本文对Kaggle中的Titanic事故中乘客遇难情况进行了相应的分析和可视化,采用逻辑回归对他们的遇难情况进行了预测。最后得到的预测结果不算很好,但是本文大致是一个较为完整的数据分析和预测流程。
1. 数据集和测试集
本文的数据集和测试集来自:https://www.kaggle.com/c/titanic/data
# 导入相关库 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
导入数据集和测试集:
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
2. 数据探索和可视化
2.1 数据的类型
接下来进行数据的探索,首先可以先了解数据的类型:
train.dtypes

训练集总共12列,Survived字段表示乘客是否获救;测试集总共11列,而Survived是我们需要预测的目标。
2.2 数据的可视化探索
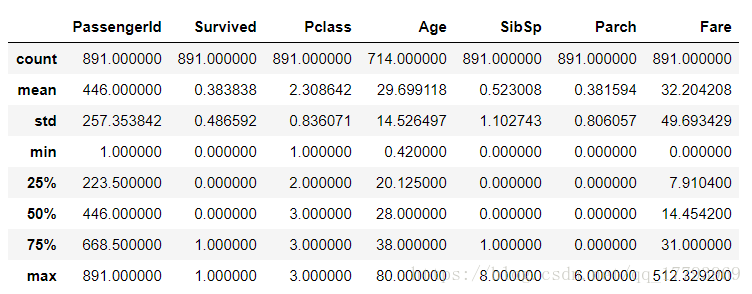
首先通过pandas中的describe()得到数值型数据的分布特点:
train.describe()
接着可以分析各个特征对应的人数分布:
# 中文字体设置
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 各属性对应的人数分布
plt.subplot(2,2,1)
sns.countplot(x='Survived', data=train)
plt.title('存活情况')
plt.subplot(2,2,2)
sns.countplot(x='Pclass', data=train)
plt.title('各等级舱人数')
plt.subplot(2,2,3)
sns.countplot(x='Sex', data=train)
plt.title('男女人数')
plt.subplot(2,2,4)
sns.countplot(x='Embarked', data=train)
plt.title('登船港口')
plt.tight_layout()

可以看出,3等舱的人数最多,男性乘客显著多余女性乘客,而登船港口则明显集中于'S',典型的偏态分布。
接着可以分析各个特征与乘客是否获救之间的关系:
船舱等级:
# 舱等级与存活情况之间的关系
Survived_0 = train.Pclass[train.Survived == 0].value_counts()
Survived_1 = train.Pclass[train.Survived == 1].value_counts()
Pclass_df = pd.DataFrame({'未获救': Survived_0, '获救': Survived_1})
Pclass_df.plot(kind='bar', stacked=True)
plt.title('各乘客舱等级的获救情况')
plt.xlabel('乘客舱等级')
plt.ylabel('人数')
plt.show()

可以看出,头等舱获救率明显较高,3等舱获救率则较低。
上船港口:
# 上船港口与存活情况之间的关系
Survived_0 = train.Embarked[train.Survived == 0].value_counts()
Survived_1 = train.Embarked[train.Survived == 1].value_counts()
Pclass_df = pd.DataFrame({'未获救': Survived_0, '获救': Survived_1})
Pclass_df.plot(kind='bar', stacked=True)
plt.title('不同上传港口乘客的获救情况')
plt.xlabel('乘客上传港口')
plt.ylabel('人数')
plt.show()
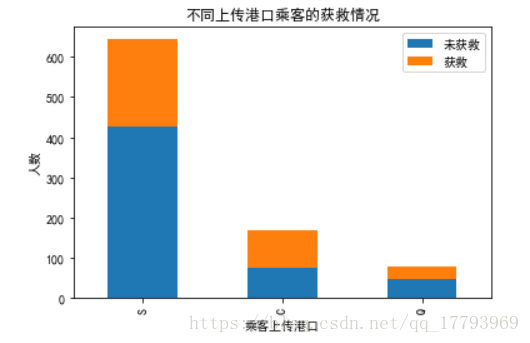
这里暂时看不出港口与存活率之间的关系。
性别:
# 性别与存活情况之间的关系
Survived_0 = train.Sex[train.Survived == 0].value_counts()
Survived_1 = train.Sex[train.Survived == 1].value_counts()
Pclass_df = pd.DataFrame({'未获救': Survived_0, '获救': Survived_1})
Pclass_df.plot(kind='bar', stacked=True)
plt.title('各乘客性别的获救情况')
plt.xlabel('乘客性别')
plt.ylabel('人数')
plt.show()

