RNN
RNN最重要的是特征就是每一时刻的结构和参数都是共享的。
先放一张盗图

RNN就好像天生为序列而生的神经网络,举个简单的例子,序列标注,比如词性标注,如图所示,x是我们输入,h是我们的输出,也就是词性。有人可能就会说,我们使用一般的神经网络也可以做到这样。
一个词一个样本就可以了,这里的话就破坏了句子的连贯性,那些多词性的还怎么标注呢。
恩达是这么说的:
一个像这样单纯的神经网络结构(普通的dense),它并不共享从文本的不同位置上学到的特征。具体来说,如果神经网络已经学习到了在位置1出现的Harry可能是人名的一部分,那么如果Harry出现在其他位置,比如x^(t)时,它也能够自动识别其为人名的一部分的话,这就很棒了。
RNN的前向后向传播
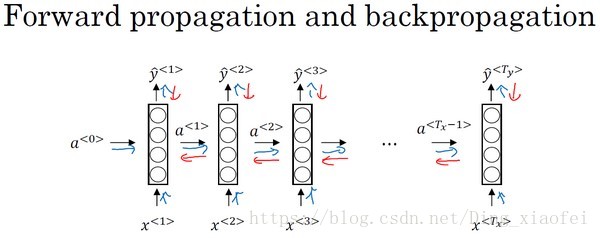
最终的损失是每个t的损失之和,反向计算也如图所示。
RNN的类型
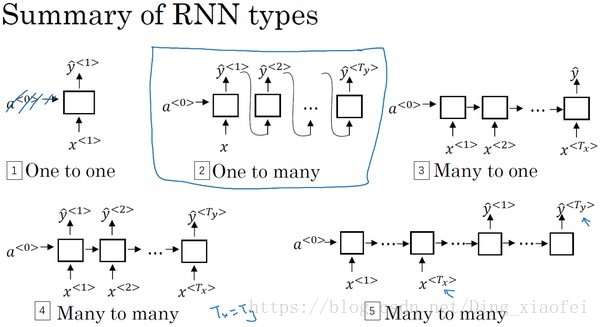
one to many可以做文本生成
many to one 做文本分类
many to many 做序列标注
many to many 机器翻译呀
LSTM
先放一篇博客,是第一个让我懂LSTM的博客。还有一个就是李宏毅的视频,b站搜李宏毅就能找到。
这边我会综合两个人的内容来复述LSTM
先看宏毅大神的结构图
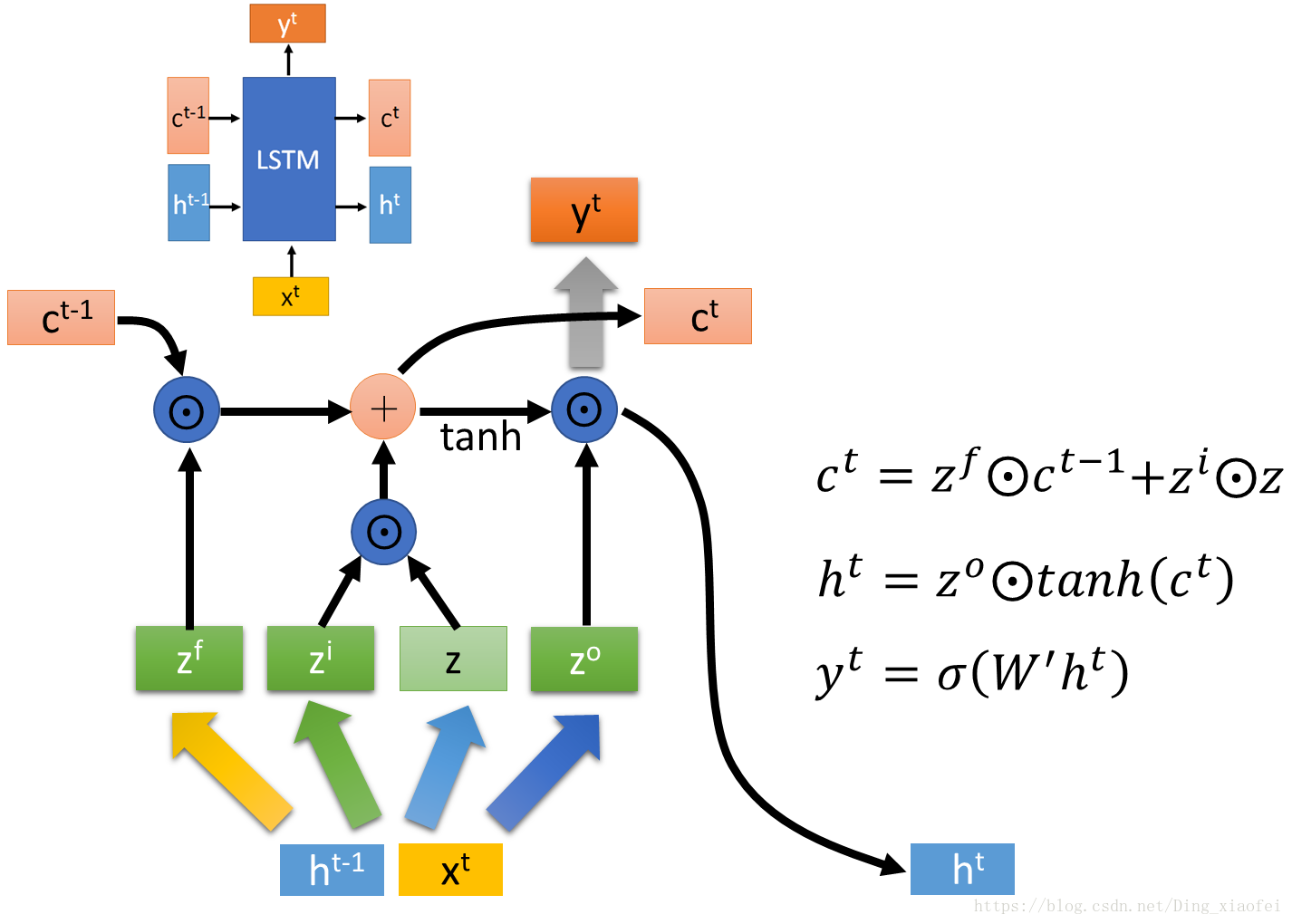
lstm里面最主要的就是c和h,这两个对应的就是长短记忆,c对应的是长记忆,变化比较慢,h对应的是短记忆,变化比较迅速。h可以迅速记住新的东西,对应到当前时刻的输出。
