摘要:
本文用于总结整个RNN的学习过程以及学习资料。
RNN
1.下文是rnn利用Bptt的训练的推导过程。
RNN与bptt推导过程
2.rnn一些基本概念以及问题分析
参考文章-1
RNN中为什么要采用tanh而不是ReLu作为激活函数?
常见问题:
1.RNN是什么?
RNN是循环神经网络的简称。常用来对时间序列建模,具体来说就是一个序列当前的输出和前面的输出也有关,应用场景主要有自然语言处理、语音识别。
其内部与传统的神经网络最大的不同之处在于,RNN把上一个时刻隐藏层输出作为输入放到了下一个时刻中进行学习。以此希望学习到不同时刻之间的依赖关系。
2.RNN存在的问题是什么?
梯度消失和梯度爆炸。
3.RNN如何产生以及解决梯度消失?
产生的原因:
本质是由于反向传播中求解梯度的时候利用了链式法则。这会导致梯度被表示成连乘积的形式(在比较深的网络里,连乘的计算很容易就会导致数值趋于0或者趋于无穷,指数型的增长),另一方面隐藏层的激活函数也有关系,因为在反向传播的时候,每次往前传播都会乘以当前层的神经元的激活函数导数值,具体下面分析sigmoid函数。
对于sigmoid函数:
Sigmoid函数饱和使梯度消失。sigmoid神经元有一个不好的特性,就是当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0(而且sigmoid导数值最大0.25)。
回忆一下,在反向传播的时候,这个(局部)梯度将会与整个损失函数关于该门单元输出的梯度相乘。因此,如果局部梯度非常小,那么相乘的结果也会接近零,这会有效地“杀死”梯度,几乎就有没有信号通过神经元传到权重再到数据了。还有,为了防止饱和,必须对于权重矩阵初始化特别留意。比如,如果初始化权重过大,那么大多数神经元将会饱和,导致网络就几乎不学习了。
tanh激活函数也有sigmoid同样的问题。(因为两者的本质是把输出挤压到了某一个范围,自然就存在饱和的问题)
解决梯度消失:
1.改进网络结构,使用lstm
2.更换激活函数,使用relu。
4.RNN如何产生以及解决梯度爆炸?
产生原因和梯度消失基本是一样的。都是由于链式法则产生的连乘积。
梯度爆炸相比于梯度消失是比较好发现的,因为梯度爆炸通常引起的异常是梯度数值过大会导致程序崩掉。解决梯度爆炸一般的方法是梯度裁剪,比如可以限幅。
LSTM
LSTM(Long Short Term Memory),其是RNN的一种变体,具体来说是对其内部结构进行了一点改变。
传统RNN的结构如下:
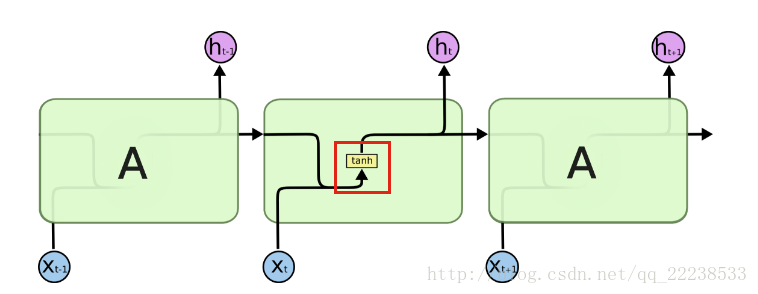
可以看到,内部只有隐藏层组成。
对于LSTM结构如下:
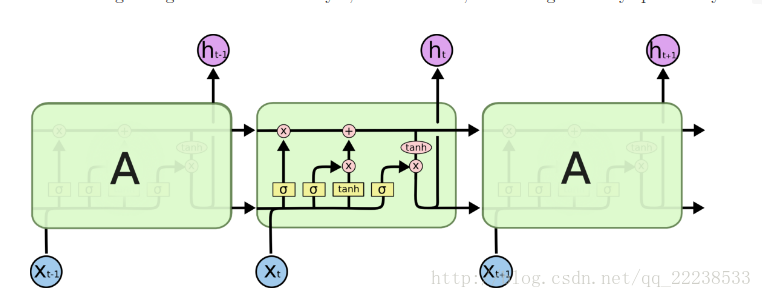
可以看到,LSTM内部结构复杂了许多。
(网上已经有许多关于lstm的学习资料了,这里只是简单做一个总结和心得)
虽然内部结构看起很复杂,其实主线是“三个门”
第一个门:(遗忘门)
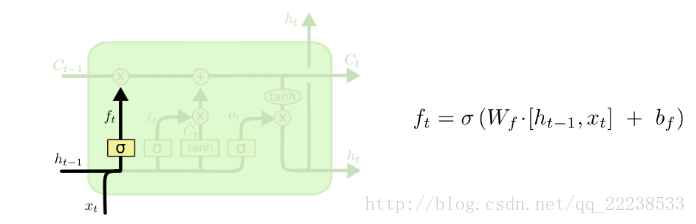
简单的说,遗忘门的作用就是对上一时刻细胞状态
第二个门:输入门
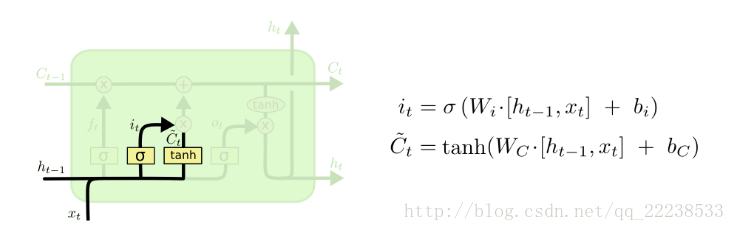
这个门的作用其实就是对新学习的内容吸收程度一个取舍。
具体来说,当前时刻新学习的内容为
第三个门:输出门
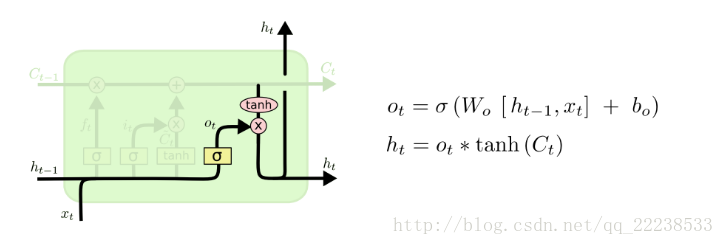
这个门的作用是对被激活之后新的细胞状态
其实,我感觉lstm的过程可以理解成以下这个过程:
当我们在试图去学习一个新的事物时(
同时,我们排除外界干扰从零开始,自己钻研这个新的事物(
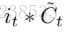
综合这两个判断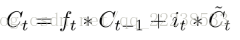
最后,我们用新的三观 (
然而,不管怎么说,我们三观已经被刷新了,它会继续的流传下去。
对于其的学习当然是下面这篇很有名的文章:
1.英文版
以及对它的一些翻译版本:
2.中文版带bptt推导
GRU
GRU(Gate Recurrent Unit),其是LSTM的变体,简化整个lstm的结构。其内部结构具体如下:
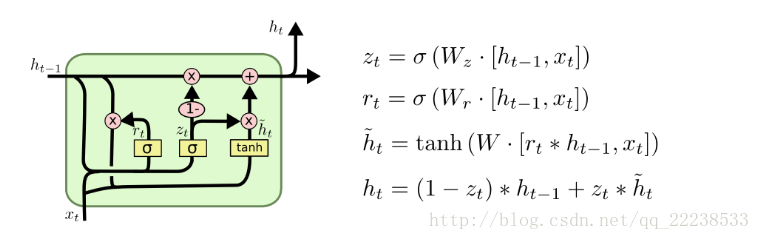
可以看到,只有两个sigmoid函数,因此只有两个门在GRU中。具体是将遗忘门和输入门进行合并,合并后叫做更新门(update gate)。
另外,对于将隐藏层的状态和细胞状态进行了合并。