从堆积直方图可以看出,女性显然更易获救,为了进一步确认,我们绘出性别与获救之间的关系:
sns.factorplot(x='Sex',y='Survived',data=train)
plt.title('各乘客性别的获救情况')
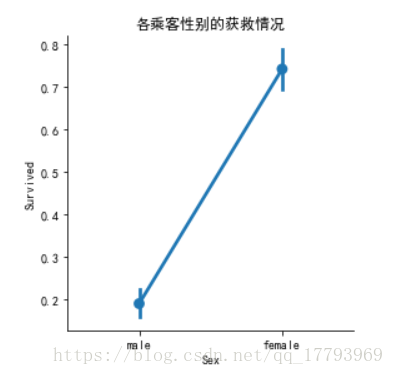
可见,确实女性乘客存活率明显更高。
分析不同年龄层的乘客获救情况:
# 不同年龄层的乘客获救情况 df=train[['Age','Sex','Survived']] bins=[0,20,25,30,35,40,50,60,100] factor = pd.cut(df['Age'],bins=bins) sns.pointplot(x=factor, y='Survived',hue='Sex',data=df)
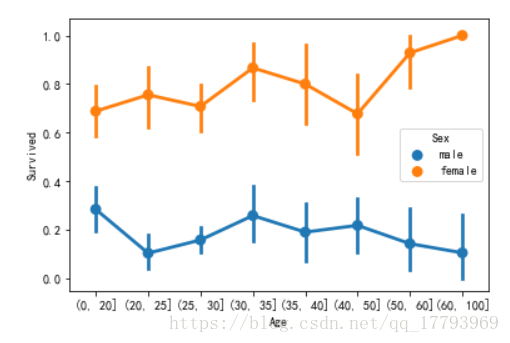
可以看到,各个年龄层女性获救概率都远大于男性,可以初步得出结论,性别对获救与否有很大影响。
3. 数据清洗与补全
完成数据的基本探索后,在建立模型之前,我们还需要对数据进行清洗,并且对数据集中缺失的数据进行补全。
首先了解数据的缺失情况:
train.info()
print('-'*30)
test.info()
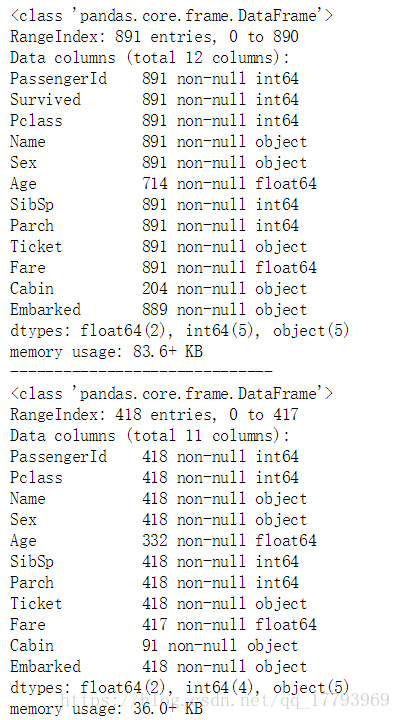
训练集中有891条数据,而测试集中有418条数据。
训练集缺失值:Age,Cabin,Embarked,其中Cabin字段缺失数量较多; 测试集缺失值:Age,Cabin,Fare,其中Cabin字段缺失数量较多。
对数据进行补全:
# Cabin属性在测试集和训练集中都缺失过多,可以将这一特征处理成有和无两种属性
train.loc[ train.Cabin.notnull(), 'Cabin' ] = 'Yes'
train.loc[ train.Cabin.isnull(), 'Cabin' ] = 'No'
test.loc[ train.Cabin.notnull(), 'Cabin' ] = 'Yes'
test.loc[ train.Cabin.isnull(), 'Cabin' ] = 'No'
# 训练集中的Embarked和测试集中的Fare属性缺失数量较少,采用相应的属性中最多的项或平均值来补全
train['Embarked'].fillna('S', inplace=True)
test['Fare'].fillna(test['Fare'].mean(), inplace=True)
# 用年龄的平均值补全训练集和测试集中的年龄属性
train['Age'].fillna(train['Age'].mean(), inplace=True)
test['Age'].fillna(test['Age'].mean(), inplace=True)
train.info()
print('-'*30)
test.info()
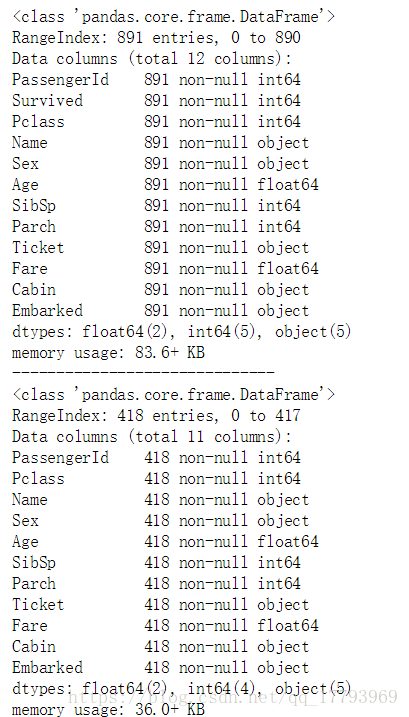
可以看到,数据缺失已经被补全。
4. 数据预处理
4.1 One-hot 编码
建立模型时,我们需要的特征往往都是数值型,因此我们需要将对相应属性转换为one-hot编码表示,首先我们打印出数据集的前5行,看看哪些特征需要进行转换:
train.head()