首先我们还是接受两个拼接向量(h(t-1),x(t))生成4个z, f代表的是forget gate,表示我们要遗忘前一刻c中的一些内容,i代表的是input gate,表示的是我们要新加入的一些内容,新加入的内容从z中选择,这些gate都是由sigmoid函数控制的。h由一个output gate控制去c中选择合适的内容输出。核心的公式就是图中的三个。如果对这个过程有不理解的可以去看我放出的博客,或者留言。
稍微总结一下,LSTM核心还是c,主要是forget gate 和 input gate去控制每一个时刻c的内容,c的内容也间接决定了h和此时刻最终的输出。h是要和x拼在一起决定很多门的范围的,所以它是变化迅速,容易遗忘很久之前的记忆,它像是内存,而c更像是一个硬盘。
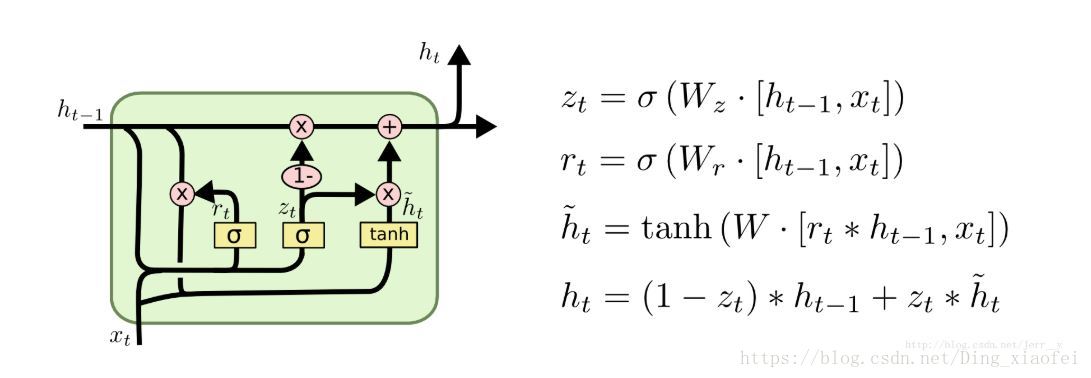
GRU
语言模型
语言模型本质上就是一个判断句子是否合理的模型,以概率的形式返回,举个简单的例子:
比如你在做一个语音识别系统,你听到一个句子,“the apple and pear(pair) salad was delicious.”,所以我究竟说了什么?我说的是 “the apple and pair salad”,还是“the apple and pear salad”?(pear和pair是近音词)。你可能觉得我说的应该更像第二种,事实上,这就是一个好的语音识别系统要帮助输出的东西,即使这两句话听起来是如此相似。而让语音识别系统去选择第二个句子的方法就是使用一个语言模型,他能计算出这两句话各自的可能性。