根据提供的“2023_MCM_Problem_Y_Boats.xlsx”文件,其中包括了大约3500艘不同长度、地区和制造年份的帆船的信息,分为单体帆船和双体帆船两个表格。
我们可以利用这些数据来开发一个数学模型,解释每个帆船的挂牌价格,并包括任何有用的预测因素。可以根据需要补充其他数据,但必须将这些数据包含在“2023_MCM_Problem_Y_Boats.xlsx”文件中,并完全标识和记录所使用的任何补充数据的来源。

为了开发一个解释挂牌价格的数学模型,我们需要考虑哪些因素会影响帆船的价格。
以下是一些可能有用的预测因素:
制造年份:帆船的制造年份可能对其价值产生影响,因为老旧的帆船通常会磨损更快,需要更多的维护。
长度:帆船的长度也可能是一个重要的预测因素。一般来说,长度越长的帆船往往会更昂贵。
地理区域:地理区域也可能影响帆船的价格,因为一些地区的帆船市场更加活跃,价格更高。
制造商和型号:帆船的制造商和型号也可能影响价格,因为某些品牌的帆船可能比其他品牌的帆船更受欢迎,从而价格更高。
船体材料:不同的船体材料可能会影响帆船的价格,因为一些材料可能更耐用或更昂贵。
引擎使用时间:引擎使用时间也可能影响帆船的价格,因为更少使用的引擎可能会更值钱。
电子设备:电子设备也可能是一个有用的预测因素,因为某些设备可能会增加帆船的价值。
其他因素:其他因素如舱室数量、通风、水处理和电源系统等也可能对帆船的价格产生影响。
我们可以利用这些预测因素来开发一个多元线性回归模型,来解释每个帆船的挂牌价格。对于缺失的数据,我们可以使用插值法来进行填补。
最终的模型将能够提供每个帆船挂牌价格的预测值,预测值的精度可能受到模型拟合的准确性和数据质量的影响。

基于以上因素,我们可以建立一个多元线性回归模型来解释航海艇价格。该模型可能采用以下形式:
Price = β0 + β1Length + β2Material + β3Displacement + β4Tonnage + β5Propulsion + β6Structure + β7Equipment + β8Region + β9Year + β10Market Conditions + ε
其中,Price是因变量,表示船只价格;Length、Material、Displacement、Tonnage、Propulsion、Structure和Equipment是自变量,表示船只的特征;Region是虚拟变量,表示船只所在地理位置;Year表示船只的制造年份;Market Conditions表示市场条件,可以是一个指标变量;β0、β1、β2、β3、β4、β5、β6、β7、β8、β9和β10是回归系数;ε是误差项。
我们可以使用线性回归模型来建立预测列表价格的数学模型。线性回归模型假设预测变量与响应变量之间存在线性关系,我们可以通过对现有数据进行拟合,得到预测变量的回归系数,并使用这些系数来预测帆船的上市价格。线性回归模型的公式为:
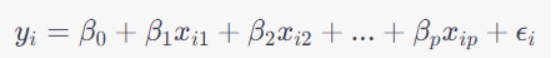
其中,$y_i$ 表示第 $i$ 个样本的响应变量(即列表价格),$x_{ij}$ 表示第 $i$ 个样本的第 $j$ 个预测变量(例如长度、地理区域等),$\beta_j$ 表示第 $j$ 个预测变量的回归系数,$\epsilon_i$ 表示误差项。我们可以使用现有数据中的长度、地理位置和年份等信息作为预测变量,使用列表价格作为响应变量,拟合出每个预测变量的回归系数,并将它们代入上述公式中,得到预测的列表价格。
多项式回归是一种线性回归的扩展,其假设自变量 $X$ 和响应变量 $Y$ 之间的关系可以用一个 $n$ 次多项式来描述。多项式回归模型的一般形式为:
其中,$\beta_0, \beta_1, \beta_2, ..., \beta_n$ 是回归系数,$\epsilon$ 是误差项。
# 导入相关库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 读取数据
df = pd.read_excel('2023_MCM_Problem_Y_Boats.xlsx', sheet_name='Monohull')
# 数据清洗
df.dropna(inplace=True)
df = df[df['Listing Price']>0]
# 特征提取
X = df[['Length (ft)', 'Year', 'Country/Region/State']]
X = pd.get_dummies(X)
y = df['Listing Price']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练
model = LinearRegression()
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = model.score(X_test, y_test)
# 输出模型评估结果
print('MSE:', mse)
print('RMSE:', rmse)
print('R2 score:', r2)具体来说,针对模型优化上,我们还有一些进一步的方案:
考虑更多的特征:除了题目给出的列之外,可能有其他的特征也会影响帆船的价格,例如帆船的重量、船龄、机器小时数、内饰、材料等等。可以尝试添加这些特征,并且使用一些特征选择的方法来决定哪些特征是最相关的。
处理缺失值:数据集中可能存在缺失值,可以使用插值方法来填充缺失值。比如说,可以使用均值插值、中值插值、K近邻插值等等。
处理异常值:可能会存在一些异常值,可以使用一些异常值检测的方法,比如说箱线图检测、基于聚类的离群点检测等等,来识别和处理这些异常值。
处理非线性关系可能存在非线性的特征之间的关系,可以使用一些非线性建模的方法,例如多项式回归、支持向量机、神经网络等等,来捕捉这些非线性关系。
考虑地理位置:帆船的价格可能受到地理位置的影响,可以考虑使用地理信息系统(GIS)技术,将帆船的位置和周围环境的特征(例如人口密度、周围港口数量等)加入模型。
使用时间序列模型:可以考虑使用时间序列模型,对帆船价格随时间的变化进行建模,这可能涉及到时间趋势、季节性因素、节假日效应等等。