把需要转换的属性定为以下6个:Pclass,Sex, SibSp, Parch, Cabin, Embarked,采用pandas的get_dummies函数进行转换:
train_dummies_Pclass = pd.get_dummies(train['Pclass'], prefix='Pclass') test_dummies_Pclass = pd.get_dummies(test['Pclass'], prefix='Pclass') train_dummies_Sex = pd.get_dummies(train['Sex'], prefix='Sex') test_dummies_Sex = pd.get_dummies(test['Sex'], prefix='Sex') train_dummies_SibSp = pd.get_dummies(train['SibSp'], prefix='SibSp') test_dummies_SibSp = pd.get_dummies(test['SibSp'], prefix='SibSp') train_dummies_Parch = pd.get_dummies(train['Parch'], prefix='Parch') test_dummies_Parch = pd.get_dummies(test['Parch'], prefix='Parch') train_dummies_Cabin = pd.get_dummies(train['Cabin'], prefix='Cabin') test_dummies_Cabin = pd.get_dummies(test['Cabin'], prefix='Cabin') train_dummies_Embarked = pd.get_dummies(train['Embarked'], prefix='Embarked') test_dummies_Embarked = pd.get_dummies(test['Embarked'], prefix='Embarked')
# 将one-hot编码表示的属性拼接在原来的数据集上,保存到train_df和test_df中 train_df = pd.concat([train, train_dummies_Pclass, train_dummies_Sex, train_dummies_SibSp, train_dummies_Parch, train_dummies_Cabin, train_dummies_Embarked], axis=1) test_df = pd.concat([test, test_dummies_Pclass, test_dummies_Sex, test_dummies_SibSp, test_dummies_Parch, test_dummies_Cabin, test_dummies_Embarked], axis=1) train_df.drop(['Pclass', 'Sex', 'SibSp', 'Parch', 'Cabin', 'Embarked'], axis=1, inplace=True) test_df.drop(['Pclass', 'Sex', 'SibSp', 'Parch', 'Cabin', 'Embarked'], axis=1, inplace=True)
我们再次看看转换后的数据集(下图没有显示完整):
train_df.head()
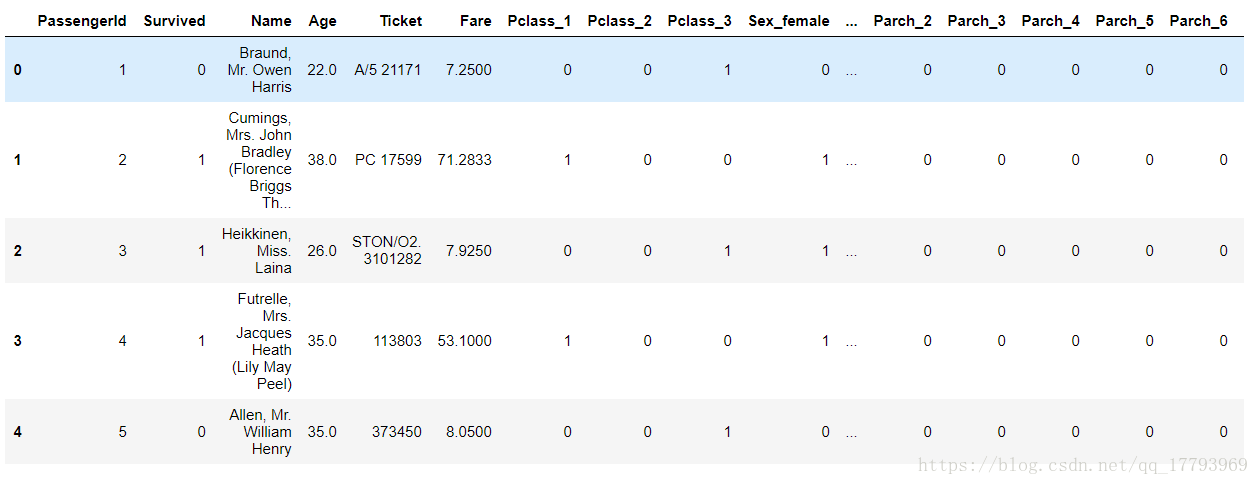
可以看到,相应属性已经被转化为了one-hot编码,例如Pclass属性有三个值:1、2、3,转化为转化为三个属性列:Pclass_1、Pclass_2、Pclass_3。
4.2 标准化
目前的特征属性中,Age和Fare属性变化赋值范围太大,可能影响后续模型的收敛,因此对其进行标准化:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(train_df['Age'].values.reshape(-1,1)) train_df['Age_scaled'] = scaler.transform(train_df['Age'].values.reshape(-1,1)) test_df['Age_scaled'] = scaler.transform(test_df['Age'].values.reshape(-1,1)) scaler.fit(train_df['Fare'].values.reshape(-1,1)) train_df['Fare_scaled'] = scaler.transform(train_df['Fare'].values.reshape(-1,1)) test_df['Fare_scaled'] = scaler.transform(test_df['Fare'].values.reshape(-1,1)) train_df.drop(['Age', 'Fare'], axis=1, inplace=True) test_df.drop(['Age', 'Fare'], axis=1, inplace=True) train_df.head()

