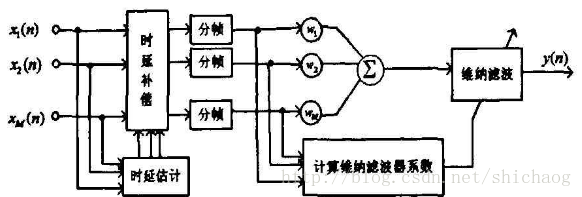
apab(adaptive post-filter for an arbitrary beamformer) 后置滤波器 
通常将自适应滤波器和后置滤波器结合起来以抑制相干和非相干噪声。
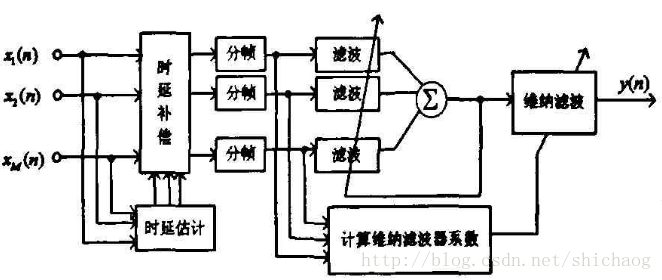
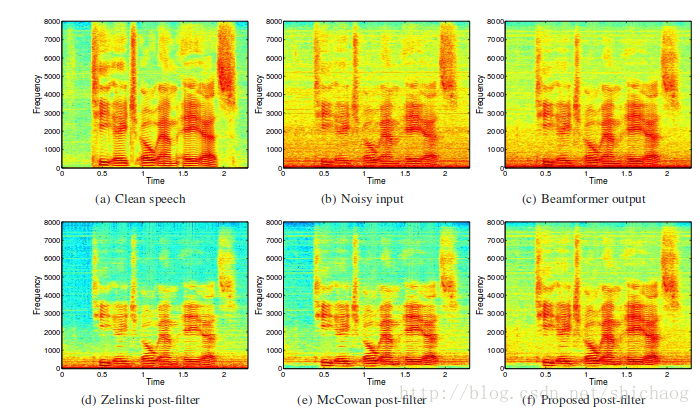
一张频谱图,可以反映它们之间的对比关系