前面写过用Word2vec和Doc2vec进行句子对匹配,以及基于传统机器学习方法进行句子对匹配的方法,本文主要介绍基于双向RNN(LSTM、GRU)和Attention Model的句子对匹配方法。
首先来看一下什么叫句子对匹配:
句子对匹配(Sentence Pair Matching)问题是NLP中非常常见的一类问题,所谓“句子对匹配”,就是说给定两个句子S1和S2,任务目标是判断这两个句子是否具备某种类型的关系。如果形式化地对这个问题定义,可以理解如下:
意思是给定两个句子,需要学习一个映射函数,输入是两个句子对,经过映射函数变换,输出是任务分类标签集合中的某类标签。
典型的例子就是Paraphrase任务,即要判断两个句子是否语义等价,所以它的分类标签集合就是个{等价,不等价}的二值集合。除此外,还有很多其它类型的任务都属于句子对匹配,比如问答系统中相似问题匹配和Answer Selection。
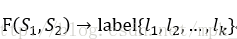
接下来我们来看一下深度学习中都有哪些句子对匹配的模型:
句子对匹配模型(一)
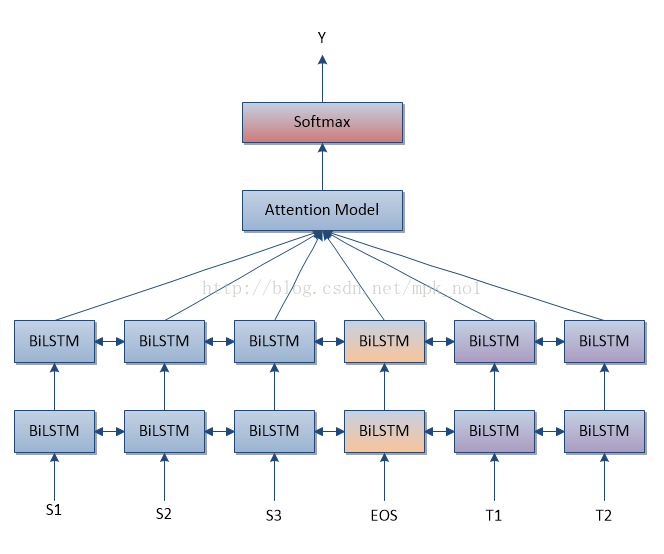
就是把两个句子S和T拼接起来,中间用一个特殊分隔符EOS分割,这里EOS不代表一个句子的结束,而是代表两个句子的分隔符号,如此就构造出了RNN的输入层。之后可以套上双向以及深层网络结构,在最高一层RNN层的输出之上,套上一个Attention Model层。这里的Attention Model层其实是一个静态的AM,具体做法就是首先计算BLSTM各个节点的注意力权重,然后对各个节点乘以注意力权重进行加和得到一个向量表示。
然后,在Attention Model之上,我们还可以套上一层SoftMax层,这样就可以实现最终的分类目的。
句子对匹配模型(二)
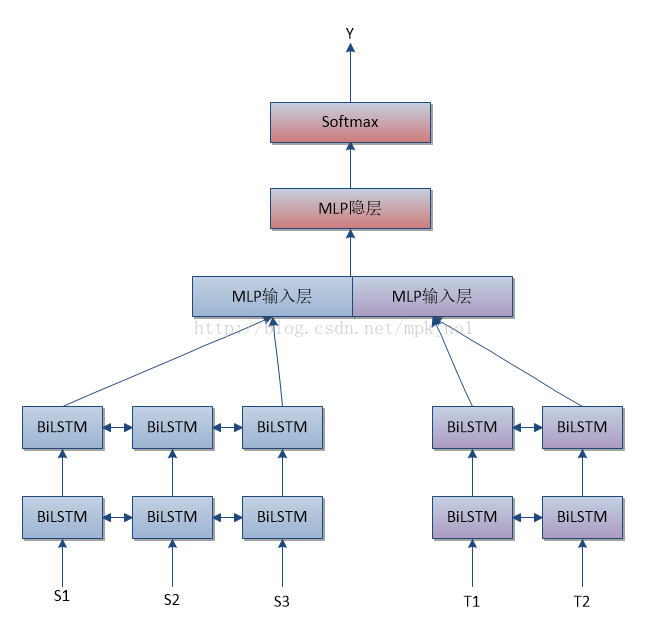
对于两个句子,分别套上一个RNN或者深层LSTM亦或双向深层LSTM等,每个RNN的目的是抽取出这个句子的特征,然后将两个句子抽取出的特征拼接成更上层的MLP多层神经网络的输入层,经过MLP的隐层使得两个句子发生非线性映射关系,最后再通过SoftMax分类层给出最后的分类结果。
这样就通过两个RNN实现了对两个句子是否具备某种关系作出分类判断的决策,使用训练数据可以获得网络参数,之后就可以将这个神经网络用来对现实任务进行分类的工作。
接下来,我们将MLP层之前添加一个Attention Model层,得到句子对匹配模型三
句子对匹配模型(三)
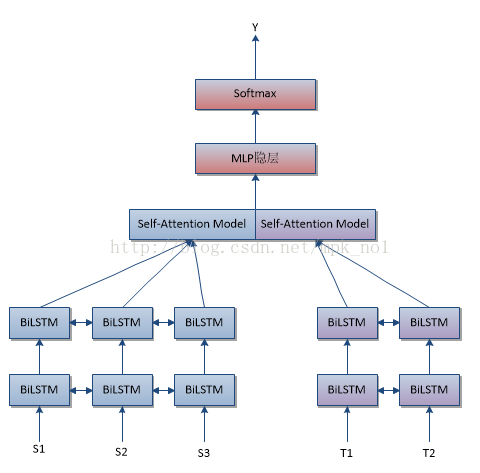
Attention Model层首先得到两个句子的向量表达,然后将得到的向量表达拼接起来作为MLP的输入,最终经过Softmax进行分类。
句子对匹配模型(四)
模型四与模型三的区别在于,模型三是对每一个句子经过深层BiLSTM得到的编码结果加上一个静态AM得到句子的一个向量表达,然后将两个句子的向量表达拼接起来。而模型四是通过Soft Attention Model得到两个句子之间的相互Attention向量,然后将这些向量进行MeanPooling,得到的结果输入MLP,最后经过Softmax得到分类结果。
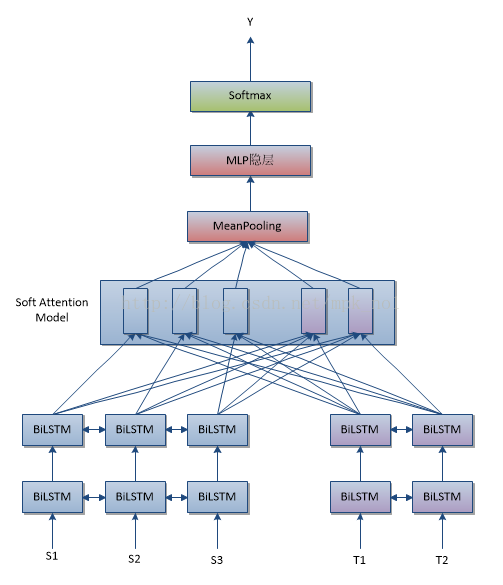
最后:图中的BiLSTM还可以替换为BiGRU。
本文主要是结合RNN和Attention Model做一些关于句子对匹配的总结,具体的实现和实验我后续会慢慢放上来的。