多元线性回归分析
通过研究自变量 X X X 和因变量 Y Y Y 的相关关系,尝试去解释 Y Y Y 的形成机制,进而达到通过 X X X 去预测 Y Y Y 的目的 。

文章目录
(1) 回归分析的简介
1. 相关性
- 相关性 ≠ \not = = 因果性。
- 因果关系很难探究,因此通过探究相关性来代替。
2. 因变量 Y Y Y
- 因变量一般是要研究的核心变量。
- 因变量的分类:
- 连续数值型变量:比如GDP的增长率。
- 0-1型变量:比如将 Y Y Y 设定为二值变量 Y = 1 Y=1 Y=1 表示女性, Y = 0 Y=0 Y=0 表示男性。
- 定序变量:比如在层次分析法中对目标的打分(1:稍微好,3:更好等等)
- 计数变量
- 生存变量
3. 自变量 X X X
- 用 X X X 来解释或者预测因变量 Y Y Y,因此 X X X 也称为解释变量, Y Y Y 称为被解释变量。
4. 回归分析的用途
- 分析哪些 X X X 真的与因变量 Y Y Y 相关。
- 分析真的与变量 Y Y Y 相关的 X X X 与 Y Y Y 的关系是正还是负。
- 在真正相关的 X X X 中计算出不同的回归系数,进而可以知道不同的 X X X 的不同的重要性。
5. 数据的分类
- 横截面数据:在某一时间收集的不同对象的数据。如:2020年的全国各省GDP。
- 时间序列数据:对同一对象在不同时间的连续观测数据。如:陕西省1945-2020的GDP。
- 面板数据:横截面数据与时间序列数据综合起来的一种数据类型。如:1945-2020全国各省的GDP。
⭐️不同分类的数据的处理方案:
| 横截面数据 | 时间序列数据 | 面板数据 |
|---|---|---|
| 多元线性回归 | 移动平均、指数平滑、ARIMA、GARCH、VAR、协积 | 固定效应,随机效应,静态面板,动态面板 |
(2) 多元线性回归分析
1. 一元线性回归与拟合的对比
- 一元线性函数拟合:
- 设样本点 ( x i , y i ) ( i = 1 , … , n ) (x_i,y_i)(i=1,\dots,n) (xi,yi)(i=1,…,n)
- 设置拟合曲线 y = k x + b y=kx+b y=kx+b
- 设定拟合值为 y i ^ = k x i + b \hat{y_i}=kx_i+b yi^=kxi+b
- 目标: k ^ , b ^ = a r g k , b ( m i n ( ∑ i = 1 n ( y − y ^ ) 2 ) = a r g k , b ( m i n ( ∑ i = 1 n ( y i ^ − k x i − b ) 2 ) \hat{k},\hat{b}=arg_{k,b}(min(\displaystyle \sum_{i=1}^n(y-\hat{y})^2)=arg_{k,b}(min(\displaystyle \sum_{i=1}^n(\hat{y_i}-kx_i-b)^2) k^,b^=argk,b(min(i=1∑n(y−y^)2)=argk,b(min(i=1∑n(yi^−kxi−b)2),即求 k ^ , b ^ \hat{k},\hat{b} k^,b^ 使 ∑ i = 1 n ( y − y ^ ) 2 \displaystyle \sum_{i=1}^n(y-\hat{y})^2 i=1∑n(y−y^)2 最小。
- 一元线性回归:
- 设 x x x 是自变量, y y y 是因变量,并且两者之间满足关系 y = β 0 + β 1 x + μ y=\beta_0+\beta_1x_+\mu y=β0+β1x+μ
- 其中 β 1 , β 0 \beta_1,\beta_0 β1,β0 为回归系数, μ \mu μ 是一个无法观测的扰动项,则预测值为 y ^ = β 0 + β 1 x ^ \hat{y}=\beta_0+\beta_1\hat{x} y^=β0+β1x^
- 记 μ ^ i = y i − β ^ 0 − β ^ 1 x i \hat{\mu}_i=y_i-\hat{\beta}_0-\hat{\beta}_1x_i μ^i=yi−β^0−β^1xi 为残差 。目标为 β ^ 0 , β ^ 1 = a r g β 0 , β 1 ( m i n ( ∑ i = 1 n μ i ^ 2 ) ) \hat{\beta}_0,\hat{\beta}_1=arg_{\beta_0,\beta_1}(min(\displaystyle \sum_{i=1}^n\hat{\mu_i}^2)) β^0,β^1=argβ0,β1(min(i=1∑nμi^2)),即求 β 0 ^ , β 1 ^ \hat{\beta_0},\hat{\beta_1} β0^,β1^ 使 ∑ i = 1 n ( μ i ^ ) 2 \displaystyle \sum_{i=1}^n(\hat{\mu_i})^2 i=1∑n(μi^)2 最小。
⭐️ 从上面看来,一元线性拟合和一元线性回归在本质上是一样的,都是求出一条曲线,保证所有样本点到该曲线的距离和最短。
2. 对于线性的理解
- 不一定必须满足完全一样的形式 y = β 0 + β 1 x 1 + ⋯ + β k x k + μ y=\beta_0+\beta_1x_1+\dotsb+ \beta_kx_k +\mu y=β0+β1x1+⋯+βkxk+μ。
- 只要可以将数据转化成类似的形式就可以按照线性的处理方式处理(导入数据之前提前计算好即可):
- y = β 0 + β 1 l n x + μ y=\beta_0+\beta_1lnx+\mu y=β0+β1lnx+μ
- l n y = β 0 + β 1 x + μ lny=\beta_0+\beta_1x+\mu lny=β0+β1x+μ
- y = β 0 + β 1 x + β 2 x 2 + μ y=\beta_0+\beta_1x+\beta_2x^2+\mu y=β0+β1x+β2x2+μ
- y = β 0 + β 1 x 1 + β 2 x 1 x 2 + μ y=\beta_0+\beta_1x_1+\beta_2x_1x_2+\mu y=β0+β1x1+β2x1x2+μ
3. 对内生性的说明
- 假设模型为: y = β 0 + β 1 x 1 + ⋯ + β l x k + μ y=\beta_0+\beta_1x_1+\dotsb+\beta_lx_k+\mu y=β0+β1x1+⋯+βlxk+μ。
- 如果误差项 μ \mu μ 与自变量 x x x 均不相关则称该模型具有外生性,如果相关则存在内生性。
- 内生性会导致回归系数估计的不准确,不满足无偏性和一致性。
4. 对变量的说明
- 核心解释变量:最关心的变量,希望得到对其系数的一致性估计(随着样本数量的增大,系数收敛到某个值)。
- 控制变量:对于方程中的其他变量,把它们也放入回归方程,主要是为了 “控制住” 那些对被解释变量有影响的遗漏因素,以避免遗漏变量偏差。
- 可以不要求控制变量外生(即允许控制变量与扰动项相关),而只要在给定控制变量的条件下,核心变量与扰动项不相关即可。
5. 对回归系数的解释
- 一般的多元线性回归: y ^ = β ^ 0 + β ^ 1 x 1 + ⋯ β ^ k x k \hat{y}=\hat{\beta}_0+\hat{\beta}_1x_1+\dotsb\hat{\beta}_kx_k y^=β^0+β^1x1+⋯β^kxk ,一般不考虑常数 β ^ 0 \hat{\beta}_0 β^0。对于其他的系数 β ^ i \hat{\beta}_i β^i 表示在控制其他变量不变的前提下, x i x_i xi 每增加一个单位对 y y y 造成的变化。
