1 JSON介绍
JSON(JavaScript Object Notation)已经成为通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标准格式之一。比CSV格式更加灵活。Json数据格式,非常接近于有效的Pyhton代码,其特点是:JSON对象所有的键都必须是字符串。
可以通过json.loads()将JSON字符串转化为Python的字典形式,方便对其进行进一步操作。
json.loads():将字符串转化为Python形式
json.load():将file文件读取,并转换为Python形式
- JSON标准格式
https://blog.csdn.net/assholeu/article/details/43037373
- Python字典与JSON的区别
https://blog.csdn.net/GitzLiu/article/details/54296971
2 源代码
import requests
import pandas as pd
import json
import time
#数据分析岗位,拉勾网总共的职位是23页
position_info_all = []
for page_num in range(1,24):
url = "https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false"
#my_header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'}
#上述伪装的不够彻底
my_header = {
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?px=default&city=%E6%B7%B1%E5%9C%B3',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'}
# my_header = {
# 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
# 'Host':'www.lagou.com',
# 'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
# 'X-Anit-Forge-Code':'0',
# 'X-Anit-Forge-Token': 'None',
# 'X-Requested-With':'XMLHttpRequest'
# }
#page_num用于修改页码,抓取全部页码的信息
my_data = {'first':'true','pn':page_num,'kd':'数据分析'}
#注意查看post请求还是get请求
response = requests.post(url,headers = my_header,data =my_data )
# print(response)
# print(response.text)
dict_all = json.loads(response.text)
dict_position_results = dict_all["content"]["positionResult"]["result"]
for position_item in dict_position_results:
position_info_single = []
position_info_single.append(position_item["companyFullName"])
position_info_single.append(position_item["companyShortName"])
position_info_single.append(position_item["companySize"])
position_info_single.append(position_item["financeStage"])
position_info_single.append(position_item["district"])
position_info_single.append(position_item["positionName"])
position_info_single.append(position_item["workYear"])
position_info_single.append(position_item["education"])
position_info_single.append(position_item["salary"])
position_info_single.append(position_item["jobNature"])
position_info_single.append(position_item["positionAdvantage"])
position_info_single.append(position_item["createTime"])
position_info_all.append(position_info_single)
time.sleep(20)
#print(position_info_all)
df = pd.DataFrame(data = position_info_all,columns = ['公司全名','公司简称','公司规模','融资阶段','区域','职位名称','工作经验','学历要求','工资','工作形式','职位福利','发布时间'])
df.to_csv('lagou_jobs_1.csv',index = False,encoding="utf_8_sig")
print("文件写入成功!")
3 Pyhton爬虫
(1)网页信息准备
本文爬取拉勾网-深圳市“数据分析”岗位的数据信息,并对其进行数据清洗及可视化操作。图1为拉勾网深圳数据分析网页界面。

爬虫的方式分为很多种,基础的爬虫通常分为网页源代码爬取和JSON数据包爬取。前者,网站内信息在网页代码中,通过发送HTTP请求网页页面代码,对其进行目标内容提取即可采集数据;后者,较前者则增加一定的难度,通常用以“爬虫攻防战”,网站将数据存于JSON数据包,爬虫开发者需要通过查看网页元素信息,找到该数据包,并通过GET或POST等请求方式,结合其他诸如“伪装成浏览器”等形式的反“反爬虫”机制手段,进行数据的爬取。
本文基于JSON数据包,进行抓包数据爬取。F12键,可快速查看页面信息。一般情况,JSON数据包存于Network - XHR或JS - Preview中,开发者需要自行找到该数据包,并与页面显示的信息进行对比,准确无误,即为要爬取的数据包。

通过查看Network - XHR或JS - Headers,找到 Request URL \ Request Method \ Request Headers \ Form Data等信息。如下图所示:(下面将详细介绍其用途)

(2)JSON数据在线解析
- 通过json数据在线解析,找到要爬取的关键值的索引,进行取值。

(3)总结
(1)深圳数据分析岗位招聘一共343,每页显示15个岗位信息,一共23页数据;
(2)网站上数据分析岗位的招聘信息,存于JSON数据包,其具体信息如下:
- Request URL: https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false(通过向该网址发送HTTP请求,接收服务器响应)
- Request Method :POST(HTTP请求方式,这点很重要,将GET和POST方式弄错,导致请求的数据与页面源代码的数据不一致)
- Request Headers :User-Agent:**Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0(一级反反爬机制,将代码请求伪装成浏览器请求,防止反爬)
- Form Data:(修改pn,可以修改爬取的页面数)
first: true
pn: 1
kd: 数据分析
4 第一页数据爬取
(1)源代码
import requests
import pandas as pd
import json
#数据分析岗位,拉勾网总共的职位是23页
#指定爬取的页面,首先爬取第一页的岗位数据
page_num =1
url = "https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false"
#my_header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'}
#上述伪装的不够彻底
my_header = {
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?px=default&city=%E6%B7%B1%E5%9C%B3',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'}
#page_num用于修改页码,抓取全部页码的信息
my_data = {'first':'true','pn':page_num,'kd':'数据分析'}
#注意查看post请求还是get请求
response = requests.post(url,headers = my_header,data =my_data )
#通过json.loads方法,将服务器响应的json格式数据转换为Python形式的数据,方便后续调用。
dict_all = json.loads(response.text)
dict_position_results = dict_all["content"]["positionResult"]["result"]
#数据预处理,未经处理的数据的列数有46columns,本文只需要提取其中关键的12列数据即可。
#方法:将字典内数据循环读取,装进列表中。
position_info_all = []
for position_item in dict_position_results:
position_info_single = []
position_info_single.append(position_item["companyFullName"])
position_info_single.append(position_item["companyShortName"])
position_info_single.append(position_item["companySize"])
position_info_single.append(position_item["financeStage"])
position_info_single.append(position_item["district"])
position_info_single.append(position_item["positionName"])
position_info_single.append(position_item["workYear"])
position_info_single.append(position_item["education"])
position_info_single.append(position_item["salary"])
position_info_single.append(position_item["jobNature"])
position_info_single.append(position_item["positionAdvantage"])
position_info_single.append(position_item["createTime"])
position_info_all.append(position_info_single)
#将爬取的数据写进CSV文件
df = pd.DataFrame(data = position_info_all,columns = ['公司全名','公司简称','公司规模','融资阶段',
'区域','职位名称','工作经验','学历要求','工资','工作形式','职位福利','发布时间'])
df.to_csv('lagou_jobs_page1.csv',index = False,encoding="utf_8_sig")
print("数据存储成功(CSV格式)!")
(2)建立HTTP请求并发送,获取响应
- 注意是POST请求
- my_header:用于伪装成浏览器访问(爬虫攻防)
- my_data:用于修改页数

