1.提出问题:符合哪些特征的人在Titanic遇难时获救的可能性更高
2.理解数据
2.1 导入数据
import numpy as np
import pandas as pd
train = pd.read_csv('data/Train.csv')
test = pd.read_csv('data/Test.csv')
print('训练数据集:',train.shape)
print('测试训练集:',test.shape)
训练数据集: (891, 12)
测试训练集: (418, 11)
2.2 合并数据,进行清洗
full = train.append(test,ignore_index=Ture)
print ('合并后的数据集:',full.shape)
合并后的数据集: (1309, 12)
2.3 查看数据集信息
full.info()

我们发现数据总共有1309行。
其中数据类型列:年龄(Age)、船舱号(Cabin)里面有缺失数据:
1)年龄(Age)里面数据总数是1046条,缺失了1309-1046=263,缺失率263/1309=20%
2)船票价格(Fare)里面数据总数是1308条,缺失了1条数据
字符串列:
1)登船港口(Embarked)里面数据总数是1307,只缺失了2条数据,缺失比较少
2)船舱号(Cabin)里面数据总数是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比较大
3.数据清洗
3.1 数据预处理
缺失值处理:
在机器学习算法中,许多训练模型算法不能有空值
常用的补全缺失值方法有:
(1)数值型数据,可以使用平均数,众数进行补全
(2)如果是分类数据,用最常见的类别取代
(3)若处理的数值比较重要,则用模型预测缺失值补全
处理数值型缺失值:
print('处理前:')
full.info()
#年龄(Age)
full['Age']=full['Age'].fillna( full['Age'].mean() )
#船票价格(Fare)
full['Fare'] = full['Fare'].fillna( full['Fare'].mean() )
print('处理红后:')
full.info()
#检查数据处理是否正常
full.head()
处理字符型缺失值:
字符串列:
(1) 登船港口(Embarked)里面数据总数是1307,只缺失了2条数据,缺失比较少
(2) 船舱号(Cabin)里面数据总数是295,缺失了1309-295=1014,缺失率=1014/1309=77.5%,缺失比较大
登船港口(Embarked):
出发地点:S=英国南安普顿Southampton
途径地点1:C=法国 瑟堡市Cherbourg
途径地点2:Q=爱尔兰 昆士敦Queenstown
查看数据样式,进行补全:
full['Embarked'].value_counts()
对’Embarked’特征,其中’S’是比例最大的值,按照S进行填充
full['Embarked'] = full['Embarked'].fillna( 'S' )
对’Cabin’特征,缺失值比较多,将缺失值用特征‘U’代替
full['Cabin'] = full['Cabin'].fillna( 'U' )
检查数据是否正常
full.head()
数据处理后,要对数据进行检查,确保没有丢失数据和特征
full.info()
3.2 特征提取
3.2.1 数据分类
(1)数值类型
乘客编号(PassengerId),年龄(Age),船票价格(Fare),同代直系亲属人数(SibSp),不同代直系亲属人数(Parch)
(2)时间序列:无
(3)分类数据:
(1)有直接类别的
乘客性别(Sex):男性:male=1 女性:female=0
登船港口(Embarked):‘S’ , ‘Q’ ,‘C’
客舱等级(Pclass):1=1等舱,2=2等舱,3=3等舱
(2)字符串类型:可能从这里面提取出特征来,也归到分类数据中
乘客姓名(Name)
客舱号(Cabin)
船票编号(Ticket)
有直接类别-性别(Sex)
将字符串类别映射成数值:男性:male=1 女性:female=0
sex_mapDict={'male':1 , 'female':0}
full['Sex']=full['Sex'].map(sex_mapDict)
full.head()
有直接类别-登船港口(Embarked)
使用get_dummies进行one-hot编码,列名前缀是Embarked
embarkedDf = pd.DataFrame()
embarkedDf = pd.get_dummies( full['Embarked'] , prefix='Embarked' )
embarkedDf.head()
因为已经转换了Embarked的编码,所以删除’Embarked’特征
full = pd.concat([full,embarkedDf],axis=1)
pd.drop('Embarked',axis=1,inplace=True)
有直接类别-客舱等级(Pclass)
1 = 1等舱 2 = 2等舱 3 = 3等舱
pclassDf = pd.DataFrame()
#使用get_dummies进行one-hot编码,列名前缀是Pclass
pclassDf = pd.get_dummies( full['Pclass'] , prefix='Pclass' )
pclassDf.head()
添加one-hot编码产生的虚拟变量(dummy variables)到数据集full
删掉客舱等级(Pclass)这一列
full = pd.concat([full,pclassDf],axis=1)
full.drop('Pclass',axis=1,inplace=True)
full.head()
字符串类型-乘客姓名(Name)
乘客姓名中含有头衔,头衔的不同可能与逃生的机会有关系
定义函数:从名字中获取头衔
def getTitle(name)
str1=name.split( ',' )[1] #Mr. Owen Harris
str2=str1.split( '.' )[0]#Mr
#strip() 方法用于移除字符串头尾指定的字符(默认为空格)
str3=str2.strip()
return str3
titleDf = pd.DataFrame()
#map函数:对Series每个数据应用自定义的函数计算
titleDf['Title'] = full['Name'].map(getTitle)
titleDf.head()
定义以下几种头衔类别:
Officer政府官员
Royalty王室(皇室)
Mr已婚男士
Mrs已婚妇女
Miss年轻未婚女子
Master有技能的人/教师
#姓名中头衔字符串与定义头衔类别的映射关系
title_mapDict = {
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess":"Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Miss" : "Miss",
"Master" : "Master",
"Lady" : "Royalty"
}
titleDf['Title'] = titleDf['Title'].map(title_mapDict)
#使用get_dummies进行one-hot编码
titleDf = pd.get_dummies(titleDf['Title'])
titleDf.head()
添加one-hot编码到full数据集中
full = pd.concat([full,titleDf],axis=1)
#删掉姓名这一列
full.drop('Name',axis=1,inplace=True)
full.head()
字符串类型-客舱号(Cabin)
使用lambda函数创建匿名函数
cabinDf = pd.DataFrame()
full[ 'Cabin' ] = full[ 'Cabin' ].map( lambda c : c[0] )
#使用get_dummies进行one-hot编码,列名前缀是Cabin
cabinDf = pd.get_dummies( full['Cabin'] , prefix = 'Cabin' )
cabinDf.head()
添加one-hot编码产生的虚拟变量到full
full = pd.concat([full , cabinDf] , axis = 1)]
#删掉客舱号这一列
full.drop('Cabin',axis=1,inplace=True)
full.head()
建立家庭人数和家庭类别
家庭人数=同代直系亲属数(Parch)+不同代直系亲属数(SibSp)+乘客自己
家庭类别:
小家庭Family_Single:家庭人数=1
中等家庭Family_Small: 2<=家庭人数<=4
大家庭Family_Large: 家庭人数>=5
familyDf = pd.DataFrame()
familyDf['FamilySize'] = full['Parch'] + full[ 'SibSp' ] + 1
#if 条件为真的时候返回if前面内容,否则返回0
familyDf[ 'Family_Single' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if s == 1 else 0 )
familyDf[ 'Family_Small' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if 2<= s <= 4 else 0 )
familyDf[ 'Family_Large' ] = familyDf[ 'FamilySize' ].map( lambda s : 1 if 5<=s else 0 )