也可以理解成偏导数的形式: β ^ m = ∂ y ∂ x i \hat{\beta}_m=\frac{\partial y}{\partial x_i} β^m=∂xi∂y - 双对数模型: l n y = a + b lny=a+b lny=a+b l n x + μ lnx+\mu lnx+μ 表示 x x x 每增加 1 % 1\% 1% , y y y 相应变化 b % b\% b%。
- 半对数模型: l n y = a + b x + μ lny=a+bx+\mu lny=a+bx+μ 表示 x x x 每增加一个单位 , y y y 相应变化 ( 100 b ) % (100b)\% (100b)%。
- 半对数模型: y = a + b y=a+b y=a+b l n x + μ lnx+\mu lnx+μ 表示 x x x 每增加 1 % 1\% 1%, y y y 相应变化 b / 100 b/100 b/100。
6. 对特殊变量的说明
6.1. 虚拟变量
- 用于处理自变量中的定性变量,比如性别,地域,年级等。
① ① ① 单分类的虚拟变量:
- 例如研究性别对工资的影响:
y = β 0 + θ 0 F e m a l e + β 1 x 1 + ⋯ + β k x k + μ y=\beta_0+\theta_0Female+\beta_1x_1+\dotsb+\beta_kx_k+\mu y=β0+θ0Female+β1x1+⋯+βkxk+μ
F e m a l e = 0 Female=0 Female=0 代表该样本为男性, F e m a l e = 1 Female=1 Female=1 代表该样本为女性。
核心解释变量为: F e m a l e Female Female。控制变量为: x m ( m = 1 , 2 , … , k ) x_m(m=1,2,\dotsc,k) xm(m=1,2,…,k)。 - 解释:样本为女性: E ( y ∣ F e m a l e = 1 , 其 它 变 量 给 定 ) = θ 0 × 1 + C E(y|Female=1,其它变量给定)=\theta_0\times1+C E(y∣Female=1,其它变量给定)=θ0×1+C, 样本为男性: E ( y ∣ F e m a l e = 0 , 其 它 变 量 给 定 ) = θ 0 × 0 + C E(y|Female=0,其它变量给定)=\theta_0\times0+C E(y∣Female=0,其它变量给定)=θ0×0+C,因此 θ 0 = E ( y ∣ F e m a l e = 1 , 其 它 变 量 给 定 ) − E ( y ∣ F e m a l e = 0 , 其 它 变 量 给 定 ) \theta_0=E(y|Female=1,其它变量给定)-E(y|Female=0,其它变量给定) θ0=E(y∣Female=1,其它变量给定)−E(y∣Female=0,其它变量给定),也就是在给定条件下,女性的平均工资与男性的平均工资的差异。
② ② ② 多分类的虚拟变量:
- 例如研究地域区别对贷款成功率的影响:
S u c c e s s i = ∑ k β n × P r o v i n c e i ( k ) + λ × C o n t r o l s i + α + μ i Success_i=\sum_k\beta_n\times Province_i^{(k)} +\lambda\times Controls_i+\alpha+\mu_i Successi=k∑βn×Provincei(k)+λ×Controlsi+α+μi - 当第 i i i 个样本的借款人来自 第 k k k 个省份,则除去 P r o v i n c e i ( k ) = 1 Province_i^{(k)}=1 Provincei(k)=1 以外,其它的都取 0 0 0,如果第 k k k 个省份是内蒙古,则所有的 P r o v i n c e i Province_i Provincei 均取 0 0 0。(将内蒙古作为对照组)
- 为避免多重共线性的影响,引入的虚拟变量的个数一般是分类数减 1 1 1。
