一、回归分析的介绍和分类
1 回归分析
研究X与Y之间相关性的分析
1.1 相关性
相关性≠因果性
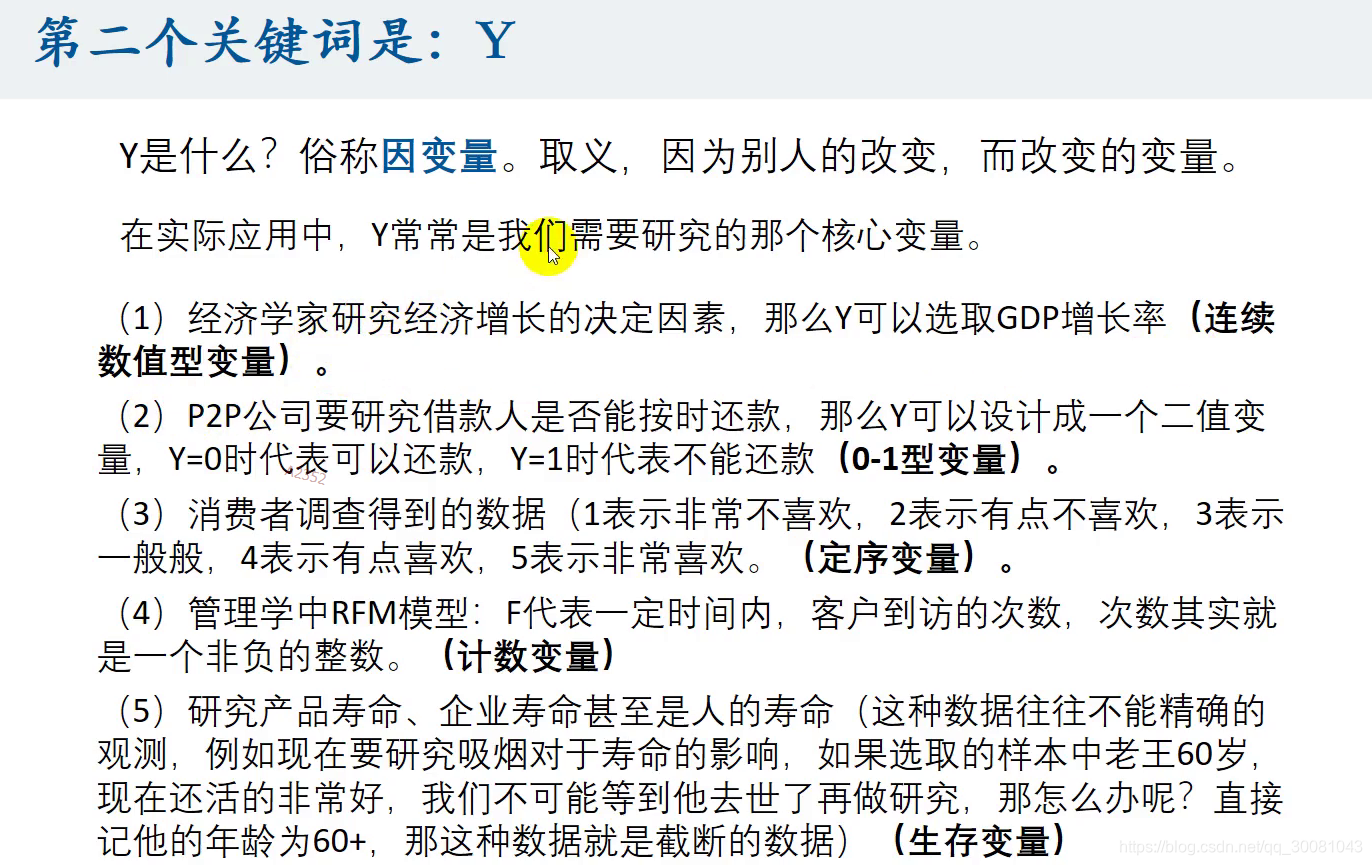
1.2 Y
因变量/核心变量
连续数值型变量
0-1型变量
定序变量
计数变量
生存变量
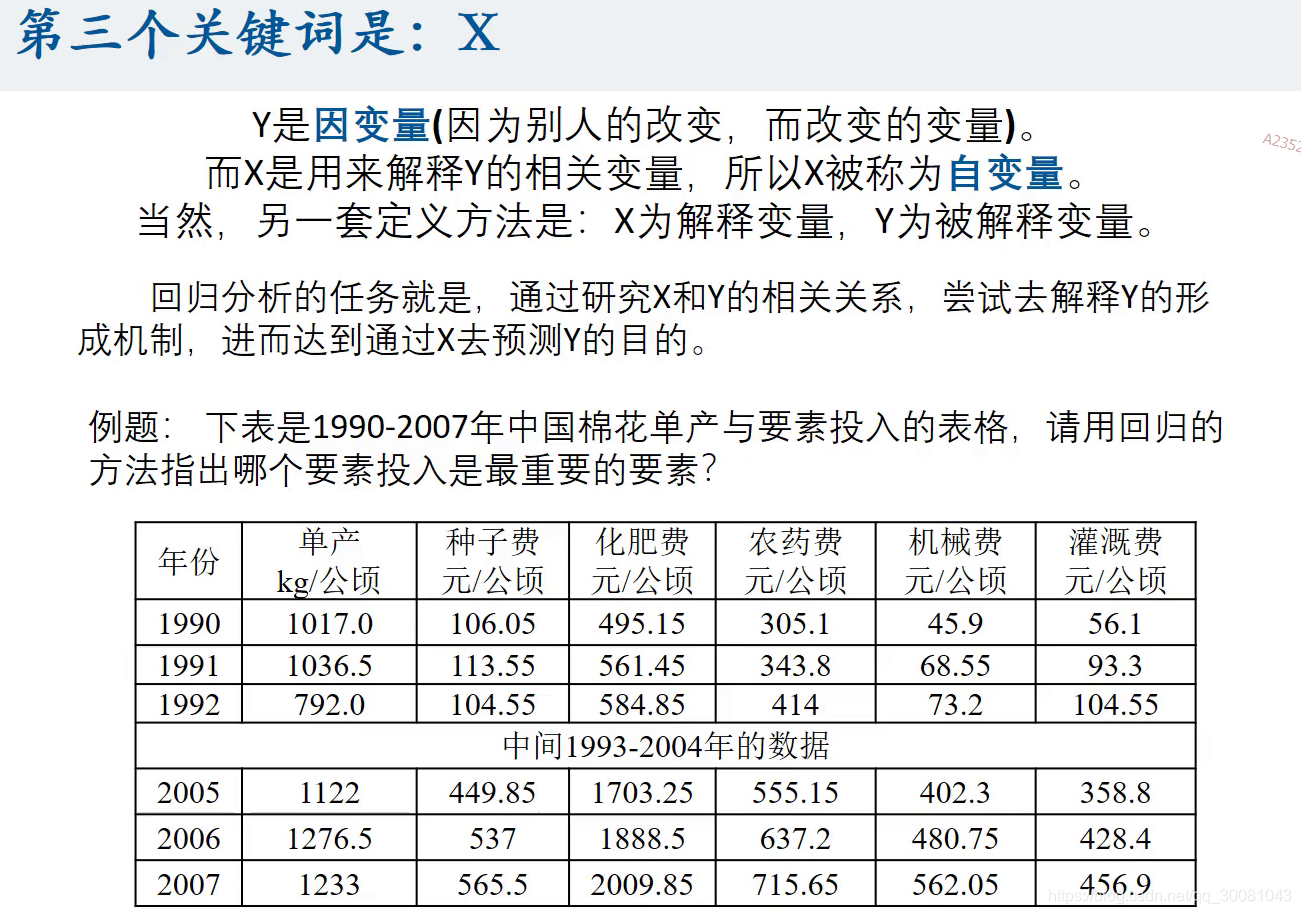
1.3 X
研究X与Y的相关关系,得到Y的形成机制,通过X去预测Y
2 回归分析的使命

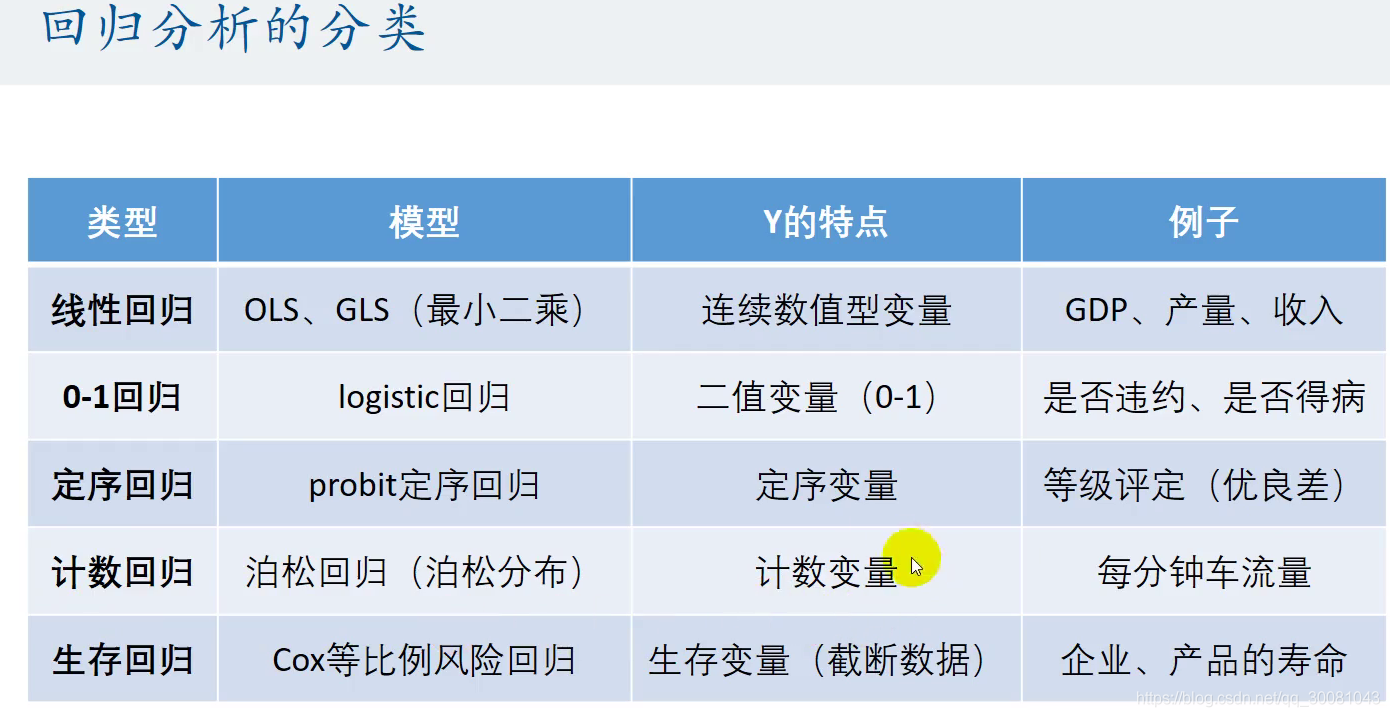
3 回归分析的分类
二、数据的分类以及数据的来源
1 数据的分类
1.1 横截面数据
在同一时间点收集的不同对象的数据

1.2 时间序列数据
对同一对象在不同时间连续观察得到的数据

1.3 面板数据
综合了横截面数据和时间序列数据

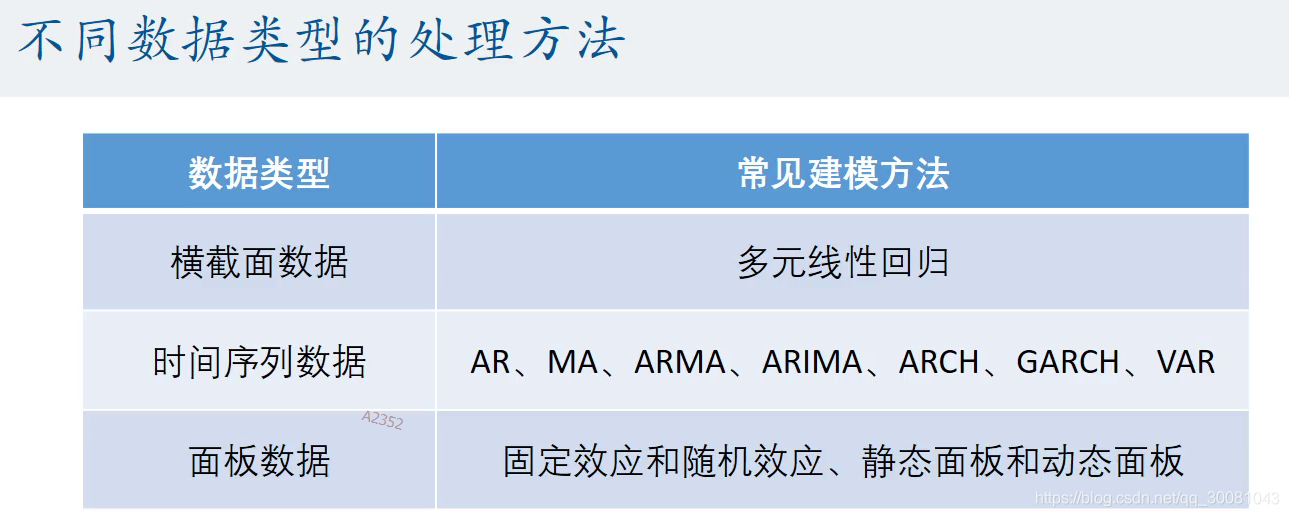
1.4 不同数据类型的处理方法
2 数据的收集(宏观数据)
详见pdf第14页
三、对于线性的理解以及内生性问题的探究
1 一元线性回归
本质上和拟合是一样的
残差

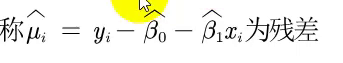
2 对于线性的理解

3 回归系数的解释
只需要分析回归系数的意义.即0.19和-1.74,无需分析没有意义的5.3
遗漏的变量,即价格!
所以加入了价格这个变量,就改变了产品品质评分的回归系数.

