麦克风阵列入门(一)
什么是麦克风阵列:
所谓麦克风阵列其实就是一个声音采集的系统,该系统使用多个麦克风采集来自于不同空间方向的声音。
为什么使用麦克风阵列:
麦克风按照指定要求排列后,加上相应的算法(排列+算法)就可以解决很多房间声学问题,比如声源定位、去混响、语音增强、盲源分离等。
【注】:在深入理解概念之前,我们先理解一下麦克风的知识
什么是麦克风的指向性(方向性):
麦克风的方向性是指麦克风可以接收到语音的方向。声音可以从不同的方向传达到麦克风,麦克风的前面/后面/侧面,麦克风将会根据自身的指向性来获取声音。
一个麦克风可以以很高的灵敏度接收来自于前方的声音,而不管后方和侧面的声音,另一个麦克风还可以接收来自于前面和后面的声音,而不管侧面的,有很多种组合。
什么是指向性麦克风:
所谓指向性麦克风是指麦克风要么接收来自于指定方向的声音,要么接收所有角度传来的声音,这取决于麦克风的自身指向属性。
常用的指向性麦克风:
-
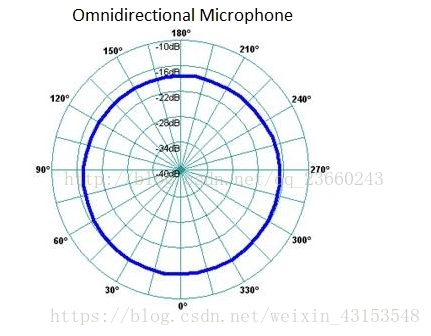
全向麦克风
有些麦克风接收来自于任何方向的声音,这种麦克风叫做全向麦克风( omnidirectional microphones)。不管说话的人在哪里对着麦克风说话,前后左右,从0°到360°,所有的这些声音都会以相同的灵敏度被拾取。
-
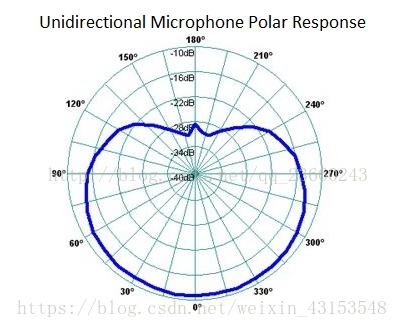
单向麦克风
其他的一些麦克风是单向的( unidirectional),他们仅仅接收从指定方向来的声音。当人们对着单向麦克风说话时,要慎重选择对着麦克风的方向。我们必须要对着“接收方向”说话来获得更好的声音增益,任何不同于此方向的声音都会被削弱接收,这也就意味着增益很小。
-
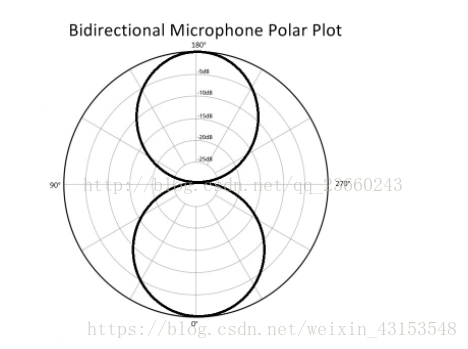
双向麦克风
另外一种麦克风叫做双向麦克风(bidirectional microphone),这种麦克风可以很好的接收来自于前向和后向的声音,但是两侧的声音增益很小。他在隔膜的相对两侧拾取具有相等灵敏度的声波,与隔膜成直角的指向null。
-
心型麦克风
另外一种是心型麦克风( cardioid microphone),它可以接收来自于前方和两侧的声音,但是后面的声音的增益很小。事实上,他们名字来源于他们的声音拾取方向,非常的像一个心。
注意:这里没有任何一种麦克风可以说比别的怎么怎么好,不同种类的麦克风在不同的使用环境下有各自的优缺点。从上面看起来,全向麦克风比其他的要好,因为它可以接收来自于所有方向的声音而不是仅仅一个方向,但是试想如果在一个比较嘈杂的环境下,全向麦克风是一个比较low的选择,因为除了我们所需要的声音外,他还录了周围的噪音。在这种环境下,指向性(非全指向性麦克风)麦克风可能会更好,因为他在获取我们所需要方向的声音外,对其他方向的声音进行了压制,使得噪声的增益非常少。所以,这些麦克风的好坏取决于用的环境。