6.2. 含有交互项的变量
- 例如: p r i c e price price:房价, s q r f t sqrft sqrft:住房面积, b d r m s bdrms bdrms:卧室数量, b t h r m s bthrms bthrms:卫生间数量。
p r i c e = β 0 + β 1 s q r t + β 2 b d r m s + β 3 s q r f t × b d r m s + β 4 b t h r m s + μ price=\beta_0+\beta_1sqrt+\beta_2bdrms+\beta_3sqrft\times bdrms+\beta_4bthrms+\mu price=β0+β1sqrt+β2bdrms+β3sqrft×bdrms+β4bthrms+μ - 可以看到这里含有交叉项 ∂ p r i c e ∂ s q r f t = β 2 + β 3 b d r m s \dfrac{\partial price}{\partial sqrft}=\beta_2+\beta_3bdrms ∂sqrft∂price=β2+β3bdrms
- 若 β 3 > 0 \beta_3>0 β3>0 则意味着,住房面积越大,增加一间卧室导致价格上升的越快。
7. 拟合优度 R 2 R^2 R2 较低的解决方法
- 回归分为解释性回归和预测型回归。对解释性回归不用太在意 R 2 R^2 R2 的大小。
- 对模型进行调整,例如对数据取对数或者进行平方。
8. 扰动项与异方差
- 一般情况下是球形扰动项(满足“同方差”和“无自相关”两个条件)。
- 横截面数据容易出现异方差问题,时间序列数据容易出现自相关问题。
- 解决方案:使用 OLS+稳健的标准误。
9. 多重共线性
- 症状:
- 虽然整个回归方程的 R 2 R^2 R2 较大、 F F F 检验也很显著,但是单个的 t t t 检验却不显著,或者系数估计值不合理,甚至符号与理论预期相反。
- 增减解释变量使系数的估计值发生较大变化。
- 检验:
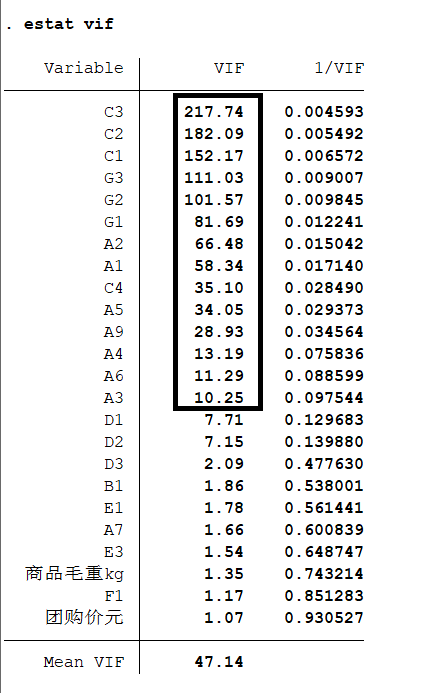
- 方差膨胀因子: V I F VIF VIF。
- 假设现在有 k k k 个变量,那么第 m m m 个自变量的 V I F m = 1 1 − R 1 − k \ m 2 VIF_m=\dfrac{1}{1-R^2_{1-k \backslash m}} VIFm=1−R1−k\m21 ,其中 R 1 − k \ m 2 R^2_{1-k \backslash m} R1−k\m2 代表将第 m m m 个自变量作为因变量,对剩下的 k − 1 k-1 k−1 个自变量进行回归得到的拟合优度,明显 V I F m VIF_m VIFm 越大, R 1 − k \ m 2 R^2_{1-k \backslash m} R1−k\m2 越大,代表第 m m m 个变量与其他变量的相关性越大。
- 定义回归模型的 V I F = m a x { V I F 1 , V I F 2 , … , V I F k } VIF=max\{VIF_1,VIF_2,\dots,VIF_k\} VIF=max{ VIF1,VIF2,…,VIFk}。
- 当 V I F > 10 VIF>10 VIF>10 就说该回归方程存在严重的多重共线性。
- 解决:
- 不关心具体的回归系数,只关心预测与解释能力,在整个方程显著的前提下,不用担心多重共线性。
- 关心具体的回归系数,但并不影响其显著性的时候,不用在意。有多重共线性都显著,没有多重共线性只能更显著。
- 如果影响到:增大样本容量,剔除导致严重共线性的变量,对模型进行修改。
(3) stata的使用
- 文件导入:注意要勾选,将第一行作为变量名。

- 写代码,类似matlab的脚本。
- 定量数据:
summarize 变量1 变量2 变量3...
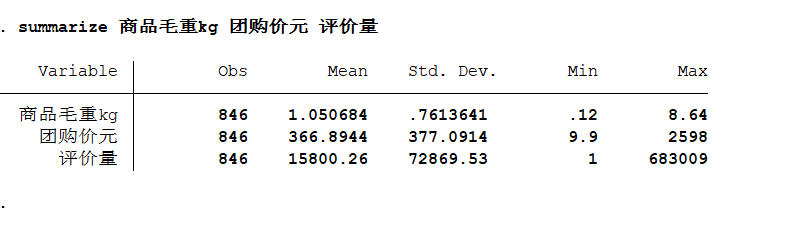
- 定性数据:
tabulate 变量,gen(A)生成对应的虚拟变量(以A开头)。

- 普通回归:
regress y x1 x2 ... xk(默认使用OLS,普通最小二乘估计)。
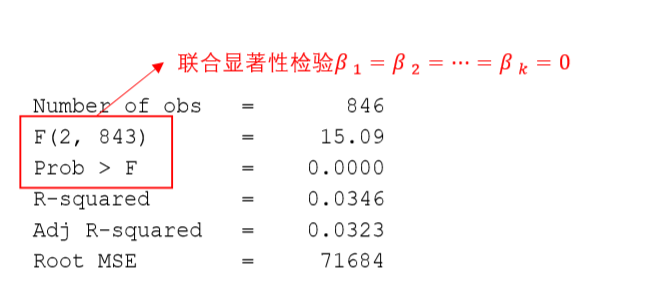
只有在 p p p 值足够小,也就是否定原假设之后这个回归才能使用。原假设也就是 β 1 = β 2 = ⋯ = β k \beta_1=\beta_2=\dotsb=\beta_k β1=β2=⋯=βk。

只有在 p p p 值足够小,也就是否定原假设之后这个回归系数才有意义。原假设就是 β i = 0 \beta_i=0 βi=0。
-
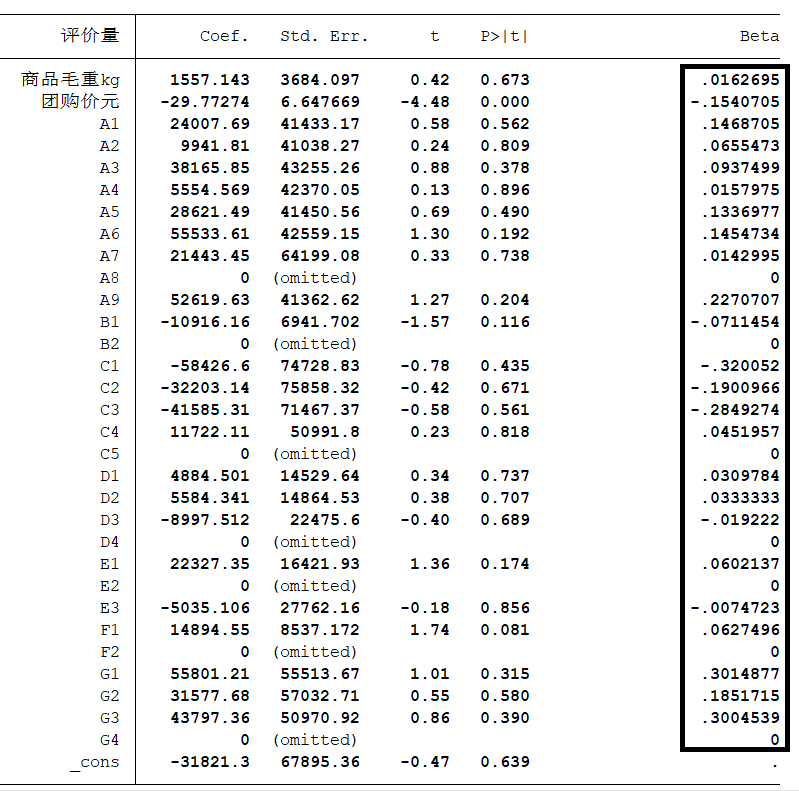
标准化回归:
regress y x1 x2 ... xk,beta,也就是对数据进行标准化,将原数据减去它的均数后再除以该变量的标准差。在系数显著的前提下,绝对值越大说明对因变量的影响越大。
-
逐步回归:
stepwise regress y x1 x2 ... xk,pe(#1)向前逐步回归,显著才加入到模型中。#1填入显著性水平的值,如0.05等。stepwise regress y x1 x2 ... xk,pr(#2)向前逐步回归,不显著就剔除出模型。#2填入显著性水平的值,如0.05等。- 注意此时 x 1 , x 2 , ⋯ , x k x_1,x_2,\dotsb,x_k x1,x2,⋯,xk 之间不能存在完全共线性,也就是对每一组虚拟变量要剔除出一组作为对照组。
- 可以在后面在加
beta或robust。注意要直接加,不要再填逗号,如stepwise regress y x1 x2 ... xk,pr(#2)robust。
-
使用OLS与稳健的标准误:
regress y x1 x2 ... xk,robust。可以看出,此时的显著不为 0 0 0 的变量明显增多。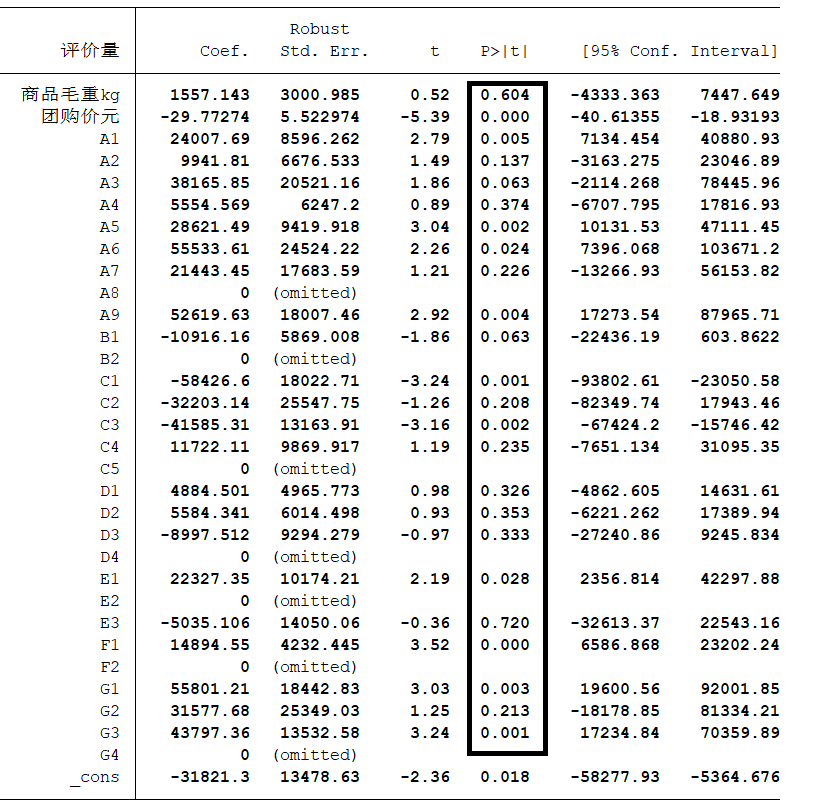
-
异方差的检验:
estat imtest,white (回归结束后使用),注意原假设为:不存在异方差
- 多重共线性的检验:
estat vif (回归结束后使用), V I F > 10 VIF>10 VIF>10 就认为存在严重的多重共线性。