一、问题描述

泰坦尼克号,英国白星航运公司下辖的一艘奥林匹克级邮轮,是当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”的美誉。然而讽刺的是,在第一次航行中,泰坦尼克号便遭厄运——她从英国南安普敦出发,途经法国瑟堡-奥克特维尔以及爱尔兰昆士敦,驶向美国纽约,船上时间1912年4月14日23时40分左右,泰坦尼克号与一座冰山相撞,造成船破裂,五座水密舱进水。

泰坦尼克号要沉了,大家都惊恐逃生,可是救生艇的数量有限,无法人人都有,副船长发话了lady and kid first!,是否获救其实并非随机,而是基于一些背景有rank先后的。Kaggle上这道题给的数据是泰坦尼克号上的乘客的一些信息,来预测乘客是否幸存。
二、数据处理与可视化
2.1 原始数据
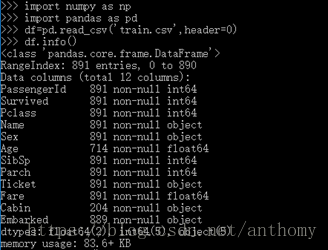

PassengerId => 乘客ID Survived => 获救情况(1为获救,0为未获救) Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名 Sex => 性别 Age => 年龄 SibSp => 堂兄弟/妹个数 Parch => 父母与小孩个数
Ticket => 船票信息 Fare => 票价 Cabin => 客舱 Embarked => 登船港口
从上述的表述可以看出
训练数据的信息,其中Embarked有两个缺失值,Age缺失值较多,Cabin有效值太少
测试数据中,Fare有一个缺失值,Age缺失值较多,Cabin有效值太少
2.2 缺失值处理
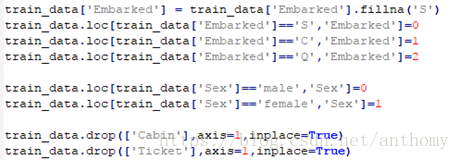
在哪儿上船Embarked这一属性(共有三个上船地点),缺失俩值,因为缺失值较少,直接给它填补上它的众数’S’,把’S’,’C’,’Q’定性转换为0,1,2
性别’Sex’,我们将其二值化’male’为0,’female’为1
船舱的缺失值确实太多,有效值仅仅有204个,很难分析出不同的船舱和存活的关系,所以在做特征工程的时候,可以直接将该组特征丢弃。
Ticket属性不方便处理,并且这个属性可以由其他信息刻画,这里也选择不处理该组特征
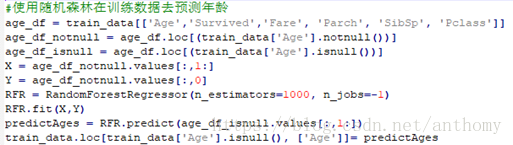
年龄采用平均值或众数填充对数据的真实性就有很大影响,并且缺失值较多,这里采用随机森林算法,对’Age’的缺失值进行预测,并填入数据中。
测试数据中的Fare属性,缺失一个值,用众数填充。
测试数据中的其他属性处理过程类似。
处理后的结果如下图

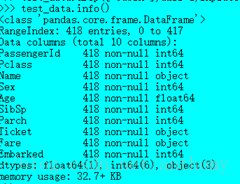
缺失数据已得到处理,接下来来看看数据的相关性。
2.3 数据可视化
2.3.1 整体生存率

整体存活率只有38.38%,只有少数人在这次灾难中活了下来
2.3.2 性别与生存与否的关系

由上图可以看出女士存活概率很高,体现出了Lady First的良好作风。
2.3.3 船舱等级与生存与否的关系
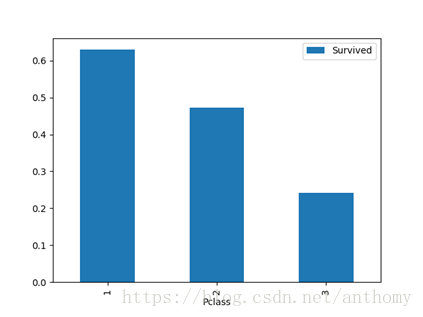
船舱等级越高,相对生存比率越高。
2.3.4 船舱等级、性别与生存与否的关系

