IDE: Pycharm + Python 3
目标:根据已有数据集中的年龄、性别等属性和存活与否,建立回归模型,并利用测试集提供的数据,进行存活预测。本次实验采用Logistic Regression
需要引用的包
#encoding=utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn.preprocessing as preprocessing
import sklearn.linear_model as linear_model
from sklearn.ensemble import RandomForestRegressor数据集的路径以及格式如下图所示
程序结构如下图所示
首先加载数据集,了解数据集的属性和数据类型
#数据集加载
def load_data(data_src):
data = pd.read_csv(data_src)
return data#加载数据集
datatrain_src = 'D:\Dataset\Titanic\\Titanic_train.csv'
data_train = load_data(datatrain_src)
data_train .info()数据集属性如下所示:
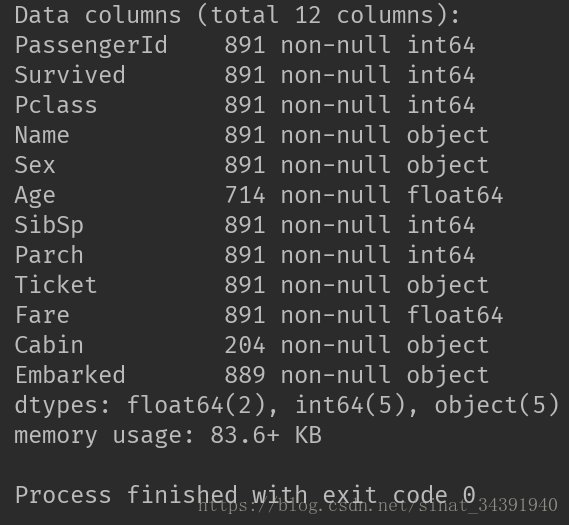
可以看出数据集一共有十二个属性,包括:
⚪ 两个浮点型 Age(年龄)、Fare(费用)
⚪ 五个整型数据 PassengerId(乘客编号)、Survived(是否存活)、Pclass(乘客类型)、SibSp(亲戚数量)、Parch(家属数量)
⚪ 五个Object型数据 Name(姓名)、Sex(性别)、Ticket(船票)、Cabin(舱位)、Embarked(港口)
部分属性有缺失值,稍后会做处理,先来查看各个属性的分布:
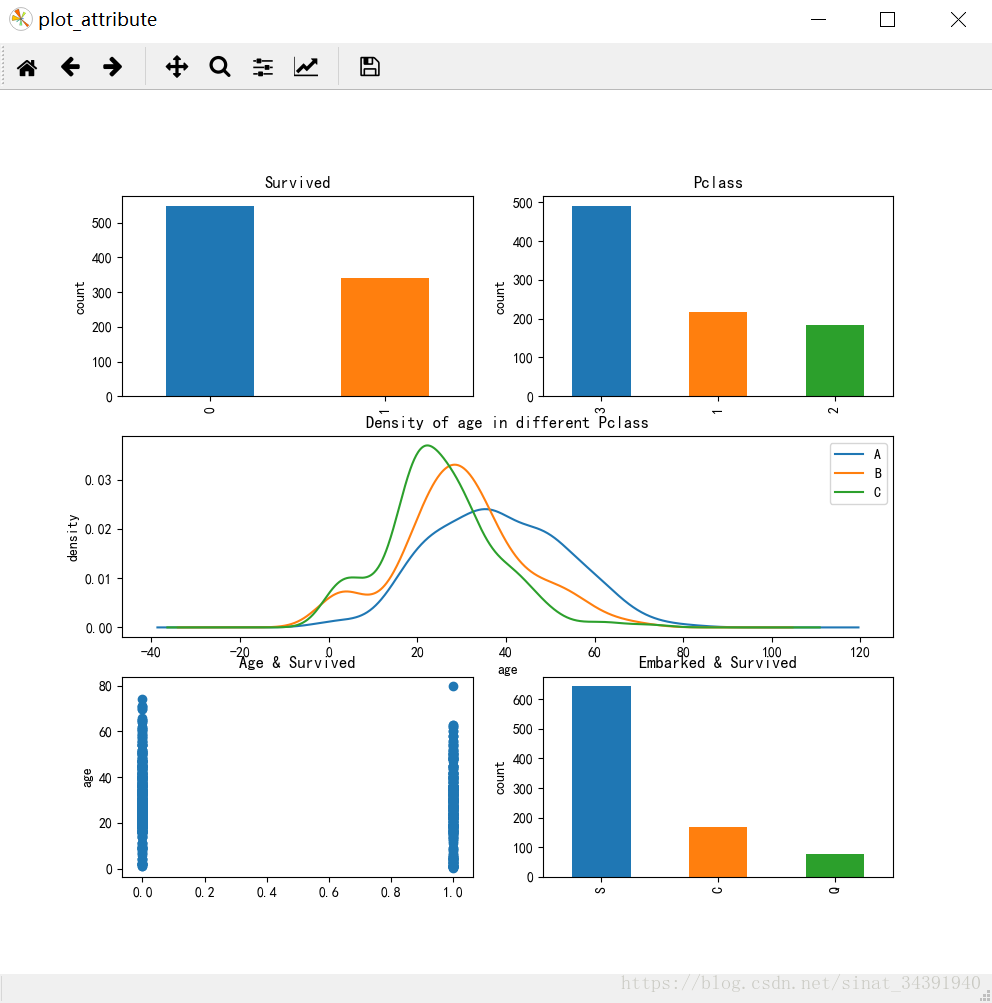
可以看出Survived人数、各个Pclass乘客人数的柱状图,各个Pclass中乘客年龄的密度分布,以及Embarked的柱状图。
代码如下所示:
#属性展示
def plot_attribute(data):
fig = plt.figure('plot_attribute')
fig.set(alpha=0.2)
# 中文字体设置,PY3开始默认是unicode编码,中文不能正常显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#存活数量柱状图
plt.subplot(3, 2, 1)
data.Survived.value_counts().plot(kind='bar')
plt.title('Survived')
plt.ylabel('count')
#乘客类型数量柱状图
plt.subplot(3, 2, 2)
data.Pclass.value_counts().plot(kind="bar")
plt.ylabel('count')
plt.title('Pclass')
#不同乘客类型的年龄分布密度图
plt.subplot(3, 2, (3, 4))
data.Age[data.Pclass == 1].plot(kind='kde')
data.Age[data.Pclass == 2].plot(kind='kde')
data.Age[data.Pclass == 3].plot(kind='kde')
plt.xlabel('age')
plt.ylabel('density')
plt.title('Density of age in different Pclass')
plt.legend(('A', 'B', 'C'), loc='best')
#年龄分布散点图
plt.subplot(3, 2, 5)
plt.scatter(data.Survived, data.Age)
plt.ylabel('age')
# plt.grid(b=True, which='major', axis='y')
plt.title('Age & Survived')
#港口数量柱状图
plt.subplot(3, 2, 6)
data.Embarked.value_counts().plot(kind='bar')
plt.title('Embarked & Survived')
plt.ylabel('count')
plt.show()plot_attribute(data_train)接下来查看属性和预测目标的关联分析,即不同的属性和存活与否的关系
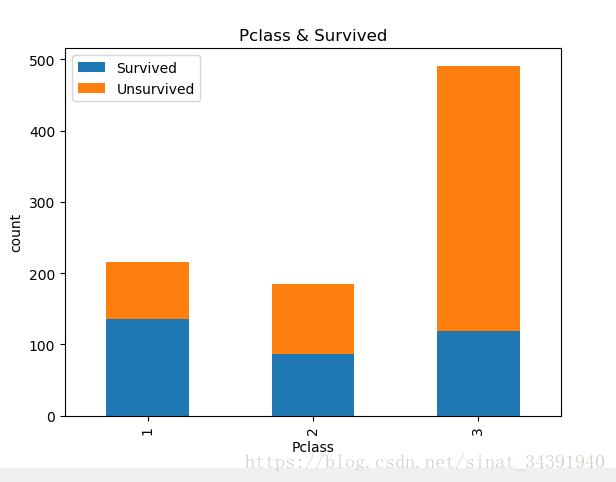
⚪可以看出1类别的乘客存活几率最大,3类别乘客存活几率最小
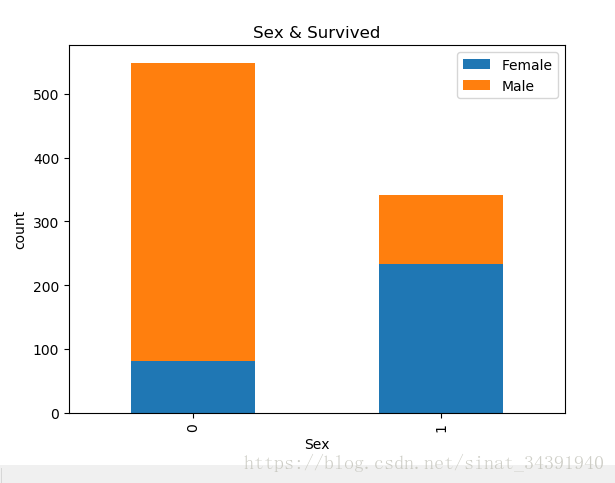
⚪可以看出女性存活的几率显著高于男性
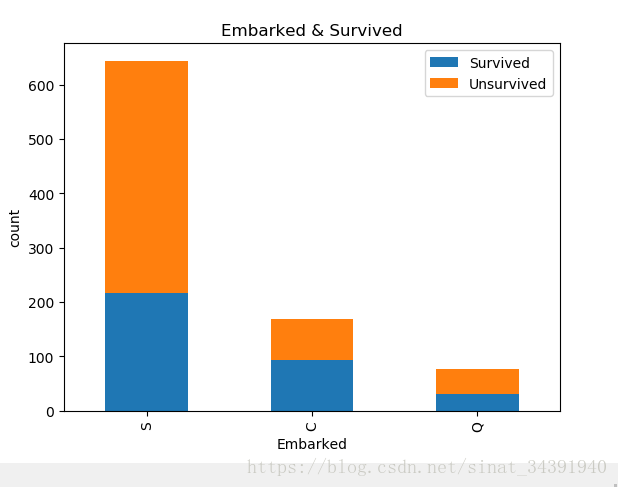
⚪看得出S港口的人最多,Q港口的人最少
⚪有舱位的人存活概率较大

代码如下:
#属性统计展示
def plot_attribute_static(data):
fig = plt.figure('plot_attribute_static')
fig.set(alpha=0.2)
#乘客等级和存活关系
Survived_0 = data.Pclass[data.Survived == 0].value_counts()
Survived_1 = data.Pclass[data.Survived == 1].value_counts()
df = pd.DataFrame({'Survived': Survived_1, 'Unsurvived': Survived_0})
df.plot(kind='bar', stacked=True)
plt.title('Pclass & Survived')
plt.xlabel('Pclass')
plt.ylabel('count')
#性别和存活关系
Survived_m = data.Survived[data.Sex == 'male'].value_counts()
Survived_f = data.Survived[data.Sex == 'female'].value_counts()