麦克风的排列及原理:
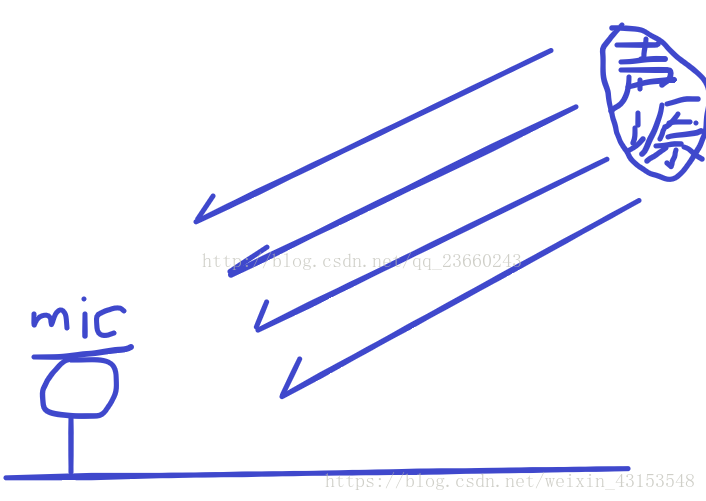
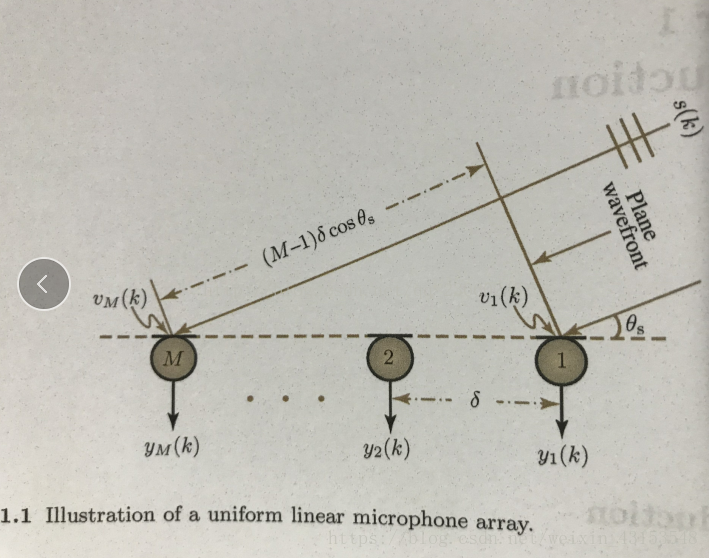
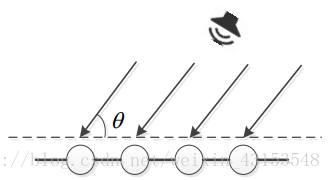
麦克风不同的排列对应不同的算法,那么最简单的排列就是线性排列了,也就是麦克风排列成一排。在远场(指说话人距离麦克风很远)的情况下,我们一般认为人说话的波形是平面波,如下:
那么每个麦克风接收到的信号在同一时刻都不会相同,因为有时延,你可能会问什么是时延,那么下面给出具体的统一线性麦克风阵列模型图:
这个模型具体参数此处不做讲解,很简单直白。那么从这里我们可以看出来,每个麦克风接收到的数据ym(k)与之前的麦克风接收到的数据之前存在延迟。其公式如下:
时间延迟如下(c是声速340m/s):
一般我们都是转化到频域去处理,所以将上述傅里叶变换后得到(别问我傅里叶变换是什么):
切记,这里都是原式子的傅里叶变换后的形式。
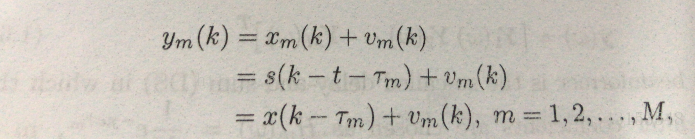
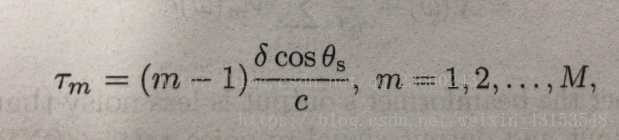
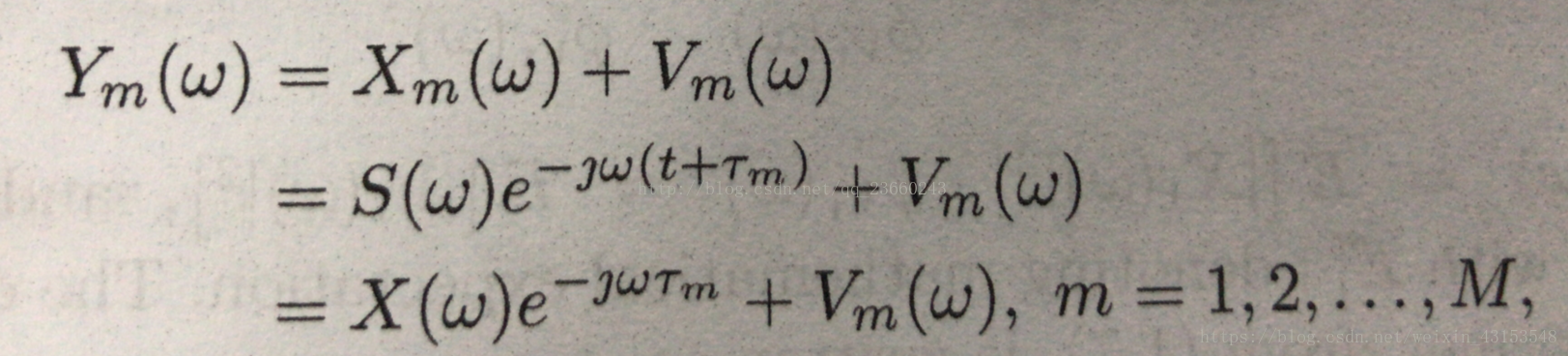
好了,理论模型推理到这里,那么开始看我们手头有什么数据,说白了,方程中有哪些参数我们是已知的,ym(k)是已知的,这就是我们的麦克风接收到的数据呀,术语观测数据。这时候不要脑袋一热就开始根据模型往回带数据,模型仅仅是为我们提供参考思路(即使想带回去也不行,vm根本就未知)。
得知观测数据的我们,需要从观测数据中抽离我们想要的内容,那么很自然的想到滤波器。我们称这种滤波器叫做:波束形成滤波器(因为它增强了我们想要的内容,削弱了我们不想要的内容,跟前面的指向性麦克风联系起来,是不是感觉世界很奇妙):
其中:
而这个得到的Z,就是我们所要求的。
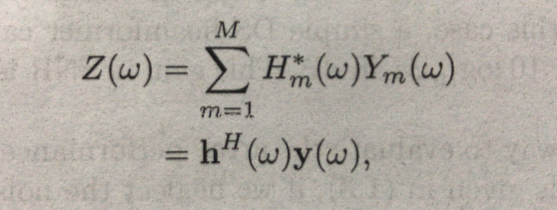
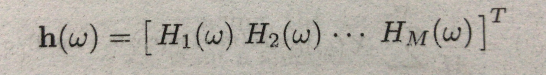
问题到了这里变得很清晰,如何估计这个滤波器。波束增强有很多种算法,有很多种估计滤波器的方式,从简单到复杂,从效果差到效果好,各有不同。那么我们这里说一下基于我们上面模型的最简单的delay-and-sum(DS)滤波器,他的效果用一句话概括就是:我们仅仅把各个麦克风接收到的信号补偿他们的时延,然后求一个均值,没有考虑混响等实际场景可能发生的情况。那么,我们的Z如下:
从而我们用最简单的办法得到了我们所要的信号,其性能评估等后续说明。
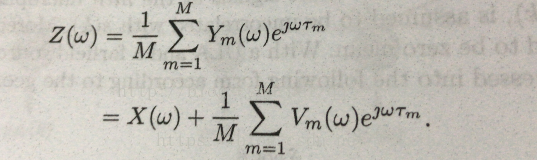
麦克风阵列原理二
1 麦克风阵列
麦克风阵列,是一组位于空间不同位置的全向麦克风按一定的形状规则布置形成的阵列,是对空间传播声音信号进行空间采样的一种装置,采集到的信号包含了其空间位置信息。根据声源和麦克风阵列之间距离的远近,可将阵列分为近场模型和远场模型。根据麦克风阵列的拓扑结构,则可分为线性阵列、平面阵列、体阵列等。
(1) 近场模型和远场模型
声波是纵波,即媒质中质点沿传播方向运动的波。声波是一种振动波,声源发声振动后,声源四周的媒质跟着振动,声波随着媒质向四周扩散,所以是球面波。
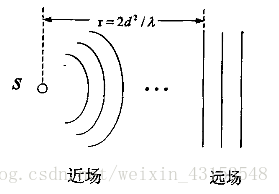
根据声源和麦克风阵列距离的远近,可将声场模型分为两种:近场模型和远场模型。近场模型将声波看成球面波,它考虑麦克风阵元接收信号间的幅度差;远场模型则将声波看成平面波,它忽略各阵元接收信号间的幅度差,近似认为各接收信号之间是简单的时延关系。显然远场模型是对实际模型的简化,极大地简化了处理难度。一般语音增强方法就是基于远场模型。
近场模型和远场模型的划分没有绝对的标准,一般认为声源离麦克风阵列中心参考点的距离远大于信号波长时为远场;反之,则为近场。设均匀线性阵列相邻阵元之间的距离(又称阵列孔径)为d,声源最高频率语音的波长(即声源的最小波长)为λmin,如果声源到阵列中心的距离大于2d2/λmin,则为远场模型,否则为近场模型,如图1所示。
(2) 麦克风阵列拓扑结构
按麦克风阵列的维数,可分为一维、二维和三维麦克风阵列。这里只讨论有一定形状规则的麦克风阵列。
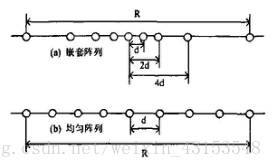
一维麦克风阵列,即线性麦克风阵列,其阵元中心位于同一条直线上。根据相邻阵元间距是否相同,又可分为均匀线性阵列(Uniform Linear Array,ULA)和嵌套线性阵列,如图2所示。均匀线性阵列是最简单的阵列拓扑结构,其阵元之间距离相等、相位及灵敏度一直。嵌套线性阵列则可看成几组均匀线性阵列的叠加,是一类特殊的非均匀阵。线性阵列只能得到信号的水平方向角信息。
图2 线性阵列拓扑结构
二维麦克风阵列,即平面麦克风阵列,其阵元中心分布在一个平面上。根据阵列的几何形状可分为等边三角形阵、T型阵、均匀圆阵、均匀方阵、同轴圆阵、圆形或矩形面阵等,如图3所示。平面阵列可以得到信号的水平方位角和垂直方位角信息。
图3 平面阵列拓扑结构
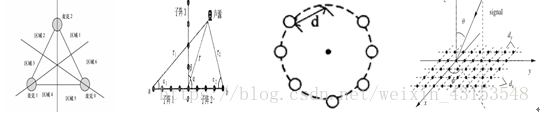
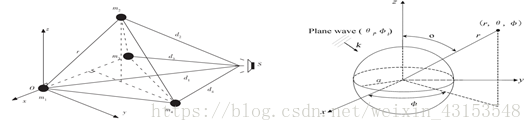
三维麦克风阵列,即立体麦克风阵列,其阵元中心分布在立体空间中。根据阵列的立体形状可分为四面体阵、正方体阵、长方体阵、球型阵等,如图4所示。立体阵列可以得到信号的水平方位角、垂直方位角和声源与麦克风阵列参考点距离这三维信息。
图4 立体阵列拓扑结构
2 波束形成
波束形成,是对各阵元的输出进行时延或相位补偿、幅度加权处理,以形成指向特定方向的波束。
在远场模型中,假设输入是一个平面波。设传播方向为θ,时域频率(弧度)为ω,声音在介质中的传播速度为c,对于在一个局部均匀的介质里传播的平面波,定义波束k为
k = ωsinθ/c = 2sinθ/λ,其中λ是对应于频率ω的波长。由于信号到达不同的传感器的时间不同,则阵列接收到的信号可表示为
f(t)=[f(t-τ0) f(t-τ1)…f(t-τN-1)]T=[exp(jω(t-kτ0)) exp(jω(t-kτ1))…exp(jω(t-kτN-1))]T
其中τn为第n个阵元接收到的信号相对于参考点的时延,N为阵元个数,T表示转置。
定义v(k) = [e-jωkτ0 e-jωkτ1 …e-jωkτN-1]T
矢量v包含了阵列的空间特征,称为阵列流行矢量。则f(t)可表示为f(t) = ejωtv(k)。
阵列处理器对一个平面波的响应为y(t,k) =HT(ω) v(k)ejωt
注意此处ω对应单一的输入频率,所以是窄带的。阵列的空时处理关系完全可以由上式的右端描述,称为阵列的频率-波数响应函数。它描述了一个阵列对于时域频率为ω,波数为k的输入平面波的复增益。
阵列的波束方向图反映了平面波在一个局部均匀的介质中传播情况,它是用入射方向表示的频率-波数响应函数,可以写成B(ω:θ) = Y(ω,k)|k=sinθ。
阵列的波束方向图是确定阵列性能的关键要素,其主要参数有3dB带宽,到第一零点的距离,第一旁瓣高度,旁瓣衰减速度等。其幅度的平方定义为功率方向图,是常用的一种阵列性能度量。
3 时延补偿
由于麦克风阵元空间位置的差异,各阵元接收到的信号存在时延,在对信号处理之前进行时延补偿,保证各阵元待处理数据的一致性,使阵列指向期望方向。
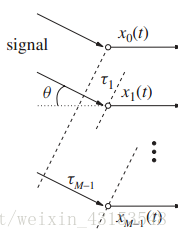
考虑最简单的均匀线性麦克风阵列,如图5所示。
图5 ULA时延
设麦克风阵列共用M个阵元,中心为参考点,阵元间距为d,信号入射角为θ,声音传播速度为c,则根据几何知识,第m(0≤m≤M-1)个阵元的时延为τm = (d/c) sinθ(m-(K-1)/2)。
麦克风采集的是数字信号,设采样周期为T,则对时域离散的信号来说,时延为D = τ/T。
通常D不是一个整数,而对离散信号来说,整数时延才有意义。对于非整数D,可以分解为整数部分和分数部分D = ⌊D⌋ + d,式中,⌊D⌋为D的向下取整,0≤d<1。对于非零的分数部分d,此时信号实际值介于两个相邻采样点之间,即分数延迟。在实际处理中,可对d四舍五入取整,然后加上⌊D⌋,得到近似整数时延,但这种方法处理的结果不够精确。