由上图可知,船舱等级越高的女性存活率越高。
2.3.5 年龄与生存与否的关系
<1>年龄的分布情况
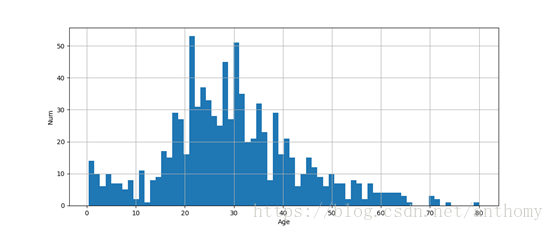
<2>年龄的统计信息

样本有891,平均年龄约为30岁,标准差13.7岁,最小年龄为0.42,最大年龄80.
按照年龄,将乘客划分为儿童(0-12岁)、少年(12-18)、成年(18-65)和老年(65-100),
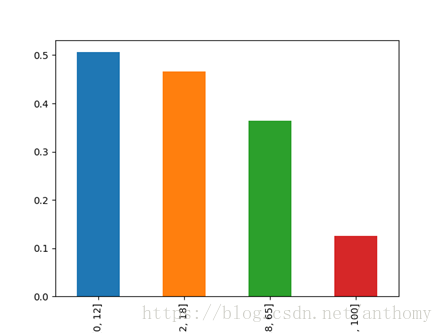
由上图可知,四个群体的生还情况是年纪越低生存率越高
2.3.6 称呼与生存与否的关系
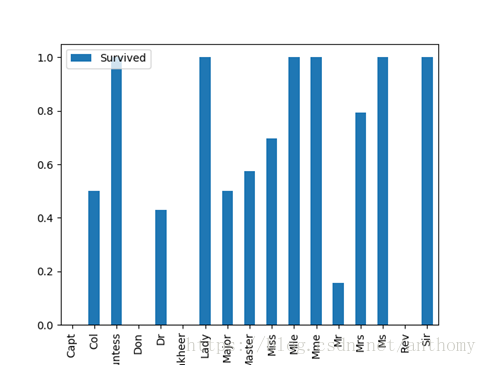
不同的称呼生存率也有不同,但是差别不大。所以在处理中,我们可以直接将特征删除
2.3.7 有无兄弟姐妹与生存与否的关系

由上图可知,有兄弟姐妹生存率会有一定的提高
2.3.8 有无父母子女与生存与否的关系

由上图可知,有父母子女生存率会有一定的提高。
2.3.9 家庭规模(SibSp+Parch)与生存与否的关系
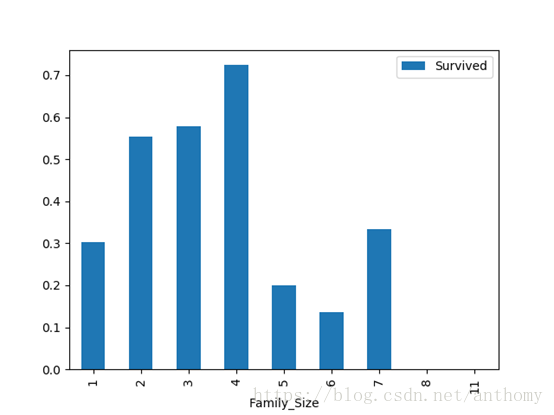
若独自一人,那么其存活率比较低;但是如果亲友(综合Sldsp和Parch的值)太多的话,存活率也会很低。
2.3.10 票价与生存与否的关系
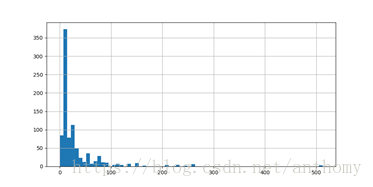
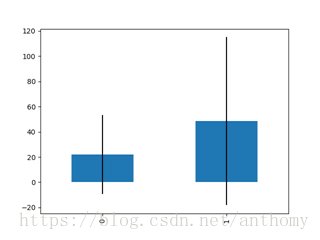
由上图知,票价与是否生还有一定的相关性,生还者的平均票价要大于未生还者的平均票价。
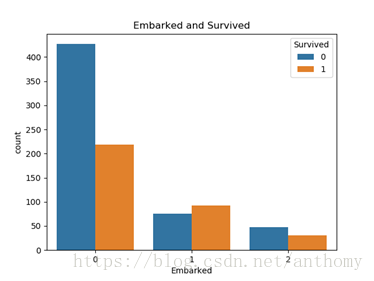
2.3.11 登船港口与生存与否的关系
泰坦尼克号从英国的南安普顿港(0)出发,途径法国瑟堡(1)和爱尔兰昆士敦(2),那么在昆士敦之前上船的人,有可能在瑟堡或昆士敦下船,这些人将不会遇到海难。
三、实验方法及原理
3.1 K近邻算法
如果一个样本在特征空间中的k个最相似(最邻近,所选择的邻居都是已正确分类的对象)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
3.2 朴素贝叶斯算法
朴素贝叶斯最核心的部分是贝叶斯法则,而贝叶斯法则的基石是条件概率。

贝叶斯定理的许多应用之一就是贝叶斯推断:根据一个已发生事件的概率,计算另一个事件的发生概率,在可以选择分类中概率最大的就是该事件的分类。是一种特殊的统计推断方法,随着信息增加,贝叶斯定理可以用于更新假设的概率。在决策理论中,贝叶斯推断与主观概率密切相关。
3.3 Adaboost算法
提升(boosting)方法是一种常用的统计学习方法,应用广泛且有效,在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。

对于分类问题,给定一个训练样本集,比较粗糙的分类规则(弱分类器),要比精确分类规则(强分类器)容易,提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器,然后组合这些弱分类器,构成一个强分类器,大多数提升方法都是改变训练数据的概率分布(训练数据的权值分布),AdaBoost的做法是,提高那些被前一轮分类器错误分类的样本的权值,而降低那些被正确分类样本的权值,这样那些没有得到正确分类的数据,由于权值加大而受到后一轮弱分类器更大的关注。
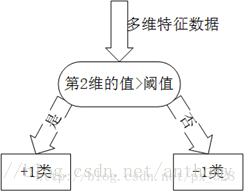
Adaboost一般使用单层决策树作为其弱分类器。单层决策树是决策树的最简化版本,只有一个决策点,也就是说,如果训练数据有多维特征,单层决策树也只能选择其中一维特征来做决策,并且需要考虑一个关键点(决策的阈值)
3.4 神经网络算法
人工神经网络(artificial neural network,缩写ANN),简称神经网络(neural network,缩写NN)或类神经网络,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具。典型的神经网络具有以下三个部分:
结构 (Architecture) 结构指定了网络中的变量和它们的拓扑关系。例如,神经网络中的变量可以是神经元连接的权重(weights)和神经元的激励值(activities of the neurons)。
激励函数(Activity Rule) 大部分神经网络模型具有一个短时间尺度的动力学规则,来定义神经元如何根据其他神经元的活动来改变自己的激励值。一般激励函数依赖于网络中的权重(即该网络的参数)。
学习规则(Learning Rule)学习规则指定了网络中的权重如何随着时间推进而调整。这一般被看做是一种长时间尺度的动力学规则。一般情况下,学习规则依赖于神经元的激励值。它也可能依赖于监督者提供的目标值和当前权重的值。
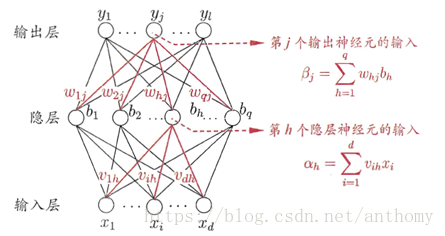
下图是一个三层的神经网络,输入层有d个节点,隐层有q个节点,输出层有l个节点。除了输入层,每一层的节点都包含一个非线性变换。
3.5 随机森林算法
随机森林属于集成学习(Ensemble Learning)中的bagging算法。在集成学习中,主要分为bagging算法和boosting算法。
随机森林的构建过程大致如下:
1.从原始训练集中使用Bootstraping方法随机有放回采样选出m个样本,共进行n_tree次采样,生成n_tree个训练集
2.对于n_tree个训练集,我们分别训练n_tree个决策树模型
3.对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据信息增益/信息增益比/基尼指数选择最好的特征进行分裂
4.每棵树都一直这样分裂下去,直到该节点的所有训练样例都属于同一类。在决策树的分裂过程中不需要剪枝
5.将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果
ID3决策树生成:
计算每个特征划分后的信息熵之后再按照信息增益的方法划分数据集。使用递归的方法构建树,直到程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类,如果所有实例具有相同的分类,则得到一个叶子借点或终止块,任何到达叶子节点的数据必然属于叶子节点的分类。

