论文链接:https://arxiv.org/abs/1512.03385
Resnet是2015年ImageNet比赛的冠军,不仅在分类上标线优秀,在目标检测中同样取得好成绩,Resnet将网络层数进一步加深,甚至达到1000+层。
1、Degradation
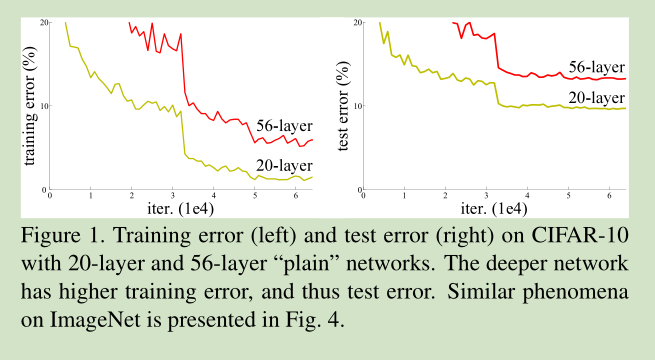
根据经验,如果没有发生梯度消失、弥散现象,网络层数越深效果会越好,但是作者实验发现,虽然网络层数增加,但是训练会出现饱和现象,精度反而没有浅层网络精度高了,作者将这种现象称为Degradation问题,如下图所示。
如果仅仅在浅层网络后面增加几层,在不出现过拟合的情况下,效果应该会比浅层网络效果好,但是实验结果却不一定好,这也表明,不是所有的网络都容易优化到最好。
为解决这个问题:本文引入一个深度残差学习框架。此框架不需要每一层能直接吻合一个映射,而是让这些层去吻合残差映射。比如:用H(X)来表示最优解映射,但本文去拟合另一个映射F(X) = H(X) - X , 此时原最优解映射H(X)就可以改写成F(X)+X。这里残差映射跟原映射相比更容易被优化。极端情况下,如果一个映射是可优化的,那也会很容易将残差推至0,把残差推至0和把此映射逼近另一个非线性层相比要容易的多。
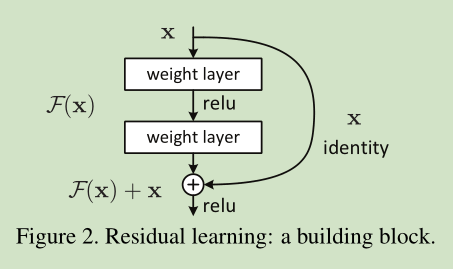
- 残差网络通过如下结构实现。
2、Deep Residual Learning
Identity Mapping by Shortcuts
如上图是一个building block,公式定义如下:
在上图例子中,由于block中包含2层,所以 ,σ表示RELU,这里省略了偏置项。
当F()与x的维度不同时,可以通过线性映射进行调整,公式如下:
Network Architectures
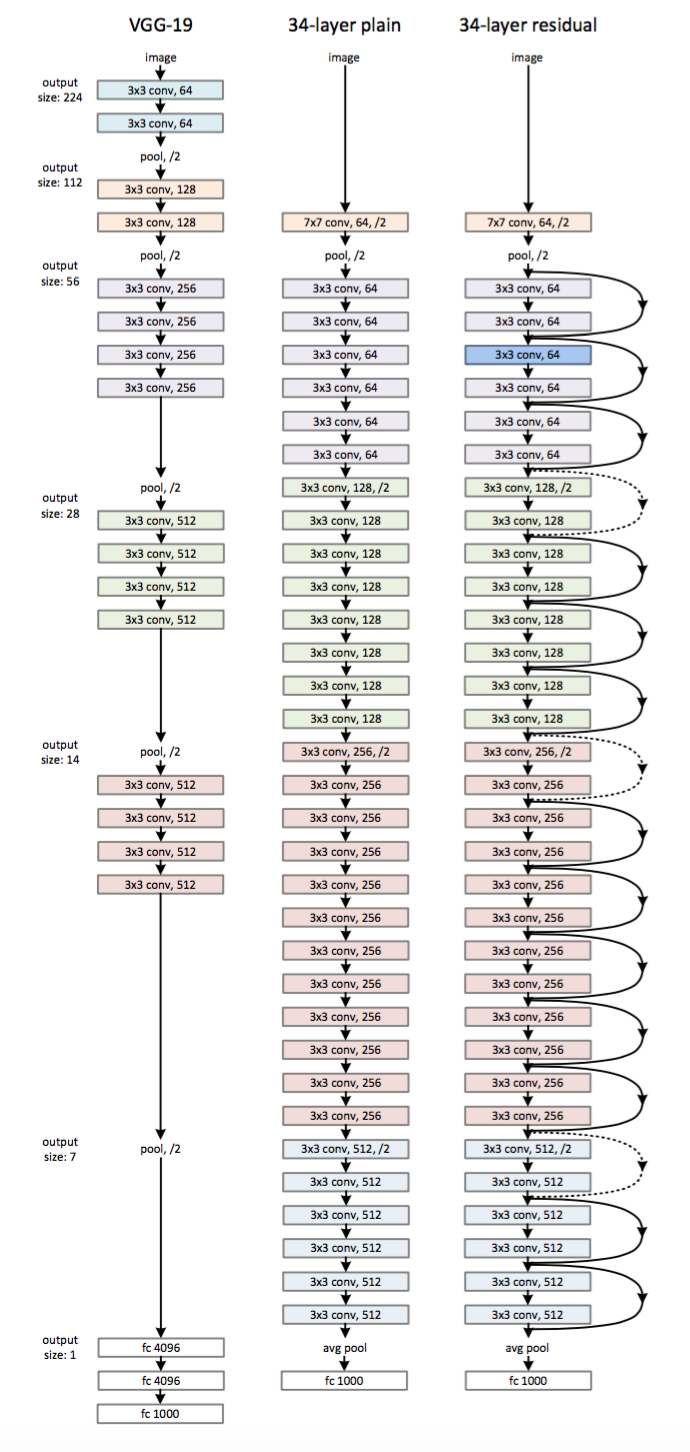
Plain Network主要是受 VGG 网络启发,主要采用3*3滤波器,但是本网络与VGG相比,滤波器要少,复杂度要小,网络特征如下:
- 对于相同输出特征图尺寸,卷积层有相同个数的滤波器。
- 如果特征图尺寸缩小一半,滤波器个数加倍以保持每个层的计算复杂度。通过步长为2的卷积来进行降采样。一共34个权重层。
ResNet在Plain Network的基础上,我们插入了快捷连接,将网络转化为其对应的残差版本。
对于shortcut的方式,作者提出了三个选项:
- 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
- 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
- 对于所有的block均使用线性投影。
Implementation
- 图片resize:短边长random.randint(256,480),裁剪到224*224,随机采样,含水平翻转,减均值。
- conv和activation间加batch normalization
- minibatch-size:256
- learning-rate: 初始0.1, error平了lr就除以10
- weight decay:0.0001
- momentum:0.9
- 没用dropout
实验
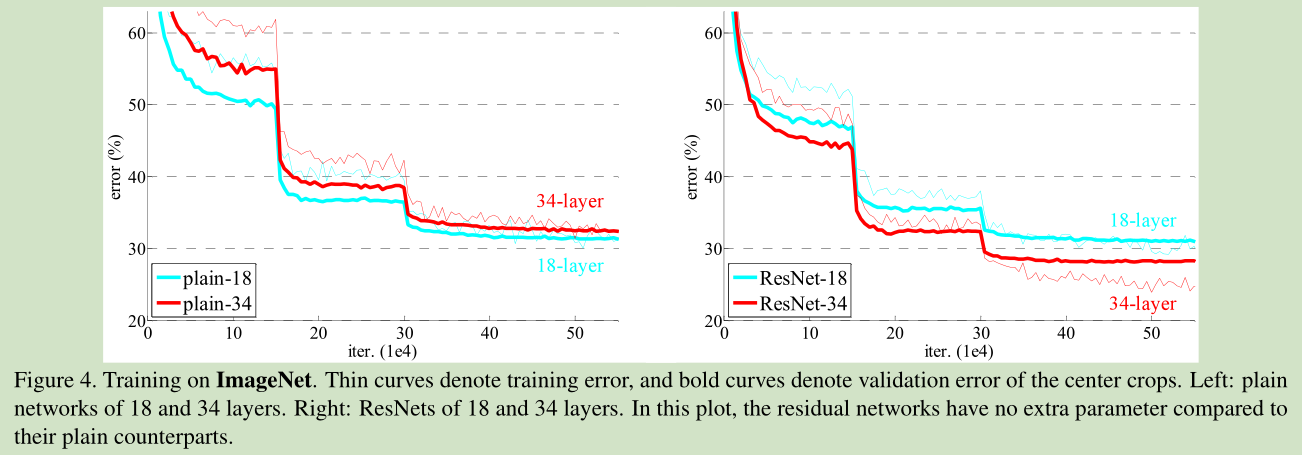
作者通过实验证明:
1、34层与18层网络比较:
- 训练过程中, 34层plain net 比18层plain net的error大 。
- 34层residual net 比18层residual net的error小,更比34层plain net小了3.5%
- 18层residual net比18层plain net收敛快
2、Residual function的设置比较:
A、在H(x)与x维度不同时, 用0充填补足
B、在H(x)与x维度不同时, 带WT
C、任何shortcut都带WT
loss效果: A>B>C
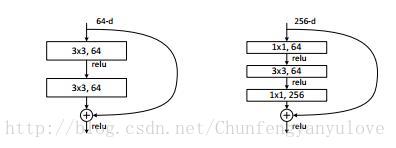
3、将两层网络变为三层网络:
三层分别是1×1、3×3,和1×1的卷积层,其中1×1层负责先减少后增加(恢复)尺寸的,使3×3层具有较小的输入/输出尺寸瓶颈,如下图所示:
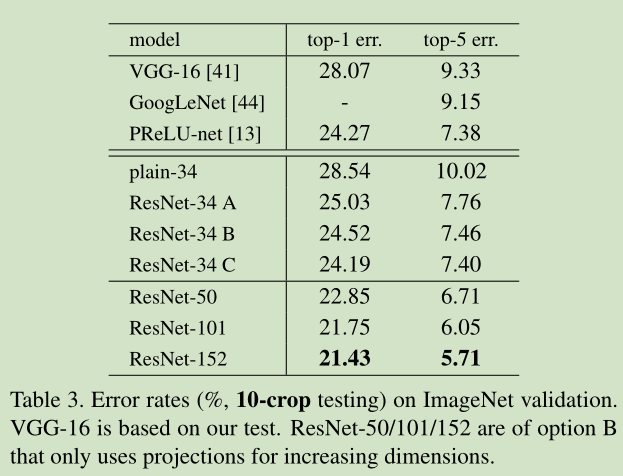
识别精度如下图所示:
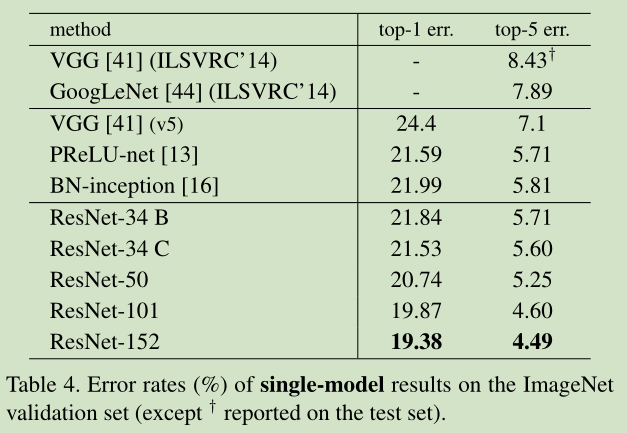
进一步的,作者在CIFAR-10数据集进行分析。同时,作者又搭建了更加变态的1202层的网络,对于这么深的网络,优化依然并不困难,但是出现了过拟合的问题,这是很正常的,作者也说了以后会对这个1202层的模型进行进一步的改进。
分析结果如下图:

附录
resnet caffe 实现:https://github.com/KaimingHe/deep-residual-networks