本来今天打算把以前的爬虫记录复制粘贴过来的,后来想想有点没意思,就想再写一次爬虫,顺便加上之前学的可视化数据分析。
有点糊涂,不知道该从哪里说起,也不知道该怎么讲。所以还是按照我自己的爬虫步骤讲吧
这里建议用jupyter notebook编辑,方便数据的展示
总的步骤就是:①导入模块 ②配置绘图风格 ③反爬 ④开始写爬虫代码 ⑤整合 ⑥绘图
大概就是以上这些步骤。
①导入包。今天想通过爬取数据绘制的图像有:条形图、饼图、地理热力图
#导入要用到的模块
'''
遇到python不懂的问题,可以加Python学习交流群:1004391443一起学习交流,群文件还有零基础入门的学习资料
'''
import requests #网络请求
import re
import pandas as pd #数据框操作
import numpy as np
import matplotlib.pyplot as plt #绘图
import matplotlib as mpl #配置字体
from pyecharts import Geo #地理图
import time #增加延时
import random这里可能会出现的问题:这些模块都要自己下载的哦,具体方法可以自己去网上找,其实挺简单。大部分都是pip install就就解决的事情。
还有一些可能要自己到文件下载网站下载,还会让你选相应的匹配文件,这里的匹配是python版本匹配、位数匹配,如果不知道的话就打开CMD命令窗口进入python,输入以下:
import pip print(pip.pep425tags.get_supported())
我的话就出现了:

所以我选的应该是箭头所指的格式的文件。
②设置绘图格式和绘图风格
mpl.rcParams['font.sans-serif'] = ['SimHei'] #这个是绘图格式,不写这个的话横坐标无法变成我们要的内容
#配置绘图风格
plt.rcParams['axes.labelsize'] = 8.
plt.rcParams['xtick.labelsize'] = 12.
plt.rcParams['ytick.labelsize'] = 12.
plt.rcParams['legend.fontsize'] =10.
plt.rcParams['figure.figsize'] = [8.,8.]上面的意思通过英文很容易理解,
③反爬虫
反爬措施可以通过firefox里的请求头里的信息实现,直接把请求头里的信息复制过来就好,用其他浏览器的也行,把cookies注释掉,因为不要登录信息。
我用的是火狐。首先按F12,在网络里找到列表里的postion开头的内容,然后找到请求头(其他浏览器可能是Rrequest什么的)
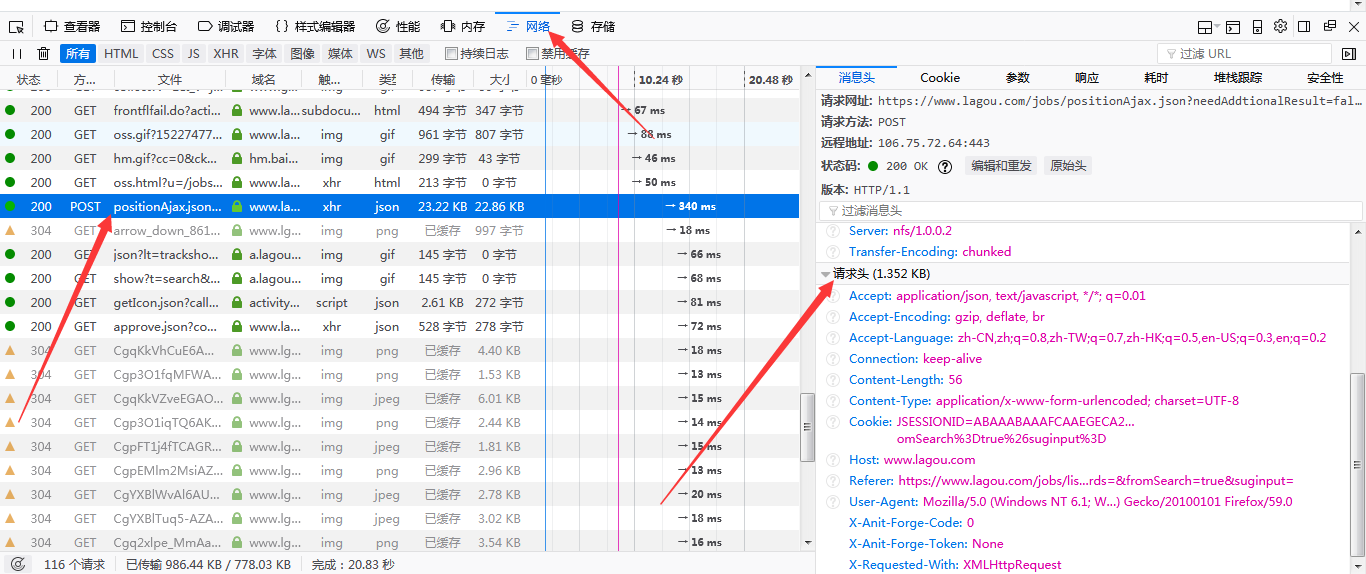
将请求头里的内容全部复制下来,需要注意的是,通过火狐浏览器复制的请求头会出现”...“,当我们复制过来发现有省略号时,把那个有省略号的地方打全。只需双击目标内容,请求头那里就会出现完整的句子,我把cookie注释掉了,因为不需要。代码如下
header = {'Accept':'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Content-Length':'56',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
#Cookie:LGUID=20161214153335-9f0eacc2-c1cf-11e6-bd6c-5254005c3644; user_trace_token=20180122030442-efefe00e-fedd-11e7-b2cb-525400f775ce; LG_LOGIN_USER_ID=e619b07cb5d026e017473de3d4ef1bb5a3da9a0ddd6ea0a5; gray=resume; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%227288096%22%2C%22%24device_id%22%3A%221626117eb3016-0703ff024b7ae5-71292b6e-1049088-1626117eb3569%22%2C%22first_id%22%3A%221626117eb3016-0703ff024b7ae5-71292b6e-1049088-1626117eb3569%22%7D; WEBTJ-ID=20180403125347-16289da9860300-0dcabf1bb6b166-71292b6e-1049088-16289da98619b; login=true; unick=%E6%8B%89%E5%8B%BE%E7%94%A8%E6%88%B73739; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=0; gate_login_token=63a7401b950e42d41a03d8ce1db134ac22aeefc46c120c43; index_location_city=%E6%B7%B1%E5%9C%B3; JSESSIONID=ABAAABAAADEAAFIDFE252684FD90098F44851E32F917A9F; TG-TRACK-CODE=search_code; SEARCH_ID=e267bafce9b0431d8f8a867e48f2a7bf; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1522167431,1522215930,1522219100,1522731245; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1522741185; _gat=1; _ga=GA1.2.983742987.1481700649; _gid=GA1.2.1178844706.1522731227; LGSID=20180403154252-9d580c63-3712-11e8-b228-525400f775ce; PRE_UTM=; PRE_HOST=; PRE_SITE=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Fjobs%2Flist_%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%3Fcity%3D%25E6%25B7%25B1%25E5%259C%25B3%26cl%3Dfalse%26fromSearch%3Dtrue%26labelWords%3D%26suginput%3D; LGRID=20180403154252-9d580e4e-3712-11e8-b228-525400f775ce; _putrc=2C1A435C1A81EDB8
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?city=%E6%B7%B1%E5%9C%B3&cl=false&fromSearch=true&labelWords=&suginput=',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.3964.2 Safari/537.36',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'}④开始写爬虫代码
首先,还是得先分析下网页信息
我们翻到第一页,其网页代码是:https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=
第二页,其网页代码是: https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=
可以发现,不同页数的网址并没有区别,所以可以判断这是一个动态网页,真正的网址其实在消息头(Headers)。用F12打开Network一栏

然后随便点开一页,比如说第四页,可以看到内容栏的第一个以position开头的东西,自己点击查看下,之后再一层一层打开,在result下面有很多我们想要的信息。
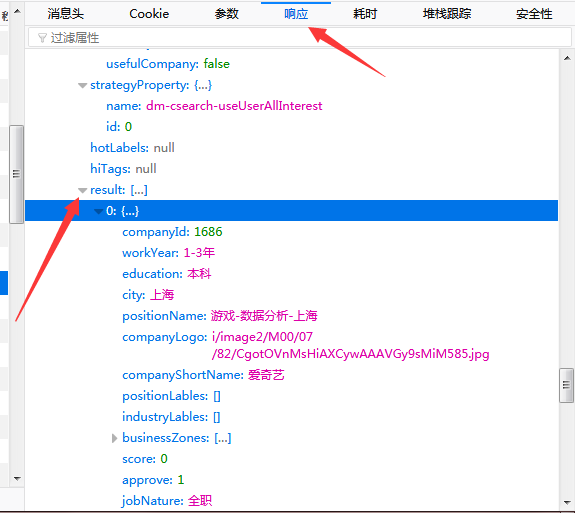
然后可以点开到参数那里,最后一栏有“表单数据”,kd是我们搜索的关键词,pn是页数。first那里我也不知道是什么,不用管它。

把这个复制下到txt里,因为等等我们还有一些东西需要复制。
但我们现在可以开始写一些代码来测试下了。
dat = {'first':'false',
'kd':'数据分析',
'pn':'3'} #这是我们刚刚复制的内容
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' #真实网址
html = requests.request('POST',url,data=dat,headers=header)
#进行请求接着来测试下我们有没有翻车!
html.status_code #返回200说明没翻车,对比404,返回的是404代表翻车了,200是服务器返回的正常消息
我的结果截图是:说明没问题,但不一定出现200就一定没问题。

再测试我们爬的内容↓
html.text #如果出现”操作频繁“就是是被反爬了,所以一定要实施反爬措施,其实反爬措施有好几种,浏览器代理、IP地址代理都可以
我出现的结果:说明爬取成功
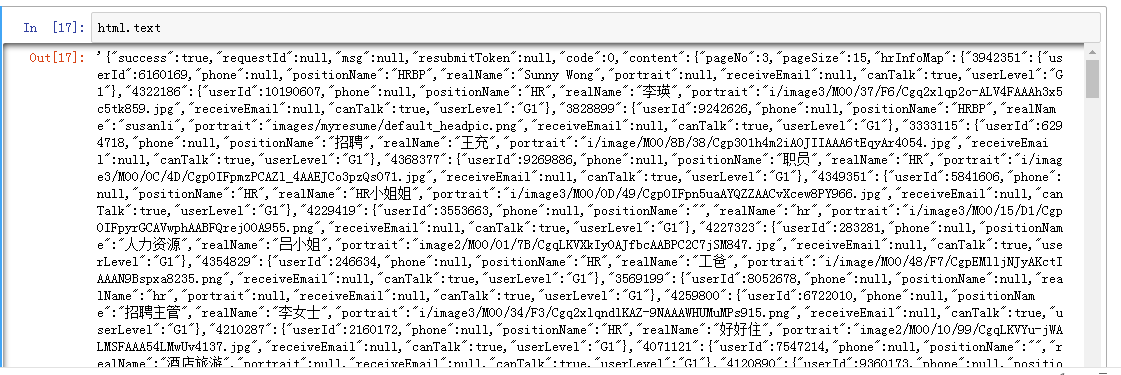
接着,要思考下,我们需要爬什么内容,我想爬工作经验、地区、福利、待遇、企业名称等内容
在jupyter notebook里,Ctrl+F,输入companyid,然后选取你可能需要的字段
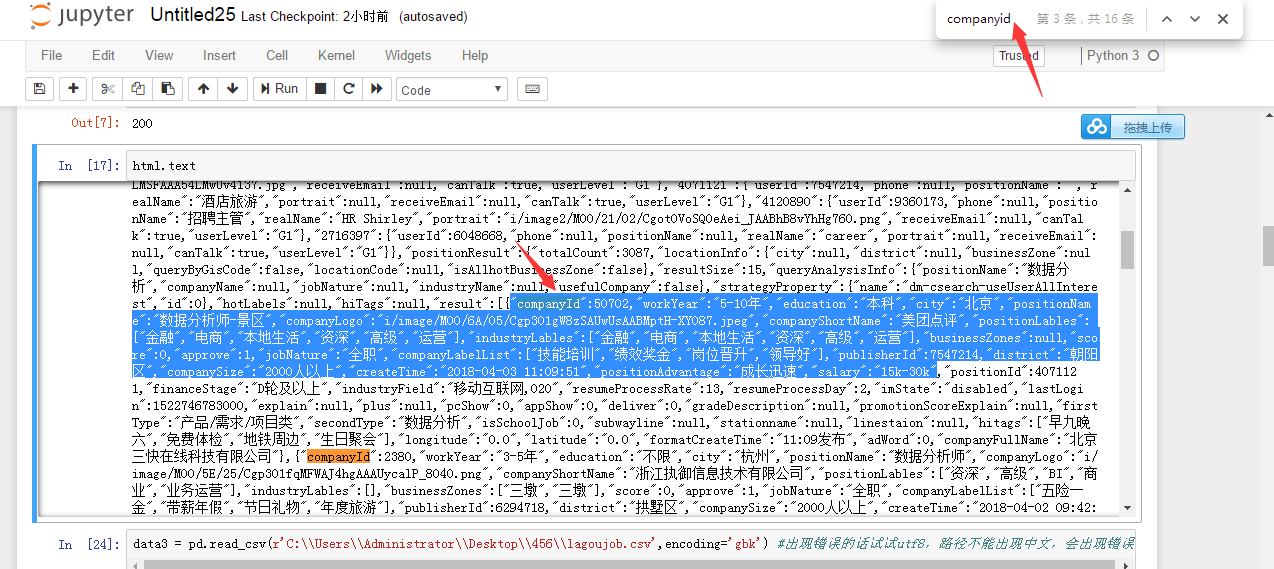
复制以后,粘贴到文本上,然后对自己需要的内容进行模糊匹配,就是把其变成(.*?),不需要的内容直接写成.*?,就是不用加括号。对这方面不熟的话,就去看看正则表达式
我是这么写的:

然后写代码进行正则提取:
#用正则表达式来提取数据
#在jupyterF5找出你想要的信息,然后复制你想要的信息,像我的话直接复制到薪水就可以了
data = re.findall('"companyId":.*?,"workYear":"(.*?)","education":"(.*?)","city":"(.*?)","positionName":"(.*?)","companyLogo":".*?","companyShortName":"(.*?)","positionLables":.*?,"industryLables":.*?,"businessZones":.*?,"score":.*?,"approve":.*?,"jobNature":".*?","companyLabelList":(.*?),"publisherId":.*?,"district":"(.*?)","companySize":".*?","createTime":".*?","positionAdvantage":".*?","salary":"(.*?)"',html.text)⑤整合
到了这里我们可以把我们写的、测试的东西整合到一起了,
我们爬取的内容一共有30页,翻页用for循环来实现。for i in range的时候要慢慢爬,不能一下子就爬到很后面,这样也会被发现的。 可以这样理解:你翻页翻太快很明显就不是人为的,所以很容易被反爬。所以这时候我们要import time,就是增加延时。time.sleep(2),停两秒在翻页。
但是每次都是停两秒才翻页的话,就太准确啦,也容易被反爬。所以再加载一个随机模块,来随机选取秒数,我将秒数设置为2到10秒。最后整合如下:
#数据分析岗位有30页,用for循环实现翻页
'''
遇到python不懂的问题,可以加Python学习交流群:1004391443一起学习交流,群文件还有零基础入门的学习资料
'''
for i in range(1,31):
#写入真实网址,不是网页上的网址,是在消息头那,别的浏览器是Headers
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
#提交数据,在参数那一栏,把这个复制过来,然后加上引号和逗号
dat = {'first':'false',
'kd':'数据分析',
'pn':'3',}
time.sleep(random.randint(2,10))
html = requests.request('POST',url,data=dat,headers=header)
#用正则表达式来提取数据
#在jupyterF5找出你想要的信息,然后复制你想要的信息,像我的话直接复制到薪水就可以了
data = re.findall('"companyId":.*?,"workYear":"(.*?)","education":"(.*?)","city":"(.*?)","positionName":"(.*?)","companyLogo":".*?","companyShortName":"(.*?)","positionLables":.*?,"industryLables":.*?,"businessZones":.*?,"score":.*?,"approve":.*?,"jobNature":".*?","companyLabelList":(.*?),"publisherId":.*?,"district":"(.*?)","companySize":".*?","createTime":".*?","positionAdvantage":".*?","salary":"(.*?)"',html.text)
#转成数据框
data2 = pd.DataFrame(data)
#写入本地
#header、index是行名、列名的意思,让他们等于False的意思是,原来的行名和列名我们都不要,mode=a+就是要追加信息,
#就是你要继续加信息的时候,他会往下写。而不是把你之前的信息覆盖掉
#执行完毕后,可在刚刚的文件夹里发现csv文件
data2.to_csv('C:\\Users\\Administrator\\Desktop\\456\\lagoujob.csv',header=False,index=False,mode='a+')执行以上代码后可在文件夹里找到一个csv文件,要等一会的,不是马上就能爬好的。↓

工作经验学历什么的是我在这个文件里自己加上去的,你也可以自己在代码里写
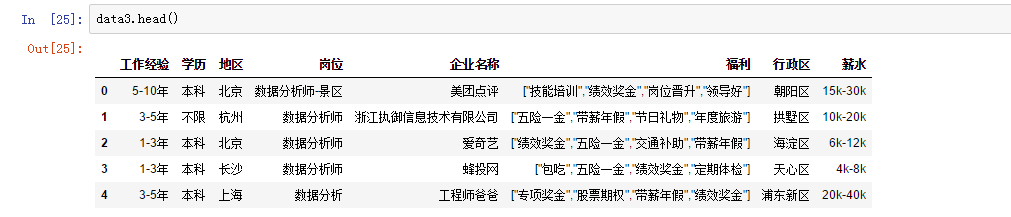
现在来读取下这个csv文件↓
data3 = pd.read_csv(r'C:\\Users\\Administrator\\Desktop\\456\\lagoujob.csv',encoding='gbk') #出现错误的话试试utf8,路径不能出现中文,会出现错误
读取前面的内容


⑥绘图
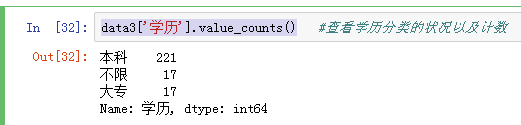
查看学下历分类的状况以及计数
根据学历状况绘制柱形图↓
data3['学历'].value_counts().plot(kind='bar') #绘制条形图 plt.show #显示图片
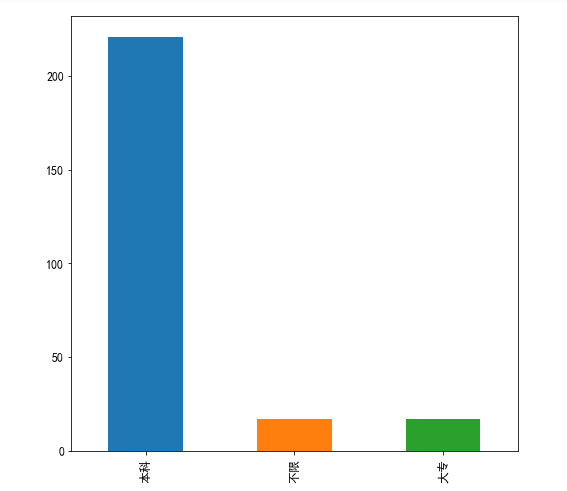
根据学历状况绘制条形图↓
data3['学历'].value_counts().plot(kind='barh') #绘制倒置的条形图 plt.show #显示图片
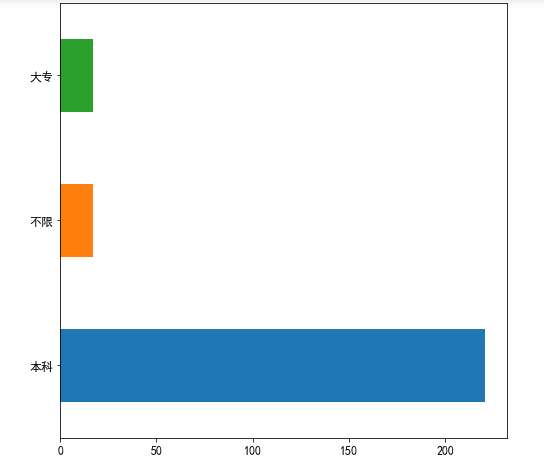
根据”工作经验“绘制条形图↓
data3['工作经验'].value_counts().plot(kind='barh') #绘制条形图 plt.show #显示图片
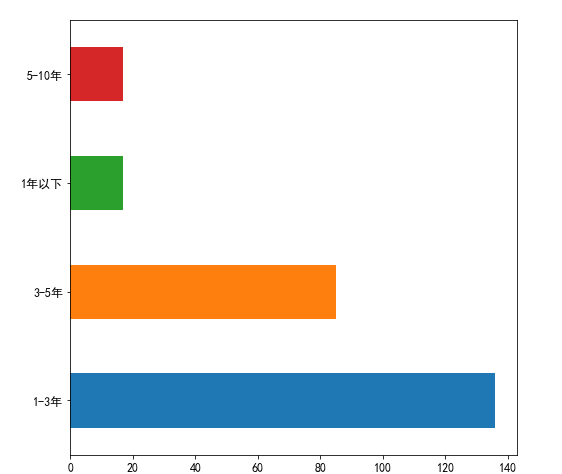
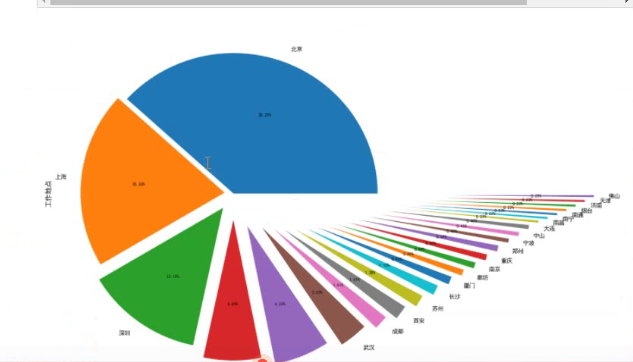
根据地区绘制饼图↓
#绘制饼图 data3['地区'].value_counts().plot(kind='pie',autopct='%1.2f%%') plt.show #显示图片
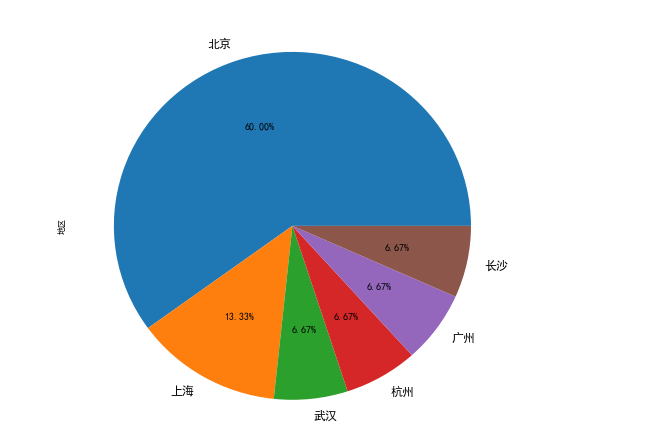
看到网上有的人可以把饼图化成这样: