首先,思考一下,一个单词的“意思”如何定义?
WordNet是一个工具包,可以使用它找出给定单词的同义词、上位词、下位词等。但是,有如下缺点:
- 难以紧跟时代步伐进行更新,需要大量的人力去维护
- 因为是人来维护的,因此具有主观性
- 缺失词语之间的细微差别
- 无法给出词语相似性的准确度量
词语的离散表示—独热编码(one-hot representation)
将所有的词汇的个数作为向量长度,向量里的每一个元素对应着一个单词。除了单词所在位置为1,其他位置均为0。
例如: “hotel”: [0 0 0 0 0 0 0 0 1 0 0 0 0 ….0]
缺点:
- 向量维数和词汇表大小成正比,当词汇表单词个数上百万,上千万 的时候,向量的维数可想而知。
- 向量十分稀疏,只有该单词所在位为1,其余为0。
- 独热编码没有对单词之间的关系进行建模,任意两个单词编码的内积为0。
分布式表示(distributed representation)
可不可以把单词的向量表示固定一个维度?可不可以让向量表示不再稀疏,而是变得稠密呢?
再看一下,开始提到的问题。一个单词的“意思”如何定义?
答案如下:
You shall know a word by the company it keeps. (J.R. Firth 1957:11)
即,我们可以根据词语的上下文来得知它的意思。
进一步,介绍一下Word2vec工具包。
Word2vec的主要思想:predict between every word and its context words.
Word2vec有两种算法:Skip-grams(SG)和Continuous Bag of Words(CBOW)。
SG: predict context words given the target word
CBOW: predict the target word given context words
Word2vec使用了两种高效的训练方法:Hierarchical softmax 和 Negative sampling
首先,对SG进行介绍。给定中心词
,预测出一定窗口大小
内的上下文单词
。
目标函数:
我们需要最大化上面的目标函数,以使得预测更加准确。
但是,概率连乘操作(多个小数相乘)可能会出现下溢,即输出0。因此采取取对数操作,并且添加负号,从而变成最小化问题。
用softmax来求。
, 其中
是中心词对应的词向量,
是上下文单词对应的词向量,
是词汇表大小。公式并不复杂,分子是把数值变为正数,然后分母进行归一化操作。
贴上SG的“全景图”:
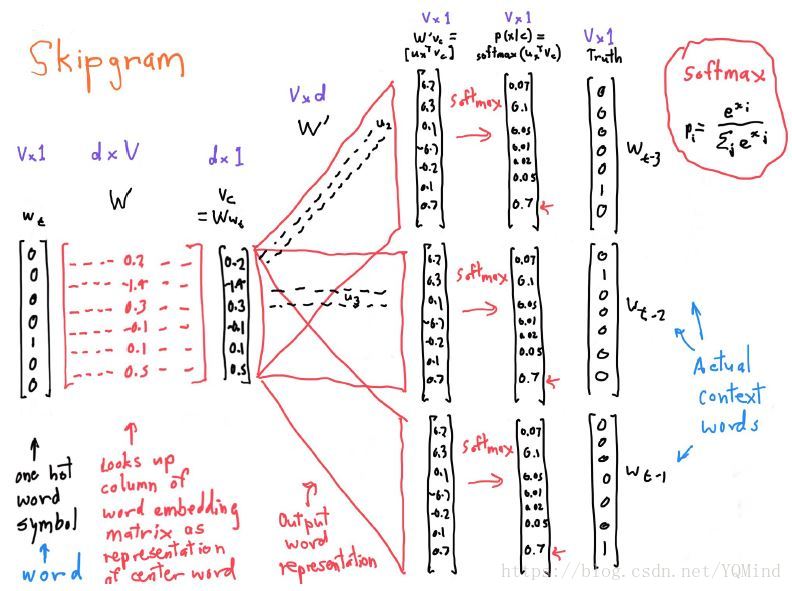
我们对上图从左至右慢慢分析。前面我们提到,SG是根据中心词来预测固定窗口内的上下文单词。因此,在图中,最左侧的输入是一个向量,最右侧的输出是三个向量(三个只是示意一下)。
Word2vec是高效的,在于网络中的参数只有两个类型,W: 内部词向量,W’:外部词向量。
中心词 根据one-hot表示对应到W中的某一列,即该单词的内部词向量表示 。然后和 中的每一行做内积计算出得分,得到向量 ,然后进行softmax得到概率表示。注意:对每一个上下文单词进行的是同样的操作,即V和W’都是唯一的,因此图中右侧的三个向量是一模一样的,除了one-hot表示。
因此,对于一个单词来说,SG可以得到两个词向量,一个是来自W的内部词向量,一个是来自W’的外部词向量。下游任务具体使用哪一个词向量还是两者的加和,没有恒定的答案,try it all !
目前的重点就在于如何训练这些词向量—-梯度下降法。需要用反向传播算法来求得对应的梯度。(老师的白板推导十分详细)


现在,考虑一个窗口,一个上下文单词。
以求对
的梯度为例:
展开为
—> observed
—>expected
一般不使用全梯度下降,因为you would wait a very long time before making a single update.

通常使用SGD(随机梯度下降),即每一个窗口后进行梯度更新:
