深度残差网络在2015年的ImageNet 图像分类/检测/定位和COCO detection/segmentation的ILSVRC & COCO竞赛中取得了冠军。而这篇《Deep Residual Learning for Image Recongnition》也被评为CVPR2016的BEST PAPER.
论文链接 https://arxiv.org/pdf/1512.03385.pdf
源代码 ImageNet models in Caffe: https://github.com/KaimingHe/deep-residual-networks
深度网络的层数按有权重W的conv层&全连接层来算,不包括池化和Relu层。在ResNet之前备受瞩目的网络如AlexNet有8层,VGG有16层和19层,而ResNet与之相比则是非常深度的网络,有152层。它的提出解决了普通的深度网络(plain network)因为网络层数的加深导致的性能退化问题(degradation problem),即 with the network depth increasing, accuracy gets saturated and then degrades rapidly,更深的网络有更高的 training & test error. 其中ResNet采用跳跃连接的 deep residual learning framework来解决此问题,同时也使训练难度下降很多。
Going Deeper的solution:
采用恒等映射, the added layers are identity mapping, and the other layers are copied from the learned shallower model.
它表明了 if the added layers can be constructed as identity mappings,a deeper model should produce no higher training error than its shallower counterpart。
Identity Mapping by Shortcuts、 残差学习的building block,如下图所示,
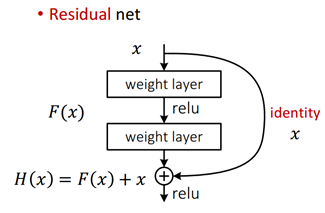
shortcut连接将间隔一层或多层的两层网络相连,在此处相当于简单地进行了 identity mapping。
上图的building block可以定义为:
![]()
其中x 和y分别是网络层的输入/输出向量,函数F是要学习的residual mapping。上图有两个layers,对于函数F+x 可通过 a shortcut connection and element-wise addition来实现,所以要求它们的维度相同。函数F至少要有两层,若FF只有一层则等式(1)相当于一个线性层,会失去linear projection 的优势。The element-wise addition is performed on two feature maps, channel by channel.
ResNet 改变了优化目标,把原来要优化的H(x)=F(x)+x,改为优化F(x)=H(x)-x,其中x为网络结构的输入。通过残差学习的这种改变,那么if identity mappings are optimal, the solvers may simply drive the weights of the multiple nonlinear layers toward zero to approach identity mappings。而且恒等映射既没有引入更多参数,也没有增加计算复杂度。
if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers. 如果一个恒等映射是最优的,则将残差项趋于0比一堆非线性层更易拟合一个恒等映射。
对于这种跳跃结构,在输入与输出的维度相同时,可直接相加;若维度不同时,则将输入的维度通过以下两种变换来增加到和输出相同的维度:
【1】zero-padding. This option introduces no extra parameter;
[2] 1x1卷积。
For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2.
网络结构
fewer filters and lower complexity than VGGnets
【1】 perform downsampling directly by convolutional layers that have a stride of 2.
【2】The network ends with a global average pooling layer and a 1000-way fully-connected layer with softmax.
[3] The identity shortcuts can be directly used when the input and output are of the same dimensions.
[4] adoptbatch normalization (BN) right after each convolution and before activation.
plain baseline的两个简单的design rules:
[1]对于输出的特征图size相同的layer,有相同数量的3 x 3 filters.
[2]如果特征图size减半,则将3 x 3 filters的数量加倍,以保证每层的时间复杂度相同。
Identity vs. Projection Shortcuts
两种不同的跳跃结构,使用不同的卷积核,similar complexity。当网络很深时用右边的较好,因为左边的参数要比右边多很多。

左图为all 3x3 conv, 其中的 the zero-padded dimensions indeed have no residual learning.
右图是ResNet 的 一个 “bottleneck” building block 。Identity shortcuts are particularly important for not increasing the complexity of the bottleneck architectures。
网络训练
Deeper ResNet 比19层的VGG有更低的复杂度和更低的 training & test error. VGG有3个全连接层,有很多权重参数,而ResNet有1个全连接层,很多个average pooling层,所以它的训练慢但test时比VGG更快。 整个网络的训练是 end-to-end by SGD with backpropagation,use SGD with a mini-batch size of 256. The learning rate starts from 0.1 and is divided by 1 0when the error plateaus, and the models are trained for up to 60×10^4 iterations. We use a weight decay of 0.0001 and a momentum of 0.9. We do not use dropout.
普通网络的训练时, BN ensures forward propagated signals to have non-zero variances, neither forward nor backward signals vanish.
testing时,采用the standard 10-crop testing( the fullyconvolutional form), average the scores at multiple scales。
实验结果
【1】 extremely deep residual nets are easy to optimize, but the counterpart “plain” nets (that simply stack layers) exhibit higher training error when the depth increases; 易于优化。
【2】 Our deep residual nets can easily enjoy accuracy gains from greatly increased depth, producing results substantially better than previous networks. The benefits of depth are witnessed for all evaluation metrics。 准确率会随着网络层数的增加而提升,没有出现性能退化的问题。
【3】the learned residual functions in general have small responses, suggesting that identity mappings provide reasonable preconditioning。
【4】the 34-layer ResNet exhibits considerably lower training error and is generalizable to the validation data.说明性能退化问题被很好地解决了。
参考文献&拓展阅读
【1】 R. Girshick. Fast R-CNN. In ICCV, 2015. #了解ROI POOLING
【2】Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S.Guadarrama,andT.Darrell. Caffe: Convolutionalarchitecturefor fast feature embedding. arXiv:1408.5093, 2014. #代码实现
【3】 S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015. # 去论文精读一下
【4】 K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015. #VGG
[5] Kaiming He, Facebook AI Research. Deep Residual Networks ---Deep Learning Gets Way Deeper. ICML 2016 tutorial.
注:参考文献【5】是论文作者写的讲义,值得去细看一下。