希望取a作为划分属性,划分到|V|个子节点后,所有子节点的信息熵之和即划分后的信息熵能够有很大的减小,减小的最多的那个属性就是我们选择的属性。
递归地调用,每次选择一个属性对样本集进行划分,直到两种情况使这个过程停止:
(1)某个子节点样本全部属于一类
(2)属性都用完了,这时候如果子节点样本还是不一致,那么少数服从多数
决策树的剪枝
决策树的剪枝主要是为了预防过拟合,主要思路是从叶节点向上回溯,尝试对某个节点进行剪枝,比较剪枝前后的决策树的损失函数值。最后我们通过动态规划(树形dp)就可以得到全局最优的剪枝方案。
四、使用上述算法对生存率情况进行预测
4.1 使用KNN对生存率进行预测
5 |
10 |
11 |
15 |
20 |
0.64114 |
0.66985 |
0.66507 |
0.6555 |
0.63157 |
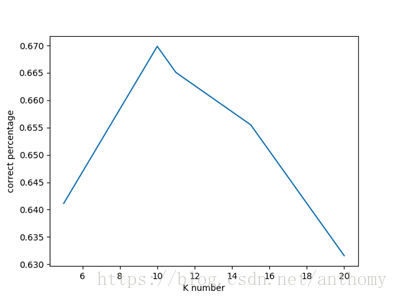
在测试数据中,在K值等于10时,分类算法正确的概率最高,但是最高也只有接近67%的正确率而已。
4.2 使用朴素贝叶斯对生存率进行预测

测试数据中正确率只有65%,效果一般。
4.3 使用Adaboost对生存率进行预测
使用集成学习方法Adaboost后,正确率明显上升,76.5%的正确率,效果较好
4.4 使用神经网络对生存率进行预测
搭建的是一个简单两层的神经网络,激活函数使用的是线性整流函数Relu,并使用了交叉验证和Adam优化器(也可以使用梯度下降进行优化),设置学习率为0.001
神经网络方法正确率75%,效果还可以。
这里只采用了两层的神经网络,层数越多,要调整的参数也就越多。
4.5 使用随机森林方法对生存率进行预测

随机森林也是一种集成学习方法,具有不错的分类效果,正确率78.4%。
4.6 使用综合模型对生存率进行预测

使用上述模型构成的简单综合,取五种预测结果中的众数,正确率有很小的提升,约为79%。
4.7 最终的Kaggle成绩

五、总结与体会
1、一个好的算法能对数据的处理结果得到更好的结果
2、数据的处理是非常关键的,是否需要降维,哪些数据是需要考虑的,不能因为不好处理而随便放弃掉数据中的一些属性,说不定这些属性也决定了分类的最终结果。
3、决策树的剪枝是非常重要的,过拟合的分类结果很差。
4、集成方法(装袋、Adaboost、随机森林)比起单个的分类方法,在分类效果上更好。
5、事情不是一蹴而就的,多尝试,多修改,才能达到更好的效果。
6、神经网络在分类问题上具有很好的一种模型,随着层数的增加,分类效果变好的同时,处理的难度也在增加。
7、随机森林有许多优点:
具有极高的准确率、随机性的引入,使得随机森林不容易过拟合,有很好的抗噪声能力
能处理很高维度的数据,并且不用做特征选择,既能处理离散型数据,也能处理连续型数据,数据集无需规范化,训练速度快,可以得到变量重要性排序。
随机森林的缺点:
当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大
六、参考文献
【1】数据挖掘十大算法之决策树详解(1)
https://blog.csdn.net/baimafujinji/article/details/51724371
【2】朴素贝叶斯分类器(NaiveBayes Classifiers)https://blog.csdn.net/sinat_36246371/article/details/60140664
【3】Peter Harrington。《机器学习实战》
【4】python使用matplotlib绘制柱状图教程
http://www.jb51.net/article/104924.htm
【5】如何解决决策树过拟合
https://wenku.baidu.com/view/6cb5d266ce2f0066f4332270.html
【6】Kaggle泰坦尼克预测
https://blog.csdn.net/guoxinian/article/details/73740746
非常感谢阅读!如有不足之处,请留下您的评价和问题 。