Vanilla RNN
参考 RNN wiki 的描述,根据隐层

- Elman network 接受上时刻的隐层
ht−1 - Jordan network 接受上时刻的输出
yt−1
但是看了很多的教程,感觉应用最多的还是 Elman network 的做法。比如 WILDML: RECURRENT NEURAL NETWORKS TUTORIAL 画出来的示意图:

还有 Andrej Karpathy 的博客 The Unreasonable Effectiveness of Recurrent Neural Networks 的实现,也是接收上一时刻隐层的结果,图就不贴了。
Bidirectional RNNs
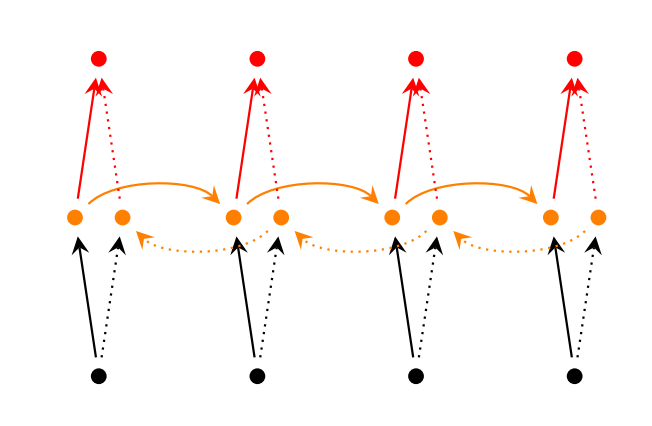
双向的 RNN 是同时考虑“过去”和“未来”的信息,考虑上图,正常情况下,输入(黑色点)沿着黑色的实线箭头传输到隐层(黄色点),再沿着红色实线传到输出(红色点)。黑色实线做完前向传播后,在 Bidirectional RNNs 却先不急着后向传播,而是从末尾的时刻沿着虚线的方向再回传回来。最后把两个方向得到的激活值拼在一起(concatenate),当做最后的激活值。那么后向传播也是类似,要转一圈回来。
Stacked Bidirectional RNNs
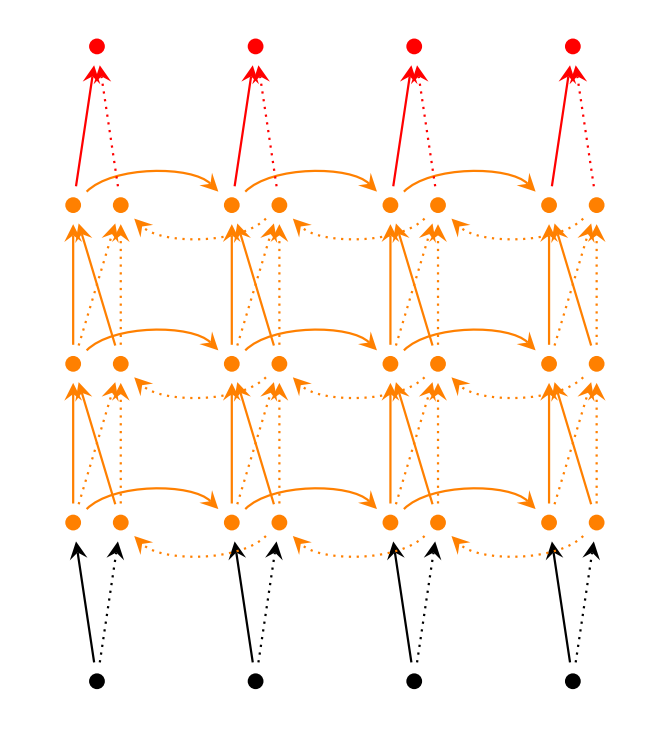
堆多层的 recurrent layer,如上图所示,可以增加模型的参数,提高模型的学习能力。每层的 hidden state 不仅要输给下一时刻,还是当做是此时刻下一层的输入。上图展示了双向的三层 RNNs,那么 hidden state 的维度是 hidden_dim * 6,输出的维度为 hidden_dim * 2,因为是两个方向最有一层 hidden state 拼接的结果。
原始的 RNN 很难训练,主要是因为存在梯度消失(gradient vanishing problem)和梯度爆炸问题(gradient explosion problem)。梯度消失导致无法抓住长时刻依赖,因此效果不好,后面的 LSTM 和 GRU 的新结构,就是为了对付这个问题。而梯度爆炸问题虽然不是每次都出现,但是一旦出现就很致命。一般会选择用截断的梯度(clipped gradient)来更新参数,或者直接把梯度 rescale 到一个固定模大小的范围。
LSTM
由于 Vanilla RNN 具有梯度消失问题,对长关系的依赖(Long-Term Dependencies)的建模能力不够强大。这句话是什么意思呢?就是说,原来的 RNN,由于结构上的限制,很长的时刻以前的输入,对现在的网络影响非常小,后向传播时那些梯度,也很难影响很早以前的输入,即会出现梯度消失的问题。而 LSTM 通过构建一些门(Gate),让网络能记住那些非常重要的信息,而这个核心的结构,就是 cell state。比如遗忘门,来选择性清空过去的记忆和更新较新的信息。
上面讲的比较迷糊,如果我有新的理解会更新这个博客。另外可以参考大神的博客 Understanding LSTM Networks,把 LSTM 讲的深入浅出,并且提到了很多的变种和展望。
有两种常见的 LSTM 结构,如 LSTM wiki 总结的,第一种是带遗忘门的 Traditional LSTM,公式如下:

前三行是三个门,分别是遗忘门
注意这里的输出
有时候第四个公式里的
第二种是带遗忘门的 Peephole LSTM,公式如下,

和上面的公式做比较,发现只是把
还有把两种结构结合起来的,可以用下图描述,
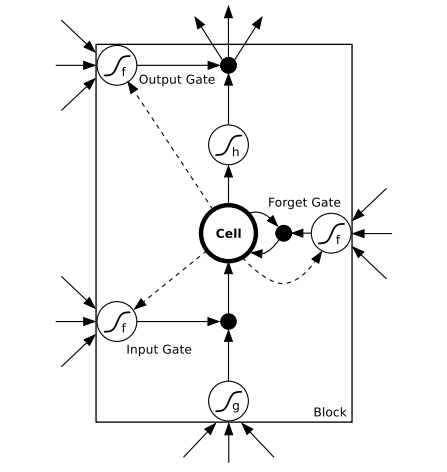
图里的连着门的那些虚线就是窥视孔。三个输入分别是
GRU
GRU 这个结构是 2014 年才出现的,效果堪比 LSTM,但是用到的参数更少。见论文 Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling 和 An Empirical Exploration of Recurrent Network Architectures 对 LSTM 和 GRU 这两种结构的比较。
GRU 的结构和 LSTM 类似,但是精简一些,见下图
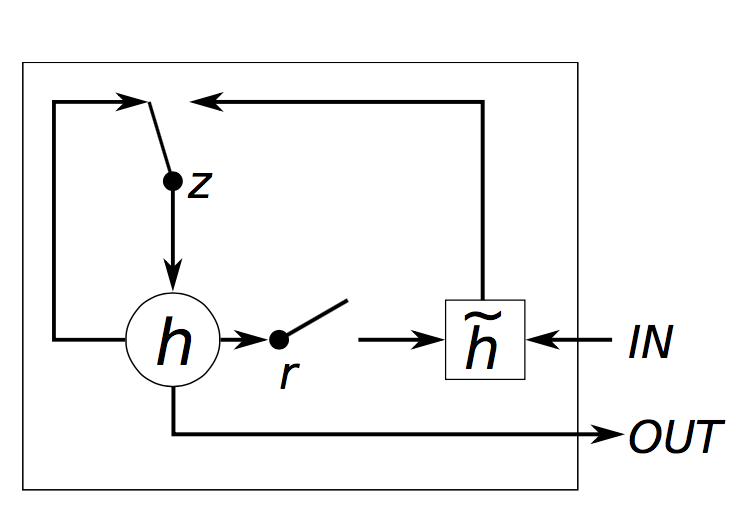
公式如下:
这四行公式解释如下:
-
zt 是 update gate,更新 activation 时的逻辑门 -
rt 是 reset gate,决定 candidate activation 时,是否要放弃以前的 activationht -
h˜t 是 candidate activation,接收[xt,ht−1] -
ht 是 activation,是 GRU 的隐层,接收[ht−1,h˜t]
论文 [8] 和 [9] 详细对比了 LSTM 和 GRU 以及传统的 RNN 的异和同,探讨了这些结构的好处。从 LSTM 和 GRU 的公式里可以看出,都会有门操作,决定是否保留上时刻的状态,和是否接收此时刻的外部输入,LSTM 是用遗忘门(forget gate
这种设计有两个解释,一个解释是说,网络是能很容易地记住长依赖问题。即前面很久之前出现过一个重要的特征,如果遗忘门或者更新门选择不重写(overwritten)内部的 memory,那么网络就会一直记住之前的重要特征,那么会对当前或者未来继续产生影响。另一点是,这种设计可以为不同状态之间提供一条捷径(shortcut),那么梯度回传的时候就不会消失的太快,因此减缓了梯度消失带来的难训练问题。
LSTM 和 GRU 也有一些重要的不同点。首先就是 LSTM 有一个输出门来控制 memory content 的曝光程度(exposure),而 GRU 则是直接输出。另一点是要更新的 new memory content 的来源也不同。
论文还用实验证明了相同个数参数的情况下,GRU 会比 LSTM 稍好一些。但是两种因为能抓住 Long-Term Dependencies,所以都比 Vanilla RNN 要好很多。
Reference:
1. LSTM wikipedia
2. WILDML RNN Tutorial
3. Pytorch Recurrent Layers
4. The Unreasonable Effectiveness of Recurrent Neural Networks
5. Understanding LSTM Networks
6. Supervised Sequence Labelling with Recurrent Neural Networks
7. A Critical Review of Recurrent Neural Networks for Sequence Learning
8. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
9. An Empirical Exploration of Recurrent Network Architectures