可以看到,Age和Fare属性已经被标准化到0-1之间。至此,终于可以开始建立预测模型。
5. 建立模型
# 采用逻辑回归模型
from sklearn.linear_model import LogisticRegression
# 将不需要的Name,Ticket和PassengerId移除
train_df2 = train_df.drop(['Name', 'Ticket','PassengerId'], axis=1)
test_df2 = test_df.drop(['Name', 'Ticket', 'PassengerId'], axis=1)
train_df2.info()
print('-'*30)
test_df2.info()

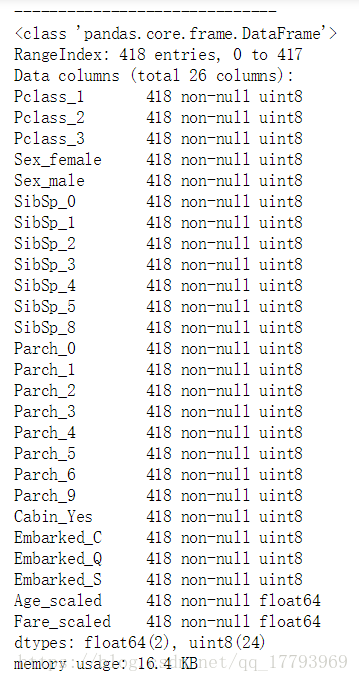
创建特征的标签的索引:
train_df2_colValue = train_df2.columns.values
train_df2_colValue_X = train_df2_colValue[1:]
train_df2_colValue_y = train_df2_colValue[0]
test_df2_colValue_X = test_df2.columns.values
print('train_df2_colValue_X:', train_df2_colValue_X)
print('train_df2_colValue_y:', train_df2_colValue_y)
print('test_df2_colValue_X:', test_df2_colValue_X)

训练模型:
# 训练模型 lr = LogisticRegression() lr.fit(train_df2[train_df2_colValue_X], train_df2[train_df2_colValue_y])

到这里,模型创建完成,并通过fit函数将训练集的feature和label分别导入模型进行拟合,获得生成的模型lr。
对测试集进行预测:
# 对测试集进行预测 predictions = lr.predict(test_df2[test_df2_colValue_X])
创建提交到Kaggle的csv文件:
# 创造提交文件
ids = test["PassengerId"]
submission_df = {"PassengerId": ids,
"Survived": predictions}
submission = pd.DataFrame(submission_df)
submission.to_csv("submission_Titanic.csv", index=False)

