Titanic是kaggle上的一道入门题目,很适合新手去练市数据分析。
这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存。这是个二元分类的机器学习问题。数据链接:https://www.kaggle.com/c/titanic/data
1. 数据清洗(Data Cleaning)
2. 探索性可视化(Exploratory Visualization)
3. 特征工程(Feature Engineering)
4. 基本建模&评估(Basic Modeling& Evaluation)
一 。数据清洗
import pandas as pd
import numpy as np
train=pd.read_csv('F:\\kaggleData\\titanic\\train.csv')
train.head()
train.info()
train.describe()
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
- PassengerId => 乘客ID
- Pclass => 客舱等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 兄弟姐妹数/配偶数
- Parch => 父母数/子女数
- Ticket => 船票编号
- Fare => 船票价格
- Cabin => 客舱号
- Embarked => 登船港口
train.isnull().sum()
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
1.1缺失值的处理
1.删除含有缺失值的记录
也就是将存在遗漏信息属性值的对象删除,从而得到一个完备的信息表。这种方法简单易行,在对象有多个属性缺失值、被删除的含缺失值的对象与信息表中的数据量相比非常小的情况下是非常有效的。
2.插补缺失值
(1)中位数、众数、均值插补。
数据的属性定性数据和定量数据。如果缺失值是定量的,就以该字段存在值的平均值来插补缺失的值;如果缺失值是定性的,就根据统计学中的众数原理,用该属性的众数(即出现频率最高的值)来补齐缺失的值。
(2)利用同类均值插补。
它用层次聚类模型预测缺失变量的类型,再以该类型的均值插补。假设X=(X1,X2…Xp)为信息完全的变量,Y为存在缺失值的变量,那么首先对X或其子集行聚类,然后按缺失个案所属类来插补不同类的均值。如果在以后统计分析中还需以引入的解释变量和Y做分析,那么这种插补方法将在模型中引入自相关,给分析造成障碍。
(3)极大似然估计(Max Likelihood ,ML)。
在缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,那么通过观测数据的边际分布可以对未知参数进行极大似然估计(Little and Rubin)。这种方法也被称为忽略缺失值的极大似然估计,对于极大似然的参数估计实际中常采用的计算方法是期望值最大化(Expectation Maximization,EM)。使用前提:大样本,并且有效样本的数量足够以保证ML估计值是渐近无偏的并服从正态分布。但是这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂。
(4)K最近距离邻法(K-means clustering)
先根据欧式距离或相关分析来确定距离具有缺失数据样本最近的K个样本,将这K个值加权平均来估计该样本的缺失数据。
同均值插补的方法都属于单值插补,不同的是,它用层次聚类模型预测缺失变量的类型,再以该类型的均值插补。假设X=(X1,X2…Xp)为信息完全的变量,Y为存在缺失值的变量,那么首先对X或其子集行聚类,然后按缺失个案所属类来插补不同类的均值。如果在以后统计分析中还需以引入的解释变量和Y做分析,那么这种插补方法将在模型中引入自相关,给分析造成障碍。
(5)回归方法
基于完整的数据集,建立回归方程(模型)。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关或预测变量高度相关时会导致有偏差的估计。
3.不处理
直接在包含空值的数据上进行数据挖掘。这类方法包括贝叶斯网络和人工神经网络等。
对于缺失数据,其中Embarked和Fare的缺失值较少,可以直接用众数和中位数插补。
Cabin的缺失值较多,目前不做处理。
二。数据的可视化
看看各个特征对应的存活情况。
2.1乘客的各个属性
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['font.family']='sans-serif'
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数
plt.subplot2grid((2,3),(0,0)) # 在一张大图里分列几个小图
train.Survived.value_counts().plot(kind='bar')# 柱状图
plt.title(u"获救情况 (1为获救)") # 标题
plt.ylabel(u"人数") # Y轴标签
plt.subplot2grid((2,3),(0,1))
train.Pclass.value_counts().plot(kind="bar") # 柱状图显示
plt.ylabel(u"人数")
plt.title(u"乘客等级分布")
plt.subplot2grid((2,3),(0,2))
plt.scatter(train.Survived, train.Age) #为散点图传入数据
plt.ylabel(u"年龄") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"按年龄看获救分布 (1为获救)")
plt.subplot2grid((2,3),(1,0), colspan=2)
train.Age[train.Pclass == 1].plot(kind='kde') # 密度图
train.Age[train.Pclass == 2].plot(kind='kde')
train.Age[train.Pclass == 3].plot(kind='kde')
plt.xlabel(u"年龄")# plots an axis lable
plt.ylabel(u"密度")
plt.title(u"各等级的乘客年龄分布")
plt.legend((u'头等舱', u'2等舱',u'3等舱'),loc='best') # sets our legend for our graph.
plt.subplot2grid((2,3),(1,2))
train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数")
plt.ylabel(u"人数")
plt.show()