为了得到较为精确的处理结果,就必须设计分数时延滤波器,对采样信号进行精确的时延补偿。理想的分数时延滤波器的冲激响应可表示为hid(m) = sinc(m-D)。
由数字信号处理知识可知,上式是无限长、非因果不稳定的,在物理上不可实现。为了解决这一问题,在实际操作中,通常会对上式进行加窗,加窗后滤波器的冲激响应为
h(m)=(W(m-D)sinc(m-D), 0≤m≤M-1。加窗后的分数时延滤波器的时延精确程度与理想分数时延滤波器非常接近。
麦克风阵列语音增强(二)
1. 时域GSC自适应波束形成算法(Griffiths-Jim)
图 2-1 Griffiths-Jim的时域GSC自适应波束形成算法
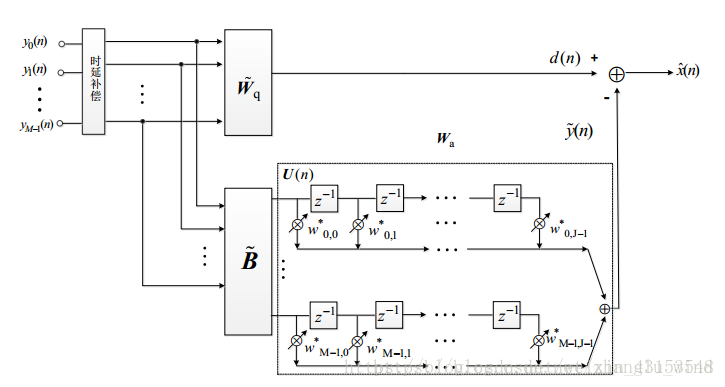
在这个专题中,将对Griffiths于1982年提出的经典时域GSC算法进行实现,并利用爱丁堡大学语音实验室开发的麦克风阵列仿真环境(之前已经单独介绍过了)进行实验测试。首先是,GSC算法的设计,算法结构框图如上图2-1所示。根据其结构,我们需要设计的部分是三个矩阵部分:固定波束形成部分的静止矩阵(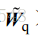
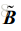
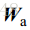
如上式(1-1)和(1-2)所示,对于阻塞矩阵采用的是 [1,-1] 形式的相邻麦克风对减方式,静止矩阵采用的是求和平均的方式(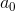
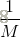
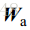

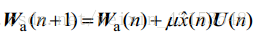
其中,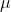
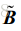
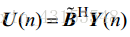
图 2-2 平面波入射模型

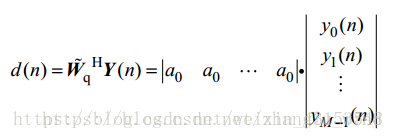
2. 实验仿真测试
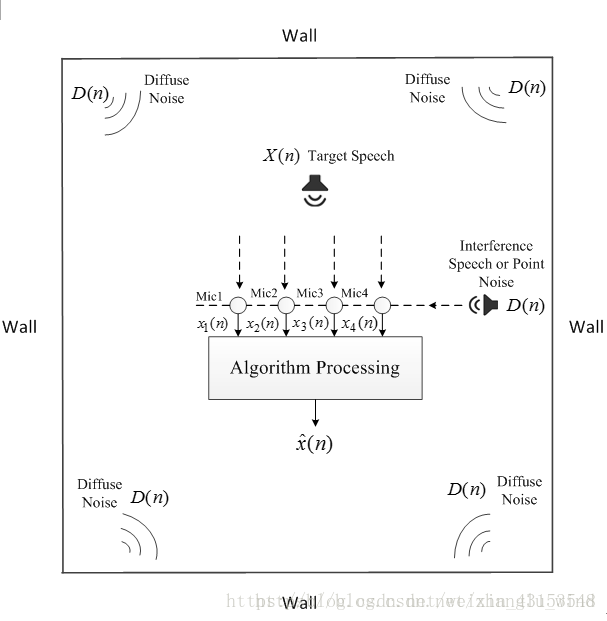
利用之前介绍的麦克风阵列仿真环境,模拟了一个长宽高为3m *4m *3m 的密闭房间,房间混响为0.1s,采用4个麦克风的均匀线性阵列(麦克风间距5cm),将其放置在房间的正中央,目标声源位于麦克风阵列正前方方向(省去了时延补偿的工作),距离麦克风阵列1.4m。另外,对具有明确方向性的语音干扰、点噪声源干扰和无方向性的散漫噪声情况进行实验测试。语音干扰和点噪声源干扰都来自麦克风阵列的右侧90度方向,且距离麦克分1m,散漫噪声以球形场的形式均匀分散在房间中,如下图2-3所示。
图 2-3 实验仿真环境设置
2.1 语音干扰情况
在麦克风阵列的一些应用场景中,语音干扰的情况十分常见,比如说,在一个房间内正在进行多媒体远程会议,这时就希望麦克风阵列只捕捉我们想要的目标声源(会议发言人),抑制那些来自干扰方向的噪声(例如,非发言人的干扰语音)。针对这种情况进行实验测试,结果如下图2-4所示。其中,图2-4中的(a)和(b)是目标声源和干扰声源分别说话时的算法处理前后的结果(目标源先说话,干扰源再说话),(c)和(d)是同时说话时的算法处理前后的结果。从时域波形图的结果可以看出,干扰声源的幅度被明显地降低了,由此可见,GSC算法可以实现有效地空间滤波性能。
图 2-4 语音干扰情况的时域波形图
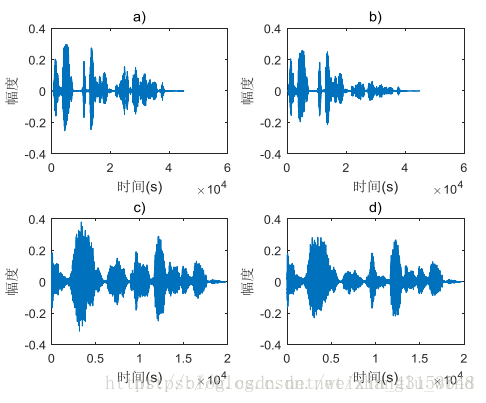
2.2 点噪声源干扰情况
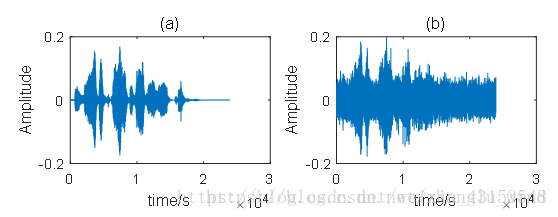
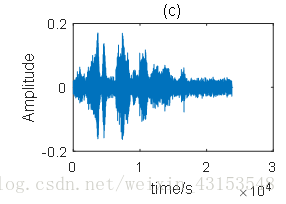
点噪声源和语音干扰的情况类似,只是干扰信号不是语音而是固定方向传过来的噪声,例如在房间内有一个窗户,窗外有一辆汽车经过,那么从窗户传进来的汽车噪声就是点噪声源。对于点噪声源的情况,实验测试了白噪声的情况(0dB的输入信噪比),如图2-5所示。其中,(a)是纯净语音的时域波形图,(b)和(c)分别是点噪声源干扰的语音和算法处理后的去噪语音。显然,GSC算法可以有效地抑制具有明确方向性的点噪声源干扰,使得点噪声源的信号幅度被衰减。
图 2-5 点噪声源干扰情况的时域波形图
2.3 散漫噪声源干扰情况
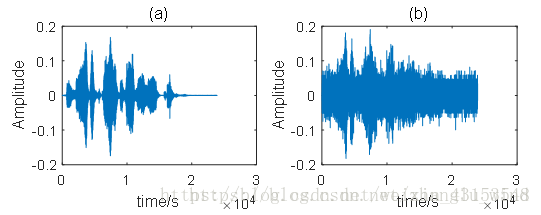
对于散漫噪声,采用的是球形噪声场的数学模型模拟产生,因此它并没有明确的方向性,在整个房间内均匀存在,是实际生活中比较常见的噪声类型。这里仍然采用白噪声作为散漫噪声源(输入信噪比为0dB),实验测试结果如下图2-6所示。其中(a)为纯净语音信号的时域波形图,(b)是被散漫噪声源污染的语音信号,(c)为GSC算法处理后的去噪语音信号。从实验结果中发现,GSC算法对散漫噪声的抑制能力比较弱,也就是说,当空间中的噪声不具有方向特性时,GSC算法的空间滤波优势将大大减弱,这也是麦克风阵列波束形成算法的缺陷所在。
图 2-6 散漫噪声源干扰情况的时域波形图
参考文献:
Griffiths L J, Jim C W. An alternative approach to linear constrained adaptive beamforming[J]. IEEE Trans Antennas & Propag, 1982, 30(1):27-34.