这个模型预测的结果只有0.77的准确率,不过作为一个初步模型,这也是一般的情况。
6. 模型优化
6.1 模型关联系数分析
coef = pd.DataFrame({'columns':train_df2_colValue_X, 'coef':list(lr.coef_.T)})
coef
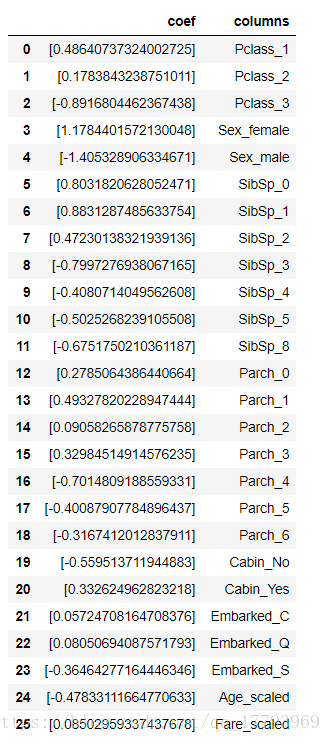
将模型中每个特征的系数打印出来分析,可以看到:头等舱可以很好的提升获救率,而三等舱与获救率则有着明显的负相关,女性与获救率之间则有着明显的正相关等。
4.2 交叉验证
之前我们直接在测试集上进行了预测,为了优化模型,我们可以首先在一部分训练集上进行预测,与真实的情况进行对比,采用sklearn里的交叉预测模块进行分析:
from sklearn import model_selection
scores = model_selection.cross_val_score(lr, train_df2[train_df2_colValue_X], train_df2[train_df2_colValue_y], cv=10)
accuracy = np.mean(scores)
print('cross_val_score:', scores)
print('mean cross_val_score:', accuracy)
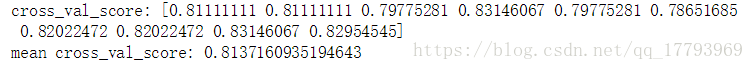
可以看到,平均准确率在0.81,较在测试集上的预测结果稍高一些。
4.3 Learning curve
通过learning curve,可以大致判断模型是否过拟合,采用sklearn中的learning_curve模块来绘出larning curve图像:
from sklearn.learning_curve import learning_curve
# 用sklearn的learning_curve得到training_score和cv_score,使用matplotlib画出learning curve
def plot_learning_curve(estimator, X, y, title='Learning curve', cv=None, n_jobs=1,
train_sizes=np.linspace(.05, 1., 20), verbose=0, plot=True):
"""
绘出data在某模型上的learning curve.
----------
输入参数:
estimator : 用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
n_jobs : 并行的的任务数(默认1)
train_sizes:训练样本的相对的或绝对的数字
verbose: 控制冗余,越高,有越多的信息
"""
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, verbose=verbose)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
if plot:
plt.figure()
plt.title(title)
plt.xlabel('训练样本数')
plt.ylabel('得分')
plt.grid()
plt.plot(train_sizes, train_scores_mean, 'o-', color="y", label='训练集上的得分')
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label='交叉验证集上的得分')
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std,
alpha=0.1, color="y")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std,
alpha=0.1, color="g")
plt.legend(loc='best')
plt.show()
return None
plot_learning_curve(lr,train_df2[train_df2_colValue_X], train_df2[train_df2_colValue_y])
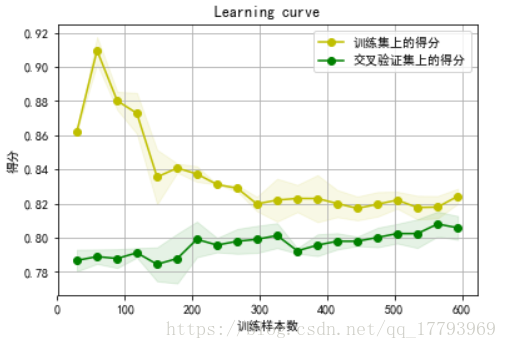
当过拟合时,模型在训练集上的得分将远大于在交叉验证集上的得分,因此从图上可以看出,本文的模型没有明显的过拟合现象。
在这之后,为了提高预测准确率,还需要进行更进一步的特征工程的工作,并且,采用多模型融合也可能可以提高预测的准确率。本文在补全未知数据时,采用了较为简单的方法,尤其时对年龄的补全,采用了所有数据的平均值作为缺失年龄的补全值,这样的做法可能并不科学;另外,对于PassengerId、Name和Ticket的信息没有进行有效的利用,在这些方面进一步深挖,也许可以提高预测的准确率。