 日萌社
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
#模型中最后一层隐藏层的最后一个时间步(节点)的输出output可作为预测值,然后通过softmax把output输出转换为概率值
#for循环遍历出来的input可以是字符,也可以是单词,那么模型可以是字符输入版本,也可以是单词输入版本
for input in range(lines):
output, hidden = RNN实例对象(input, hidden)
output, hidden = GRU实例对象(input, hidden)
output, (hidden, cn) = LSTM实例对象(input, (hidden, cn))
encoder_output, encoder_hidden = encoder(encoder_input, encoder_hidden)
decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)
# nn.RNN(输入数据的词嵌入维度input_size, 隐藏层中神经元数量hidden_size, 隐藏层层数num_layers)
rnn = nn.RNN(5, 6, 2)
gru = nn.GRU(5, 6, 2)
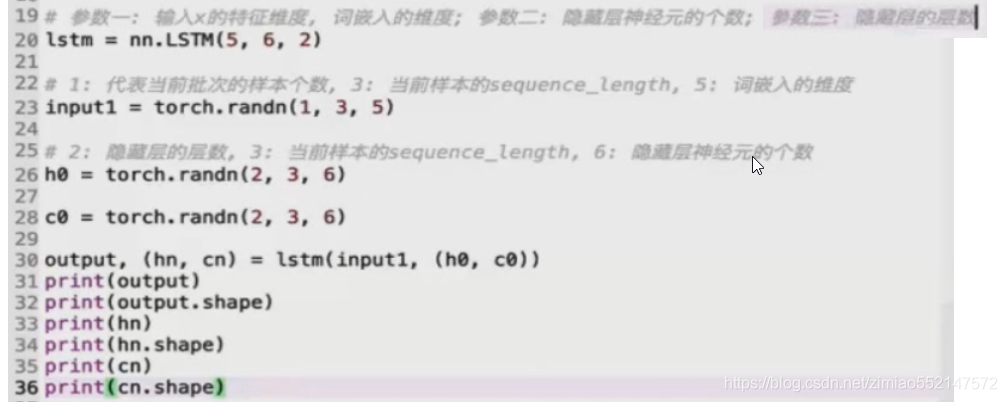
lstm = nn.LSTM(5, 6, 2)
input_size: 每一个时步(time_step)输入到RNN/GRU/LSTM单元的维度,实际输入的数据shape为(当前批次的样本个数, 当前样本的序列长度(单词个数), 词嵌入维度)
hidden_size: 确定了隐含状态hidden_state的维度,可以简单的看成构造了一个可学习输入隐藏权重的形状(hidden_size, input_size)
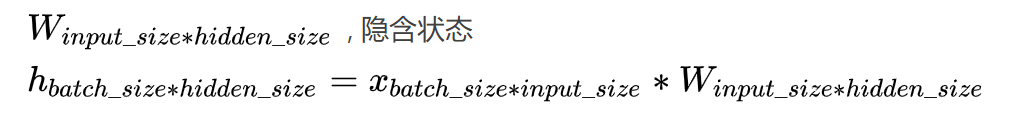
weight_ih:
可学习输入隐藏权重的形状(hidden_size, input_size)
每个单词 的嵌入维度的 向量 作为 一个时间步 输入到 一个 RNN 节点,
然后 会和 神经元数量维度的 向量 构成一个 可学习输入隐藏权重 这样的 形状 (hidden_size, input_size),
就是 (神经元数量, 单词嵌入维度)。
比如input输入数据为(当前批次的样本个数, 当前样本的序列长度(单词个数), 词嵌入维度),
那么input_size即为input输入数据的最后一个维度即词嵌入维度,
那么每个时间步的输入维度input_size(一个单词的词嵌入维度embedding_dim) 都要作用于 隐藏层的所有隐藏神经元hidden_size,
那么便会构建一个(hidden_size, input_size)形状的可学习输入隐藏权重。
def __init__(self, mode, input_size, hidden_size,
num_layers=1, bias=True, batch_first=False, dropout=0.,
bidirectional=False):
#默认值bidirectional=False:那么“2 if False else 1”返回1,“2 if True else 1”返回2。
#如果RNN是双向的,num_directions应该是2,否则应该是1。
num_directions = 2 if bidirectional else 1
========================================================================
# nn.RNN(输入数据的词嵌入维度, 隐藏层中神经元数量, 隐藏层层数)
rnn = nn.RNN(5, 6, 2)
gru = nn.GRU(5, 6, 2)
lstm = nn.LSTM(5, 6, 2)