4 外生性的概念以及内生性的探究
误差项包含了什么? 它包含了价格


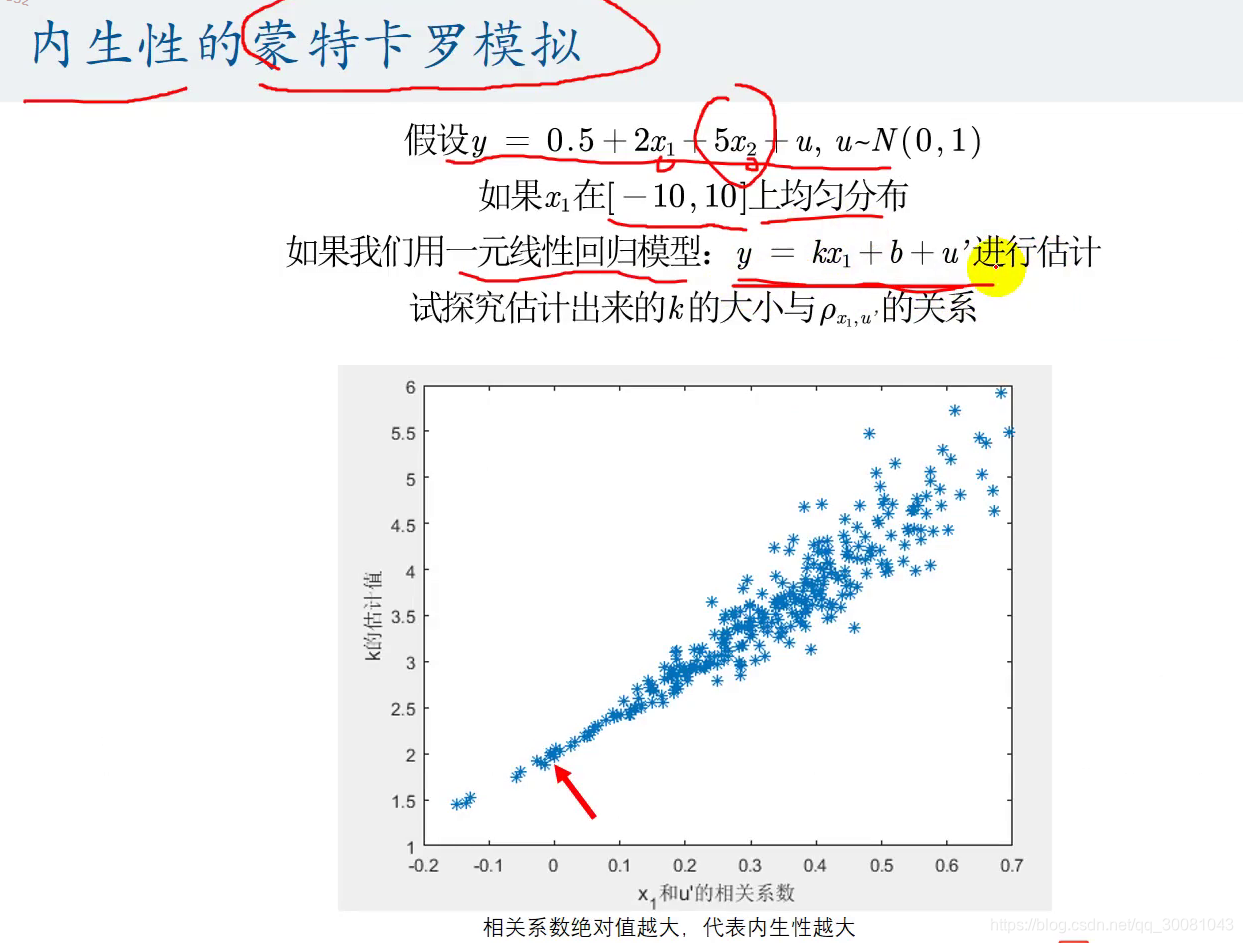
5 内生性的蒙特卡罗模拟(内生性的危害)
如果我们忽略了一个变量,就会出现这个问题.
相关系数越大,说明内生性越严重(误差项u和所有的自变量x的相关性)
6 核心解释变量和控制变量
保证核心解释变量和扰动项不相关.
控制变量:



四、四种模型的解释、虚拟变量的设置以及交互项的解释
1 回归系数的解释

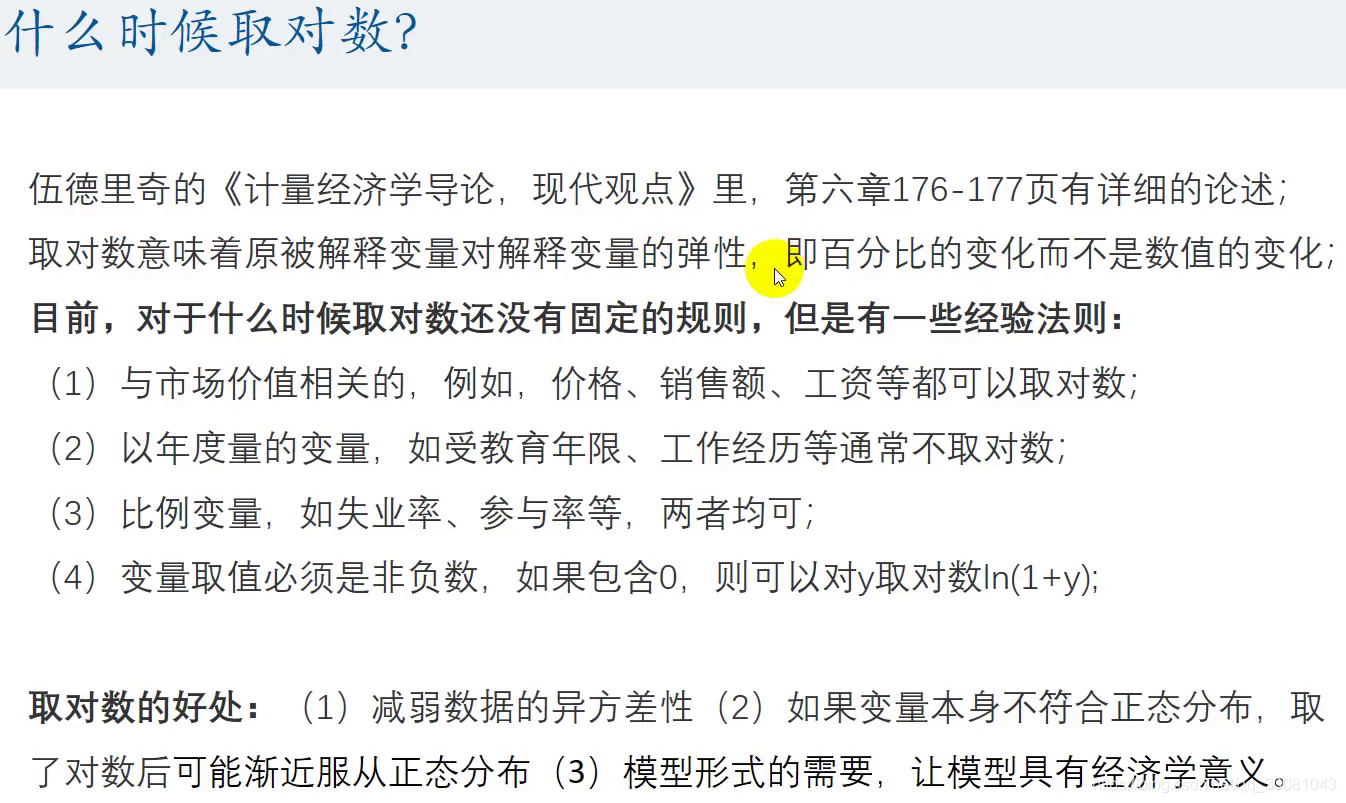
2 什么时候取对数
即百分比的变化而不是数值的变化.
3 四类模型回归系数的解释
3.1一元线性回归

3.2双对数模型

3.3半对数模型 y = a+b ln(x)

3.4半对数模型 ln(y) = a+bx

4.定性变量如何处理
引入虚拟变量
当famale = 1表示女性,famale = 0 表示男性
f
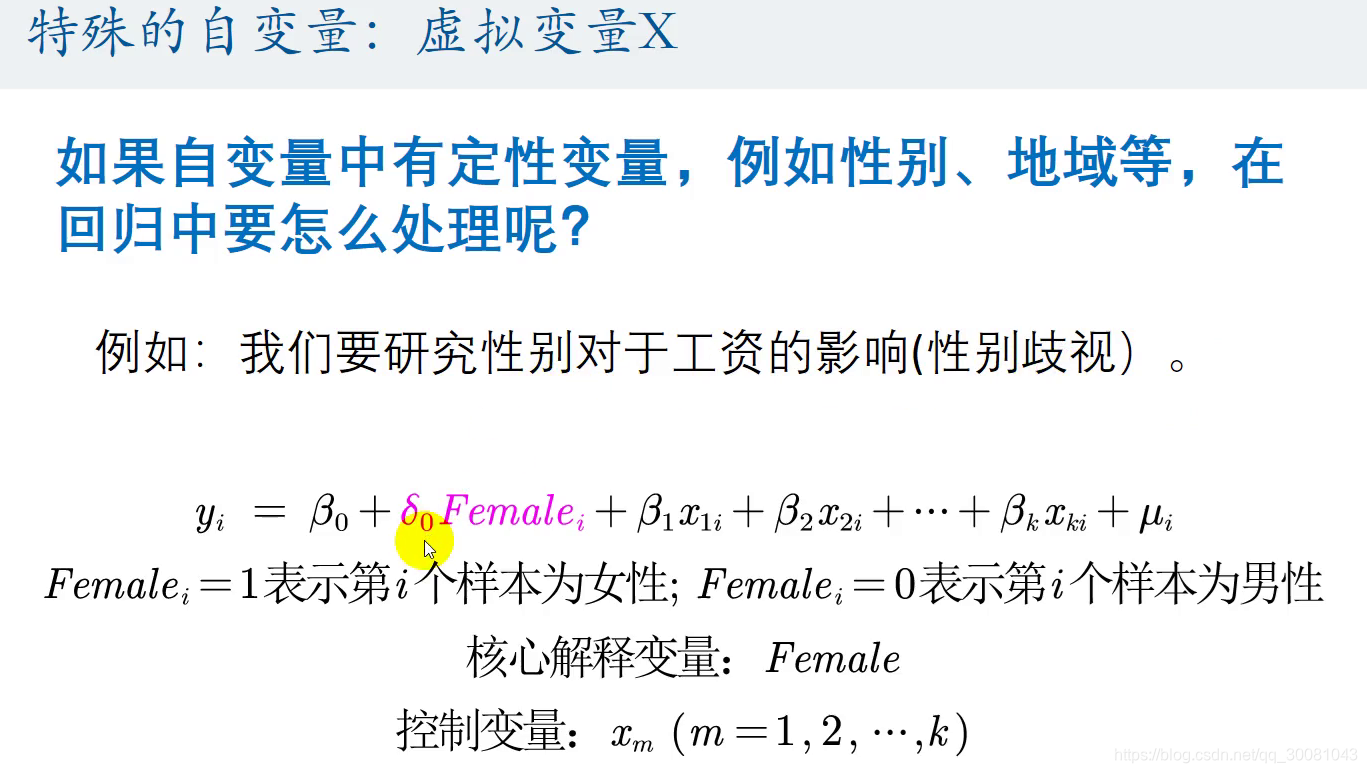

5.例:是否存在歧视
想要计算出回归系数,必须不存在完全多重共线性的影响,引入的东西多了就会存在这个问题.
就是为了防止这个问题.


6.含有交互项的自变量
偏导 bdrms
6.17的结果,说明了住房面积越大,价格上升越多.

