文章目录
lecture plan



1.how do we represent the meaning of a word?
1.1 wordnet
建立所有同义词synonym和下义词hypernym(即“is a"的关系)的词库,一个单词的含义就由它的同义词集合和下义词集合来定义。
这一表示方法有很多问题;这一表示方法有很多问题,比如一个单词只在某些语境下和另一个词为同义词而其他语境下不是,词汇的新的含义很难包含进入词库,定义比较主观且需要较多人力整理,而且也很难量化两个词的相似程度。
ppt中wordnet的问题
- 缺乏细微之处:同义词只在某些情况下正确
- 词缺乏新含义
- 偏主观
- 需要人力去更新修改
- 不能计算word的相似度

1.2 representing words by their context
一个简单的方法是我们用one-hot的向量来表示单词,即该单词对应所在元素为1,向量中其他元素均为0。

而向量的维度就等于词库中的单词数目。
一个显然的问题是由于所有向量都是互相正交的,我们无法有效的表示两个向量间的相似度,并且向量维度过大。
1.3 distributional semantics
we use the context of w to build up a representation of a word w w w.这就是分布语义学的思想,用上下文表示单词,这是现代统计nlp的one of best ideas.,它提供了学习单词含义的好方法。
- 100维词向量的二维投影

这种二维投影虽然会损失信息,扭曲原空间的内容,但是从这个向量空间中我们可看出向量空间中表示出的单词的相似性。
2. word2vec : overview
我们将每个单词构建一个密集的向量,这样它与出现在相似上下文中的单词向量相似。
idea:
- 有大量的文本;
- 固定词汇表中的每个单词都由一个向量表示;
- 浏览文本中的每个位置t,其中有一个中心词c和上下文(“外部”)单词o;
- 使用c和o的词向量的相似性来计算o给定c的概率(反之亦然);
- 不断的调整词向量,最大化概率。
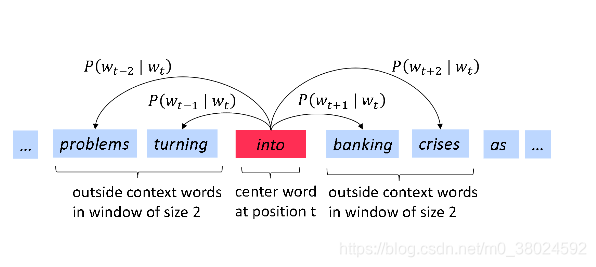
下图表示,w为into的计算图示:
在word2vec中,条件概率写作context word与center word的点乘形式再对其做softmax运算:
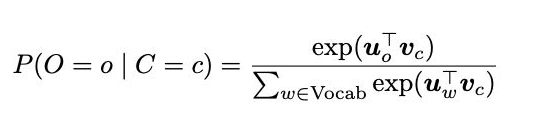
而整体的似然率就可以写成这些条件概率的联乘积形式:
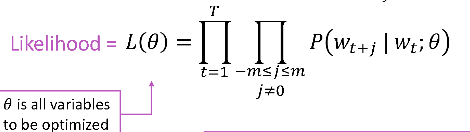
而我们的目标函数或者损失函数就可以写作如下形式:
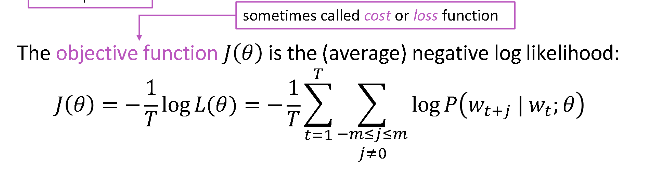
有了目标函数以及每个条件概率的表现形式,我们就可以利用梯度下降算法来逐步求得使目标函数最小的word vector的 θ \theta θ,这也就意味着我们将擅长再另一个单词的上下文中预测单词:
