RNN
在循环神经网络(RNN)中,神经元的输出在下一时刻是可以传递给自身的,可以对时间序列建模。很多任务的时间序列信息很重要,即一个样本中前后输入的信息是有关联的。样本出现时间顺序信息对语音识别、自然语言处理等问题很重要,所以对于这类问题,可以使用循环神经网络(Recurrent Neural Network)来对其建模。
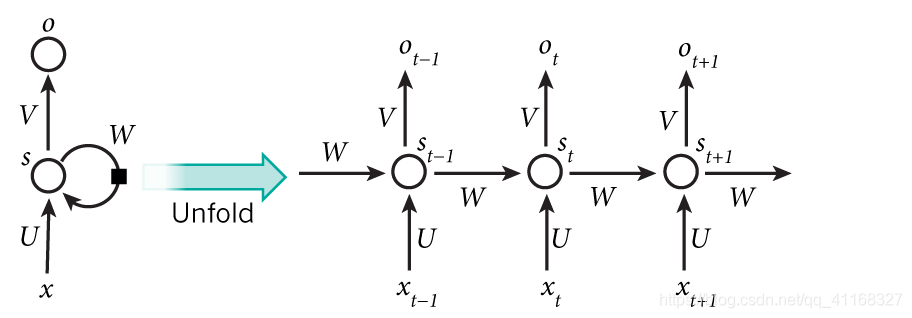
先看上图左侧部分,x、s、o都是向量,分别表示输入层、隐藏层和输出层的值。U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵,W是上一时刻的隐藏层s作为下一时刻输入的权重矩阵。把W去掉这其实就是一个简单的全连接神经网络。
上图右半部分,是左侧图按时刻展开的图,看起来更直观。相较于全连接神经网络,隐藏层的值不仅取决于,还取决于上一时刻的隐藏值
下面是RNN的计算公式:
式1是隐藏层的计算公式,f是激活函数,U是输入层到隐藏层的权重矩阵,W是上一时刻的隐藏层到当前时刻隐藏层 的权重矩阵,b是偏差向量。DNN与RNN的区别就在于式1,即隐藏层不同,DNN的式1没有这一项,RNN有了这一项,就有了上图左侧中,隐藏层s的时间循环(也即右侧的展开),所以称之为循环神经网络。
式2是输出层的计算公式,g是激活函数,V是隐藏层到输出层的权重矩阵,c是偏差向量,该层是一个全连接层。
因为时刻t的输出不仅取决于之前时刻的信息,还取决于未来的时刻,所以有了双向RNN
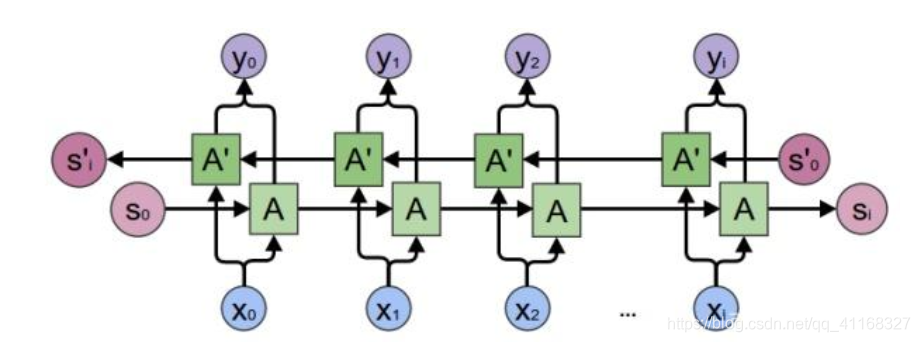
可以看出,每个时刻有一个输入,隐藏层有两个节点(向量),一个进行正向计算,另一个进行反向计算,输出层由这两个值决定。
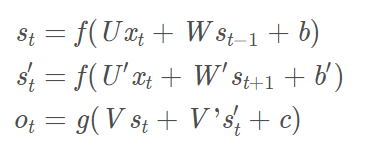
正向传播分两步完成:
1、我们从左向右移动,从初始时间步骤开始计算值,一直持续到到达最终时间步骤为止;
2、我们从右向左移动,从最后一个时间步骤开始计算值,一直持续到到达最终时间步骤为止;
感谢 https://blog.csdn.net/huwenxing0801/article/details/84894238
LSTM
长短时记忆网络(Long Short Term Memory Network, LSTM),是一种改进之后的循环神经网络,可以解决RNN无法处理长距离的依赖的问题.
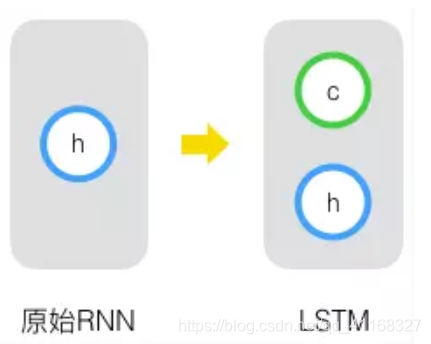
原始 RNN 的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。
再增加一个状态,即c,让它来保存长期的状态,称为单元状态(cell state)。
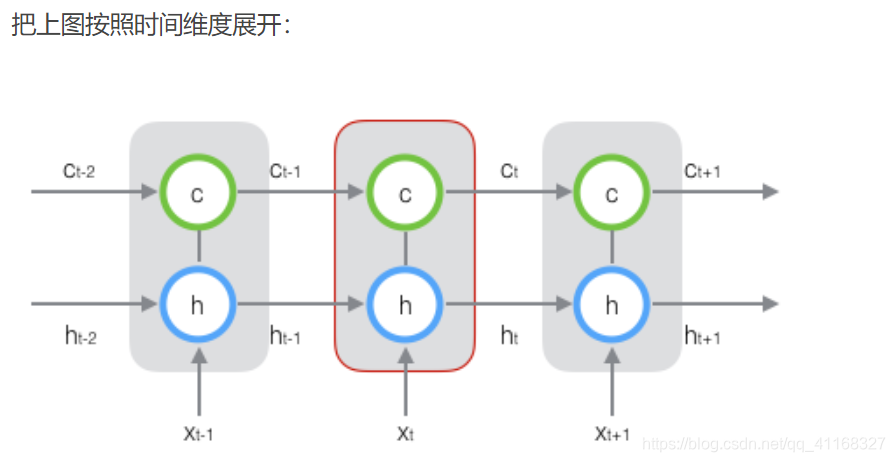
在 t 时刻,LSTM 的输入有三个:当前时刻网络的输入值 x_t、上一时刻 LSTM 的输出值 h_t-1、以及上一时刻的单元状态 c_t-1;
LSTM 的输出有两个:当前时刻 LSTM 输出值 h_t、和当前时刻的单元状态 c_t
怎样控制长期状态 c ?
方法是:使用三个控制开关
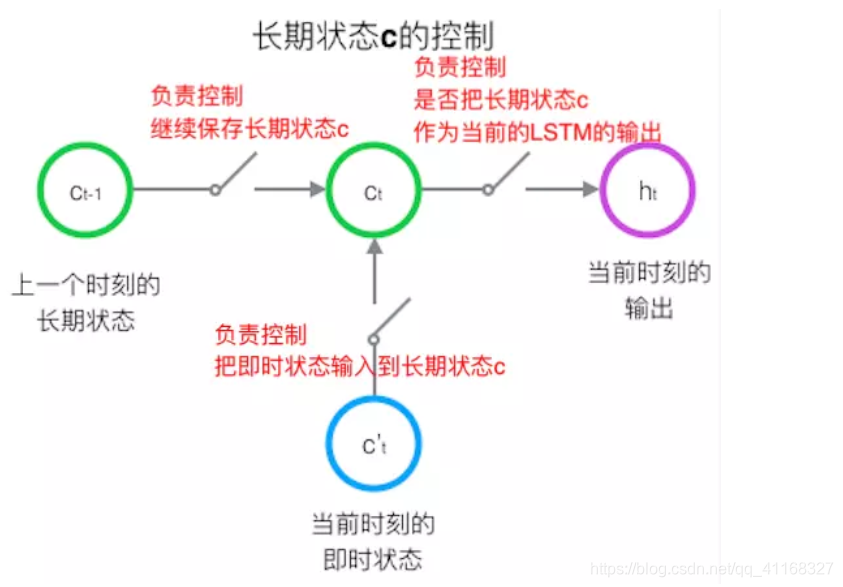
第一个开关,负责控制继续保存长期状态c;
第二个开关,负责控制把即时状态输入到长期状态c;
第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。
如何在算法中实现这三个开关?
方法:用 门(gate)
定义:gate 实际上就是一层全连接层,输入是一个向量,输出是一个 0到1 之间的实数向量。
公式为:
回忆一下它的样子:

gate 如何进行控制?
方法:用门的输出向量按元素乘以我们需要控制的那个向量
原理:门的输出是 0到1 之间的实数向量,
当门输出为 0 时,任何向量与之相乘都会得到 0 向量,这就相当于什么都不能通过;
输出为 1 时,任何向量与之相乘都不会有任何改变,这就相当于什么都可以通过。
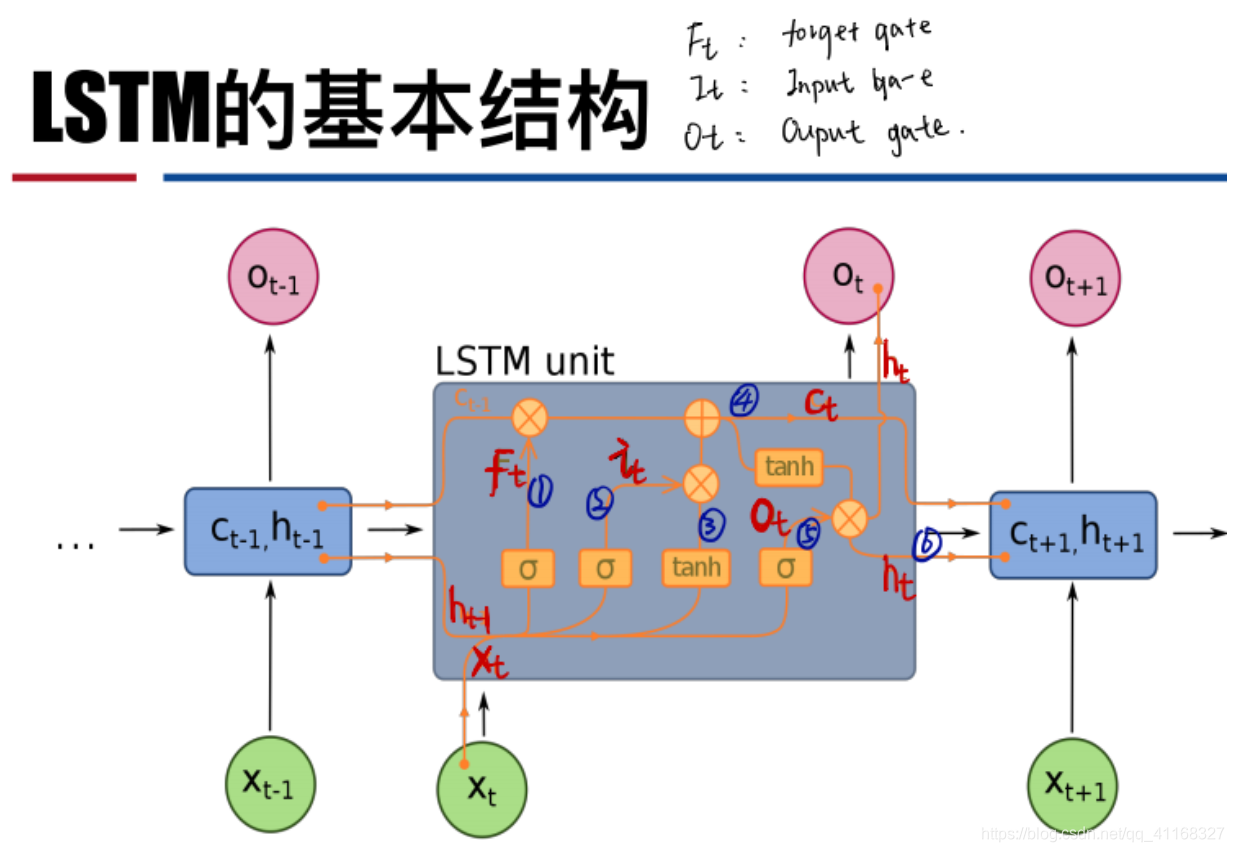
LSTM 的前向计算:
遗忘门(forget gate)
它决定了上一时刻的单元状态 c_t-1 有多少保留到当前时刻 c_t
输入门(input gate)
它决定了当前时刻网络的输入 x_t 有多少保存到单元状态 c_t
输出门(output gate)
控制单元状态 c_t 有多少输出到 LSTM 的当前输出值 h_t

LSTM 的反向传播训练算法:
-
前向计算每个神经元的输出值,一共有 5 个变量,计算方法就是前一部分:
-
反向计算每个神经元的误差项值。与 RNN 一样,LSTM 误差项的反向传播也是包括两个方向:
一个是沿时间的反向传播,即从当前 t 时刻开始,计算每个时刻的误差项;
一个是将误差项向上一层传播。 -
根据相应的误差项,计算每个权重的梯度。
感谢 https://www.cnblogs.com/chihaoyuIsnotHere/p/10604085.html
GRU
GRU模型中只有两个门:分别是更新门和重置门。具体结构如下图所示:
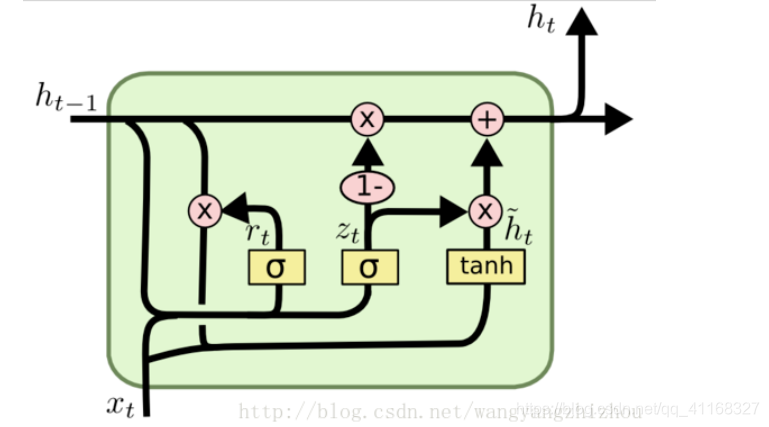
图中的zt和rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 上,重置门越小,前一状态的信息被写入的越少。
GRU前向传播:
其中[]表示两个向量相连接,*表示矩阵元素相乘。GRU的训练:
从前面的公式中可以看到需要学习的参数就是那些权重参数,其中前三个权重都是拼接的,所以在学习时需要分割出来,即
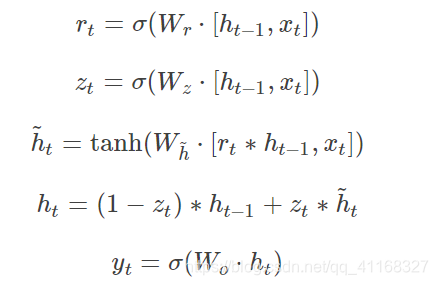

采用后向误差传播算法来学习网络,所以先得求损失函数对各参数的偏导(总共有7个):
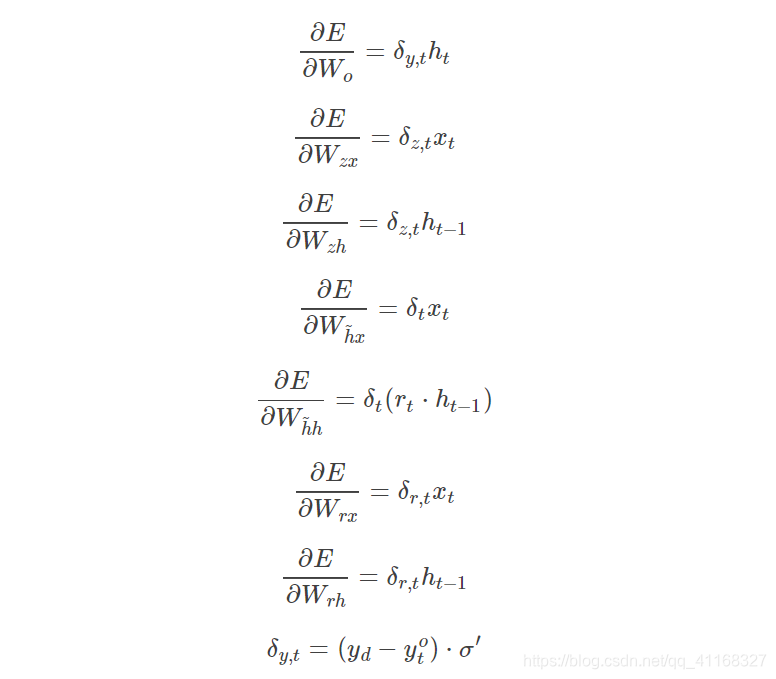
其中各中间参数为:

感谢 https://blog.csdn.net/wangyangzhizhou/article/details/77332582