# input of shape (seq_len, batch, input_size):(当前批次的样本个数, 当前样本的序列长度(单词个数), 词嵌入维度)
# input输入数据,torch.randn(当前批次的样本个数, 当前样本的序列长度(单词个数), 词嵌入维度)
input = torch.randn(4, 3, 5)
# h_0 of shape (num_layers * num_directions, batch, hidden_size):
# RNN是单向:(隐藏层层数 * 1, 一个句子单词个数, 隐藏层中神经元数量)
# RNN是双向:(隐藏层层数 * 2, 一个句子单词个数, 隐藏层中神经元数量)
# hn隐藏层数据,torch.randn(隐藏层层数, 当前样本的序列长度(单词个数), 隐藏层中神经元数量)
h0 = torch.randn(2, 3, 6)
# c_0 of shape (num_layers * num_directions, batch, hidden_size)
# RNN是单向:(隐藏层层数 * 1, 一个句子单词个数, 隐藏层中神经元数量)
# RNN是双向:(隐藏层层数 * 2, 一个句子单词个数, 隐藏层中神经元数量)
c0 = torch.randn(2, 3, 6)
output, hn = rnn(input, h0)
output, (hn, cn) = rnn(input, (h0, c0))
# output of shape (seq_len, batch, num_directions * hidden_size):
# RNN是单向:(当前批次的样本个数, 当前样本的序列长度(单词个数), 隐藏层中神经元数量 * 1)
# RNN是双向:(当前批次的样本个数, 当前样本的序列长度(单词个数), 隐藏层中神经元数量 * 2)
output.shape #torch.Size([4, 3, 6])
# h_n of shape (num_layers * num_directions, batch, hidden_size)
# RNN是单向:(隐藏层层数 * 1, 一个句子单词个数, 隐藏层中神经元数量)
# RNN是双向:(隐藏层层数 * 2, 一个句子单词个数, 隐藏层中神经元数量)
hn.shape #torch.Size([2, 3, 6])
# c_n of shape (num_layers * num_directions, batch, hidden_size)
# RNN是单向:(隐藏层层数 * 1, 一个句子单词个数, 隐藏层中神经元数量)
# RNN是双向:(隐藏层层数 * 2, 一个句子单词个数, 隐藏层中神经元数量)
hn.shape #torch.Size([2, 3, 6])
Examples::
#nn.LSTM(输入数据的词嵌入维度 10, 隐藏层中神经元数量 20, 隐藏层层数 2)
>>> rnn = nn.LSTM(10, 20, 2)
#input输入数据,torch.randn(当前批次的样本个数 5, 当前样本的序列长度(单词个数) 3, 词嵌入维度 10)
>>> input = torch.randn(5, 3, 10)
#h0/hn隐藏层数据,torch.randn(隐藏层层数 2, 当前样本的序列长度(单词个数) 3, 隐藏层中神经元数量 20)
>>> h0 = torch.randn(2, 3, 20)
#c0/cn细胞状态数据,torch.randn(隐藏层层数 2, 当前样本的序列长度(单词个数) 3, 隐藏层中神经元数量 20)
>>> c0 = torch.randn(2, 3, 20)
>>> output, (hn, cn) = rnn(input, (h0, c0))

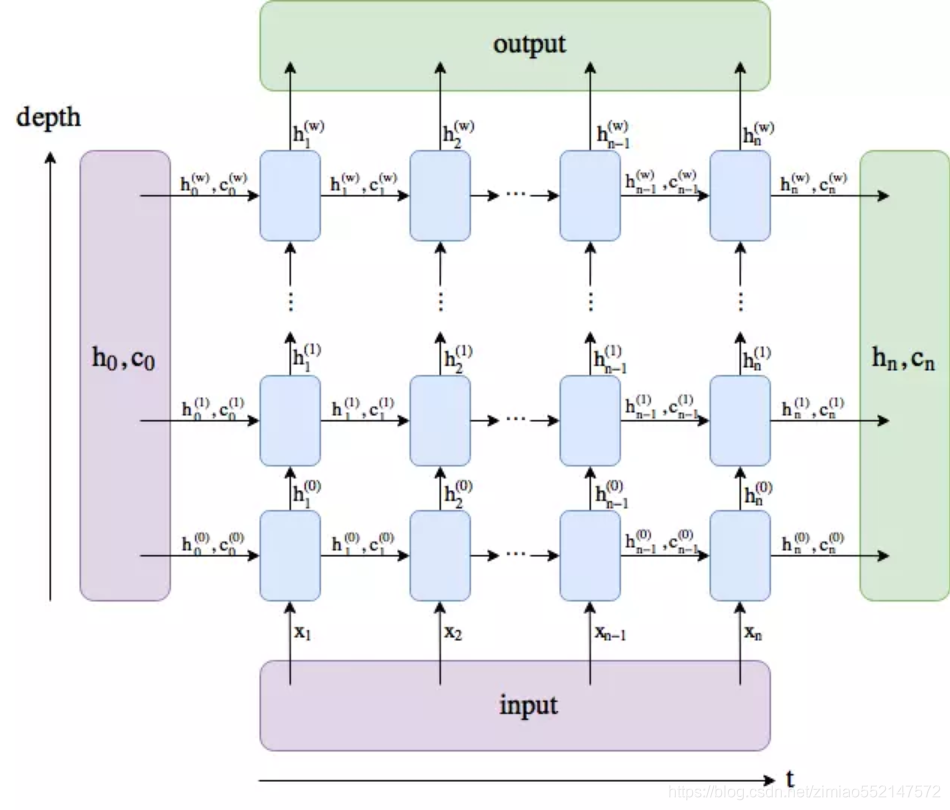
LSTM输出API为:output,(h_n,c_n)=self.rnn(x)
1.output: 如果num_layer为3,则output只记录最后一层(即第三层)的输出
对应图中向上的各个time_step的ht,也即output。
(seq_len, batch, num_directions * hidden_size):
RNN是单向:(当前批次的样本个数, 当前样本的序列长度(单词个数), 隐藏层中神经元数量 * 1)
RNN是双向:(当前批次的样本个数, 当前样本的序列长度(单词个数), 隐藏层中神经元数量 * 2)
2.h_n: 各个层的最后一个时步的隐含状态h
shape为[num_layers, batch_size, hidden_size]。
(num_layers * num_directions, batch, hidden_size)
RNN是单向:(隐藏层层数 * 1, 一个句子单词个数, 隐藏层中神经元数量)
RNN是双向:(隐藏层层数 * 2, 一个句子单词个数, 隐藏层中神经元数量)
3.c_n: 各个层的最后一个时步的隐含状态C
c_n可以看成另一个隐含状态,其shape和h_n的shape相同。
(num_layers * num_directions, batch, hidden_size)
RNN是单向:(隐藏层层数 * 1, 一个句子单词个数, 隐藏层中神经元数量)
RNN是双向:(隐藏层层数 * 2, 一个句子单词个数, 隐藏层中神经元数量)
RNN

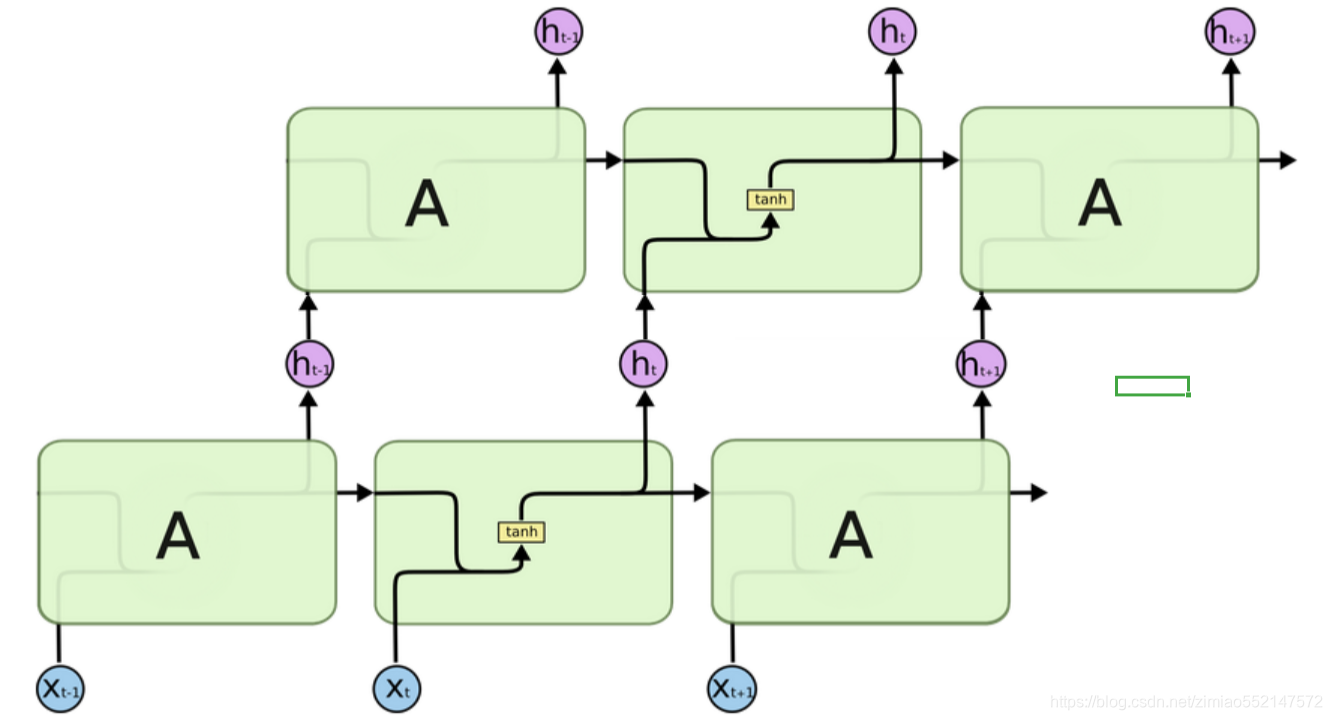
weight_ih:
可学习输入隐藏权重的形状(hidden_size, input_size)
每个单词 的嵌入维度的 向量 作为 一个时间步 输入到 一个 RNN 节点,
然后 会和 神经元数量维度的 向量 构成一个 可学习输入隐藏权重 这样的 形状 (hidden_size, input_size),
就是 (神经元数量, 单词嵌入维度)。
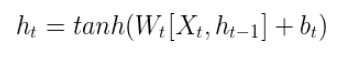
nn.RNN(输入数据的词嵌入维度, 隐藏层中神经元数量, 隐藏层层数)
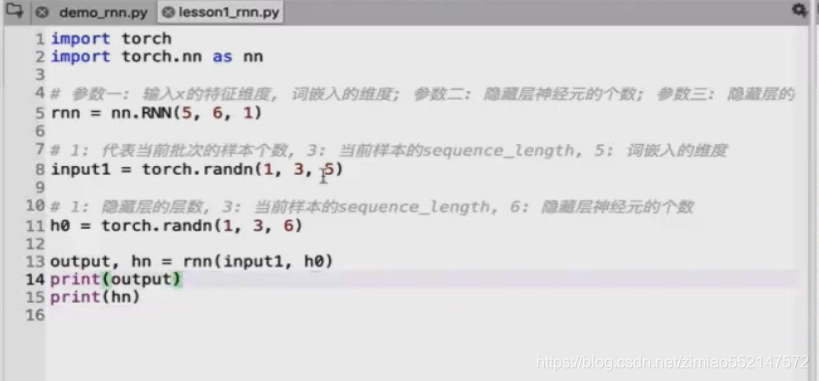
Xt:输入数据,shape为(当前批次的样本个数, 当前样本的序列长度(单词个数), 词嵌入维度影),比如[1,3,5]。
h0:隐藏层数据,shape为(隐藏层层数, 当前样本的序列长度(单词个数), 隐藏层中神经元数量),比如[1,3,6]。
[Xt,ht-1]:通过concat(Xt,ht-1)把[1,3,5]和[1,3,6]进行列维度(最后一个维度)的拼接变成[1,3,11]。
Wt[Xt,ht-1]:concat拼接后的[1,3,11]乘以Wt的[11,6]变成[1,3,6]。
output是hn隐藏层中的最后一层输出,比如:
当隐藏层只有一层时,rnn的输出output和隐藏层数据hn 两者完全相同,shape均为[1,3,6]。
当隐藏层有多层时,rnn的输出output为隐藏层数据hn中的最后一个二维矩阵,比如hn为[2,3,6],output的数据实际为hn中最后一个二维矩阵[1,3,6]。

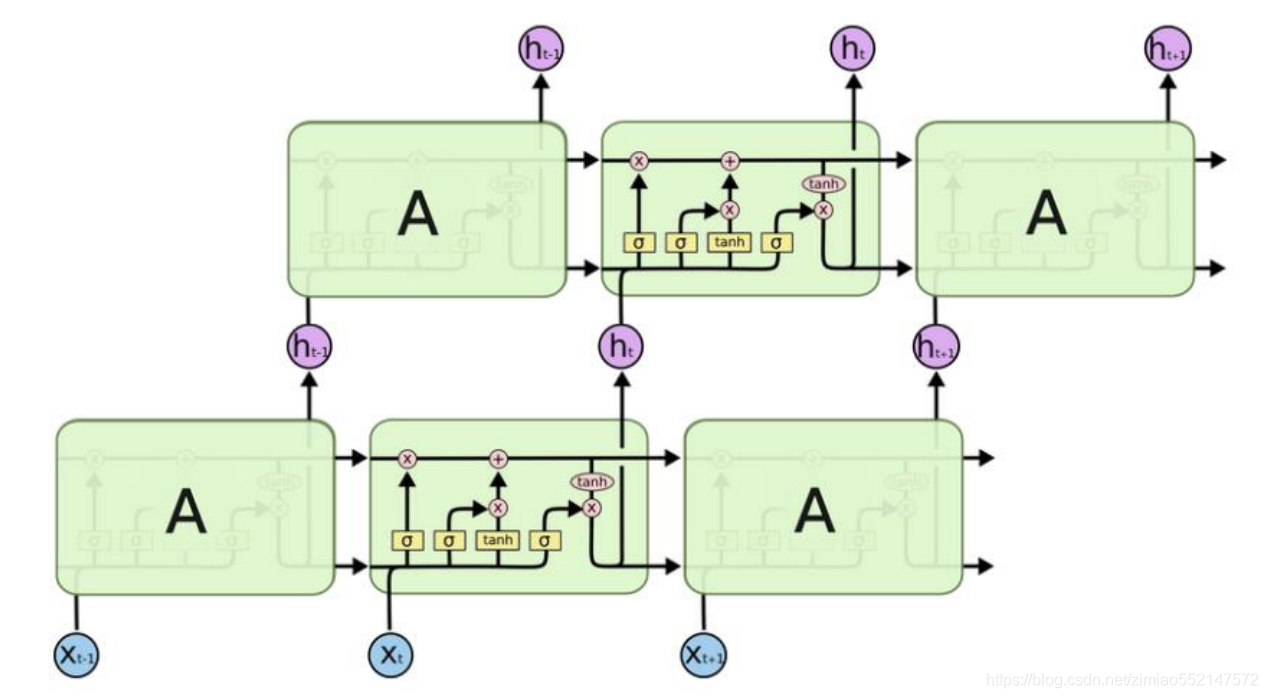
LSTM
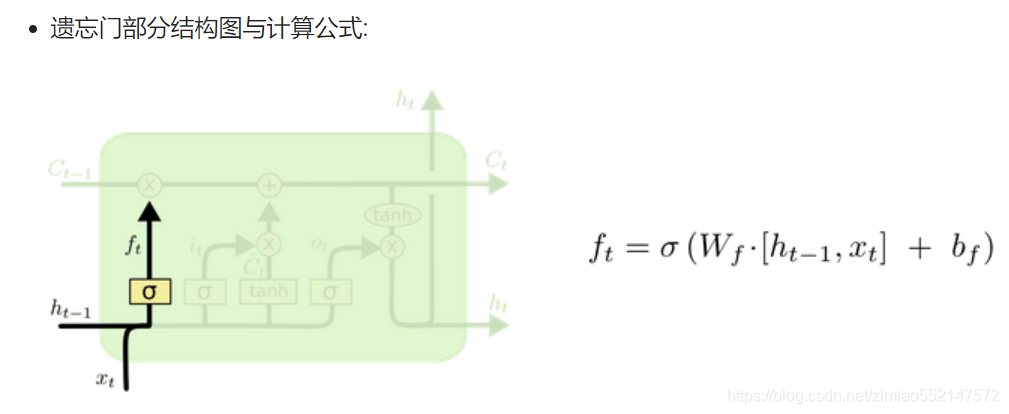
1.激活函数sigmiod的作用:用于帮助调节流经网络的值, sigmoid函数将值压缩在0和1之间的小数值(相当于一个百分比值)。
只要是sigmiod输出的百分比值(比如ft/it/ot) 都可作为控制阈值(保留信息比例值),用于控制流经的数据保留多少。
2.比如此处的遗忘门中的通过sigmiod输出的ft便是一个0和1之间的小数值,ft用作在“细胞状态更新公式”中的ft*Ct-1,
因为ft本身就是一个0和1之间的小数值(相当于一个百分比值),那么ft*Ct-1表示使用ft这个百分值保留多少Ct-1的值。

1.激活函数sigmiod的作用:用于帮助调节流经网络的值, sigmoid函数将值压缩在0和1之间的小数值(相当于一个百分比值)。
只要是sigmiod输出的百分比值(比如ft/it/ot) 都可作为控制阈值(保留信息比例值),用于控制流经的数据保留多少。
