问题:当网络深度到一定深度后,网络层数越深,纯神经网络的效果呢,如图所示?
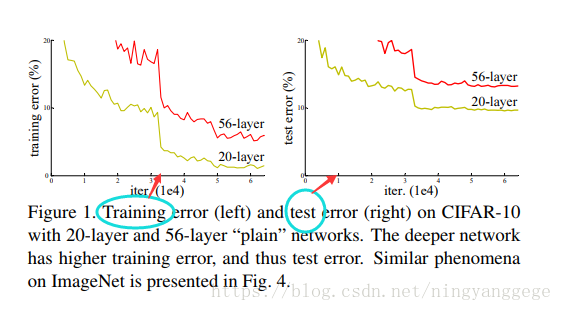
从理论上来讲,神经网络越深,其学习能力越强;但实际上却面临着优化难题;不是梯度消失也不是梯度爆炸导致的,因为使用了BN;论文作者推断是因为深度网络面临着随着层数增加,而出现指数级下降的收敛速度,换句话说,需要非常多的训练次数;这个优化难题留在未来解决;
作者设计了两个网络,一个是较浅的神经网络结构,另一个较深的神经网络结构在前者后面链接数据层网络,但其新的层数只有一个功能就是完美复制,不作任用修改,专业术语为恒等映射,其结果为输出结果完全等同于较浅的神经网络;这个设计就表明更深的深度神经网络至少能训练出不亚于较浅的神经网络结构模型;但事实证明无法找到比这种恒等映射更好的结果了;
针对这个超深度网络,作者独创了一种名为residual learning,如图所示:
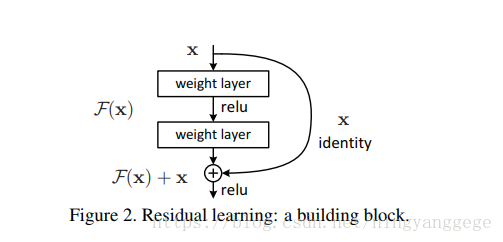
可以把正常的h(x)分成两部分一是f(x)与x,可以看作是先验的一部分,也可以一种独特的结构,对h(x)的收敛方向作了一定的约束或者指向;可以加快其收敛速度;该结构的网络非常容易优化,网络深度快速增加时,能较快的优化或者收敛;效果如图所示:
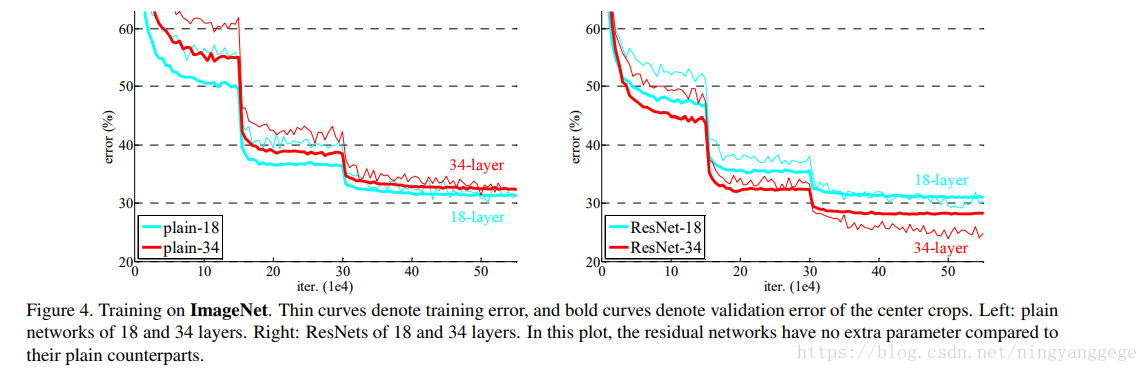
作者将层数增加到1000层,训练误差降到历史新低,但测试误差一样;说明此时出现了过拟合;此时可以考虑使用dropout,maxout等正则化;
对于imagenet的训练,于卷积后激活之前使用了BN,使用了batchsize=256的SGD,学习率从0.1开始,每进入稳定期后,学习率除以10,迭代次数为60万次,使用权重decay值为0.0001,动量系数为0.9,不使用dropout;
对于CIFAR-10的训练,使用权重decay值为0.0001,动量系数为0.9,不使用dropout,mini-batchsize=128,两块GPU,学习率以0.1开始,到迭代到32000次和48000次时学习率除以10;当层数增加到110层时,初始学习率为0.1就太大而不能收敛,所以开始就以0.01进行训练直到训练误差下降到80%(大概迭代480次),然后将学习率恢复到0.1进行训练