familyDf.head()
将产生的one-hot编码添加到full数据集中
full = pd.concat([full,familyDf],axis=1)
已有33个特征
3.3 特征选择
相关系数法:计算各个特征的相关系数
#相关性矩阵
corrDf = full.corr()
corrDf
'''
查看各个特征与生成情况(Survived)的相关系数,
ascending=False表示按降序排列
'''
corrDf['Survived'].sort_values(ascending =False)
将排名靠前的特征提取出来分析
full_X = pd.concat( [titleDf,#头衔
pclassDf,#客舱等级
familyDf,#家庭大小
full['Fare'],#船票价格
cabinDf,#船舱号
embarkedDf,#登船港口
full['Sex']#性别
] , axis=1 )
full_X.head()
生成相关性图矩
from seaborn as sns
sns.heatmap(full_X.astype(float).corr(),linewidths=0.1,vmax=1.0, square=True, linecolor='white', annot=True)
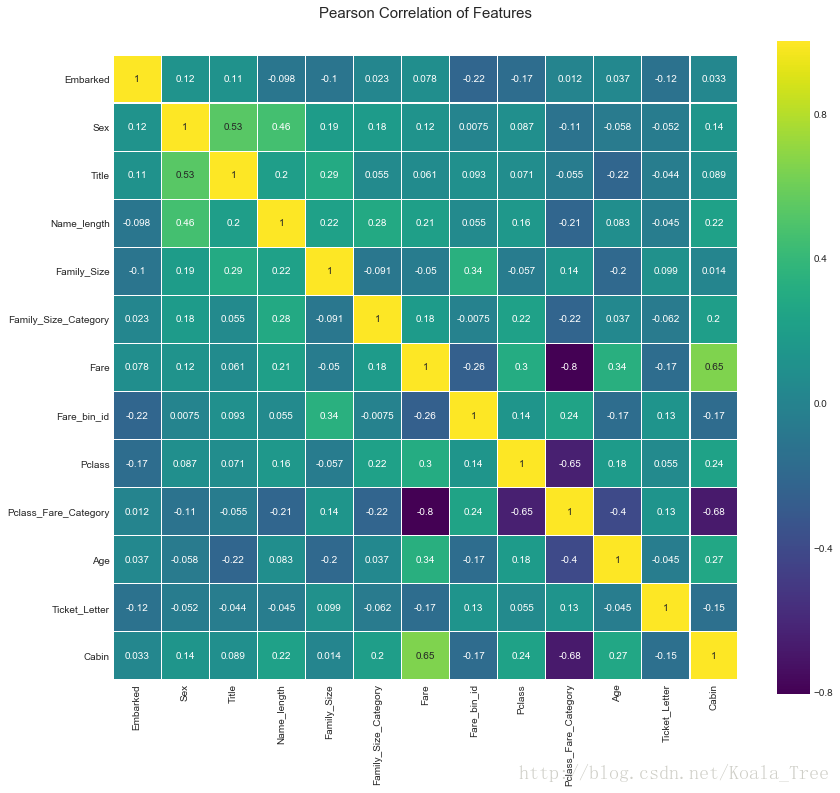
4.构建模型
4.1 建立训练数据集和测试数据集
sourceRow = train.sape[0]
source_X = full_X.loc[0 : sourceRow-1 , :]
source_y = full_X.loc[0 : sourceRow-1 , ‘Survived’]
#输入预测特征集
pred_X = full_X.loc[sourceRow: , :]
#原始数据集有多少行
print('原始数据集有多少行:',source_X.shape[0])
#预测数据集大小
print('原始数据集有多少行:',pred_X.shape[0])
从原始数据集(source)中拆分出训练数据集(用于模型训练train),测试数据集(用于模型评估test)
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和test data
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
from sklearn.model_selection import train_test_split
#建立模型用的训练数据集和测试数据集
train_X , test_X , train_y , test_y = train_test_split( source_X , source_y , train.size = 0.8 )
#输出数据集大小
print ('原始数据集特征:',source_X.shape,
'训练数据集特征:',train_X.shape ,
'测试数据集特征:',test_X.shape)
print ('原始数据集标签:',source_y.shape,
'训练数据集标签:',train_y.shape ,
'测试数据集标签:',test_y.shape)
4.2 选择机器学习算法
第一步:导入算法
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
第二步:创建模型
model = LogisticRegression()
#model = RandomForestClassifier(n_estimators=100)
#model = SVC()
#model = GradientBoostingClassifier()
#model = KNeighborsClassifier(n_neighbors = 3)
#model = GaussianNB()
第三步:训练模型
model.fit(train_X , train_y)
第四部:评估训练出来的模型
model.score(test_X , test_y)
5.使用模型
使用模型,对预测数据集中的生存情况预测
pred_Y = model.predict(pred_X)
生成的预测数值是浮点数,但要求的是整数型,要对数据进行转换
pred_Y=pred_Y.astype(int)
将乘客ID和预测值对应
passenger_id = full.loc[ sourceRow: , 'PassengerId' ]
predDf = pd.DataFrame(
{
'PassengerId': passenger_id ,
'Survived' : pred_Y
})
prefDf.head( )
#保存结果
prefDf.to_csv( 'titanic_pred.csv' , index = False )
