文章目录
0. 问题:Survived from Titanic Disaster
小呆听了小瓜讲了几天的课了,有点理解又有点理解不够深入,于是小瓜甩给小呆一道数据分析的题目,从Titanic Disaster逃难的项目练手以增加理解。
项目数据摘自:Titanic: Machine Learning from Disaster
注:https://www.kaggle.com 是一个Data Science的竞赛平台,里面有很多实际的项目数据。
1. 分析问题
从kaggle中下载数据有:test.csv、train.csv。
先导入数据,初看数据内容
import pandas as pd
df = pd.read_csv('train.csv')
pd.set_option('display.width', 1000)
pd.set_option('display.max_columns', None)
print(df)
print(df.columns)
print(df.shape)
输出
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
.. ... ... ... ... ... ... ... ... ... ... ... ...
889 890 1 1 Behr, Mr. Karl Howell male 26.0 0 0 111369 30.0000 C148 C
890 891 0 3 Dooley, Mr. Patrick male 32.0 0 0 370376 7.7500 NaN Q
[891 rows x 12 columns]
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
(891, 12)
导入的训练数据集为形如(891,12)的DataFrame格式,其中列标签为[‘PassengerId’, ‘Survived’, ‘Pclass’, ‘Name’, ‘Sex’, ‘Age’, ‘SibSp’,‘Parch’, ‘Ticket’, ‘Fare’, ‘Cabin’, ‘Embarked’]。这里解释一下标签意义:
1.PassengerId:乘客编号
2.Survived:存活与否
3.Pclass:客舱等级
4.Name:乘客姓名
5.Sex:乘客性别
6.Age:乘客年龄
7.SibSp:乘客兄弟姐妹等亲戚个数
8.Parch:乘客随行父母/子女个数
9.Ticket:票号
10.Fare:票价
11.Cabin:仓号
12.Embarked:从哪里上船
1.1 影响因素分析
我们要寻找存活和列标签[‘Pclass’, ‘Name’, ‘Sex’, ‘Age’, ‘SibSp’,‘Parch’, ‘Ticket’, ‘Fare’, ‘Cabin’, ‘Embarked’]的关系,初步进行判断哪些是有关系的,哪些是肯定没啥关系。
1.Name列:由于不是算命先生,小呆确认乘客姓名和存活与否没有半毛钱关系
2.Ticket列:由于小呆不信命,所以确认乘客票号和存活与否没有关系(另外观察Ticket内容不具有规律性,所以也是排除原因)
那么原来的数据集可以直接删去这两列。
df2 = df.drop(['Name', 'Ticket'],axis = 1)
print(df2)
结果显示如下
PassengerId Survived Pclass Sex Age SibSp Parch Fare Cabin Embarked
0 1 0 3 male 22.0 1 0 7.2500 NaN S
1 2 1 1 female 38.0 1 0 71.2833 C85 C
2 3 1 3 female 26.0 0 0 7.9250 NaN S
3 4 1 1 female 35.0 1 0 53.1000 C123 S
4 5 0 3 male 35.0 0 0 8.0500 NaN S
.. ... ... ... ... ... ... ... ... ... ...
886 887 0 2 male 27.0 0 0 13.0000 NaN S
887 888 1 1 female 19.0 0 0 30.0000 B42 S
888 889 0 3 female NaN 1 2 23.4500 NaN S
889 890 1 1 male 26.0 0 0 30.0000 C148 C
890 891 0 3 male 32.0 0 0 7.7500 NaN Q
[891 rows x 10 columns]
剩下[‘Pclass’, ‘Sex’, ‘Age’, ‘SibSp’,‘Parch’, ‘Ticket’, ‘Fare’, ‘Cabin’],我们一项一项来看看与存活与否的关系。
1.1.1 性别、舱等级
首先看看性别、舱等级和存活与否的关系。

survived_class = []
dead_class = []
survived_class.append(df2[df2['Pclass'] < 2]['Survived'].sum())
survived_class.append(df2[df2['Pclass'] == 2]['Survived'].sum())
survived_class.append(df2[df2['Pclass'] > 2]['Survived'].sum())
dead_class.append(df2[df2['Pclass'] < 2].shape[0]-survived_class[0])
dead_class.append(df2[df2['Pclass'] == 2].shape[0]-survived_class[1])
dead_class.append(df2[df2['Pclass'] > 2].shape[0]-survived_class[2])
survived_sex=[]
dead_sex=[]
survived_sex.append(df2[df2['Sex']=='female']['Survived'].sum())
survived_sex.append(df2[df2['Sex']=='male']['Survived'].sum())
dead_sex.append(df2[df2['Sex']=='female'].shape[0]-survived_sex[0])
dead_sex.append(df2[df2['Sex']=='male'].shape[0]-survived_sex[1])
ind1 = np.arange(3)
fig = plt.figure('Data Analysis: Titanic Disaster')
ax_class = plt.subplot(1,2,1)
ax_class.bar(ind1, survived_class, 0.3)
ax_class.bar(ind1, dead_class, 0.3, bottom=survived_class)
plt.xticks(ind1,('First Class', 'Second Class', 'Third Class'))
plt.title('Survived passengers of difference class')
ind2 = np.arange(2)
ax_sex = plt.subplot(1,2,2)
ax_sex.bar(ind2, survived_sex, 0.3)
ax_sex.bar(ind2, dead_sex, 0.3, bottom=survived_sex)
plt.xticks(ind2,('Female', 'Male'))
plt.title('Survived passengers of difference sex')
plt.show()
结果如下
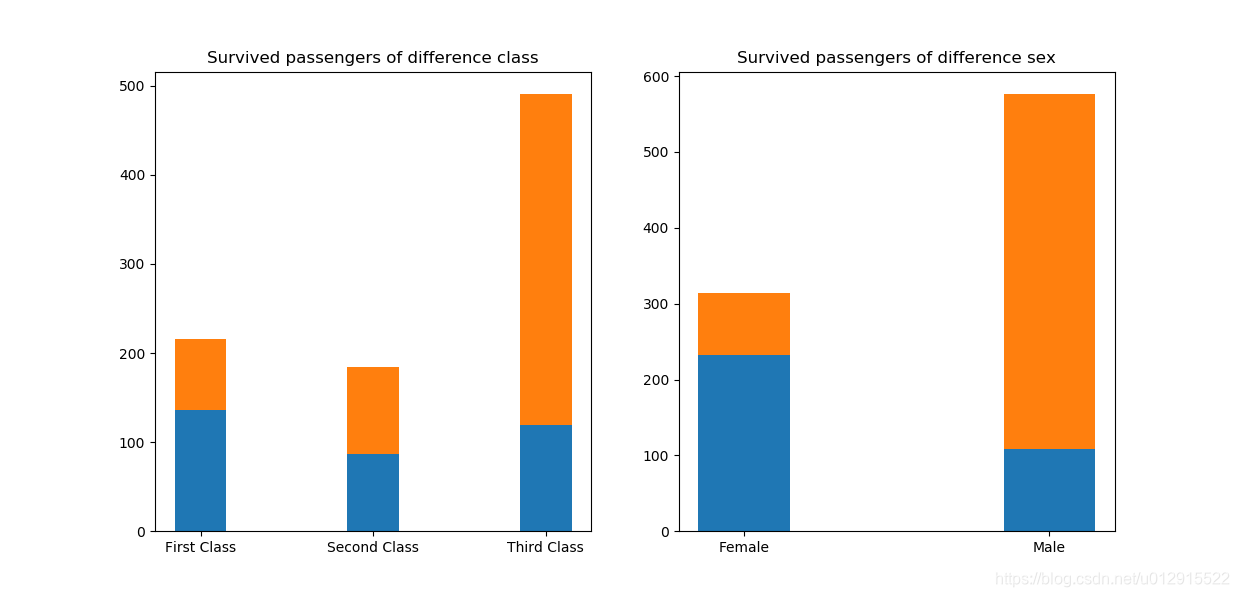
非常明显能够观察到两点:
1.在Titanic上人数三等舱>头等舱>二等舱,女性<男性;
2.最终存活概率头等舱>二等舱>三等舱,女性>男性。
所以舱等级和性别是影响存活与否的关键因素,所以必须选定作为特征之一。
1.1.2 年龄
再来看年龄
print(df2[df2['Age'].isna()])
结果如下
5 6 0 3 male NaN 0 0 330877 8.4583 NaN
17 18 1 2 male NaN 0 0 244373 13.0000 NaN
19 20 1 3 female NaN 0 0 2649 7.2250 NaN
26 27 0 3 male NaN 0 0 2631 7.2250 NaN
.. ... ... ... ... ... ... ... ... ... ...
863 864 0 3 female NaN 8 2 CA. 2343 69.5500 NaN
868 869 0 3 male NaN 0 0 345777 9.5000 NaN
878 879 0 3 male NaN 0 0 349217 7.8958 NaN
888 889 0 3 female NaN 1 2 W./C. 6607 23.4500 NaN
[177 rows x 10 columns]
也就是说年龄存在总共177行的缺失值。在做数据进一步分析前,需要进行处理。
缺失值的补充可以参见小呆学数据分析——缺失值处理(一),先用最简单的方式处理,用平均值补充。
1.1.3 家庭成员
接下来看SibSp和Parch两列数据
survived_sibsp = []
dead_sibsp = []
for loopi in range(0, df2.SibSp.max()+1):
survived_sibsp.append(df2[df2.SibSp==loopi]['Survived'].sum())
dead_sibsp.append(df2[df2.SibSp==loopi].shape[0]-survived_sibsp[loopi])
survived_parch = []
dead_parch = []
for loopj in range(0, df2.Parch.max()+1):
suvived_parch.append(df2[df2.Parch==loopj]['Survived'].sum())
dead_parch.append(df2[df2.Parch==loopj].shape[0]-survived_parch[loopj])
ind4 = np.range(survived_sibsp.shape[0])
ax_sibsp = plt.subplot(1,2,1)
ax_sibsp.bar(ind4, survived_sibsp, 0.3)
ax_sibsp.bar(ind4, dead_sibsp, 0.3, bottom=survived_sibsp)
plt.xticks(ind4, ind4)
ind5 = np.range(survived_parch.shape[0])
ax_parch = plt.subplot(1,2,2)
ax_parch.bar(ind5, survived_parch, 0.3)
ax_parch.bar(ind5, dead_parch, 0.3, bottom=survived_parch)
plt.xticks(ind5, ind5)
plt.show()
结果见下图,可见单身的人数是最多的,有多个家庭成员(>2)的样本太少了,单个个体对于结果影响过大。
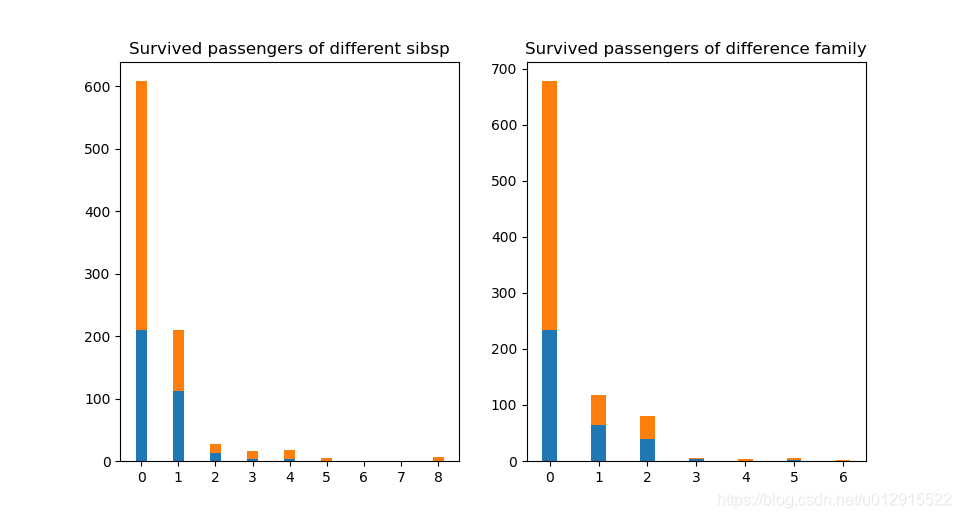
再来看百分比的图,好像也没有明确的规律性,我们可以想到实际上家庭成员在灾难面前可能具有相同的效果,所以可以看看将两者相加之后有什么显著的改变没有,并且将总数大于4的合并以减少个别样本对小样本的影响。
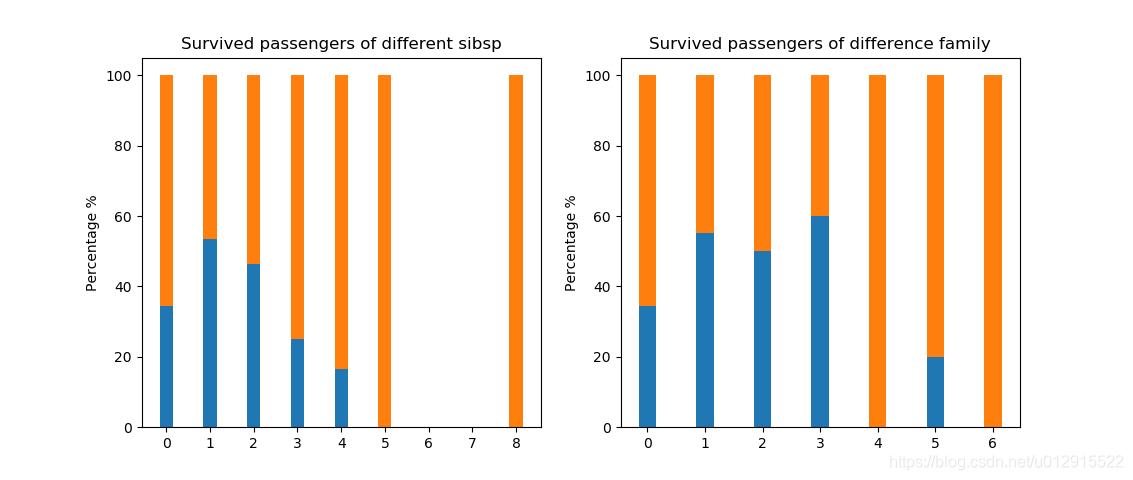
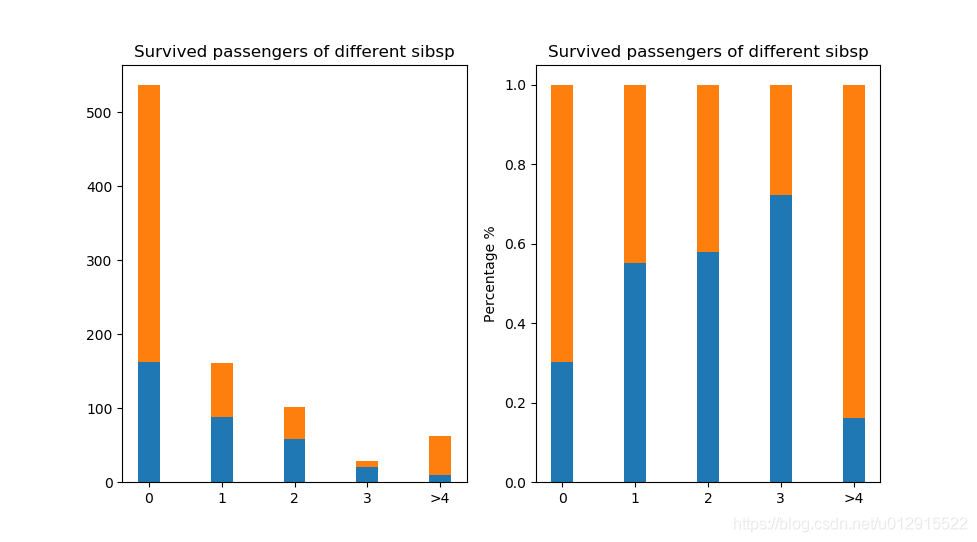
可以看到一些规律性的改变,在家庭成员小于3个的时候随着家庭成员的增多,存活率是递增的,这个符合常理,因为大家在灾难面前的互助,但是当家庭成员大于4的时候存活率反而大幅降低,这可能和家庭成员过多,挤占了逃生的机会,也能够得到合理的解释。我们看到家庭成员是1或者2的时候存活率其实差不多,所以可以将两者合二为一,进一步提炼有用的信息,降低冗余信息。
1.1.4 票价
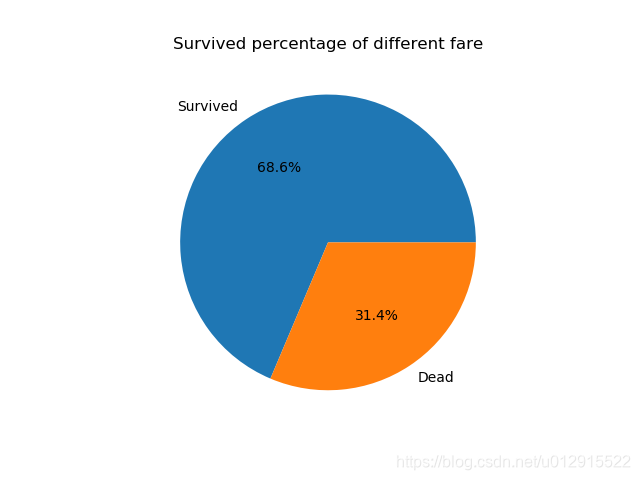
现在来看票价对存活率的影响。
survived_fare = df2[df2.Survived==1]['Fare'].mean()
dead_fare = df2[df2.Survived==0]['Fare'].mean()
fare = [survived_fare, dead_fare]
labels = ['Survived', 'Dead']
plt.pie(fare, labels=labels, autopct='%3.1f%%')
plt.title('Survived percentage of different fare')
plt.show()
结果饼图所示,明显的是有钱人更容易获救(典型的拿钱就换命)。
1.1.5 舱号
现在来看看舱号对于存活率的影响。可以发现船舱号有很多都是NaN,就是等级缺失的,统计一下到底有多少是缺失的
print(df2[df2.Cabin.isna()])
结果如下
PassengerId Survived Pclass Sex Age SibSp Parch Fare Cabin Embarked
0 1 0 3 male 22.0 1 0 7.2500 NaN S
2 3 1 3 female 26.0 0 0 7.9250 NaN S
4 5 0 3 male 35.0 0 0 8.0500 NaN S
5 6 0 3 male NaN 0 0 8.4583 NaN Q
7 8 0 3 male 2.0 3 1 21.0750 NaN S
.. ... ... ... ... ... ... ... ... ... ...
884 885 0 3 male 25.0 0 0 7.0500 NaN S
885 886 0 3 female 39.0 0 5 29.1250 NaN Q
886 887 0 2 male 27.0 0 0 13.0000 NaN S
888 889 0 3 female NaN 1 2 23.4500 NaN S
890 891 0 3 male 32.0 0 0 7.7500 NaN Q
[687 rows x 10 columns]
也就是说总共有687行的缺失,占总共891行的大多数,所以显然在这个缺失值处理不能通过填充来解决,我们转换一下思路,看能否以有无舱号登记作为影响存活率的因素呢?那么来看一下的数据分析
surivived_cabin = []
dead_cabin = []
survived_cain.append(df2[~df2.Cabin.isna()]['Survived'].sum())
dead_cabin.append(df2[~df2.Cabin.isna()].shape[0]-survived_cabin[0])
survived_cabin.append(df2[df2.Cabin.isna()]['Survived'].sum())
dead_cabin.append(df2[df2.Cabin.isna()].shape[0]-survived_cabin[1])
survived_cabin = np.array(survived_cabin)
dead_cabin = np.array(dead_cabin)
cabin = survived_cabin + dead_cabin
survived_cabin1 = survived_cabin/cabin*100
dead_cabin1 = dead_cabin/cabin*100
ind6 = np.arange(len(survived_cabin))
ax_cabin = plt.subplot(1,2,1)
ax_cabin.bar(ind6,survived_cabin, 0.3)
ax_cabin.bar(ind6, dead_cabin, 0.3, bottom=survived_cabin)
plt.xticks(ind6, ('YES','No'))
plt.title('Survived passenger of different Cabin')
ax_cabin = plt.subplot(1,2,2)
ax_cabin.bar(ind6,survived_cabin1, 0.3)
ax_cabin.bar(ind6, dead_cabin1, 0.3, bottom=survived_cabin1)
plt.xticks(ind6, ('YES','No'))
plt.title('Survived passenger of different Cabin')
plt.ylabel('Percentage %')
结果如下图,可以看到登记的存活率明显高于没有登记的。
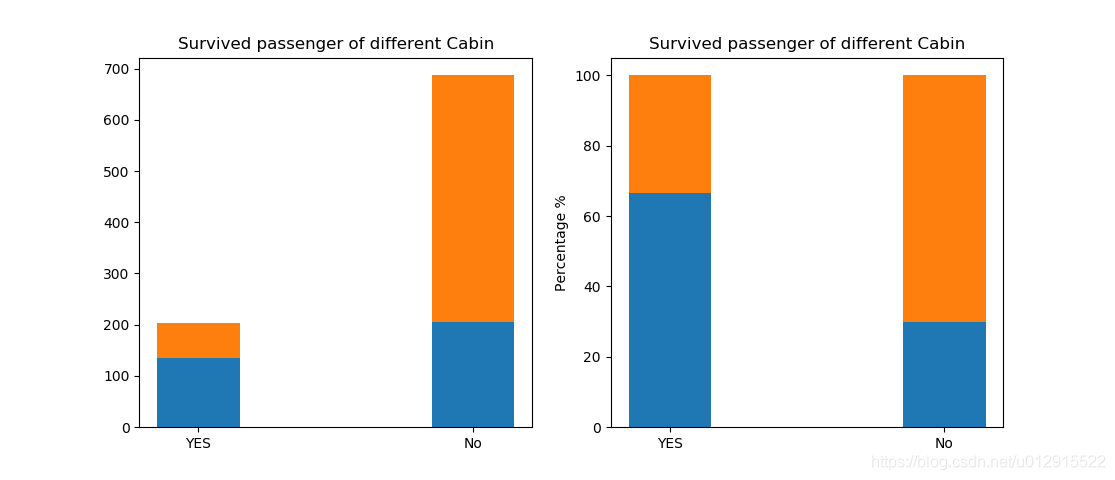
1.1.6 登船地
现在来看看登船地对于存活率的影响。上船地有两处缺失值
print(df[df.Embarked.isna()])
结果如下
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
61 62 1 1 Icard, Miss. Amelie female 38.0 0 0 113572 80.0 B28 NaN
829 830 1 1 Stone, Mrs. George Nelson (Martha Evelyn) female 62.0 0 0 113572 80.0 B28 NaN
有两个单身女性的上船地是缺失了,观察发现,两者的票价都是80.0,舱号都是B28,在看两者的票号都是113572,合理推测两者都是同一上船地。采用众数进行填充。
survived_embarked = []
dead_embarked = []
survived_embarked.append(df2[df2.Embarked=='S']['Survived'].sum())
survived_embarked.append(df2[df2.Embarked=='C']['Survived'].sum())
survived_embarked.append(df2[df2.Embarked=='Q']['Survived'].sum())
dead_embarked.append(df2[df2.Embarked=='S']['Survived'].shape[0]-survived_embarked[0])
dead_embarked.append(df2[df2.Embarked=='C']['Survived'].shape[0]-survived_embarked[1])
dead_embarked.append(df2[df2.Embarked=='Q']['Survived'].shape[0]-survived_embarked[2])
ind5 = np.arange(len(survived_embarked))
ax_embarked = plt.subplot(1,2,1)
ax_embarked.bar(ind5, survived_embarked, 0.3)
ax_embarked.bar(ind5, dead_embarked, 0.3, bottom=survived_embarked)
plt.xticks(ind5, ('S','C' , 'Q'))
plt.title('Survived passenger of different embarked')
ax_embarked = plt.subplot(1,2,2)
ax_embarked.bar(ind5, survived_embarked1, 0.3)
ax_embarked.bar(ind5, dead_embarked1, 0.3, bottom=survived_embarked1)
plt.xticks(ind5, ('S','C' , 'Q'))
plt.title('Survived passenger of different embarked')
plt.ylabel('Percentage %')
结果见下图,可以看到存活率最高的是C地登船的,超过50%,第二是Q地上船的,大约40%,最低的是S地上船的,大约只有35%。
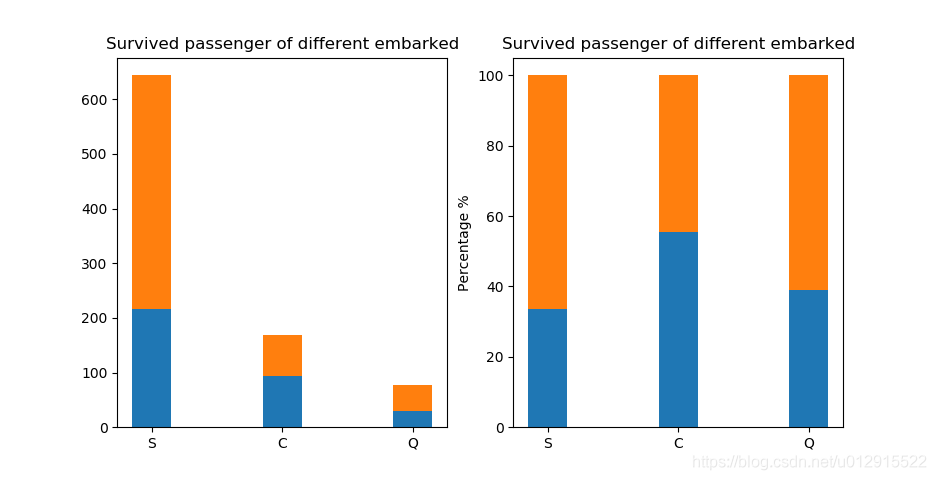
1.2 特征工程
通过上述分析,暂选定[‘Pclass’, ‘Sex’, ‘Age’, ‘SibSp’+‘Parch’, ‘Fare’, ‘Cabin’, ‘Embarked’]七项作为特征项。下面进行数据预处理。
1.2.1 缺失值补充
由于‘Age’等数据列存在缺失值,所有需要对其进行处理,在‘Age’中采用平均数补充,在Embarked中采用众数补充
df2.loc[df2.Age.isna(), 'Age'] = df.Age.mean()
df2.loc[df2.Embarked.isna(), 'Embarked'] = 'S'
1.2.2 数据标准化
年龄和票价是跨度比较大的值,为了能获得更好的结果,需要对其进行标准化,采用sklearn库中的前处理包preprocessing中的MinMaxScaler进行最大最小值方法标准化。
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler()
age = np.array(df2.Age).reshape(df2.shape[0], 1)
age_std = sc.fit_transform(age)
fare = np.array(df2.Fare).reshape(df2.shape[0], 1)
fare_std = sc.fit_transform(fare)
1.2.3 One-Hot编码
对于离散数据需要用One-Hot编码转换成特征向量。
dummies_cabin = pd.get_dummies(df2['Cabin'], prefix='Cabin')
dummies_sex = pd.get_dummies(df2.Sex, prefix='Sex')
dummies_family = pd.get_dummies(family, prefix='Family')
dummies_embarked = pd.get_dummies(df2.Embarked, prefix='Embarked')
dummies_pclass = pd.get_dummies(df2.Pclass, prefix='Pclass')
1.3 特征向量
通过上述过程,提炼出特征向量可以供之后的模型训练、验证及预测。综上特征工程的代码如下
def featrue(df):
df2 = df.drop(['Name', 'Ticket'], axis=1)
df2.loc[~df2.Cabin.isna(), 'Cabin'] = 'YES'
df2.loc[df2.Cabin.isna(), 'Cabin'] = 'NO'
family = df2.SibSp + df2.Parch
family.loc[family>3] = 4
dummies_cabin = pd.get_dummies(df2['Cabin'], prefix='Cabin')
dummies_sex = pd.get_dummies(df2.Sex, prefix='Sex')
dummies_family = pd.get_dummies(family, prefix='Family')
dummies_embarked = pd.get_dummies(df2.Embarked, prefix='Embarked')
dummies_pclass = pd.get_dummies(df2.Pclass, prefix='Pclass')
df2.loc[df2.Age.isna(), 'Age'] = df2.Age.mean()
age = np.array(df2.Age).reshape(df2.Age.shape[0], 1)
df2.loc[df2.Fare.isna(), 'Fare'] = df2.Fare.mean()
fare = np.array(df2.Fare).reshape(df2.Fare.shape[0], 1)
sc = MinMaxScaler()
age_std = pd.DataFrame(sc.fit_transform(age), columns=['Age_std'], index=df.index.values)
fare_std = pd.DataFrame(sc.fit_transform(fare), columns=['Fare_std'], index=df.index.values)
df3 = pd.concat([df2, dummies_pclass, dummies_sex, dummies_family, dummies_cabin, dummies_embarked, age_std, fare_std],
axis=1)
df3 = df3.drop(['Pclass', 'Sex', 'SibSp', 'Parch', 'Cabin', 'Embarked', 'Age', 'Fare', 'Survived'], axis=1)
return df3
2. 训练模型
为了减少在训练集上模型的过拟合,提高模型的泛化能力,一般采用交叉验证,将训练集分割成训练集和验证集。
2.1 划分训练集和验证集
sklearn库中model_selection中有划分工具
from sklearn.model_selection import train_test_split
train1, test1, train_label1, test_label1 = train_test_split(df, df.Survived, test_size=0.4, random_state=20)
train_featrue = featrue(train1)
test_featrue = featrue(test1)
2.2 多种机器学习方法结果
这里用到LogisticRegression、KNeighborsClassifier、SVC三种方法,代码如下
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
lg_clf = LogisticRegression(C=1)
lg_clf.fit(train_featrue, train_label1)
lg_score1 = lg_clf.score(train_featrue, train_label1)
lg_score2 = lg_clf.score(test_featrue, test_label1)
print('='*40)
print('Method: LogisticRegression')
print('score on train set:', lg_score1)
print('score on test set:', lg_score2)
knn_clf = KNeighborsClassifier(n_neighbors=5)
knn_clf.fit(train_featrue, train_label1)
knn_score1 = knn_clf.score(train_featrue, train_label1)
knn_score2 = knn_clf.score(test_featrue, test_label1)
print('='*40)
print('Method: KNeighborsClassifier')
print('score on train set:', knn_score1)
print('score on test set:', knn_score2)
svm_clf = SVC(C=0.1, kernel='rbf', gamma='scale')
svm_clf.fit(train_featrue, train_label1)
svm_score1 = svm_clf.score(train_featrue, train_label1)
svm_score2 = svm_clf.score(test_featrue, test_label1)
print('='*40)
print('Method: Support Vector Machine')
print('Score on Train Set:', svm_score1)
print('Score on Test Set:', svm_score2)
结果如下:
========================================
Method: LogisticRegression
score on train set: 0.8164794007490637
score on test set: 0.8207282913165266
========================================
Method: KNeighborsClassifier
score on train set: 0.846441947565543
score on test set: 0.7478991596638656
========================================
Method: Support Vector Machine
Score on Train Set: 0.8389513108614233
Score on Test Set: 0.7899159663865546
可以看到逻辑回归基本上在训练集和验证集差不多的准确率,但是K近邻法和支持向量机的过拟合程度较高。
调整参数,在逻辑回归中减小罚因子,提高泛化能力;
在支持向量机中减小参数C,以降低过拟合程度。
========================================
Method: LogisticRegression
score on train set: 0.8164794007490637
score on test set: 0.8235294117647058
========================================
Method: KNeighborsClassifier
score on train set: 0.846441947565543
score on test set: 0.7478991596638656
========================================
Method: Support Vector Machine
Score on Train Set: 0.8071161048689138
Score on Test Set: 0.8123249299719888
3.预测
predict_df = pd.read_csv(r'h:\dataanalysis\titanic\test.csv')
predict_df.set_index(['PassengerId'], inplace=True)
predict_featrue = featrue(predict_df)
#print(predict_featrue)
lg_clf_predict = lg_clf.predict(predict_featrue)
knn_clf_predict = knn_clf.predict(predict_featrue)
svm_clf_predict = svm_clf.predict(predict_featrue)
lg_clf_predict = pd.DataFrame(lg_clf_predict, columns=['Survived'], index=predict_df.index)
knn_clf_predict = pd.DataFrame(knn_clf_predict, columns=['Survived'], index=predict_df.index)
svm_clf_predict = pd.DataFrame(svm_clf_predict, columns=['Survived'], index=predict_df.index)
#print(lg_clf_predict)
lg_clf_predict.to_csv(r'h:\dataanalysis\titanic\submission1.csv')
knn_clf_predict.to_csv(r'h:\dataanalysis\titanic\submission2.csv')
svm_clf_predict.to_csv(r'h:\dataanalysis\titanic\submission3.csv')
上传到kaggle上,最后最好的结果是支持向量机的结果,如下