1、为什么需要递归神经网络?
- RNN可以考虑上下文关系,语序
- RNN可以减少参数量,减少模型复杂度
- 可以处理不同时长的数据
2、Recurrent Neural Network——递归神经网络
2.1 构造语言模型
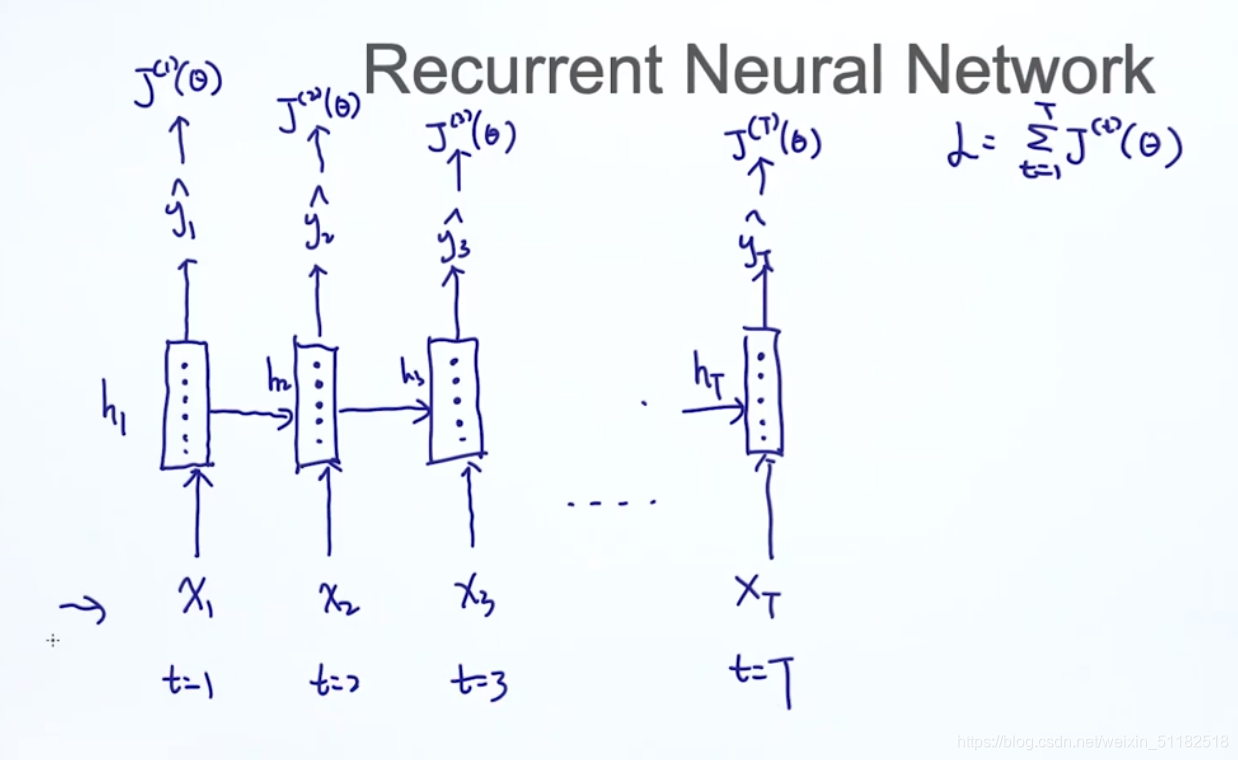
2.2 对于情感分析只需要在最后时刻将rnn cell的输出接入一个softmax
2.3 RNN formulation
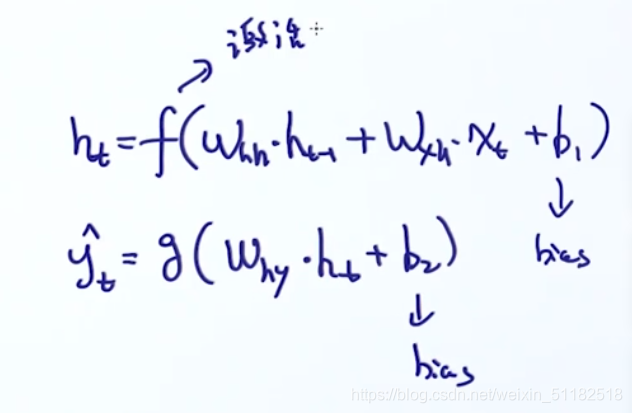
线性的转换+非线性激活函数
2.4 RNN vs HMM
在hmm中,每一个时刻只有一个状态被激活。RNN每个时刻的每个状态都是一个连续性的随机变量——分布式表示方法。深度学习基本都是分布式的表示方法
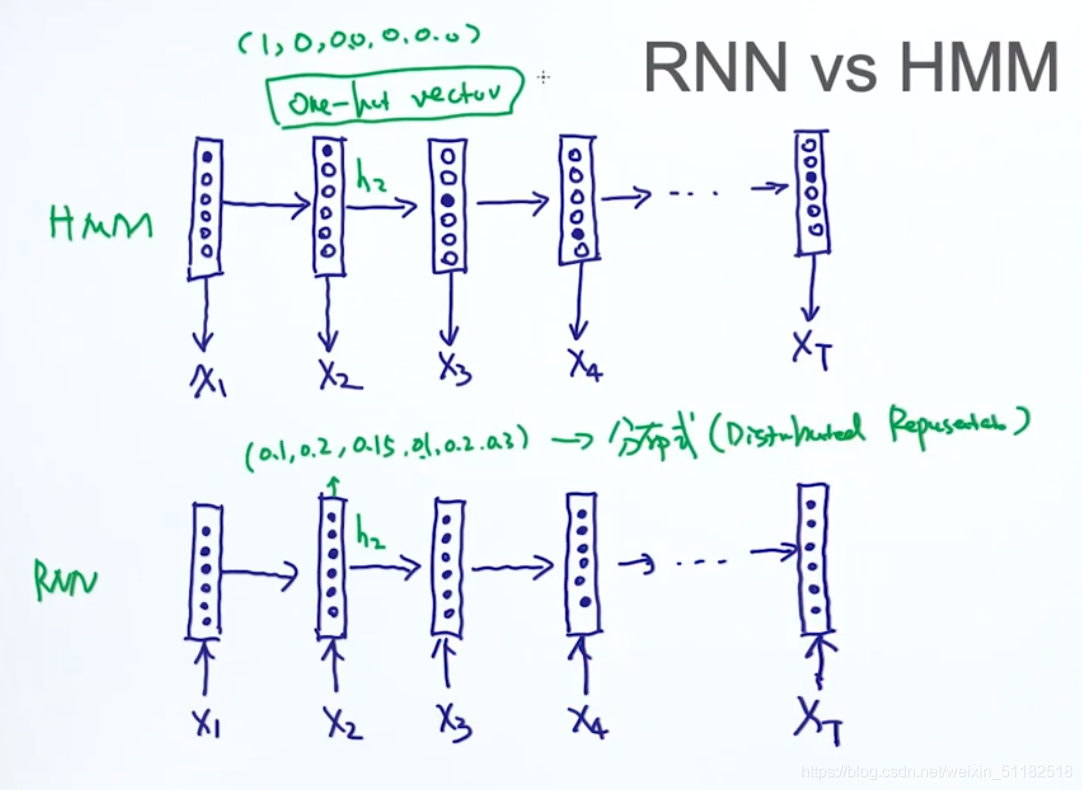
one- hot encoding:
- sparse
- 不需要学习
- 状态转移矩阵会非常大
distributed representation - non-sparse/compact
- 需要训练学习
3、Recap:语言模型

