来源:https://www.johnwittenauer.net/machine-learning-exercises-in-python-part-2/
在第1部分我就在Python学习机系列中,我们介绍的锻炼1的安德鲁·Ng的第一部分机器学习班。在这篇文章中,我们将通过完成练习的第2部分来完成练习1。如果您还记得,在第1部分中,我们实施了线性回归,以根据卡车所在城市的人口来预测新食品卡车的利润。对于第2部分,我们有一项新任务 - 预测价格房子会卖。这次的差异是我们有多个因变量。我们给出了平方英尺的房子大小和房子里的卧室数量。我们可以轻松扩展我们以前的代码来处理多元线性回归吗?我们来看看吧!
首先让我们来看看数据。
path = os.getcwd() + '\data\ex1data2.txt'
data2 = pd.read_csv(path, header=None, names=['Size', 'Bedrooms', 'Price'])
data2.head() | Size | Bedrooms | Price | |
|---|---|---|---|
| 0 | 2104 | 3 | 399900 |
| 1 | 1600 | 3 | 329900 |
| 2 | 2400 | 3 | 369000 |
| 3 | 1416 | 2 | 232000 |
| 4 | 3000 | 4 | 539900 |
请注意,每个变量的值的大小差异很大。房子通常有2-5间卧室,但可能有几百到几千平方英尺。如果我们按原样对这些数据运行我们的回归算法,那么“大小”变量的权重过大,最终会使“卧室数”功能的任何贡献相形见绌。要解决这个问题,我们需要做一些名为“功能规范化”的工作。也就是说,我们需要调整功能的比例以平衡比赛场地。一种方法是通过从特征中的每个值中减去该特征的平均值,然后除以标准偏差。幸运的是,这是使用pandas的一行代码。
data2 = (data2 - data2.mean()) / data2.std()
data2.head()
| Size | Bedrooms | Price | |
|---|---|---|---|
| 0 | 0.130010 | -0.223675 | 0.475747 |
| 1 | -0.504190 | -0.223675 | -0.084074 |
| 2 | 0.502476 | -0.223675 | 0.228626 |
| 3 | -0.735723 | -1.537767 | -0.867025 |
| 4 | 1.257476 | 1.090417 | 1.595389 |
接下来,我们需要修改第1部分中的线性回归实现,以处理1个以上的因变量。或者我们呢?让我们再看一下梯度下降函数的代码。
def gradientDescent(X, y, theta, alpha, iters):
temp = np.matrix(np.zeros(theta.shape))
parameters = int(theta.ravel().shape[1])
cost = np.zeros(iters)
for i in range(iters):
error = (X * theta.T) - y
for j in range(parameters):
term = np.multiply(error, X[:,j])
temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term))
theta = temp
cost[i] = computeCost(X, y, theta)
return theta, cost仔细查看计算误差项的代码行:error =(X * theta.T) - y。一开始可能并不明显,但我们正在使用所有矩阵运算!这是线性代数在工作中的力量。只要theta中的参数数量一致,无论X中有多少变量(列),此代码都能正常工作。类似地,只要y中的行数一致,它就会为X中的每一行计算误差项。最重要的是,这是一个非常有效的计算。这是一种将任何表达式同时应用于大量实例的强大方法。
由于我们的梯度下降和成本函数都使用矩阵运算,因此处理多元线性回归所需的代码实际上没有变化。我们来试试吧。我们首先需要执行一些初始化来创建适当的矩阵以传递给我们的函数。
# add ones column
data2.insert(0, 'Ones', 1)
# set X (training data) and y (target variable)
cols = data2.shape[1]
X2 = data2.iloc[:,0:cols-1]
y2 = data2.iloc[:,cols-1:cols]
# convert to matrices and initialize theta
X2 = np.matrix(X2.values)
y2 = np.matrix(y2.values)
theta2 = np.matrix(np.array([0,0,0])) 现在我们准备尝试一下。让我们看看发生了什么。
# perform linear regression on the data set
g2, cost2 = gradientDescent(X2, y2, theta2, alpha, iters)
# get the cost (error) of the model
computeCost(X2, y2, g2) 0.13070336960771897
看起来有前途 我们还可以绘制训练进度,以确认误差实际上随着梯度下降的每次迭代而减小。
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(np.arange(iters), cost2, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch') 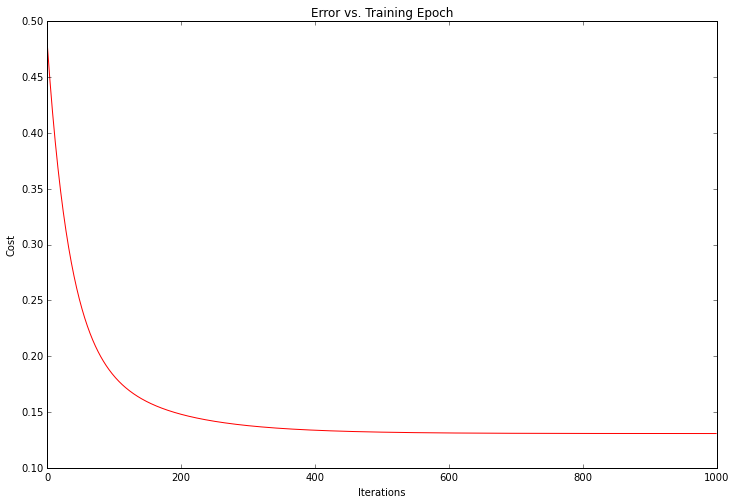
解决方案的成本或错误随着每次成功迭代而下降,直到最低点为止。这正是我们期望发生的事情。看起来我们的算法有效。
值得注意的是,我们无需从头开始实现任何算法来解决此问题。Python的优点在于其庞大的开发人员社区和丰富的开源软件。在机器学习领域,顶级Python库是scikit-learn。让我们看看如何使用scikit-learn的线性回归类从第1部分处理我们的简单线性回归任务。
from sklearn import linear_model
model = linear_model.LinearRegression()
model.fit(X, y) 它并没有那么容易。“fit”方法有很多参数我们可以调整,这取决于我们希望算法如何运行,但是默认值对我们的问题是合理的,我单独留下它们。让我们尝试绘制拟合参数,看看它与我们之前的结果相比如何。
x = np.array(X[:, 1].A1)
f = model.predict(X).flatten()
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size') 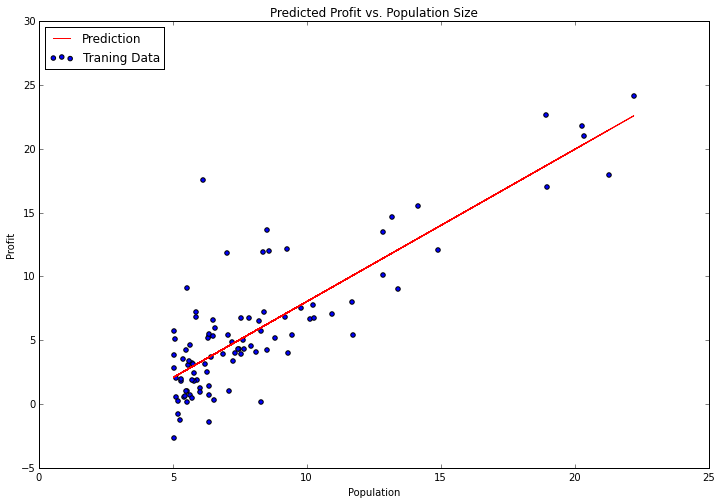
请注意,我正在使用“预测”功能来获取预测的y值以绘制线条。这比手动尝试要容易得多。Scikit-learn有一个很好的API,具有许多便利功能,适用于典型的机器学习工作流程。我们将在以后的帖子中更详细地探讨其中的一些内容。
今天就是这样。在第3部分中,我们将看一下练习2,并使用逻辑回归深入研究一些分类任务。