df = pd.DataFrame({'Male': Survived_m, 'Female': Survived_f})
df.plot(kind='bar', stacked=True)
plt.title('Sex & Survived')
plt.xlabel('Sex')
plt.ylabel('count')
#港口和存活关系
Survived_0 = data.Embarked[data.Survived == 0].value_counts()
Survived_1 = data.Embarked[data.Survived == 1].value_counts()
df = pd.DataFrame({'Survived': Survived_1, 'Unsurvived': Survived_0})
df.plot(kind='bar', stacked=True)
plt.title('Embarked & Survived')
plt.xlabel('Embarked')
plt.ylabel('count')
#舱位和存活关系
Survived_cabin = data.Survived[pd.notnull(data.Cabin)].value_counts()
Survived_nocabin = data.Survived[pd.isnull(data.Cabin)].value_counts()
df = pd.DataFrame({'Exist': Survived_cabin, u'Unexist': Survived_nocabin}).transpose()
df.plot(kind='bar', stacked=True)
plt.title('Cabin & Survived')
plt.xlabel('Cabin')
plt.ylabel('count')
plt.show()看完以上的关联属性之后,初步确定了建立模型所需要的属性:Pclass、Age、Sex、Fare、SibSp、Parch、Cabin、Embarked
Logistic Regression模型所需要的属性类型需要是整型数据,这里需要对以上属性做数据处理:
⚪缺失值处理
a.直接丢弃。但是数据来之不易,有它的存在价值,不能轻易否认。
b.填充。简单的有用中位数、平均数、众数等直接填充。常用的有回归拟合,用已知属性值拟合出缺失值,但是不合理的填充会产生噪声。
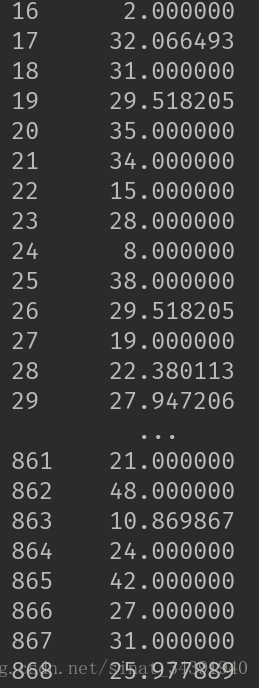
本文采用Random Forest来进行拟合。Random Forest会在数据集中进行采样建立多棵子树,再进行平均取值,能够更加真实的拟合出缺失值,实现结果如下图所示。
填充之前
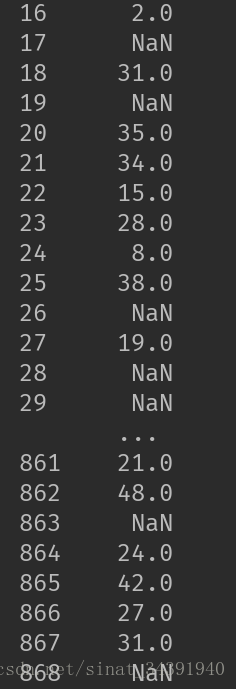
填充之后
代码如下
#缺失值处理
def set_missing_ages(df):
age_df = df[['Age', 'Fare', 'Parch', 'SibSp', 'Pclass']]
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix() #type为numpy.ndarray
unknown_age = age_df[age_df.Age.isnull()].as_matrix() #type为numpy.ndarray
y = known_age[:, 0]
X = known_age[:, 1:]
#X[:, 0] = np.array(X[:, 0], dtype=np.float64)
#print(X[:, 0].dtype)
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
return df, rfrdata_train, rfr = set_missing_ages(data_train)
print(data_train.Age)⚪特征处理。
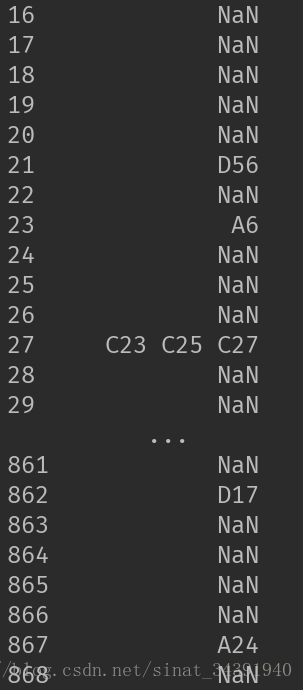
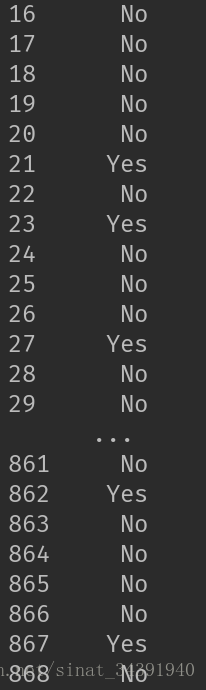
对一些不宜拟合的数据做处理,如Cabin属性缺失值太多,因此将Yes和No作为Cabin属性新的值。处理如下
处理之前
处理之后
代码如下
#特征处理
def set_Cabin_type(df):
df.loc[(df.Cabin.notnull()), 'Cabin'] = "Yes"
df.loc[(df.Cabin.isnull()), 'Cabin'] = "No"
return dfdata_train = set_Cabin_type(data_train)
print(data_train.Cabin)⚪特征因子化。
属性取值不是整型数据时,不能像比较数字10、100、1000一样来描述其大小作用,即不可量化处理的取值。为了能体现出属性下各个取值的“大小作用”,引入哑变量(Dummy Variable),将一个属性拆成k个属性,k就是原属性中不可量化的取值种类数目。如本例中Pclass属性,虽然是整型取值但不是用作大小比较的,因此将其拆分成三个新的属性Pclass_1(1=1/0=非1)、Pclass_2(1=2/0=非2)、Pclass_3(1=3/0=非3),这样就将Pclass的一维属性值在二维进行展开,同时没有丢失原属性值存储的信息。下面只将处理前后的前五条数据作展示:
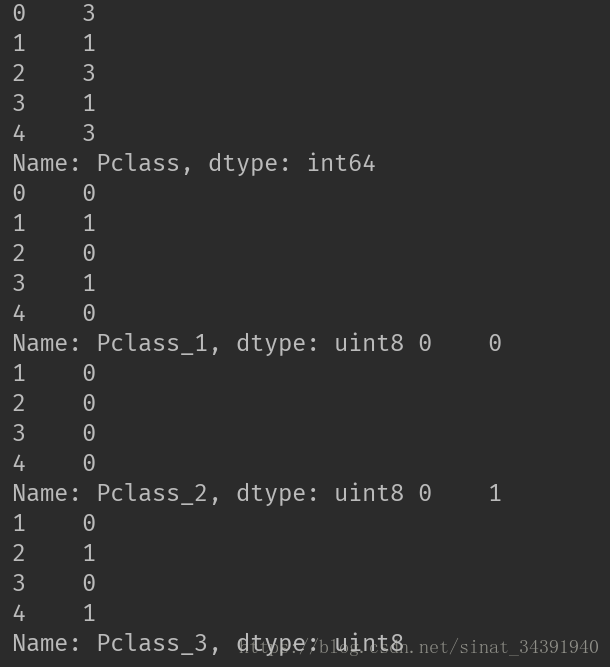
代码如下:
#特征因子化
def feature_factorization(data):
dummies_Cabin = pd.get_dummies(data['Cabin'], prefix='Cabin')
dummies_Embarked = pd.get_dummies(data['Embarked'], prefix='Embarked')
dummies_Sex = pd.get_dummies(data['Sex'], prefix='Sex')
dummies_Pclass = pd.get_dummies(data['Pclass'], prefix='Pclass')