(3)json数据转化、数据清洗、按格式存储数据
- json.loads方法,将json格式数据转换成Python可用数据
- 数据清洗,通过按索引从字典中提取关键数据,存入列表
- 存储数据成CSV格式
- 注意:存储成CSV格式,用Excel打开的时候,容易出现乱码现象。
需加上如图的encoding = ‘utf_8_sig’

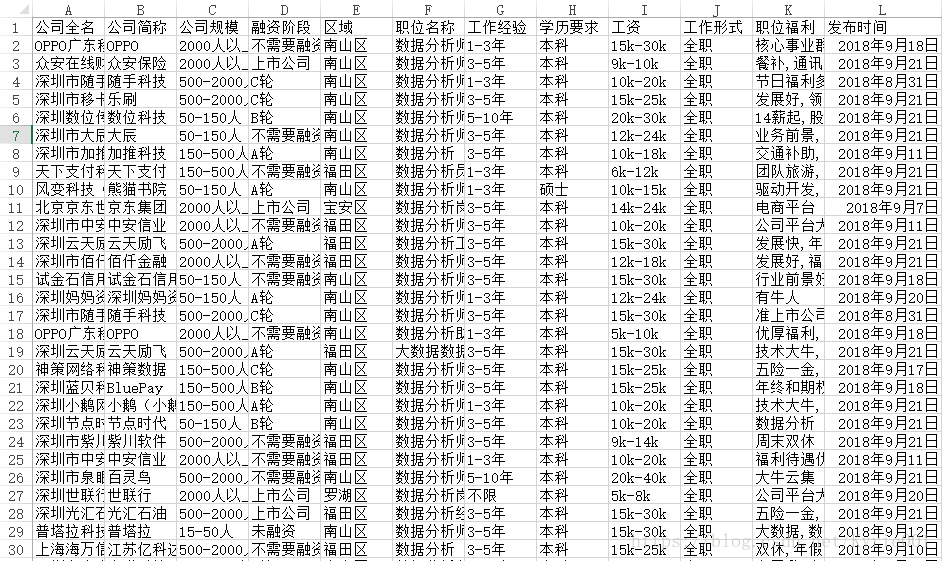
(4)CSV数据展示(15个数据)

5 循环爬取所有信息
(1)源代码
import requests
import pandas as pd
import json
import time
#数据分析岗位,拉勾网总共的职位是23页
position_info_all = []
for page_num in range(1,24):
url = "https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false"
#my_header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'}
#上述伪装的不够彻底
my_header = {
'Host':'www.lagou.com',
'Origin':'https://www.lagou.com',
'Referer':'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?px=default&city=%E6%B7%B1%E5%9C%B3',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0',
'X-Anit-Forge-Code':'0',
'X-Anit-Forge-Token':'None',
'X-Requested-With':'XMLHttpRequest'}
#page_num用于修改页码,抓取全部页码的信息
my_data = {'first':'true','pn':page_num,'kd':'数据分析'}
#注意查看post请求还是get请求
response = requests.post(url,headers = my_header,data =my_data )
dict_all = json.loads(response.text)
dict_position_results = dict_all["content"]["positionResult"]["result"]
for position_item in dict_position_results:
position_info_single = []
position_info_single.append(position_item["companyFullName"])
position_info_single.append(position_item["companyShortName"])
position_info_single.append(position_item["companySize"])
position_info_single.append(position_item["financeStage"])
position_info_single.append(position_item["district"])
position_info_single.append(position_item["positionName"])
position_info_single.append(position_item["workYear"])
position_info_single.append(position_item["education"])
position_info_single.append(position_item["salary"])
position_info_single.append(position_item["jobNature"])
position_info_single.append(position_item["positionAdvantage"])
position_info_single.append(position_item["createTime"])
position_info_all.append(position_info_single)
time.sleep(20)
#print(position_info_all)
df = pd.DataFrame(data = position_info_all,columns = ['公司全名','公司简称','公司规模','融资阶段','区域','职位名称','工作经验','学历要求','工资','工作形式','职位福利','发布时间'])
df.to_csv('lagou_jobs_page_all.csv',index = False,encoding="utf_8_sig")
print("全部数据存储成功(CSV格式)!")
(2)for循环的加入
- time.sleep()暂停进程
- import time,加入限时函数,模拟人为点击爬虫,以免被网站封杀
- 在没有加入time.sleep(20)的时候,出现KeyError: ‘content’,在加入sleep之后,就解决了。
- 可能原因1:https://blog.csdn.net/u011089523/article/details/72887163
- 可能原因2:https://segmentfault.com/q/1010000007079342?_ea=1232968