Titanic 生存预测(上)
欢迎来到我的学习记录博客
最近学习pandas的时候,体会到如果一直看大量教程,不仅磨灭学习热情还会有抓不住重点没有整体认识的感觉,不如直接上手实例数据,这样对数据分析甚至机器学习的整套流程以及pandas的常用功能都会有基本的了解。
所以我以Kaggle中经典的Titanic数据集数据分析作为我的第一篇CSDN文章。
在这篇博客文章中,我将讲述在著名的泰坦尼克数据集上创建一个机器学习模型的整个过程,这个数据集被世界各地的许多人使用。它提供泰坦尼克号上乘客的命运信息,根据经济地位(等级)、性别、年龄和生存状况进行汇总。
RMS Titanic(背景)
皇家邮轮泰坦尼克号是一艘英国客轮,1912年4月15日凌晨沉没在北大西洋,在从南安普顿到纽约的处女航中撞上冰山。据估计,船上有2224名乘客和船员,超过1500人死亡,这是现代历史上和平时期最致命的商业海上灾难之一。泰坦尼克号是当时最大的水上游轮,也是白星航运公司运营的三艘奥林匹克级远洋客轮中的第二艘。

Importing the Libraries
#linear algebra
import numpy as np
#data processing
import pandas as pd
#data visualization
import seaborn as sns
from matplotlib import pyplot as plt
from matplotlib import style
#algorithms
from sklearn import linear_model
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC,LinearSVC
from sklearn.naive_bayes import GaussianNB
Getting the Data
test_df = pd.read_csv("test.csv")
train_df = pd.read_csv("train.csv")
Data Exploration
train_df.info()
运行结果:

训练集有891个例子和11个特征+目标变量(幸存)。其中2个是浮点数,5个是整数,5个是对象。
train_df.describe()
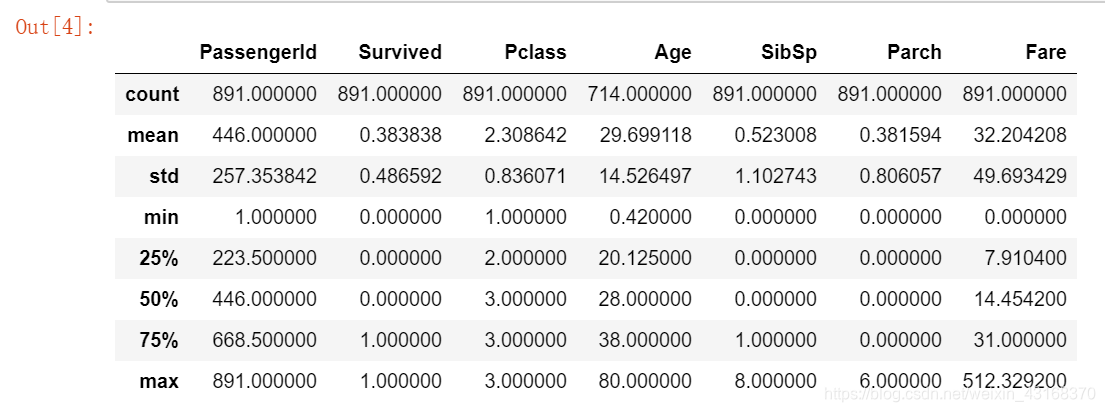 在上面我们可以看到38%的火车在泰坦尼克号上幸存了下来。我们还可以看到乘客的年龄在0.4到80岁之间。除此之外,我们已经可以检测到一些包含缺失值的特性,比如“年龄”特性。
在上面我们可以看到38%的火车在泰坦尼克号上幸存了下来。我们还可以看到乘客的年龄在0.4到80岁之间。除此之外,我们已经可以检测到一些包含缺失值的特性,比如“年龄”特性。
train_df.head(8)
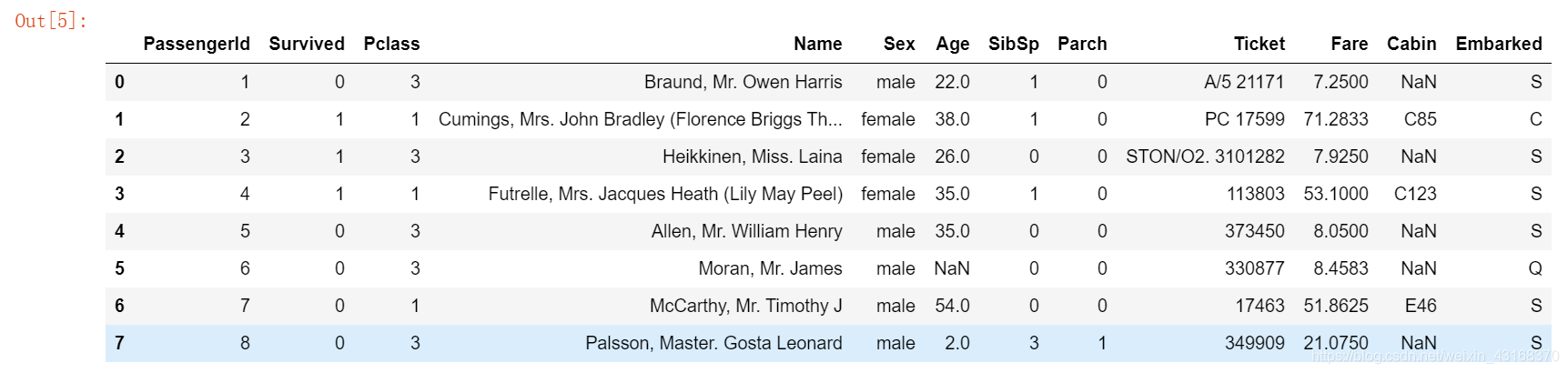 从上面的表格中,我们可以注意到一些事情。首先,我们需要把很多特征转换成数值特征,这样机器学习算法才能处理它们。此外,我们可以看到这些特性具有不同的范围,我们需要将这些范围转换为大致相同的范围。我们还可以发现更多的特性,这些特性包含我们需要处理的缺失值(NaN = not a number)。
从上面的表格中,我们可以注意到一些事情。首先,我们需要把很多特征转换成数值特征,这样机器学习算法才能处理它们。此外,我们可以看到这些特性具有不同的范围,我们需要将这些范围转换为大致相同的范围。我们还可以发现更多的特性,这些特性包含我们需要处理的缺失值(NaN = not a number)。
让我们更详细地看看哪些数据实际上是缺失的:
total=train_df.isnull().sum().sort_values(ascending=False)
p1=round(train_df.isnull().sum()/train_df.isnull().count()*100,1)
p2=p1.sort_values(ascending=False)
missing_data=pd.concat([total,p2],axis=1,keys=['Total','%'])
missing_data.head(5)
 Embarked特征只有两个缺失值,可以很容易地填补。要处理“年龄”特性要复杂得多,它有177个缺失的值。“Cabin”特征需要进一步的调查,但看起来我们可能想要把它从数据集中删除,因为它的77%是失踪的。
Embarked特征只有两个缺失值,可以很容易地填补。要处理“年龄”特性要复杂得多,它有177个缺失的值。“Cabin”特征需要进一步的调查,但看起来我们可能想要把它从数据集中删除,因为它的77%是失踪的。
>>>train_df.columns.values
array(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp','Parch', 'Ticket', 'Fare', 'Cabin','Embarked'],dtype=object)
上面可以看到11个特性+目标变量(存活)。哪些特征有助于提高存活率?
对我来说,如果除了‘乘客身份证’、‘车票’和‘姓名’之外的所有东西都与高存活率相关,那就说得通了。
isnull用法(小插曲)
python的pandas库中isnull()函数,可以用来判断缺失值。
首先我们创建一个dataframe,其中有一些数据为缺失值。
###isnull
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.rand(8,5))
df.iloc[6:8,0]=np.nan
df.iloc[1:4,2]=np.nan
df.iloc[3:5,4]=np.nan
df
输出为:
0 1 2 3 4
0 0.682206 0.305236 0.369599 0.517843 0.810993
1 0.267073 0.382239 NaN 0.973444 0.299277
2 0.565783 0.721179 NaN 0.389783 0.532427
3 0.162865 0.428798 NaN 0.472107 NaN
4 0.797429 0.605827 0.855398 0.023409 NaN
5 0.407492 0.102099 0.459061 0.523023 0.508735
6 NaN 0.196554 0.472896 0.342083 0.776740
7 NaN 0.142510 0.733085 0.919060 0.369357
df.isnull() #元素为空或者NA就显示True,否则就是False
输出:
0 1 2 3 4
0 False False False False False
1 False False True False False
2 False False True False False
3 False False True False True
4 False False False False True
5 False False False False False
6 True False False False False
7 True False False False False
df.isnull().any() #判断哪些列包含缺失值,该列存在缺失值则返回True,反之False。
输出:
0 True
1 False
2 True
3 False
4 True
dtype: bool
对比count() 、isnull().count()和isnull().sum()
df.count() #每一列中非缺失值的个数
输出:
0 6
1 8
2 5
3 8
4 6
dtype: int64
df.isnull().count() #每一列总元素个数
输出:
0 8
1 8
2 8
3 8
4 8
dtype: int64
df.isnull().sum() #每列缺失数据的个数
输出:
0 2
1 0
2 3
3 0
4 2
dtype: int64
Data Analysis
分析乘客年龄和票价分布
fig,axes=plt.subplots(2,1,figsize=(10,5))
train_df['Age'].hist(ax=axes[0]) #年龄分布
axes[0].set_title('plot of age')
train_df['Fare'].hist(ax=axes[1]) #票价分布
axes[1].set_title('plot of fare')
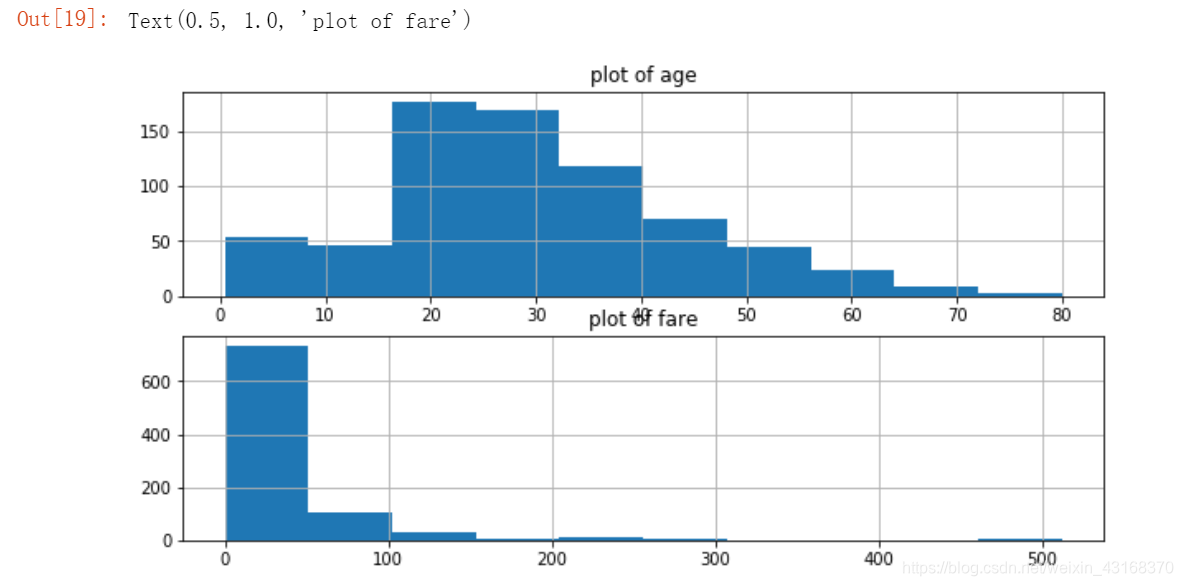 结论:
结论:
1.大部分乘客的年龄在20到40岁之间
2.票价在主要分布在(0,100)美元之间
整体生存状况
survived_rate = float(train_df['Survived'].sum())/train_df['Survived'].count()
print (survived_rate)
by_survived = train_df.groupby(['Survived'])['Survived'].count()
plt.pie(by_survived,labels=['Non-Survived','Survived'],autopct='%1.0f%%')
plt.title('Pie Chart Of Surviveness for Surviveness of Passengers')
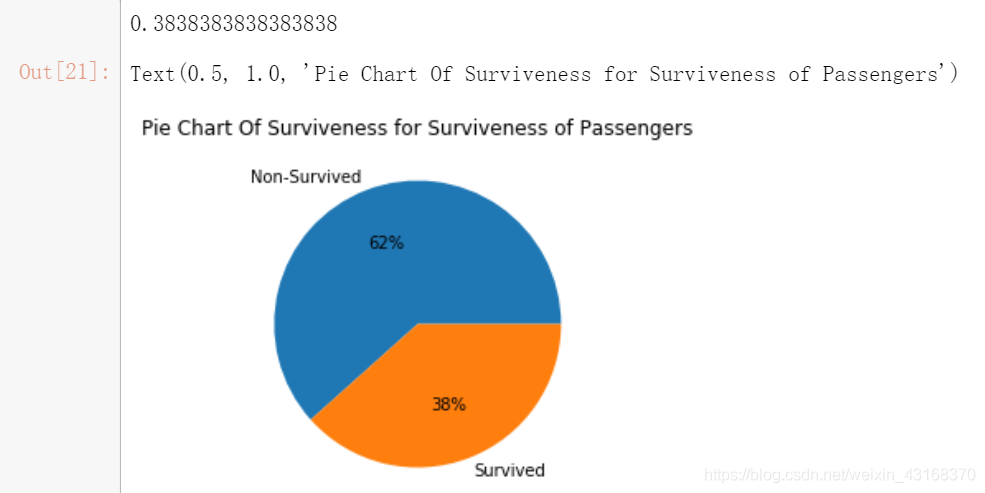 结论:整体的存活率不超过40%
结论:整体的存活率不超过40%
性别与生存的关系
train_df.groupby(['Sex','Survived'])['Survived'].count()
Sex Survived
female 0 81
1 233
male 0 468
1 109
Name: Survived, dtype: int64
train_df[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()
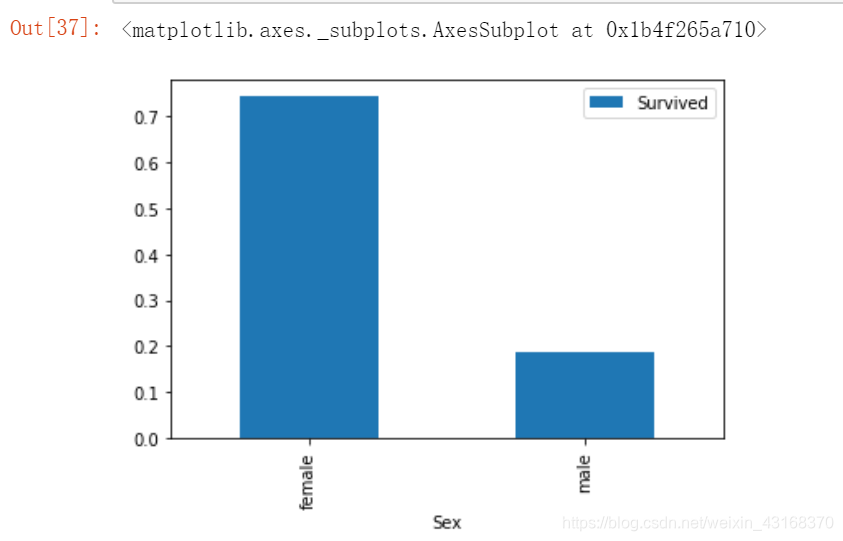 结论:在泰坦尼克事故中,女士的存活率是男士的三倍还多,体现了Lady First原则。
结论:在泰坦尼克事故中,女士的存活率是男士的三倍还多,体现了Lady First原则。
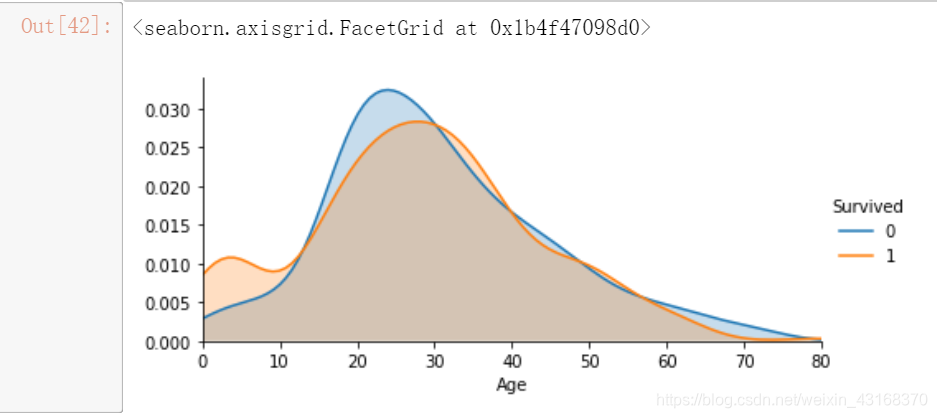
年龄与生存的关系
不同年龄下的生存状况:
face = sns.FacetGrid(train_df, hue="Survived",aspect=2)
face.map(sns.kdeplot,'Age',shade= True)
face.set(xlim=(0, train_df['Age'].max()))
face.add_legend()
上船地点、舱位等级和生存的关系
FacetGrid = sns.FacetGrid(train_df, row='Embarked', size=2.5, aspect=1.6)
FacetGrid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette=None, order=None, hue_order=None )
FacetGrid.add_legend()
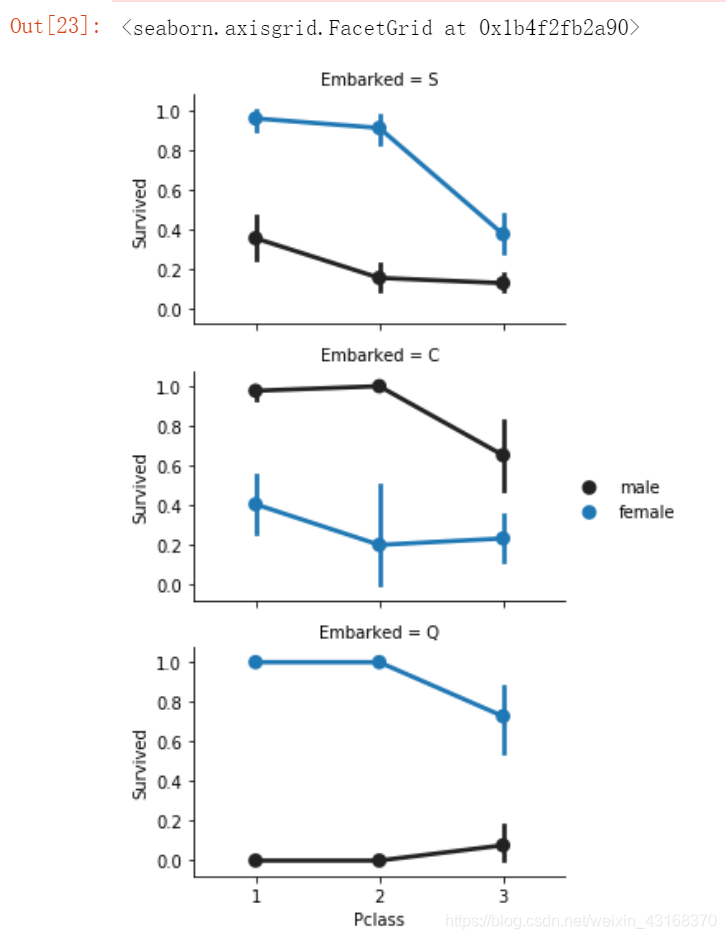 结论: 舱位等级似乎与生存相关,并取决于性别。
结论: 舱位等级似乎与生存相关,并取决于性别。
在Q港和S港的妇女有更高的生存机会。反之亦然,如果他,男士有较高的生存几率,但如果他们在Q或S港,生存几率就很低。
Pclass似乎也与存活率有关。我们将在下面分析。
舱位等级和生还的关系
sns.barplot(x='Pclass', y='Survived', data=train_df)
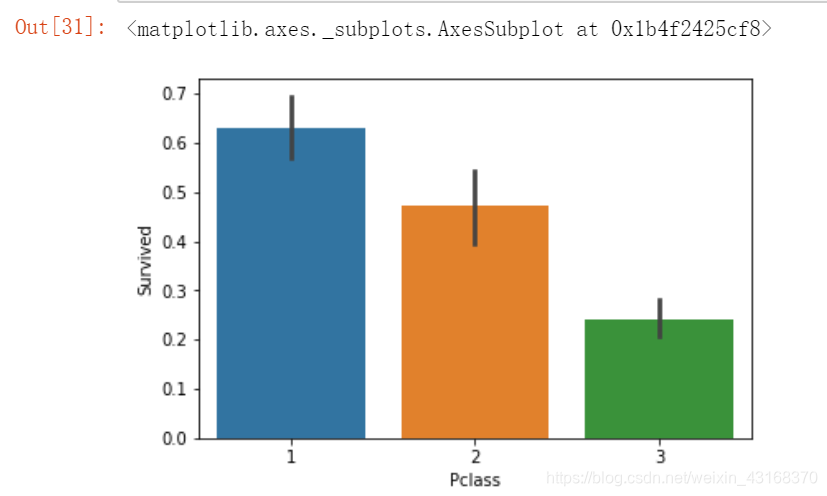 结论:1等舱生还的几率超过50%,2等舱的生还几率接近50%,而三等舱获救的可能性最低,证实了事故发生时三等舱被第一时间锁死
结论:1等舱生还的几率超过50%,2等舱的生还几率接近50%,而三等舱获救的可能性最低,证实了事故发生时三等舱被第一时间锁死
亲友的人数与生存的关系 SibSp and Parch
SibSp和Parch作为一个综合特征会更有意义,它显示了一个人在泰坦尼克号上的亲戚总数,代表是否有人陪同,be alone or not.
data = [train_df, test_df]
for dataset in data:
dataset['relatives'] = dataset['SibSp'] + dataset['Parch']
dataset.loc[dataset['relatives'] > 0, 'not_alone'] = 0
dataset.loc[dataset['relatives'] == 0, 'not_alone'] = 1
dataset['not_alone'] = dataset['not_alone'].astype(int)
train_df['not_alone'].value_counts()
1 537
0 354
Name: not_alone, dtype: int64
axes = sns.factorplot('relatives','Survived', data=train_df, aspect = 1.5)
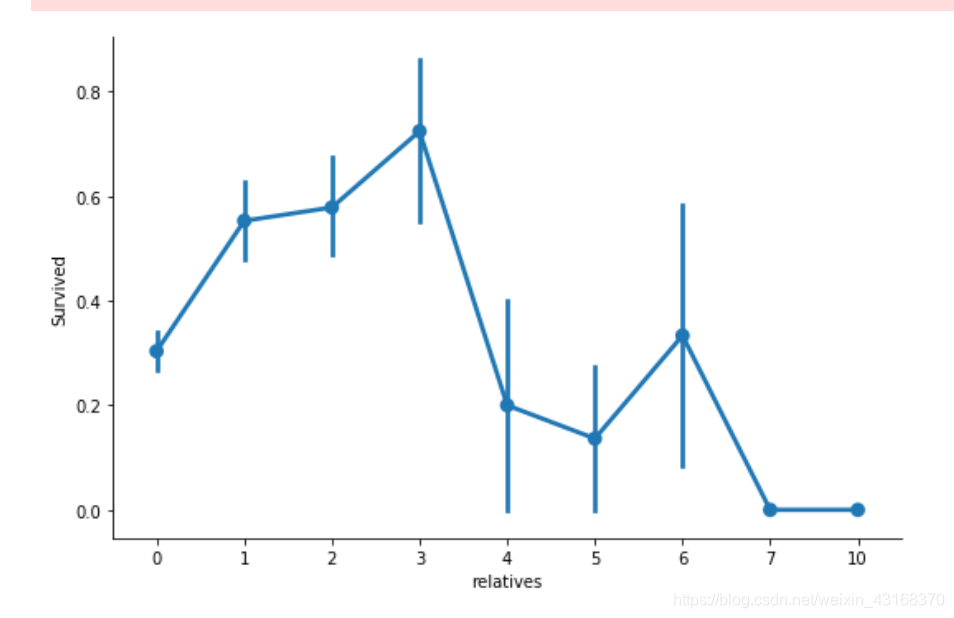 在这里我们可以看到,与1到3个亲戚在身边时生存概率较高,但如果你有少于1或多于3(除了一些情况下有6个亲戚)存活率将会更低。
在这里我们可以看到,与1到3个亲戚在身边时生存概率较高,但如果你有少于1或多于3(除了一些情况下有6个亲戚)存活率将会更低。
以上为所给出的数据特征与生还与否的分析。
据了解,泰坦尼克号上共有2224名乘客,该数据集只给出了891名乘客的信息。根据中心极限定理,若891组数据为随机选出且总样本数据足够大,那么我们的分析就是合理的;否则会有不合理的分析出现。
groupby用法
groupby根据字面意思就是按xx分组,我们看一下它是如何实现的。
df=pd.DataFrame({
'A':[1,2,2,3,3,3],
'B':[8,9,8,9,8,9],
'C':np.random.randn(6)
})
df
A B C
0 1 8 -0.604327
1 2 9 -0.805326
2 2 8 0.925473
3 3 9 -0.567683
4 3 8 -0.727911
5 3 9 -0.215905
>>>df.groupby('A') #按照A标签 分组聚合
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001F4FEF42A58>
这里我们得到了一个叫DataFrameGroupBy的东西, 但是 pandas 不让我们直接看它长啥样。
>>>df.groupby('A')['B'].mean() #按照A这一列作分组聚合,B这一列作统计运算
A
1 8.000000
2 8.500000
3 8.666667
Name: B, dtype: float64
对每一组数据进行操作 (取平均 取中值 取方差 或 自定义函数),我把对这些DataFrame的操作计划写成字典, 然后进行agg, (aggragate, 合计)。但是列名将被分成不同层级。
>>>df.groupby('A')['B'].agg({'计数':np.size,'w':[np.mean,np.std]})
w 计数
mean std B
A
1 8.000000 NaN 1
2 8.500000 0.707107 2
3 8.666667 0.577350 3
同时groupby方便可视化,直接免去遍历的循环筛选,一行搞定。
df.groupby('A')['B'].value_counts().unstack().plot(kind='bar', figsize=(3, 3))

我将在下半部分继续介绍:数据预处理,创建分类,ML建模,K折交叉验证等等。
感谢您的阅读~