df = pd.concat([data, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
return dfdata_train = feature_factorization(data_train)⚪范围缩放
属性取值范围可能变化很大,不同属性的取值范围变化也很大,如本例中的Age和Fare属性。因此统一将所有属性缩放到合理的大小,以使模型训练保证准确度的前提下更加迅速。下面只将处理前后的前五条数据作展示:
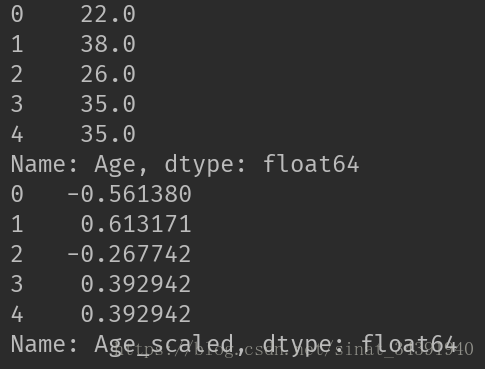
代码如下:
#特征归一化
def feature_standared(data):
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(data['Age'].values.reshape(-1, 1))
data['Age_scaled'] = scaler.fit_transform(data['Age'].values.reshape(-1, 1), age_scale_param)
fare_scale_param = scaler.fit(data['Fare'].values.reshape(-1, 1))
data['Fare_scaled'] = scaler.fit_transform(data['Fare'].values.reshape(-1, 1), fare_scale_param)
return datadata_train = feature_standared(data_train)至此,数据处理部分已经完成,接下来就需要利用处理好的属性进行模型训练。

#模型训练
def model_train(data):
train_df = data.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()
y = train_np[:, 0]
X = train_np[:, 1:]
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
return clfclf = model_train(data_train)模型已经训练完成,将测试集作同样的数据处理,放入模型中即可输出预测结果,如下图所示:
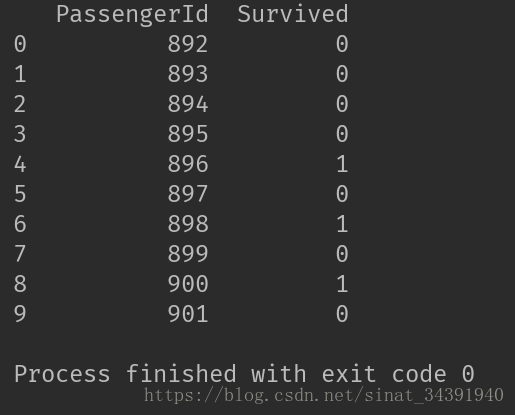
代码如下:
#利用模型进行预测
test = data_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
prediction = clf.predict(test)
result = pd.DataFrame({'PassengerId': data_test['PassengerId'].as_matrix(),
'Survived': prediction.astype(np.int32)})
print(result.head(10))这篇文章就到这里结束,这只是一个base_model,下一篇再介绍如何评估模型并进行优化。