语音增强
1.1 语音增强概况
语音增强,英文名:Speech Enhancement,其本质就是语音降噪,换句话说,日常生活中,麦克风采集的语音通常是带有不同噪声的“污染”语音,语音增强的主要目的就是从这些被“污染”的带噪语音中恢复出我们想要的干净语音。
语音增强涉及的应用领域十分广泛,包括语音通话、电话会议、场景录音、军事窃听、助听器设备和语音识别设备等,并成为许多语音编码和识别系统的预处理模块。举几个简单的例子,在手机的语音助手中,例如苹果的Siri、微软的小娜属于这其中的佼佼者,他们在近距离(一般工作距离小于1米)、无噪声的环境中进行语音识别,有着较高的语音识别准确率,但是如果我们的声学场景变得更加复杂,比如展会,街道等场景中,噪声的影响会大大降低他们的语音识别准确率,因此进行语音识别的前端降噪显得十分重要。此外,在一些助听器设备中,语音增强技术也有其应用。通常的助听器,只是实现一个语音的基本放大,复杂一些的会进行声压级压缩以实现对患者听觉范围的补偿,但是如果听觉场景比较复杂,患者听到的语音中不仅包含了放大后的语音也包含了很多噪声,时间一长势必会对患者的听觉系统造成二次损害,因此高端的数字助听器设备中,语音降噪也成为了他们不容忽视的一个重要方面。
语音增强作为数字信号处理的一个分支,已经有了50多年的历史。虽然语音增强技术看似只是一个简单的纯净语音恢复过程,但是其中涉及的知识和算法是广泛而又多样的。在学术界,该领域的研究可以说是“百花齐放,百家争鸣”,既有传统的数字信号处理的方法,又有近几年刚刚兴起的深度学习的方法。经过几十年的发展,学术界也涌现出来了不少大牛,像Rainer Martin、Yariv Ephraim、Israel Cohen、Phillip Loizou以及Sharon Gannot等,这几位前辈在数字信号处理领域的语音增强方法中,起到的十分重要的推动作用。然而,在语音增强的另一个新兴领域:深度学习语音增强,虽然是后起之秀,但是伴随着硬件技术的升级,该技术在工程界得以落地,也使其在语音增强领域站住了脚跟。当然,该技术的发展与“深度学习之父”Geoffrey Hinton在神经网络结构上取得的重大成果是分不开的。在当今学术界,如果说在该领域,真正占有一席之地的,我个人认为,当属俄亥俄州立大学的汪德亮教授,他的实验室和学生,对深度学习语音增强这一方法的发展起到了十分重要的推动作用。
1.2 语音增强方法分类
对于语音增强方法的分类,可以按照其运用方法的不同进行分类,于是便可以分成如下两大类:数字信号处理的语音增强方法和基于机器学习的语音增强方法。 其中,数字信号处理的语音增强方法是主流方法,历史悠久,且拥有很深的技术奠基,是目前工程界进行语音降噪的主要思路。而在传统的数字信号处理的方法中,按照其通道数目的不同,又可以进一步划分为:单通道语音增强方法和麦克风阵列的语音增强方法。
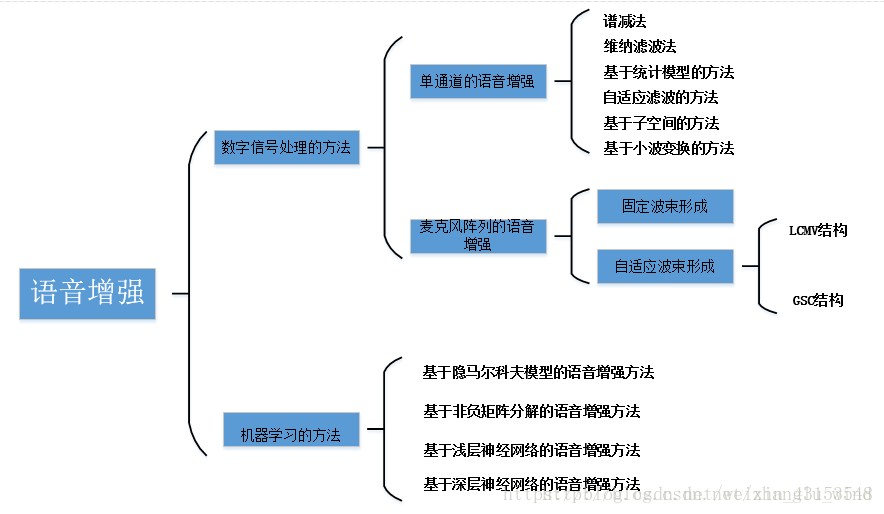
在传统的单通道语音增强方法中,对数字信号处理的知识运用较多,时域和频域的方法都有,以频域处理为主,其中基于短时谱估计的语音增强方法是目前应用最为广泛的语音增强方法,具体的算法可以分为以下三大类:谱减法、维纳滤波法和基于统计模型的方法。除了上述提到的短时谱方法,在单通道的语音增强领域还有一种自适应滤波的方法,但是其需要事先知道噪声或者纯净语音,然后利用随机梯度下降的方式进行最优解的逼近,而在大多数情况下,噪声或者纯净语音等先验知识是无法获得的,因此大大限制了自适应滤波方法的应用,但是该方法在手机通话中的降噪应用比较广泛,通常手机中都会专门用一个降噪麦克风来收取环境中的噪音,以此作为参考输入来实现降噪。此外,在单通道的方法之中,还有一种基于子空间的方法也备受关注,但由于其运算度相对较高,所以在工程中的应用并不算广泛。近些年以来,小波变换的方法发展迅猛,它克服了短时傅里叶变换固定分辨率的缺点,可以获得信号在不同分别率上的信息,在近几年里得到了广泛的应用。
而在麦克风阵列的语音增强方法中,由于利用了更多的麦克风,考虑了信号的空间信息,因此在抑制特定方向的干扰、进行语音分离等方面,比单通道的语音增强更有优势。麦克风阵列的语音增强方法目前在智能音箱、机器人等领域应用较多,利用其多麦克风的优势,这类产品可以实现在远场和更复杂的声学环境中进行语音增强。主流的麦克风阵列方法有:固定波束形成的方法和自适应波束形成的方法。固定波束形成的应用环境十分受限,但运算复杂度较低,所以一般应用于声学场景固定不变的环境中;而自适应波束形成的方法则表现出更好的鲁棒性,当然这也是以牺牲运算复杂度为代价,目前自适应波束形成方法主要有两大阵营:LCMV结构和GSC结构,如今的麦克风阵列语音增强算法基本上都是基于这两种结构进行地改进和优化。
基于机器学习的语音增强方法算是奇巧之技,不同于传统的数字信号处理方法,它借鉴机器学习的思路,通过有监督的训练实现语音增强。该领域的算法算是刚刚起步,满打满算也没有二十年的历史,但是“存在即合理”,它之所以能够在语音增强领域占有一席之地,也有其优势所在,例如,在数字信号处理领域的一些比较棘手的问题,比如瞬时噪声的消除,这类方法另辟蹊径,可以较容易地将其解决,因此,这类算法也许会成为未来人工智能时代的语音增强主流方向。如今,运用机器学习的语音增强方法不多,大致梳理一下,可以分成以下几类:基于隐马尔科夫模型的语音增强、基于非负矩阵分解的语音增强、基于浅层神经网络的语音增强和基于深层神经网络的语音增强。其中,基于深度神经网络的语音增强方法,也就是深度学习语音增强,利用深度神经网络结构强大的非线性映射能力,通过大量数据的训练,训练出一个非线性模型进行语音增强,取得了十分不错的效果。此外,该类方法在工程界也刚刚实现落地,华为今年发布的mate10手机,已成功地将该技术应用到了复杂声学环境中的语音通话中,也算是开辟了深度学习应用于语音增强的先河,未来该何去何从,仍需要我们这一代人的不懈努力。
1.3 语音增强入门
语音增强的方向较多,各方向领域的大牛不同,涉及的知识也不太一样,因此分别给出了不同的语音增强研究方向的大牛和书籍。
-
传统单通道的语音增强方法:
Yariv Ephraim 主页:http://ece.gmu.edu/~yephraim/
Rainer Martin 主页:http://www.ruhr-uni-bochum.de/ika/mitarbeiter/martin_publik.htm#2017
Isreal Cohen 主页:http://webee.technion.ac.il/people/IsraelCohen/
Philip Loizou 主页:http://ecs.utdallas.edu/loizou/
推荐书籍:《语音增强理论与实践》(Loizou) -
麦克风阵列的语音增强方法:
Sharon Gannot 主页:http://www.eng.biu.ac.il/gannot/
Jacob Benesty 主页:http://externe.emt.inrs.ca/users/benesty/
推荐书籍:《Wideband Beamforming Concepts and Techniques》(Wei Liu) -
基于深度学习的语音增强方法:
汪德亮主页:http://web.cse.ohio-state.edu/~wang.77/index.html
推荐学习:吴恩达深度学习在线课程:http://mooc.study.163.com/smartSpec/detail/1001319001.htm
博士论文:《基于深层神经网络的语音增强方法研究》(徐勇 2015)