交互效应
显著大于0就是正向的.
五、回归的应用_奶粉例题讲解(stata)
1.回归实例
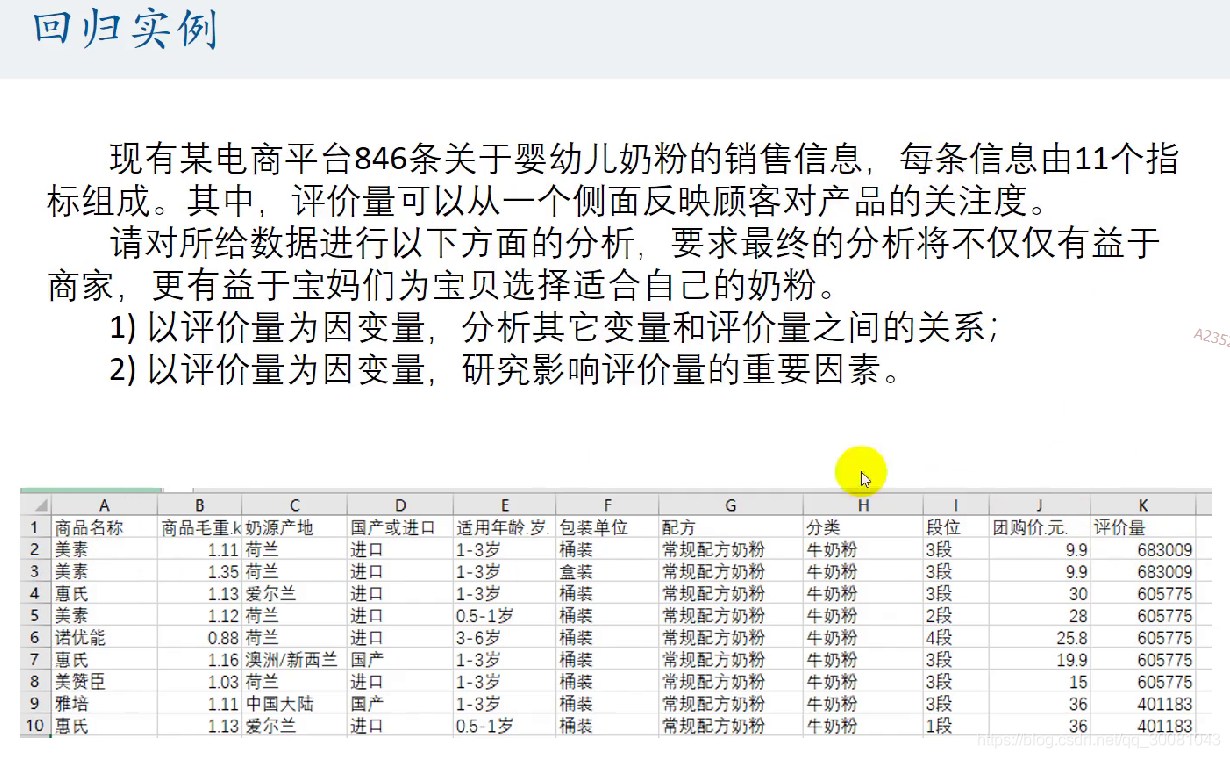
2.stata入门
2.1 导入excel数据
文件-导入-excel-勾选 将第一行作为变量名.
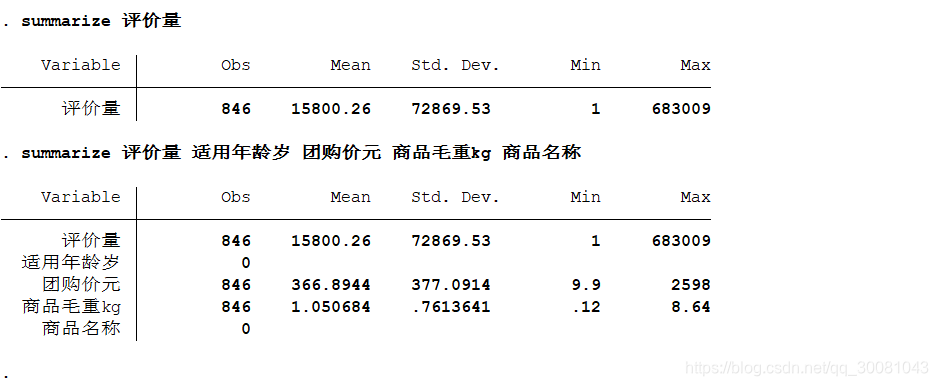
2.2 数据的描述性统计
2.2.1定量数据
summarize 变量1,变量2…
也可以简写为sum
得到数据之后,使用三线表,弄进论文.
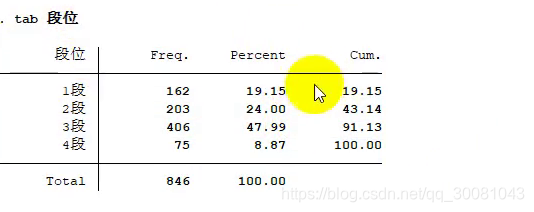
2.2.1定性数据
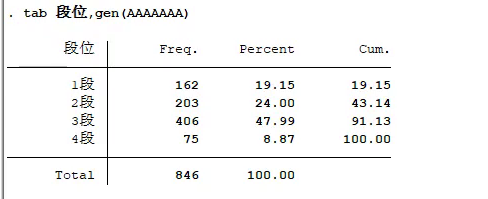
tabulate
频数,频率,累计频率

定型数据的虚拟变量
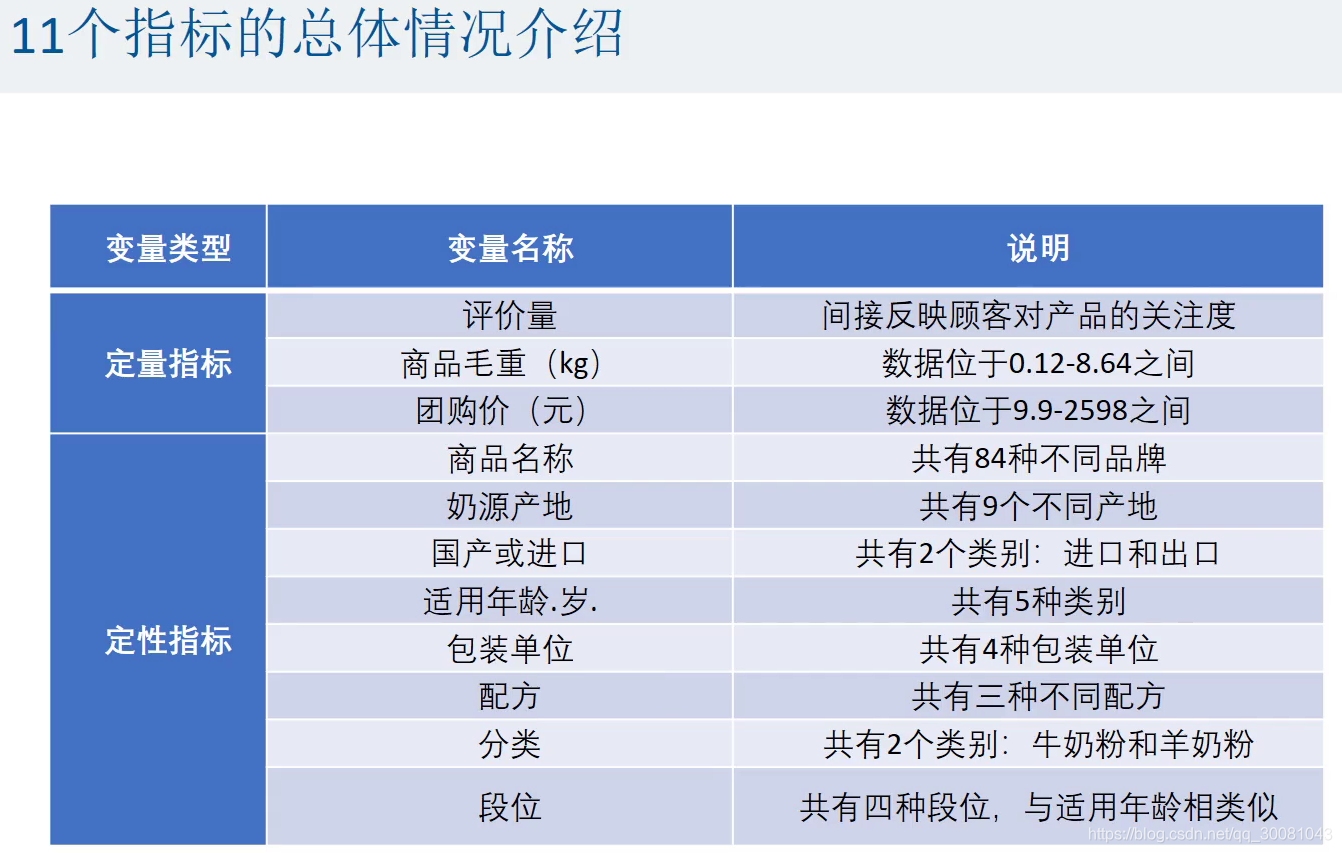
2.3 Excel中的数据透视表?论文中需要的图表
11个指标的总体情况介绍(论文)
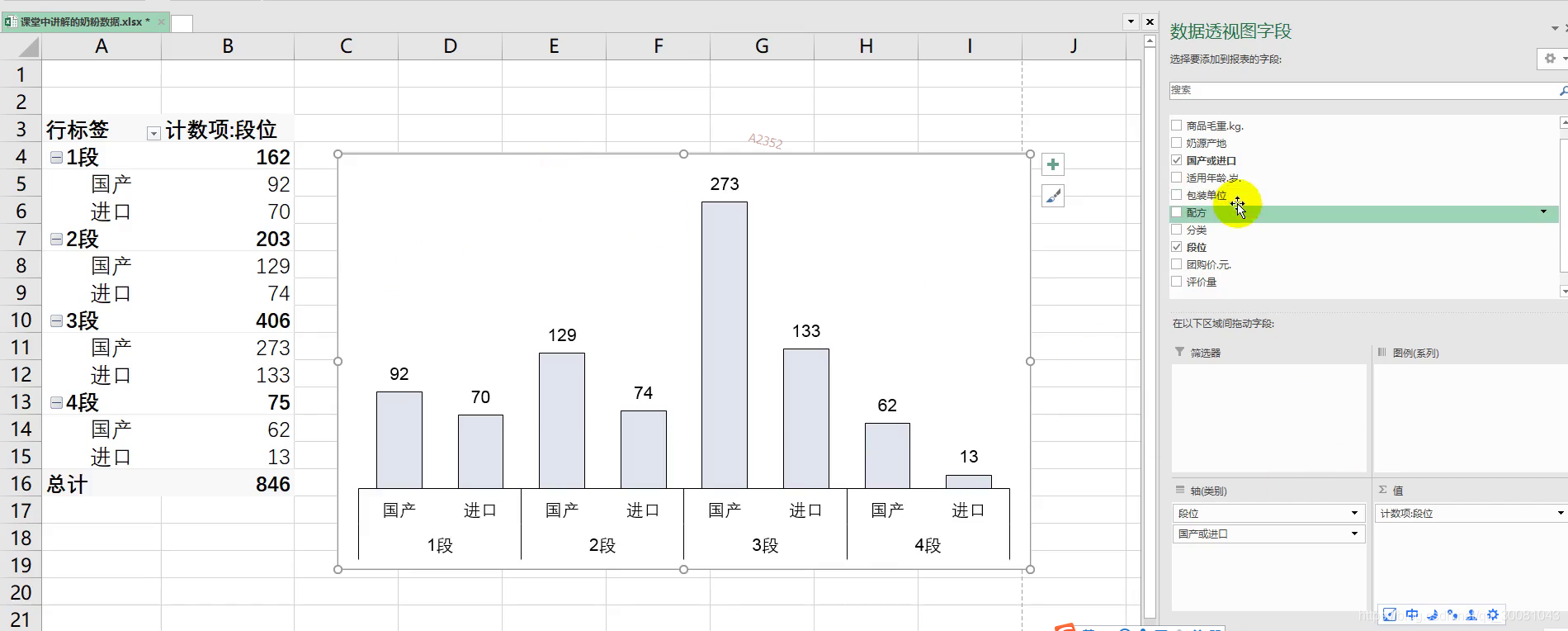
数据交互
3.Stata回归的语句
df自由度
residual 残差
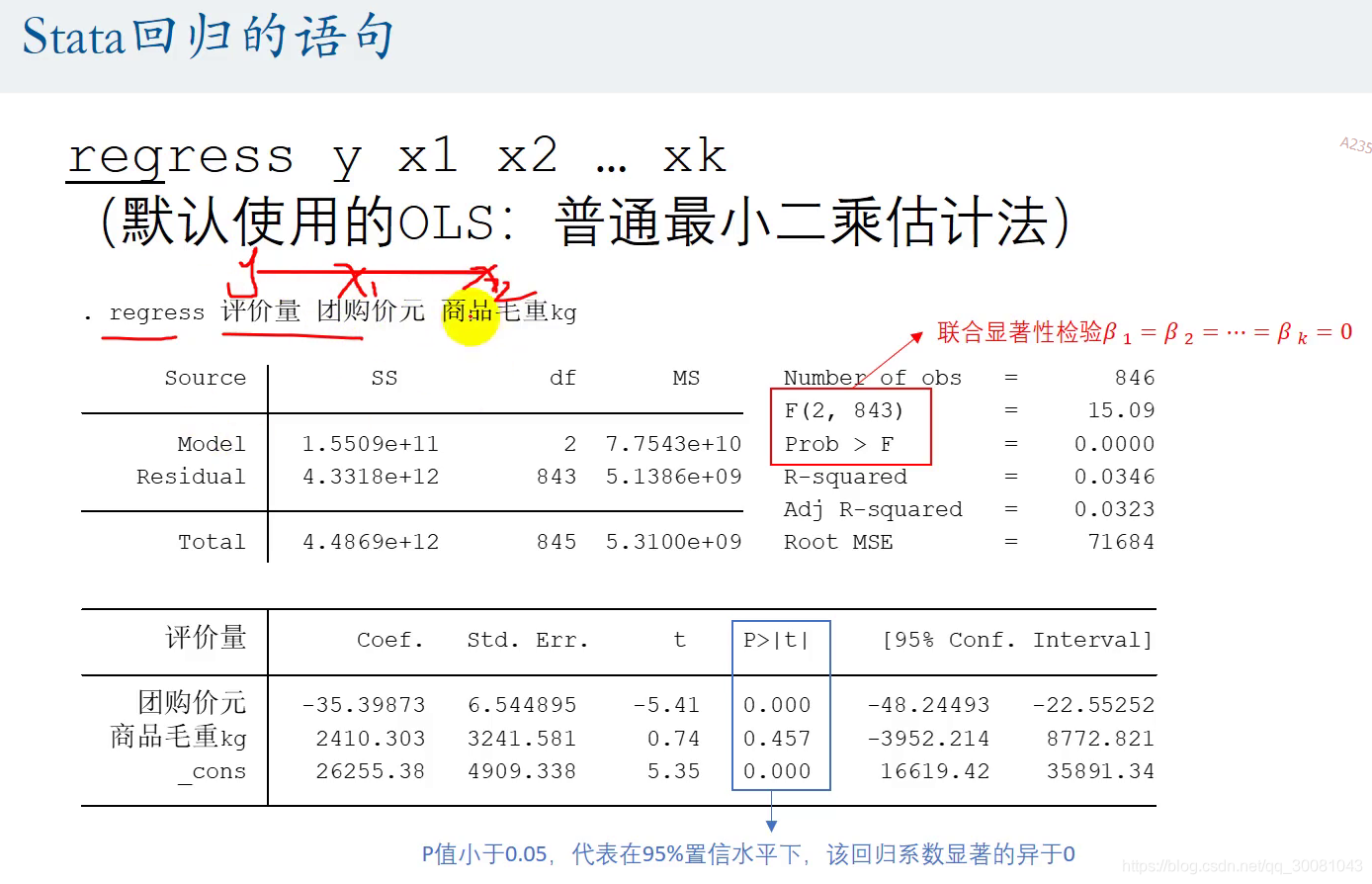
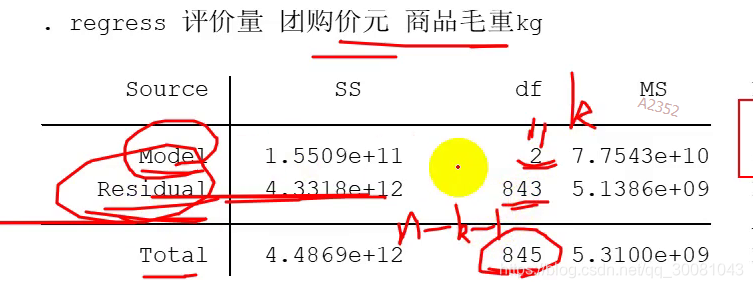
使用t检验统计量
coef. 回归系数
_cons :β0
团购价元:β1
商品毛重kg:β2
std.Err 标准误
t= 回归系数 / 标准误
原假设H0: B1= 0 ,检验它是不是等于0,p值=0 < 0.05> 拒绝原假设
商品毛重 p=0.475>0.05 ,无法拒绝原假设.
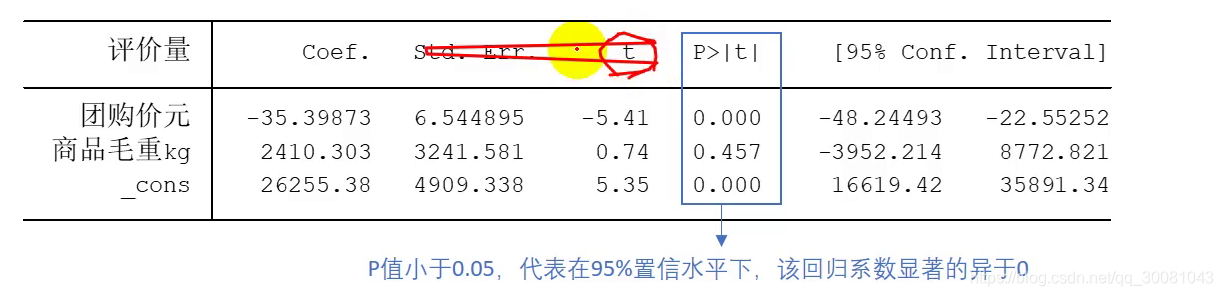
95%概率落入如下区间

解读

G1:段位为1
G4:段位为4,作为对照组
G1与G4进行比较,G1-G4
若R-squared 大于0.05,那么就没办法拒绝原假设,也是这个回归没有什么意义.
一般不用R方,而是使用adj R-squared ,放在论文中.
都是避免完全多重共线性.所以自动剔除一个,作为对照组.

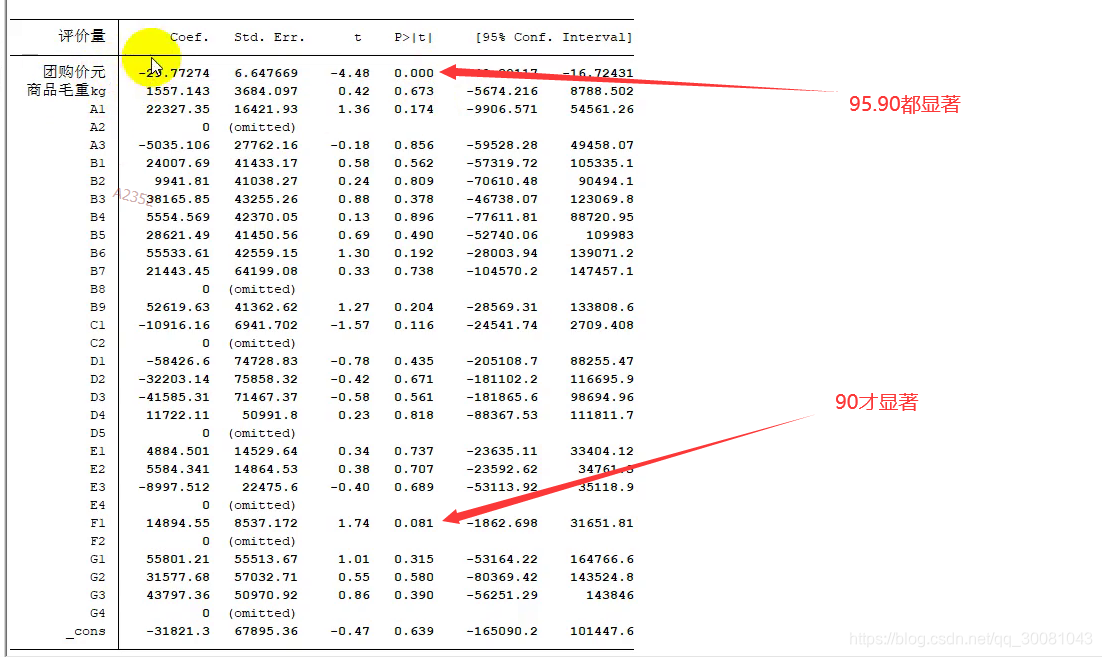
拟合度低怎么办?
回归分为解释性和预测性.,
他们的关注点不一样,解释性关注显著性如果不显著就没有意义。,预测性关注R方。
R方很小,说明模型设置有问题,
数据的问题.
拟合优度和调整后的拟合优度,论文中一般使用调整后的拟合优度.




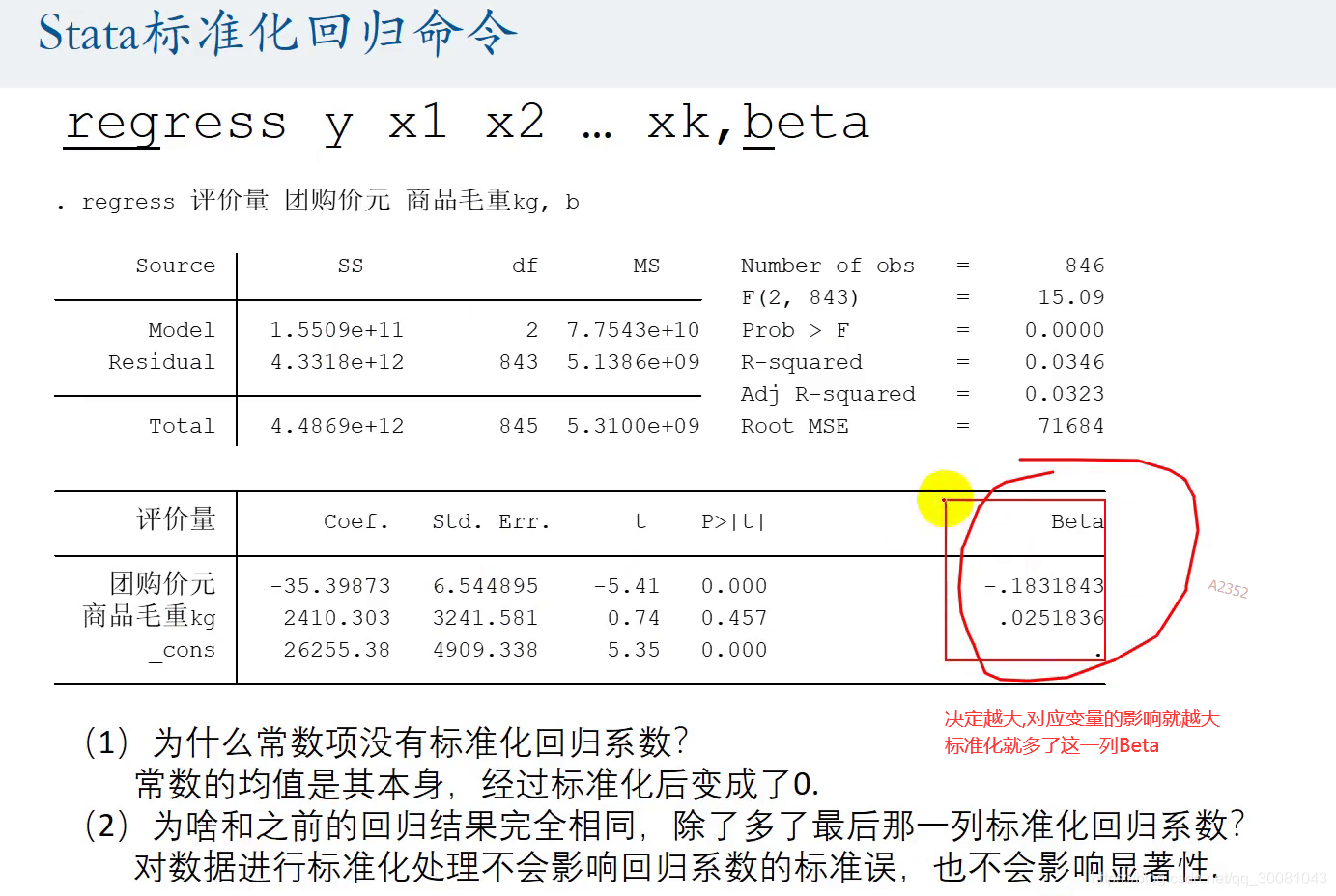
4. 标准化回归系数.
取出量纲的影响.
如何标准化?
比较的回归系数一定要是显著的回归系数,不然就没有多大的意义.
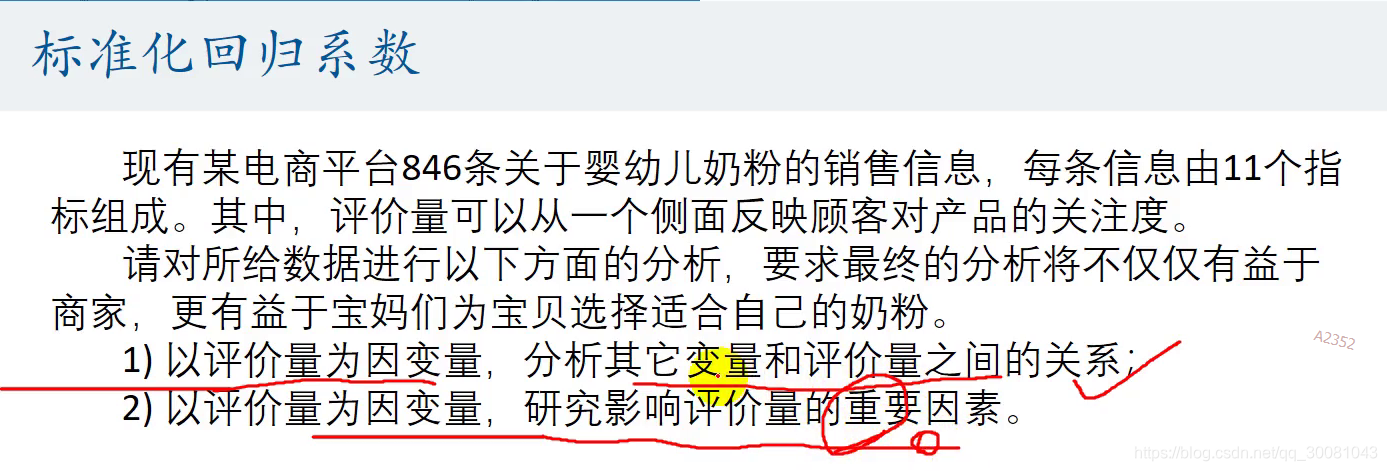


5.Stata标准化回归命令
决定越大--Beta绝对值越大
SSR—MODEL
SSE—RESIDUAL
SST—total
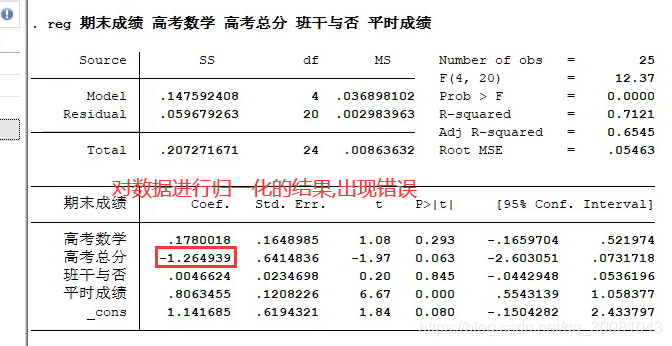
六、点评一篇很多错误的论文:期末数学成绩的影响因素探究
R方:拟合优度
不要轻易加入高次模型,不能仅考虑R方的大小.
而且这是解释性回归,应该更关注自变量统计的显著性
仅仅是为了解释,不需要复杂的模型.

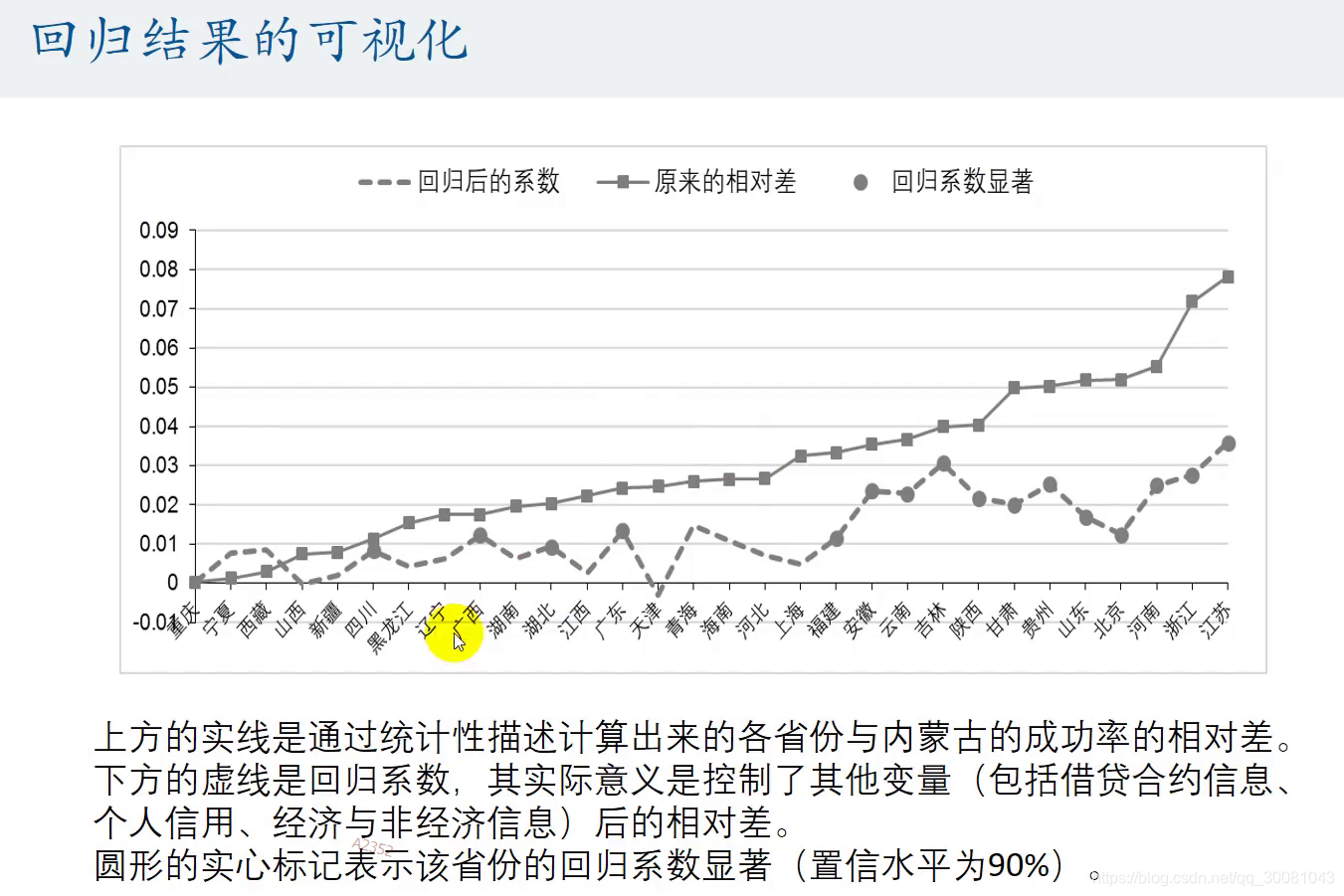
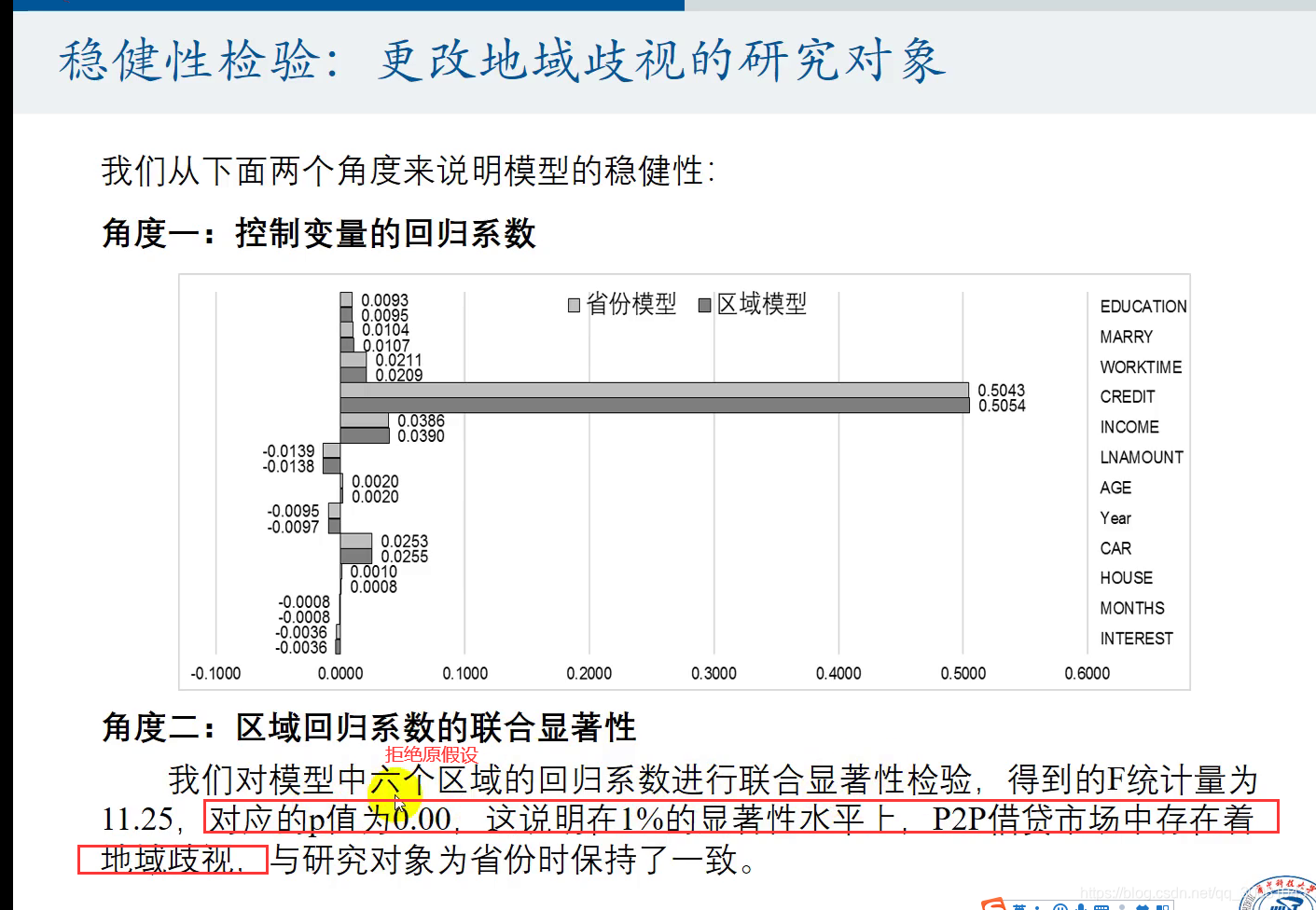
七、多元回归在我毕业论文中的运用
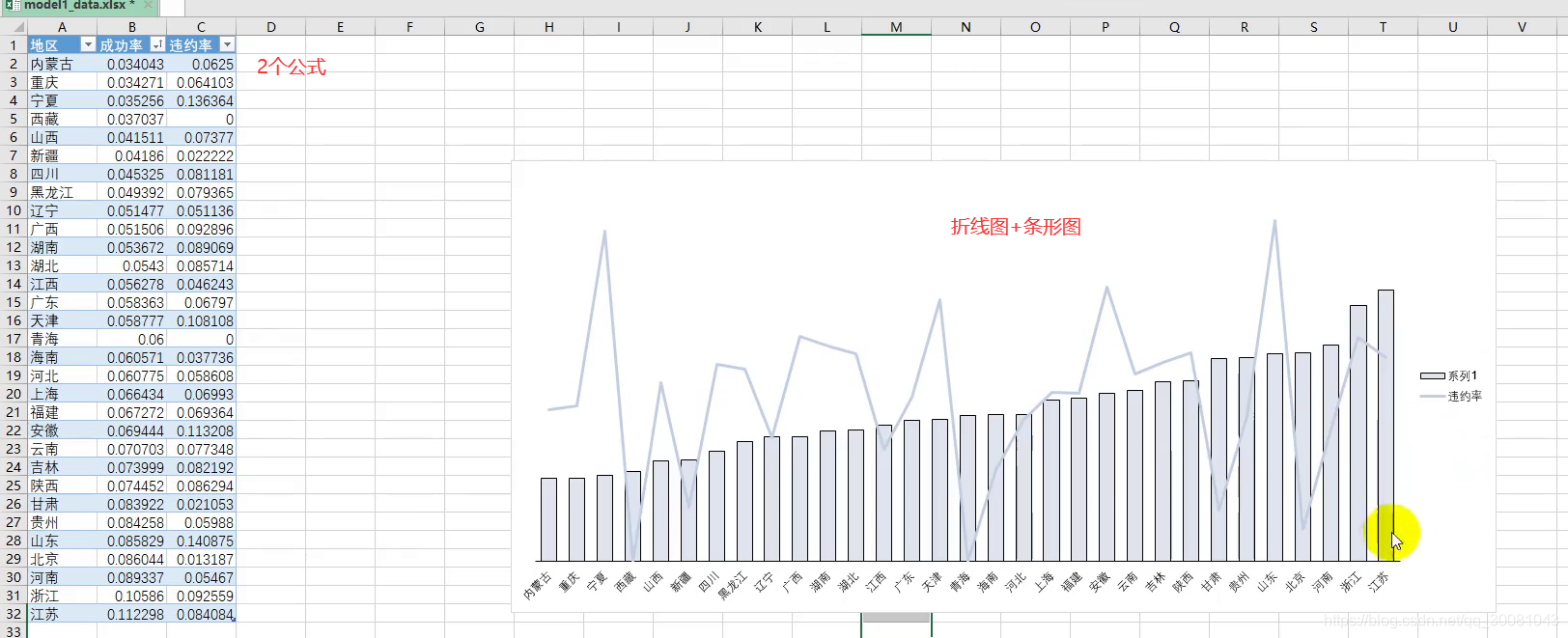
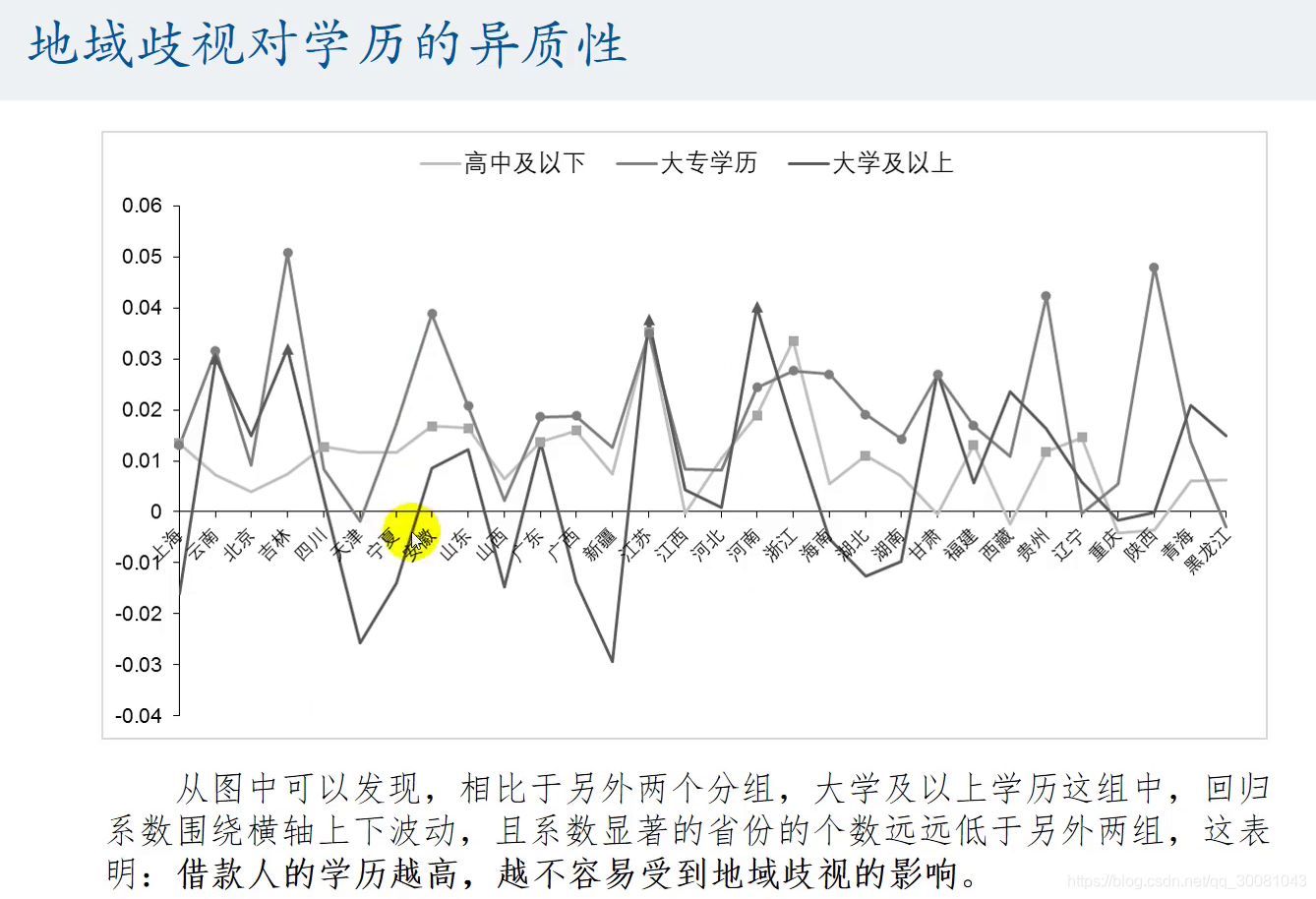
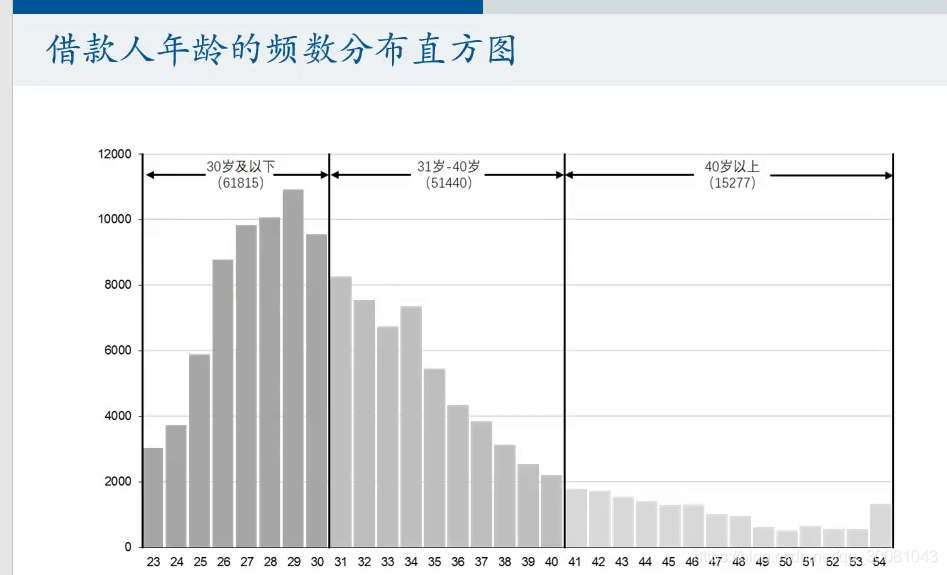
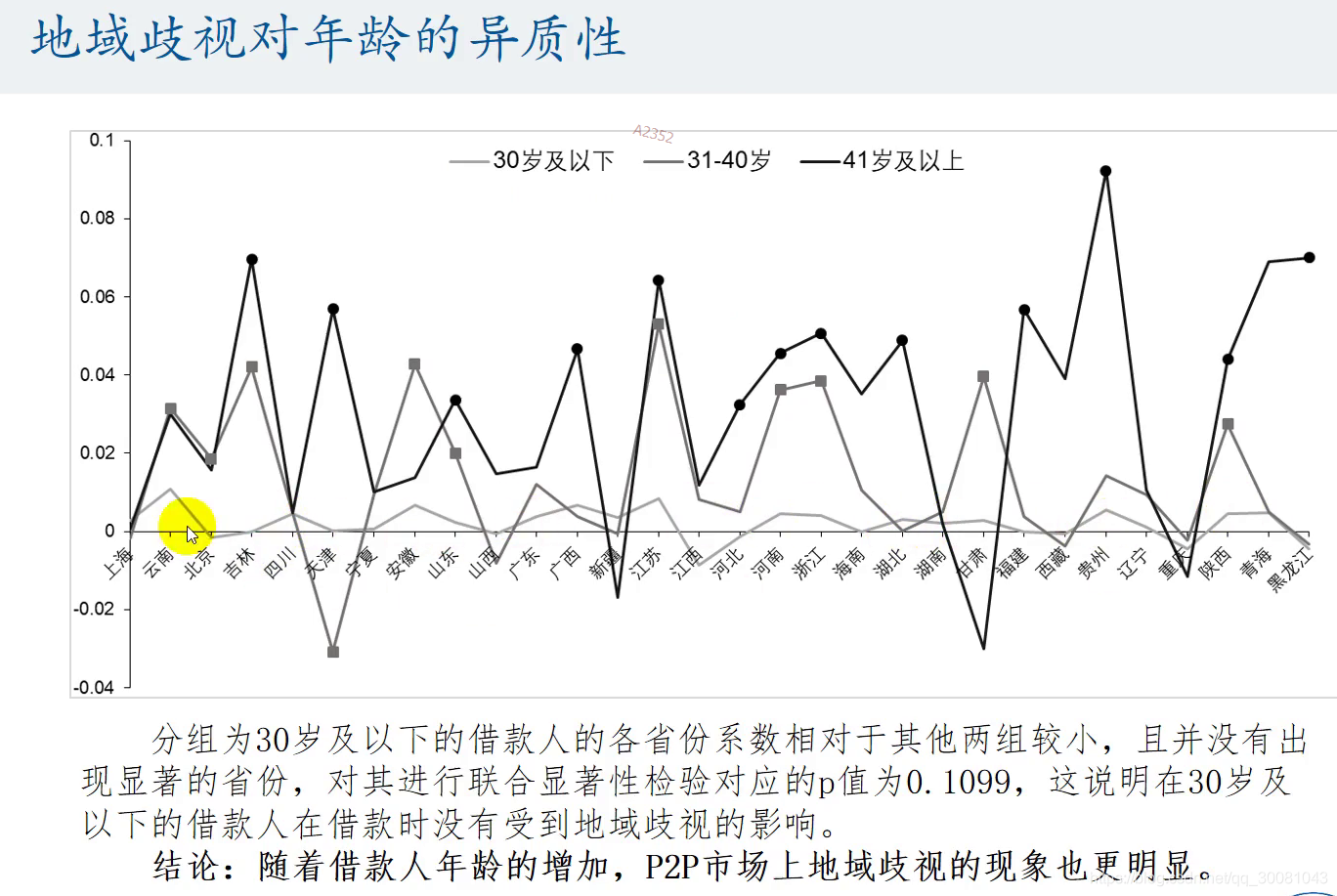
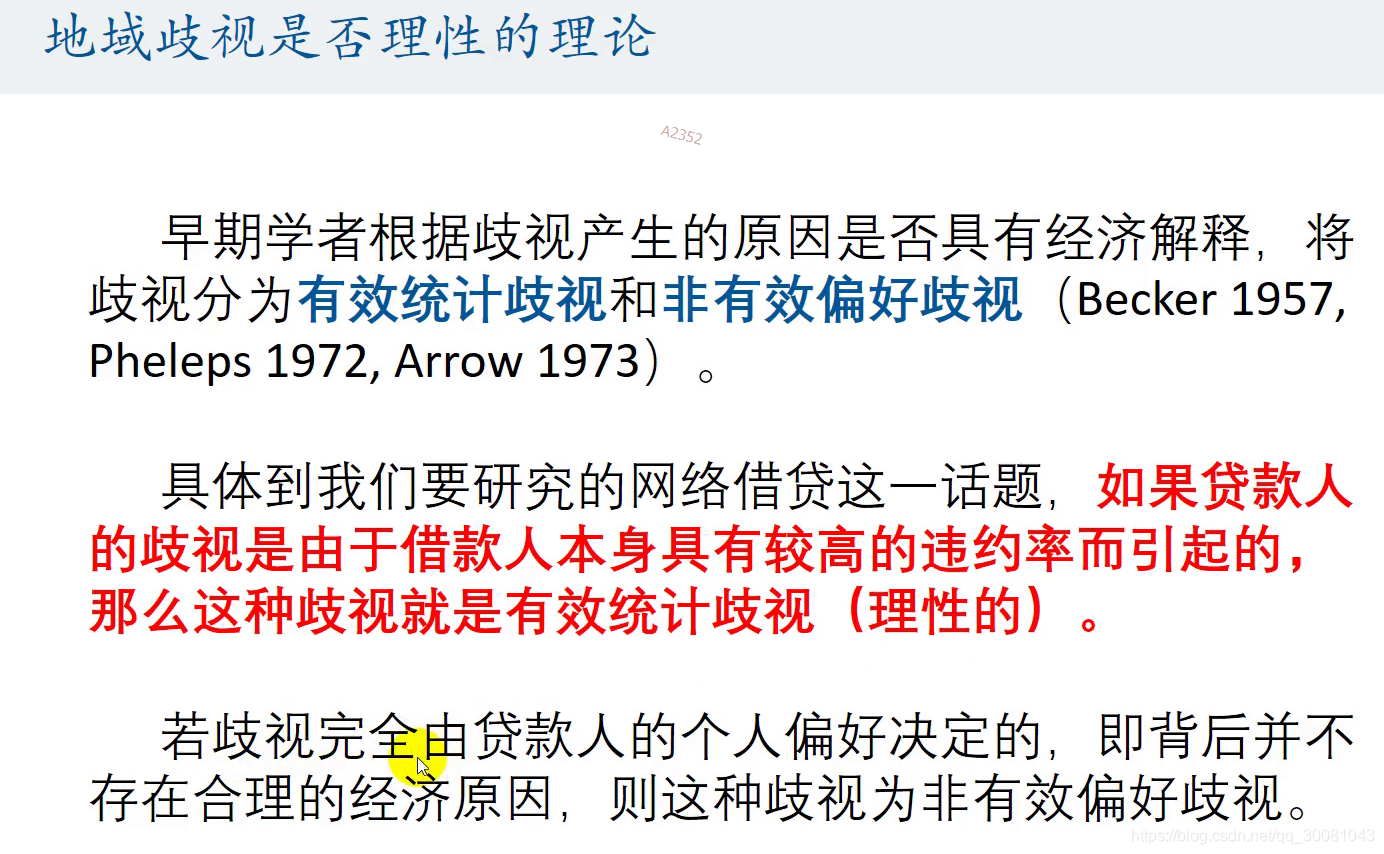
30个都等于0,才能说明他们和内蒙古没什么区别.不存在地域歧视

八、异方差、多重共线性以及逐步回归的介绍
1.扰动项要满足的条件
同方差,无相关

2.异方差
随着x变大,方差在逐渐变大.

给予信息量大的数据更大的权重(即方差较小的数据给予更大的权重)
2.1 检验异方差
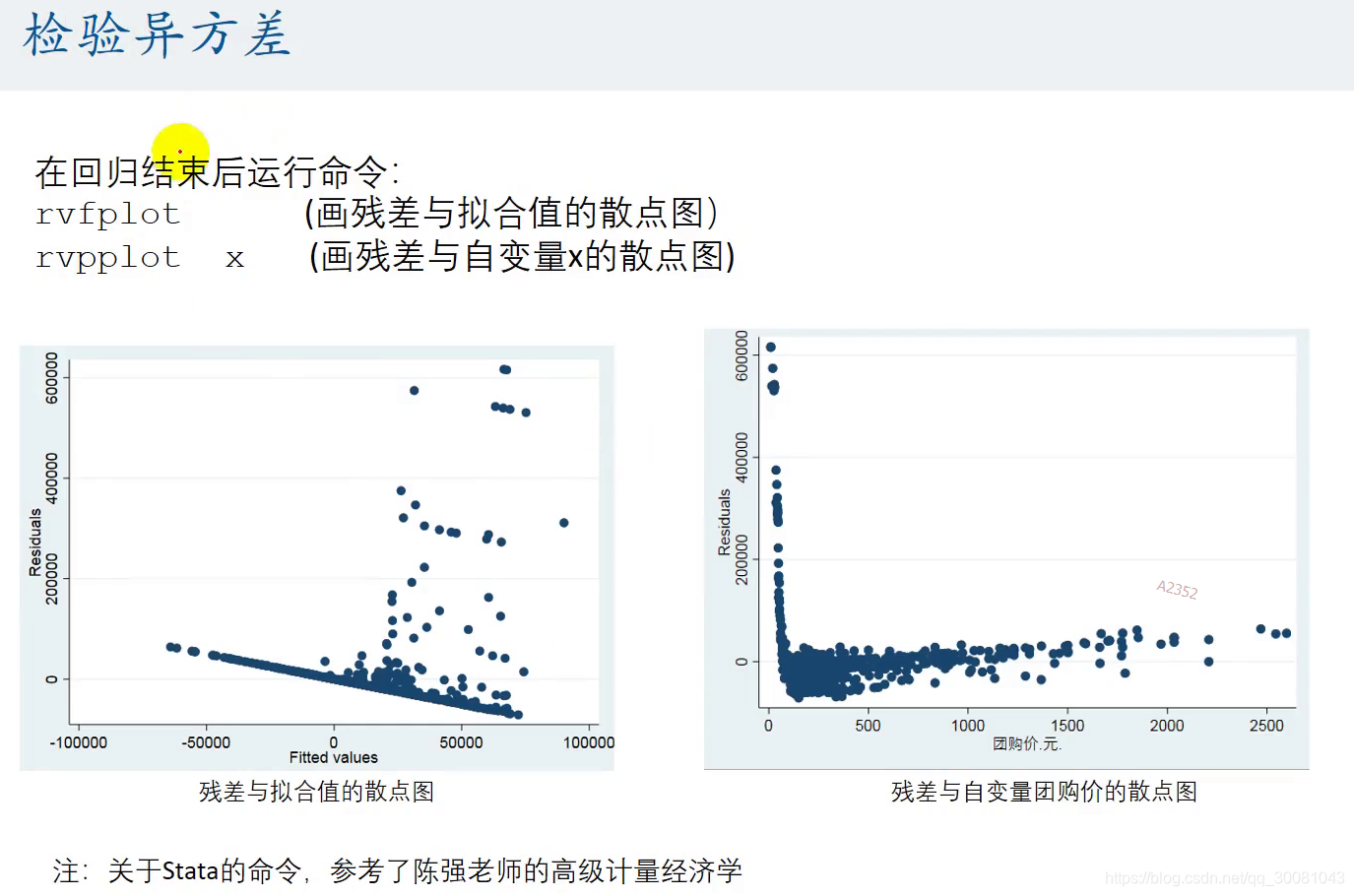
2.2 拟合值出现负数的原因
分布极度不均匀

3.异方差的假设检验
检验扰动项是否存在异方差
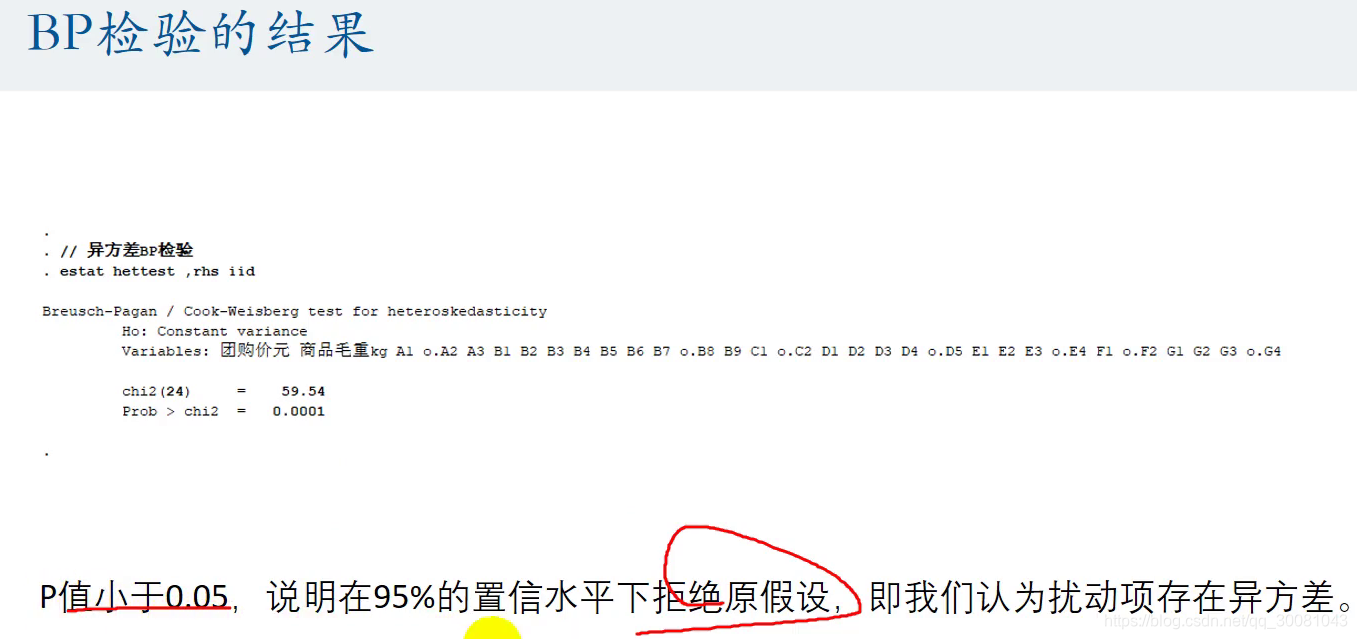
2.1 BP检验

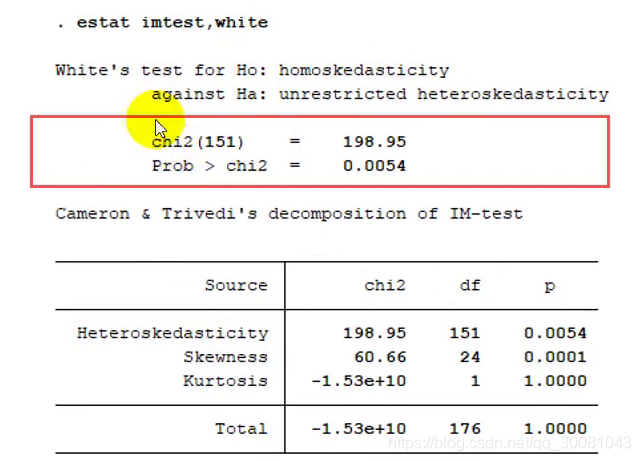
2.1 怀特检验
优点:可以检验任何形式的异方差
原假设:不存在异方差
4.异方差的处理方法
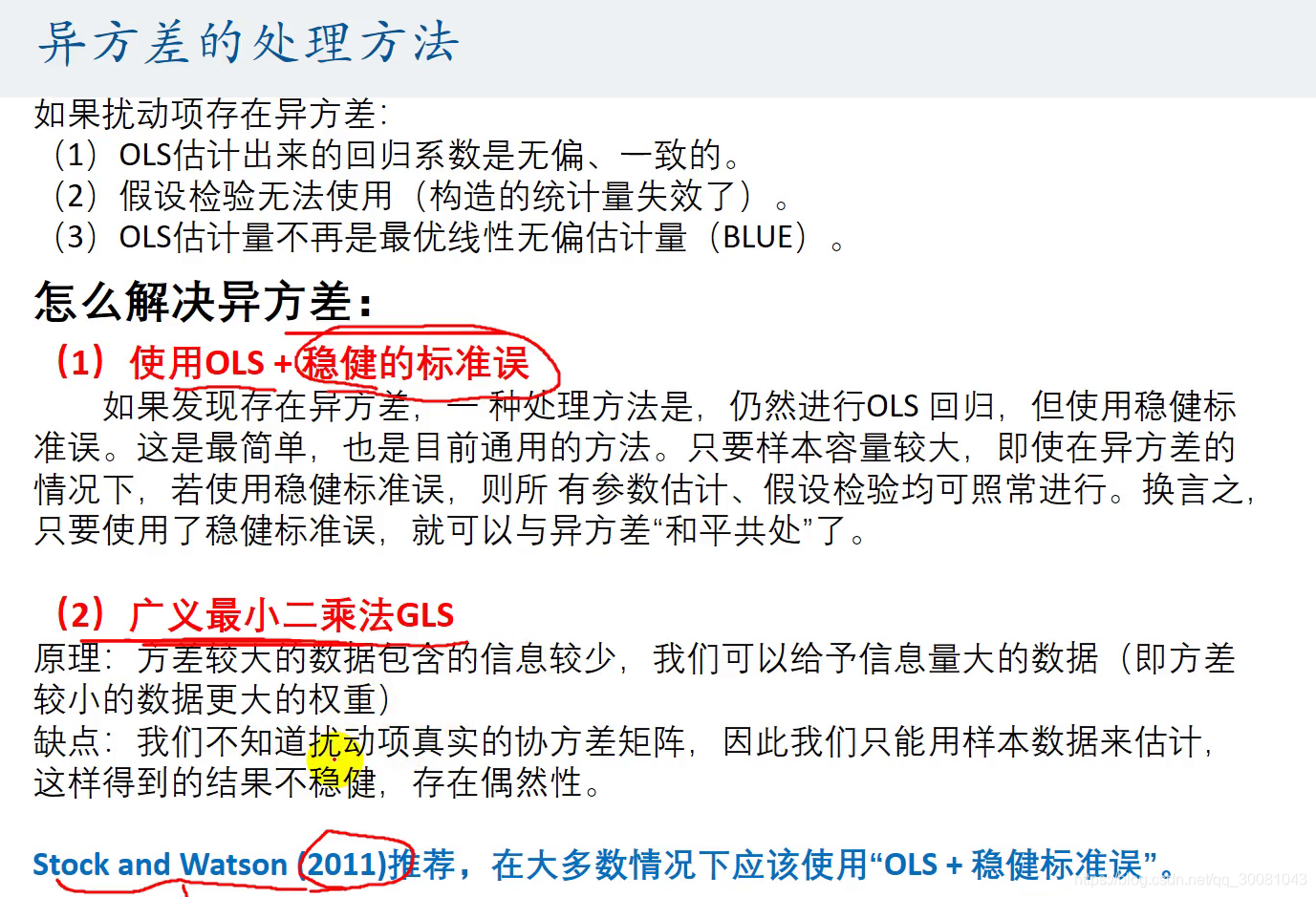
标准误std .err 变成了文件的标准误
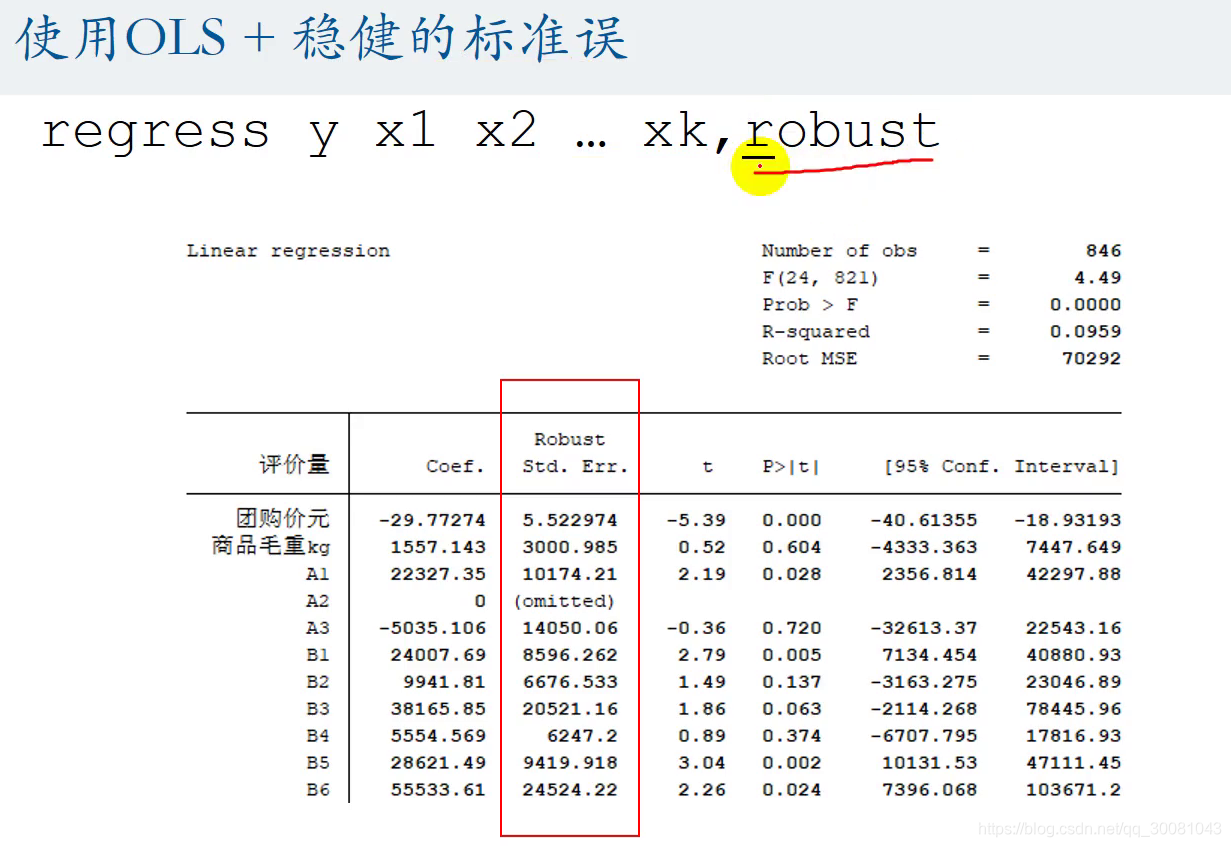
剔除了异方差的影响,就多了很多显著的评价量(p值小于0.05就是显著)
5.多重共线性会出现的问题

