论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1512.03385
论文代码:https://link.zhihu.com/?target=https%3A//github.com/KaimingHe/deep-residual-networks
1、问题
Vanishing or exploding gradients has been largely addressed by normalized initialization and intermediate normalization layers.
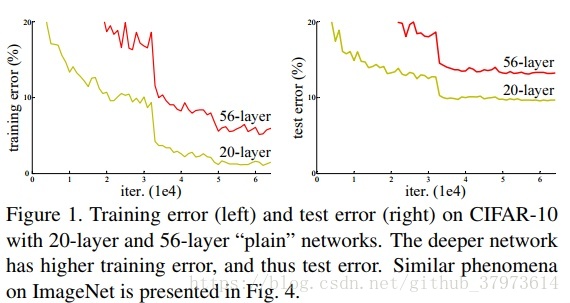
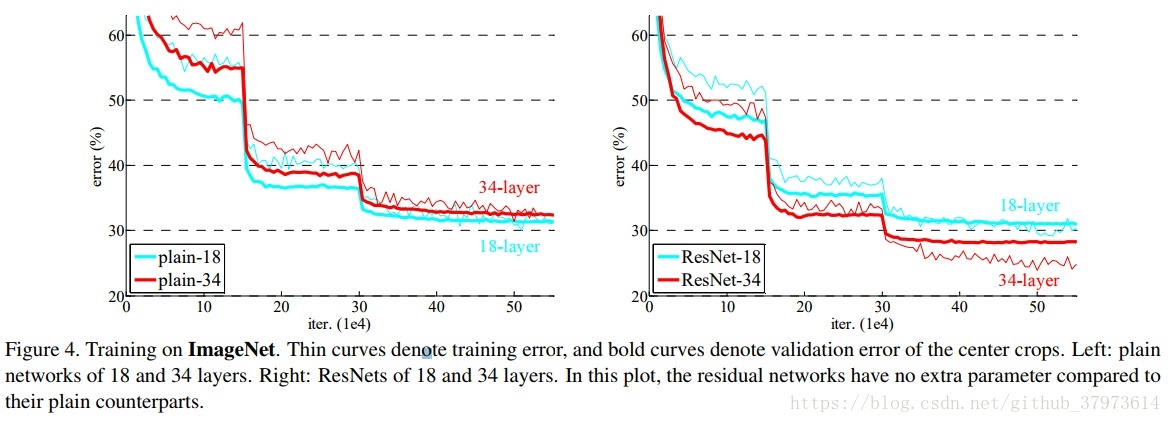
problem:在一定深度下,深层网络的训练误差大于浅层网络的训练误差。
2、文中的残差
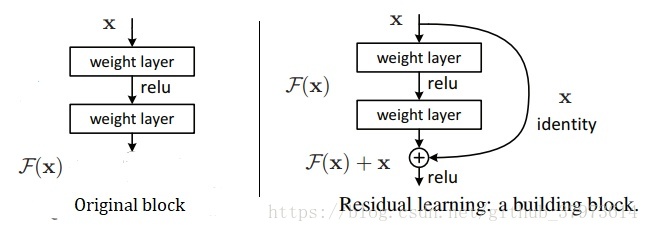
恒等映射问题:宿儒一个x经过某个函数(设为G(x))作用输出还是x本身,即G(x)=x。
若上图中的original block输入为x,输出也应为x,那么这个block中的w, b参数将无法很好的去学习这样的恒等映射,但是若是加入了残差,那么可以直接令block中参数为0即可。
Why ResNet perform better?