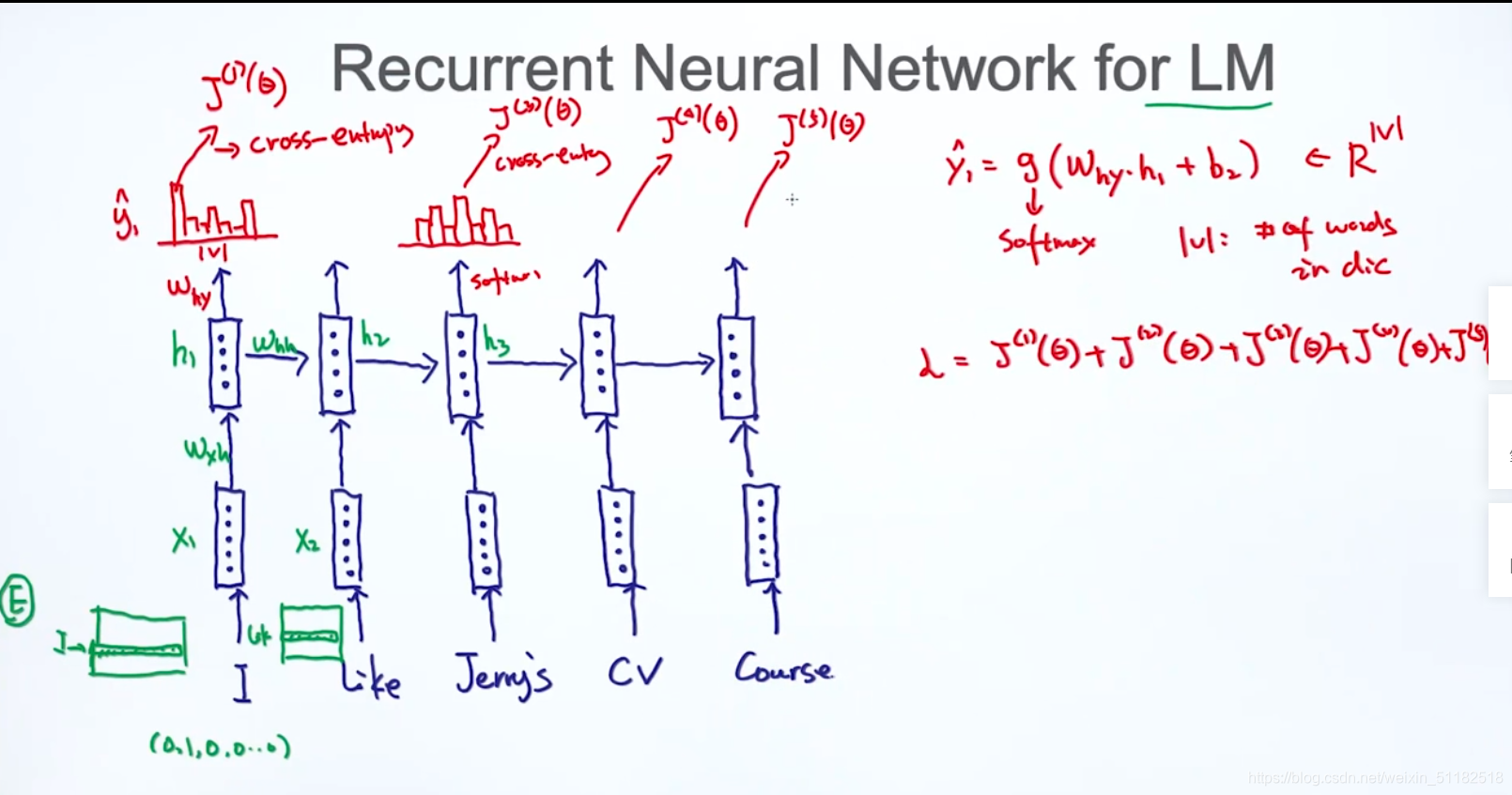
4、RNN的语言模型
-
1、先对每一个word做word embedding
-
2、输入rnn cell
-
3、输出每个时刻的output
-
4、y输出的是给定当前单词,下一个单词出现的概率分布
-
5、针对一个sentence,损失函数是每个时刻loss的叠加
从时间维度上,rnn是deep model。对于每个时刻,隐式表达层上RNN也可以deep
5、RNN gradient vanishing and exploding