5.1 检测多重共线性
m作为因变量,对剩下的k-1个自变量回归得到拟合优度
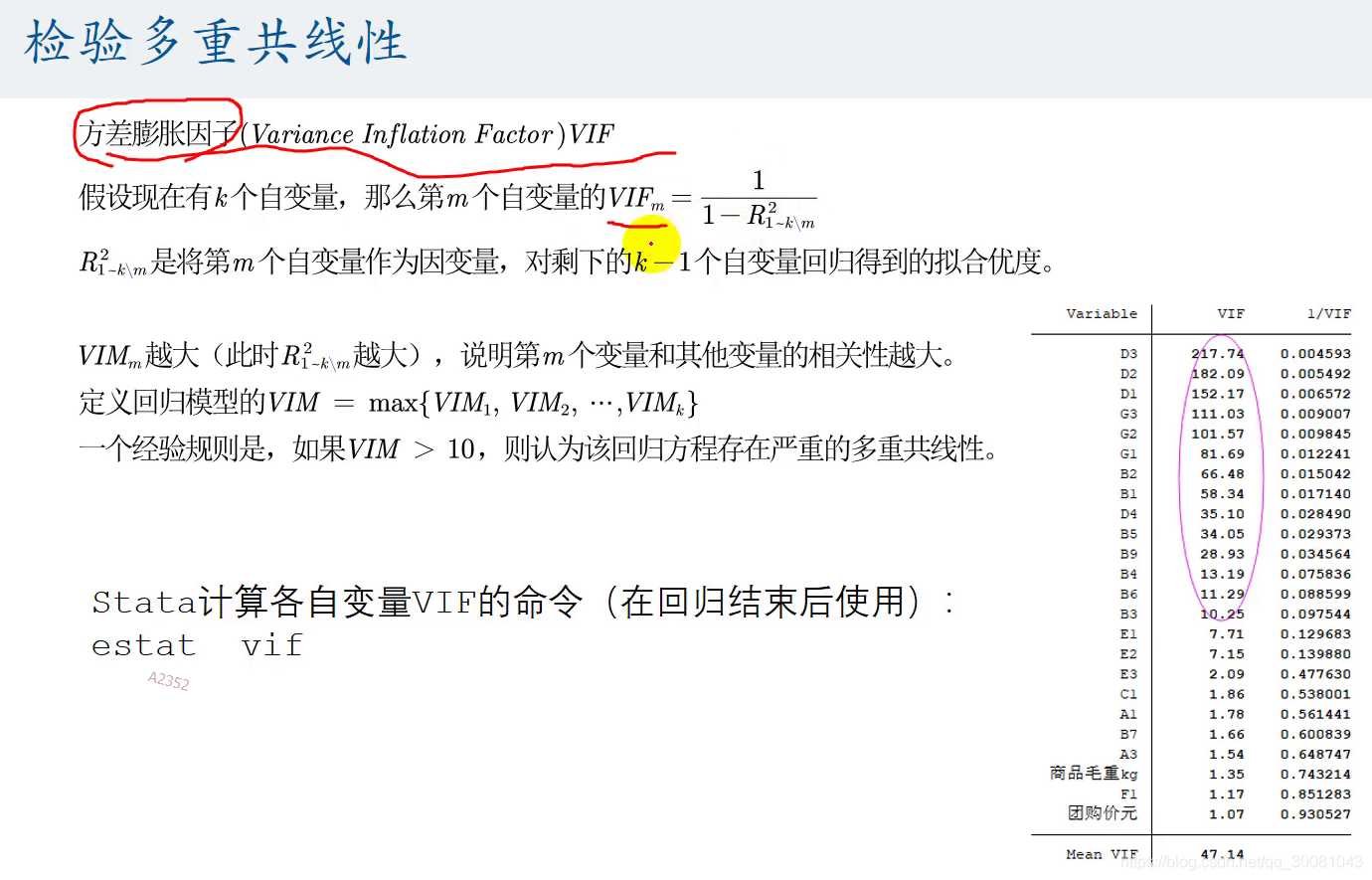
大于10,就认为它存在多重共线性

stata命令

5.2 多重共线性处理方法

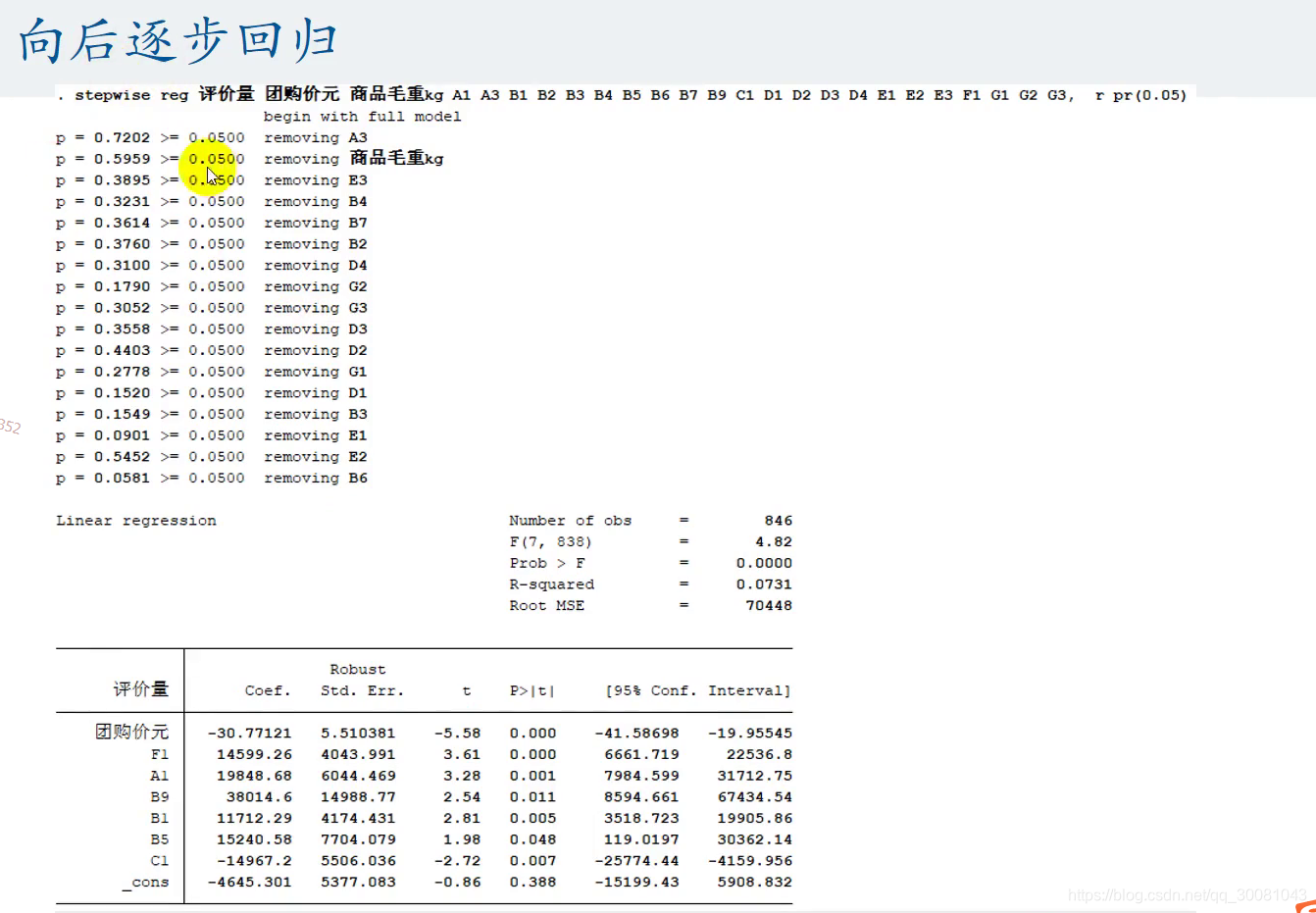
6. 逐步回归分析
剔除多重共线性的影响!(论文需要使用并说明)
显著才引入回归模型

推荐使用向后逐步回归

向前逐步回归

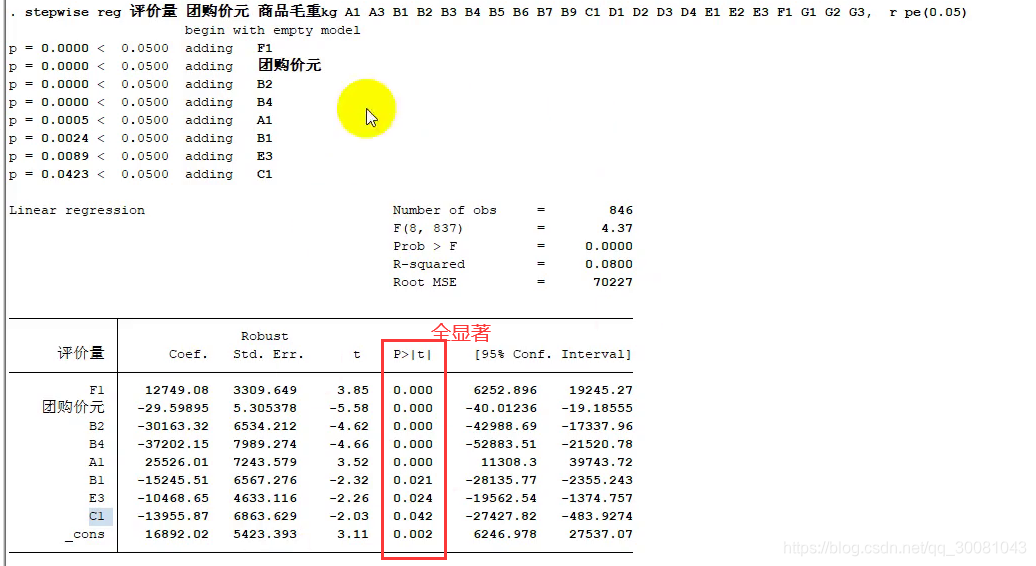
向后逐步回归
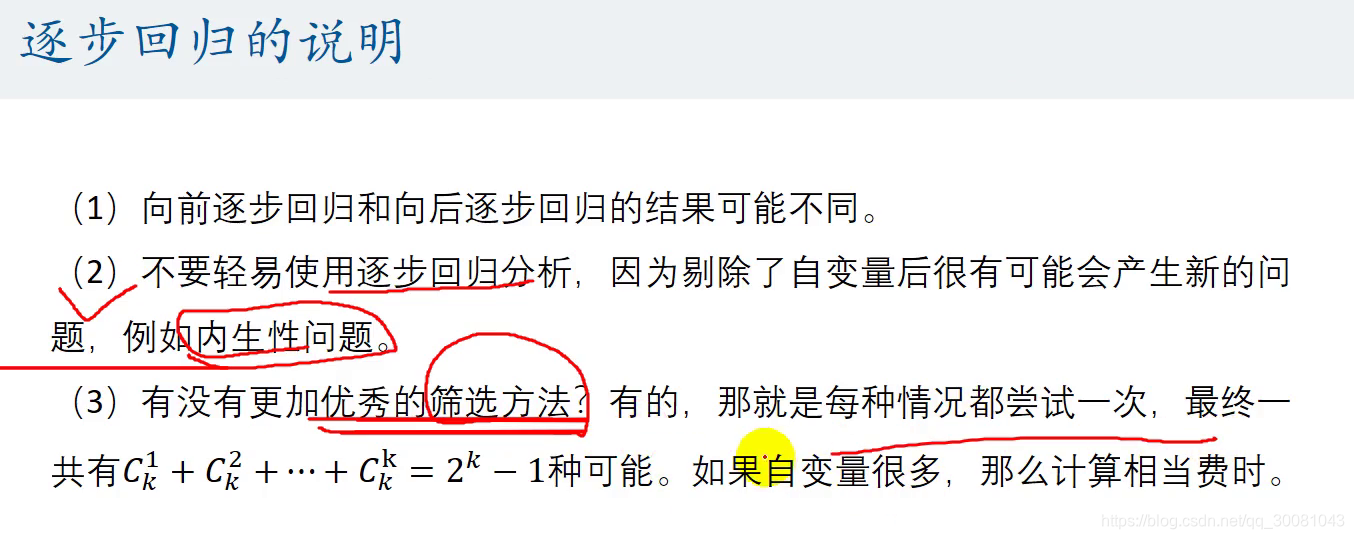
7.逐步回归说明
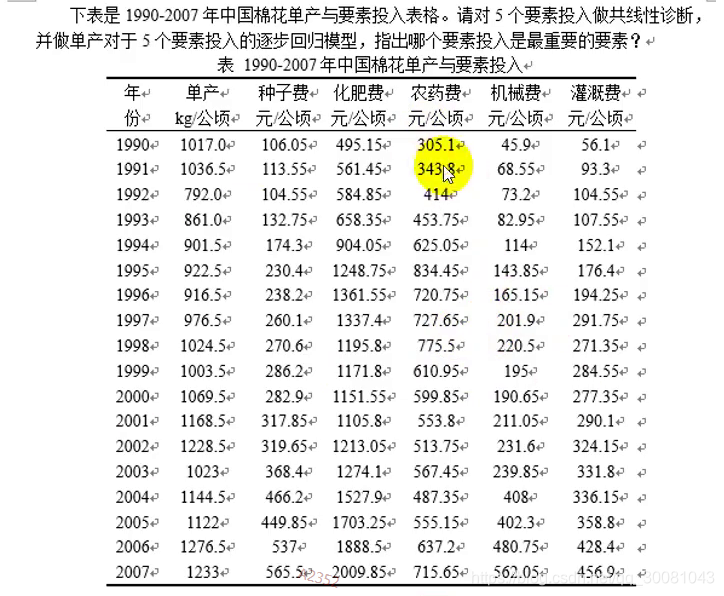
作业
逐步回归