2.比如此处输入门中的通过sigmiod输出的it便是一个0和1之间的小数值,it用作在“细胞状态更新公式”中的it*Ct~,
因为it本身就是一个0和1之间的小数值(相当于一个百分比值),那么it*Ct~表示使用it这个百分值保留多少Ct~的值。
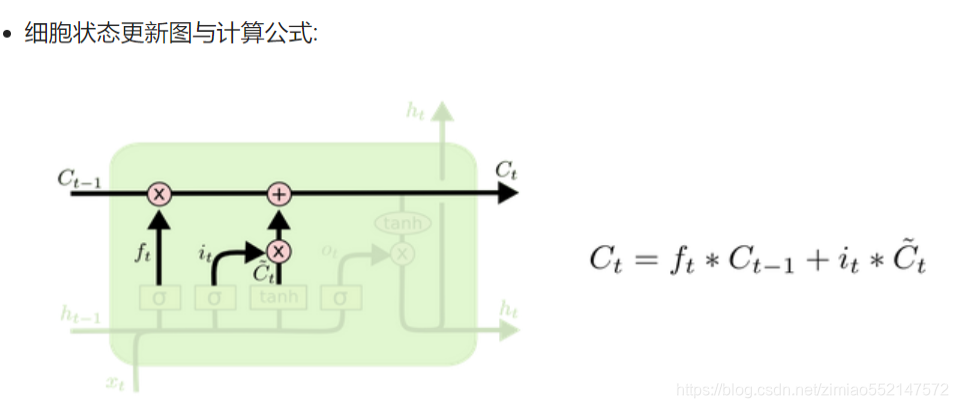
1.激活函数sigmiod的作用:用于帮助调节流经网络的值, sigmoid函数将值压缩在0和1之间的小数值(相当于一个百分比值)。
只要是sigmiod输出的百分比值(比如ft/it/ot) 都可作为控制阈值(保留信息比例值),用于控制流经的数据保留多少。
2.比如输入门中的通过sigmiod输出的it便是一个0和1之间的小数值,it用作在“细胞状态更新公式”中的it*Ct~,
因为it本身就是一个0和1之间的小数值(相当于一个百分比值),那么it*Ct~表示使用it这个百分值保留多少Ct~的值。
3.比如遗忘门中的通过sigmiod输出的ft便是一个0和1之间的小数值,ft用作在“细胞状态更新公式”中的ft*Ct-1,
因为ft本身就是一个0和1之间的小数值(相当于一个百分比值),那么ft*Ct-1表示使用ft这个百分值保留多少Ct-1的值。
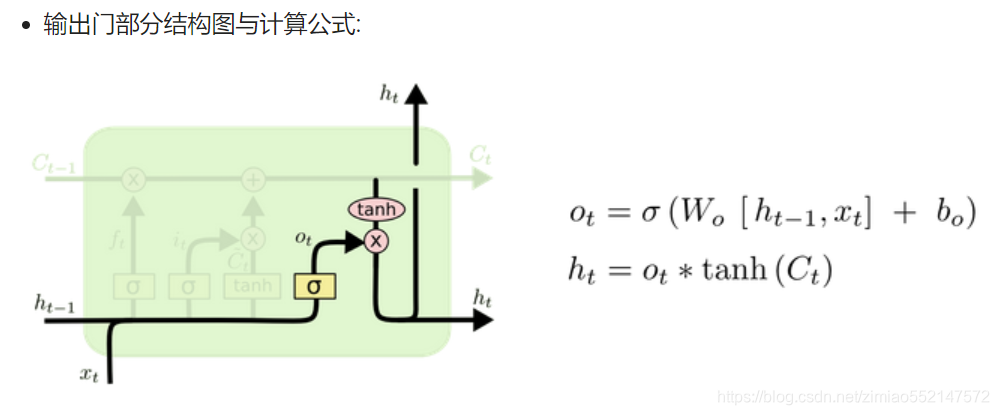
1.激活函数sigmiod的作用:用于帮助调节流经网络的值, sigmoid函数将值压缩在0和1之间的小数值(相当于一个百分比值)。
只要是sigmiod输出的百分比值(比如ft/it/ot) 都可作为控制阈值(保留信息比例值),用于控制流经的数据保留多少。
2.比如此处输出门中的通过sigmiod输出的ot便是一个0和1之间的小数值,ot用作在“输出门更新公式”中的ot*tanh(Ct),
因为ot本身就是一个0和1之间的小数值(相当于一个百分比值),那么ot*tanh(Ct)表示使用ot这个百分值保留多少tanh(Ct)的值。


GRU