2.2各属性与获救情况的关联
各乘客等级的获救情况
Survived_0 = train.Pclass[train.Survived == 0].value_counts() # 未获救Survived_1 = train.Pclass[train.Survived == 1].value_counts() # 获救
df = pd.DataFrame({u'获救':Survived_1,u'未获救':Survived_0})
df.plot(kind = 'bar', stacked = True)
plt.title(u'各乘客等级的获救情况')
plt.xlabel(u'乘客等级')
plt.ylabel(u'人数')

各性别的获救情况
Survived_m = train.Survived[train.Sex == 'male'].value_counts()
Survived_f = train.Survived[train.Sex == 'female'].value_counts()
df = pd.DataFrame({u'男性':Survived_m,u'女性':Survived_f})
df.plot(kind = 'bar', stacked = True)
plt.title(u'按性别看获救情况')
plt.xlabel(u'性别')
plt.ylabel(u'人数')
plt.show()

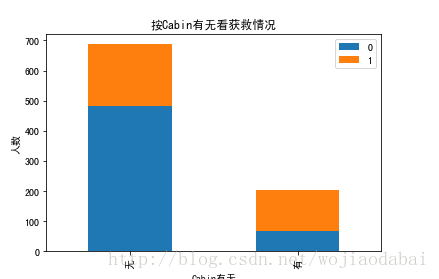
按Cabin有无看获救情况
Survived_cabin = train.Survived[pd.notnull(train.Cabin)].value_counts()
Survived_nocabin = train.Survived[pd.isnull(train.Cabin)].value_counts()
df = pd.DataFrame({u'有':Survived_cabin, u'无':Survived_nocabin}).transpose()
df.plot(kind = 'bar', stacked = True)
plt.title(u'按Cabin有无看获救情况')
plt.xlabel(u'Cabin有无')
plt.ylabel(u'人数')
plt.show()
三。特征工程
##age 用中值填充
train['Age']=train['Age'].fillna(train['Age'].median())
#####Sex 0-1化
print(train['Sex'].unique())
train.loc[train['Sex']=='male','Sex']=0
train.loc[train['Sex']=='female','Sex']=1
print(train['Embarked'].unique())
train['Embarked']=train['Embarked'].fillna('S')
train.loc[train['Embarked']=='S','Embarked']=0
train.loc[train['Embarked']=='C','Embarked']=1
train.loc[train['Embarked']=='Q','Embarked']=2
Embarked用众数填充,然后转化成数值型,unique函数可以查看每一列的分类,
#print(train['Embarked'].unique())
[0 1 2]
接下来就建模:
1.先用线性回归
from sklearn.linear_model import LinearRegression
from sklearn.cross_validation import KFold
##选择特征
predictors=['Pclass','Sex','Age','SibSp','Fare','Embarked']
lr=LinearRegression()
#sklearn.cross_validation用来进行交叉验证,先把train分为训练集和测试集,再把训练样本分成三份,用来交叉验证
kf=KFold(train.shape[0],n_folds=3,random_state=1)predictions=[]
for tra,test in kf:
tra_predictors=(train[predictors].iloc[tra,:])
tra_target=train['Survived'].iloc[tra]
lr.fit( tra_predictors,tra_target)
test_predictons=lr.predict(train[predictors].iloc[test,:])
predictions.append(test_predictons)
import numpy as np
predictions=np.concatenate(predictions,axis=0)
##大于0.5为1 ,小于0.5位0
predictions[predictions>0.5]=1
predictions[predictions<=0.5]=0
accuracy=sum(predictions[predictions==train["Survived"]])/len(predictions)
print(accuracy)
0.261503928171
结果太低了,实在是无语。
2.用随机森林来拟合
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
predictors=['Pclass','Sex','Age','SibSp','Fare','Embarked']
##每次选10个样本,每次分裂两个,产生两个叶节点
alg=RandomForestClassifier(random_state=1,n_estimators=10,min_samples_split=2,min_samples_leaf=2)
kf=KFold(train.shape[0],n_folds=3,random_state=1)
scores=cross_validation.cross_val_score(alg,train[predictors],train['Survived'],cv=kf)
print(scores.mean())
0.822671156004
拟合概率比回归模型好多了。
当然,还有的变量没有用上,拟合应该还可以更好。
最后,也可以将导出的csv文件在Kaggle中进行提交。