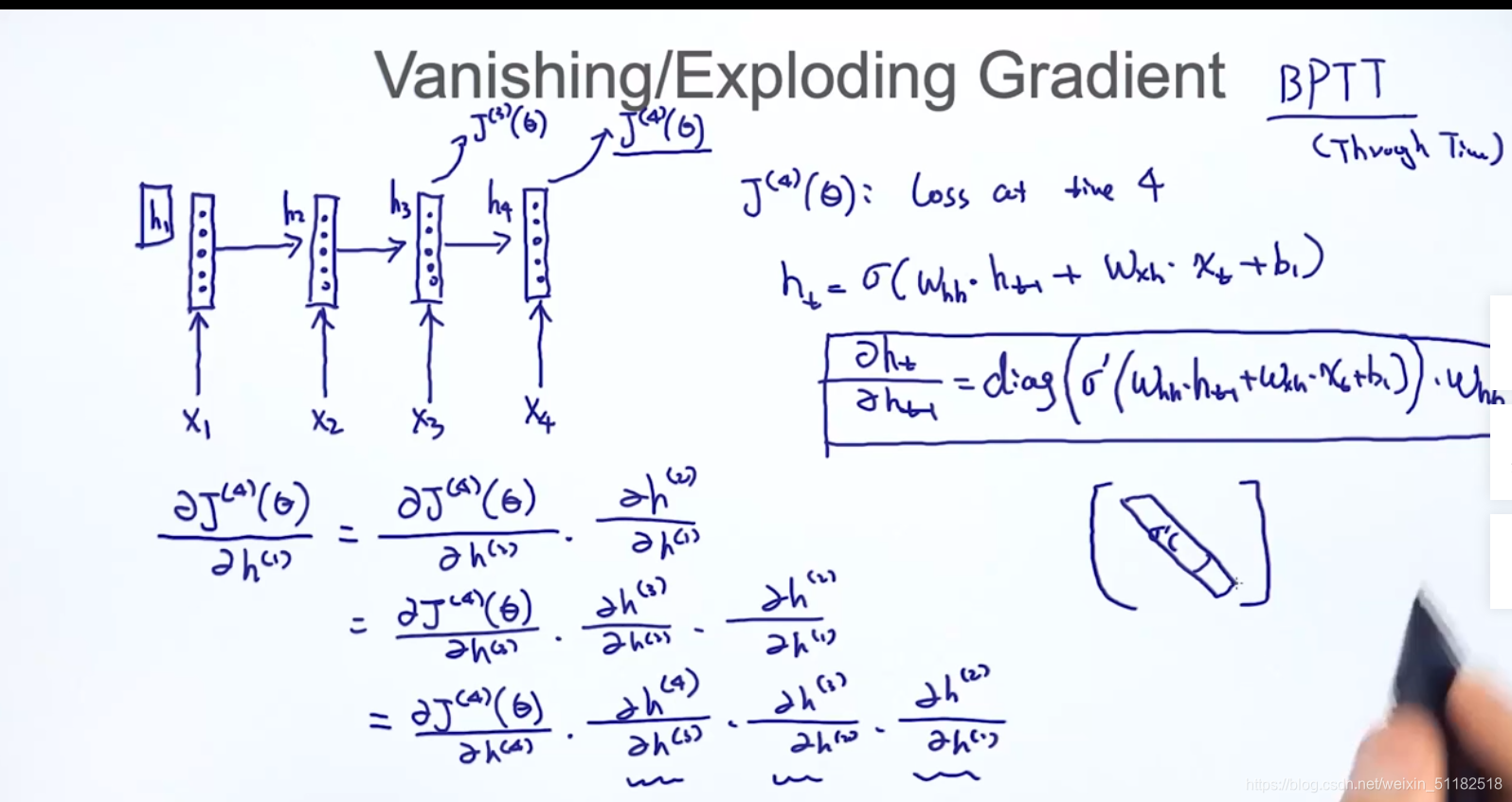
在计算梯度时,需要求出每个时刻的h对上一时刻的h,当对于rnn前几个时刻的梯度计算时, w h h w_{hh} whh的t次方项参与了计算。

- w h h w_{hh} whh> 1 发生梯度爆炸
- w h h w_{hh} whh <1 发生梯度消失
Long-term dependency
当句子太长时,rnn模型由于梯度计算的问题,很难捕获到很前面的单词和当前单词的关系。

对于第二个例子,空格时刻的词的选择更依赖于上一个时刻而不是更前面的几个时刻
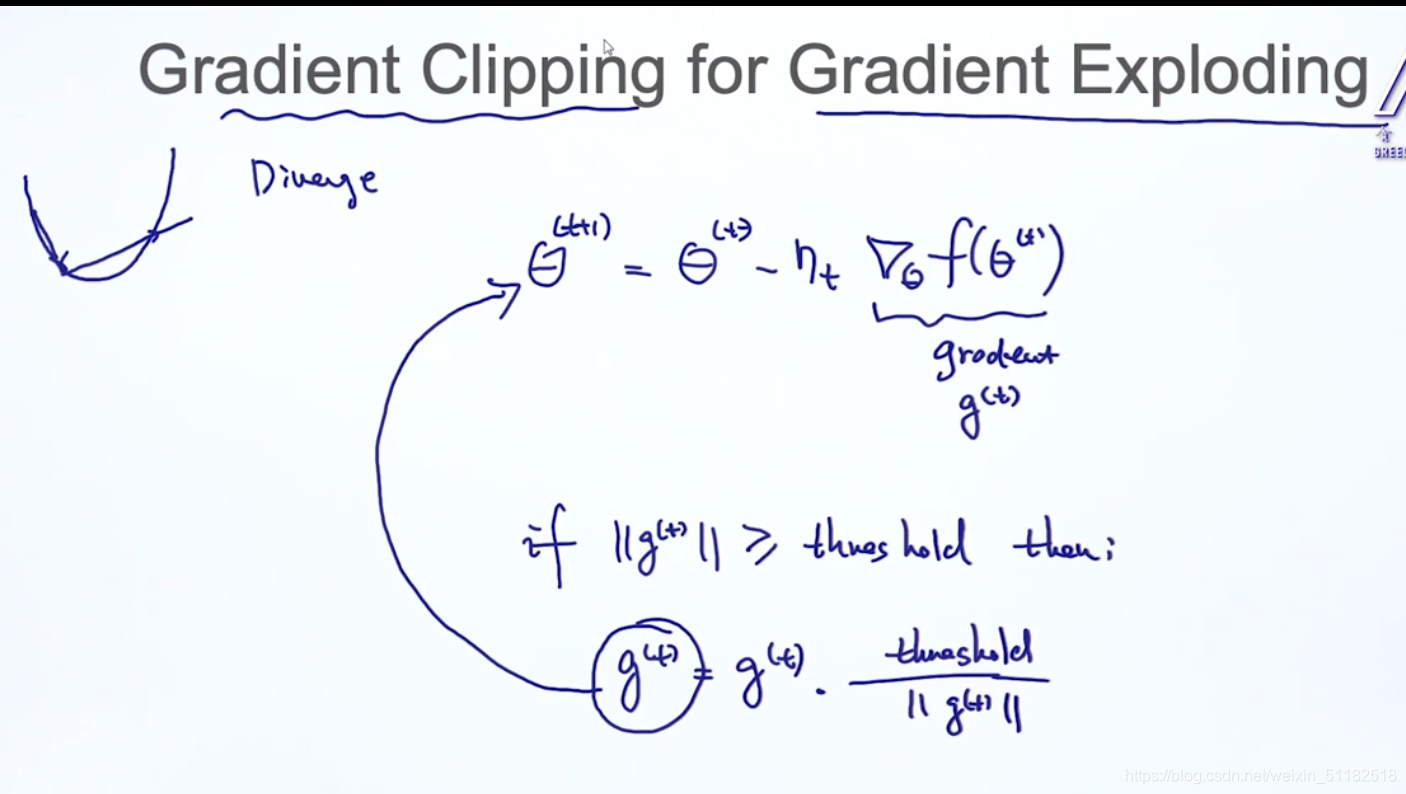
6、Gradient clipping——solve gradient exploding
设置阈值,当当前梯度大于阈值时,对当前时刻的梯度除以梯度的norm再乘阈值限制梯度的值。
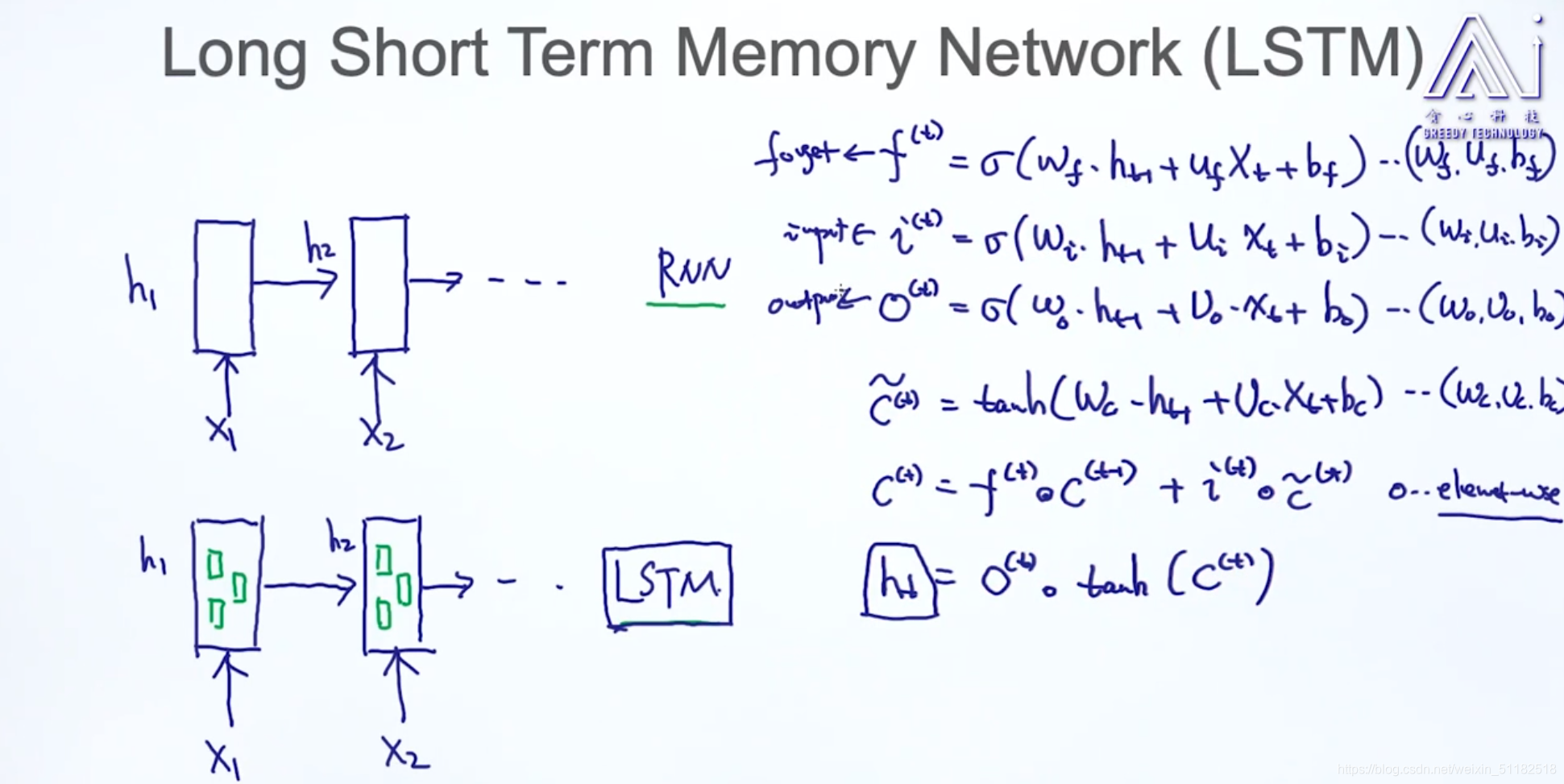
7、LSTM
7.1 LSTM的内部结构:三个门
7.2 LSTM的应用
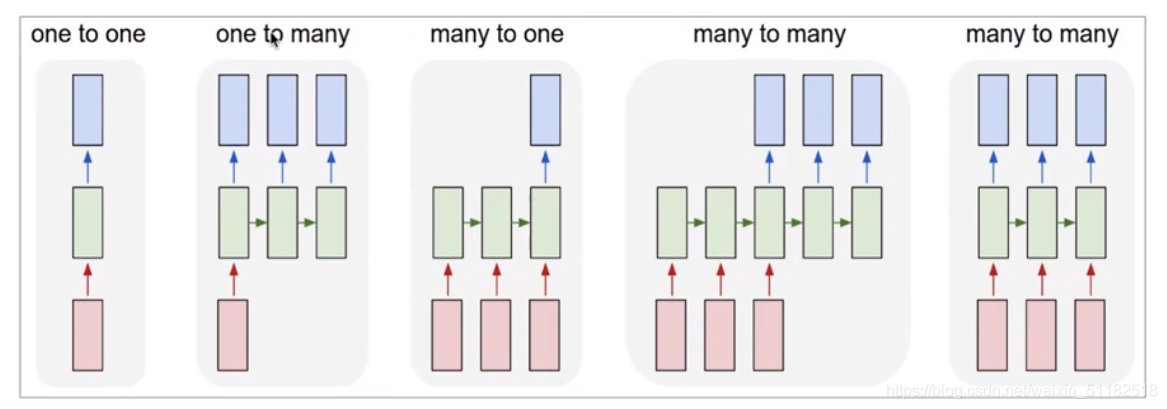
1、one to one:适合做图像模型 image classification
2、one to many:只有第一个时刻有输入,适合做image captioning,看图说话,根据图像生成文本
3、many to one:粉色代表text,蓝色代表分类,适合sentiment classification等分类,情感分析
4、many to many:机器翻译,seq2seq模型
5、many to many:针对每个输入都有相应输出:语言模型,NER识别
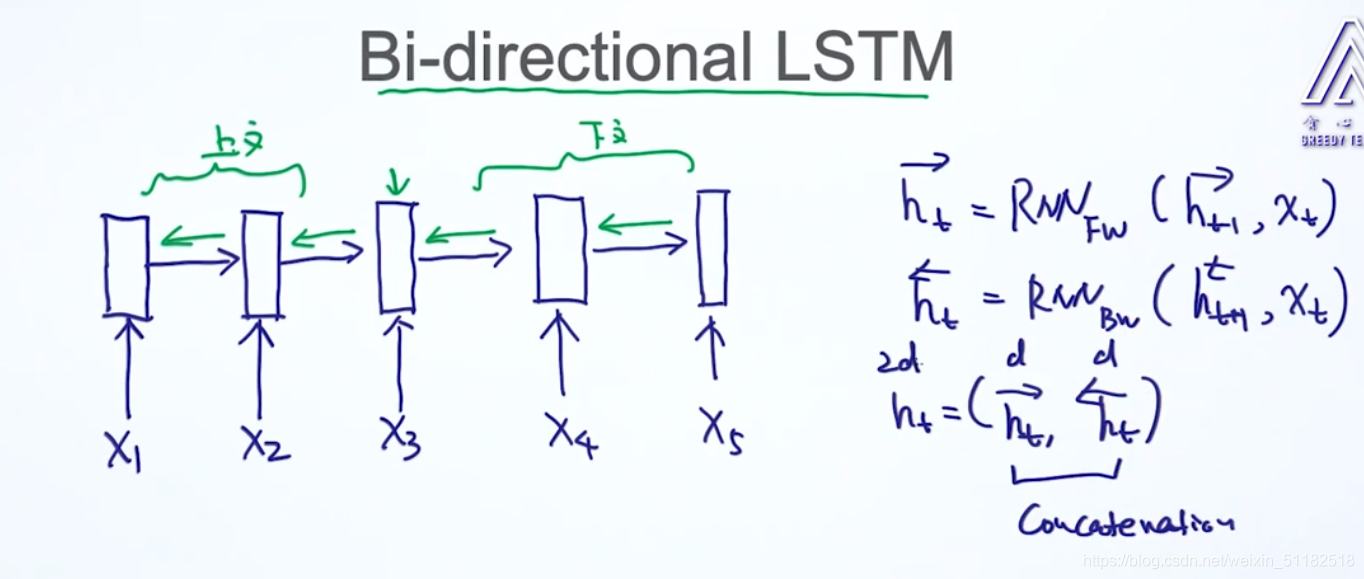
7.3 Bi-directional(双向) LSTM
对于当前时刻t的结果,不止考虑前几个时刻还要考虑后面几个时刻的memory的影响。可以完全考虑上下文,准确率会高。更好地捕获长时序的关系。
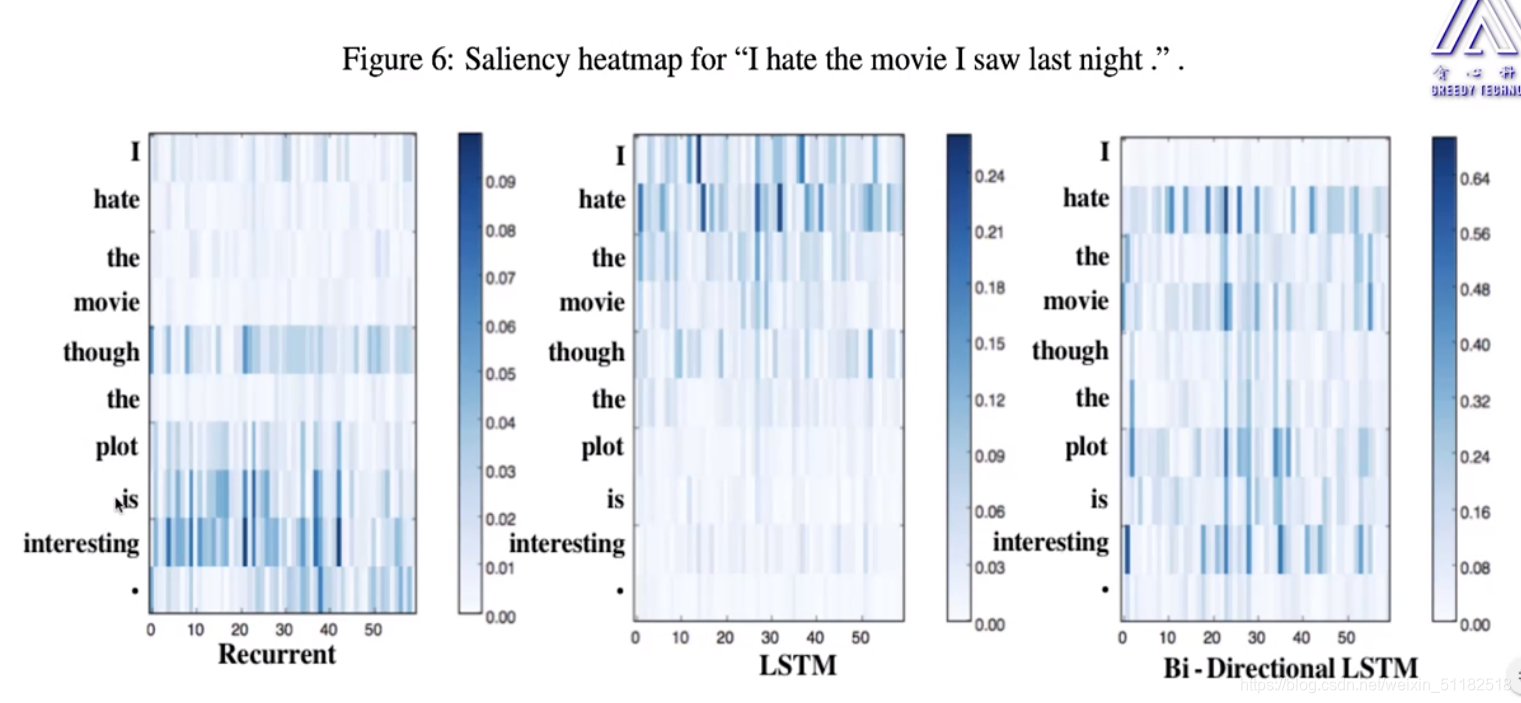
- RNN捕获到后几个时刻的单词信息,但由于梯度消失,很难捕获到前面时刻的单词信息
- LSTM对于前几个单词更加敏感,可能是由于forget gate 的关闭导致前面的memory 被清洗,所以后面单词针对前几个单词的memory不明确。
- Bi-directional LSTM 弥补了RNN和LSTM各自的缺点。
8、GRU ——Gated Recurrent Unit
只有两个门,复杂度低于LSTM,效果与LSTM类似。
- update gate 控制input
- reset:类似于forget gate,决定是否抽取上一个时刻的h

对于当前时刻的output:
- 对于当前时刻输入端计算出的output
- 对于之前时刻计算保留的memory
- u控制上面两部分对于当前时刻总output的贡献比。