可以更加容易的拟合恒等映射,至少会让深度网络与浅层网络有相同的拟合能力,不会出现之前的网络退化的问题。
Shortcut的方式:(主要是对维度的调整)
(1)如果x的维度增加,就使用0来填充增加出来的维度。
(2)(文中采用)如果x维度增加,使用线性变换来增加多出来的维度,在程序中表现为使用一个1x1卷积核进行调整维度。
(3)对所有的shortcut都是用线性变换,也就是1x1的卷积。
一些结构的对比:
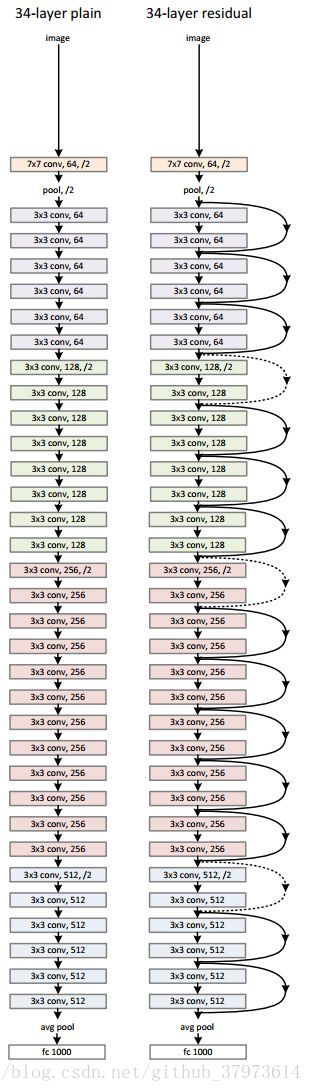
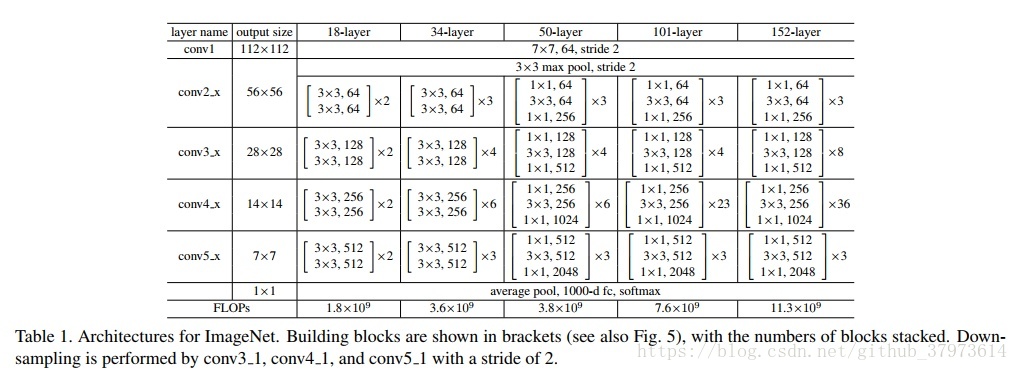
作者搭建的其他深度的resnet网络结构:
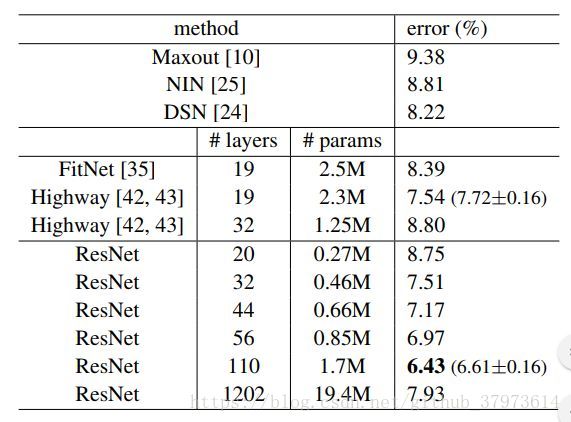
实验结果的对比:
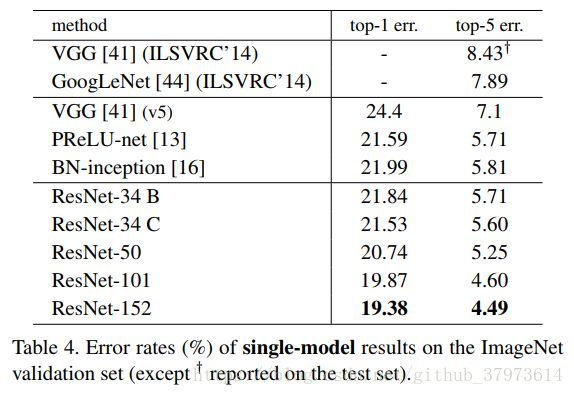
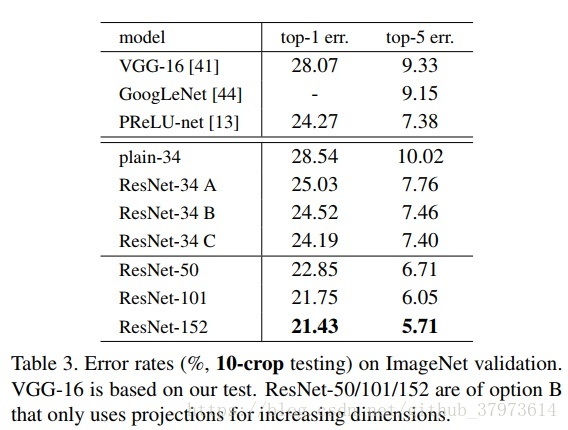
不同深度的ResNet模型对比实验: