Deep Residual Learning for Image Recognition 这是一篇2015年何凯明在微软团队提出的一篇大作,截止目前其论文引用量达12000多次。
摘要
网络比较深的模型比较难以训练。作者提出了一个残差学习的框架来减轻模型的训练难度,并使得其模型深度远远大于之前的工作。我们明确地将层作为输入学习残差函数,而不是学习未知的函数。我们提供了非常全面的实验数据来证明,残差网络更容易被优化,并且可以在深度增加的情况下让精度也增加。在ImageNet的数据集上我们评测了一个深度152层(是VGG的8倍)的残差网络,但依旧拥有比VGG更低的复杂度。残差网络整体达成了3.57%的错误率,这个结果获得了ILSVRC2015的分类任务第一名,我们还用CIFAR-10数据集分析了100层和1000层的网络。
一、介绍
最近的研究表明网络的深度是非常重要的,不仅是ImageNet挑战赛以及其他非常重要的视觉任务都收益于比较深的网络模型。由于网络模型深度的的驱动下,存在一个问题,是不是很多层的叠加很深的网络就能够学到到更好的网络?梯度爆炸问题很好否定的上面的问题。这个问题虽然通过初试标准化,中间层标准化等措施很大程度上解决了梯度爆炸的问题,使得网络的深度可以达到几十层的网络深度,并可以使用SGD进行梯度反向传播。
当很深的网络在开始训练时在收敛,但是随着网络的深度增加却出现了一个模型退化的问题,就是模型的准确率却达到饱和甚至出现意想不到的退化现象。奇怪的是,这种模型退化现象不是由过拟合导致的,而是由在合适的浅层网络中加入更多的层导致的更高的训练误差,如下图所示:

模型的退化(训练误差)表明不是所有的系统都是相似的很容易优化。让我们考虑一个浅层架构和它的对应的增加了更多层的深层架构。存在一个解决方案来构建更深层次的模型:添加的层是自身映射,其他层从是训练好的浅模型中复制而来。这种特殊的构建方式让我们推测,深的模型应该不会比浅的模型产生更高的训练误差。但实验结果表明,我们手头上有的方案都找不到解,找不到更好或者同样好的解(或者是无法在可接受的时间里做完)。
在本文中,我们通过引入一个深度残差学习框架,解决了这个退化问题。我们不期望每一层能直接吻合一个映射,我们明确的让这些层去吻合残差映射。形式上看,就是用H(X)来表示最优解映射,但我们让堆叠的非线性层去拟合另一个映射F(X):=H(X) - X, 此时原最优解映射H(X)就可以改写成F(X)+X,我们假设残差映射跟原映射相比更容易被优化。极端情况下,如果一个映射是可优化的,那也会很容易将残差推至0,把残差推至0和把此映射逼近另一个非线性层相比要容易的多。
F(X)+X的公式可以通过在前馈网络中做一个“快捷连接”来实现(如下图2) ,快捷连接跳过一个或多个层。在我们的用例中,快捷连接简单的执行自身映射,它们的输出被添加到叠加层的输出中。自身快捷连接既不会添加额外的参数也不会增加计算复杂度。整个网络依然可以用SGD+反向传播来做端到端的训练。
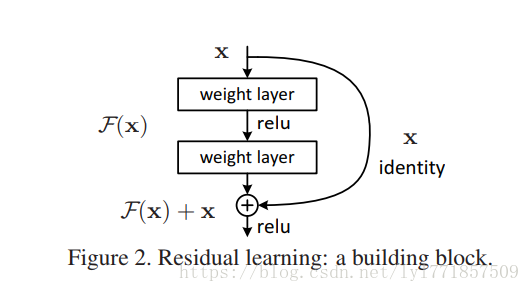
在统计学中,残差的定义为实际观测值与估计值(拟合值)的差值,这里则是直接的映射H(x)与快捷连接x的差值。
这样设计的主要思想:去构造映射H(x),与构造残差映射F(x)是等价的,但是残差映射F(x)比H(x)更容易优化。
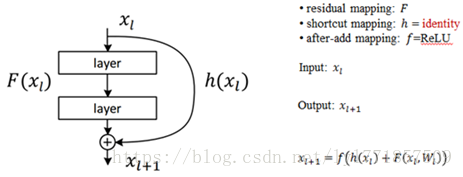
如果f 激活函数也是恒等映射,也就是 =
=
, 则
看下残差网络的前向传播过程:

前向过程,最后的结果表示直接的前向过程,连加的运算(考虑的残差元为一个单元,残差元的内部还是两层的连乘),即从第l层可以直接到第L层,而传统的网络则是连乘运算,计算量明显不同。(从连乘到连加)
三、残差网络与普通网络的区别

对于残差元来说,前向过程是线性的,而且后面的输入等于输入加上每一次的残差元的结果,而普通的网络,则为每一层卷积的连乘运算;
残差网络的第一大特点,反向更新解决梯度消失的问题:

残差网络在反向传播的时候,则只求链式法则前面的部分,即从第L层的梯度可以基本上保持稳定的传递到第l层反向过程。
四、残差网路和普通的网络反向传播的求导对比

之前的正向和反向可以保证计算相对简单,主要是存在两个恒等映射。其中激活函数不为恒等映射就为普通的网络结构。快捷连接部位为恒等映射时,ReLu的使用,使得学习周期大大缩短。综合速率和效率,DL中大部分激活函数应该选择ReLu。
五、考虑如果残差网络的快捷连接不为恒等映射的情况
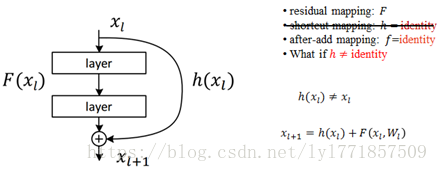

如此时英文描述的一样,h(xl)时,只要系数不为1,在对误差求导时总是会出现梯度消失或者梯度爆炸的问题。
参考:https://blog.csdn.net/qq_29184757/article/details/77983824