文章目录
Realtime Robust Malicious Traffic Detection via Frequency Domain Analysis
中文题目:基于频域分析的实时鲁棒恶意流量检测
发表会议:Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security
发表年份:2021-11-12
作者:Chuanpu Fu, Qi Li, Meng Shen, and Ke Xu
latex引用:
@inproceedings{fu2021realtime,
title={Realtime robust malicious traffic detection via frequency domain analysis},
author={Fu, Chuanpu and Li, Qi and Shen, Meng and Xu, Ke},
booktitle={Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security},
pages={3431--3446},
year={2021}
}
摘要
基于机器学习(ML)的恶意流量检测是一种新兴的安全范式,特别是零日攻击检测,它是现有基于规则检测的补充。但是现有的基于ML的检测由于流量特征提取效率低,检测精度低,吞吐量低。因此,它们无法实时检测攻击,特别是在高吞吐量网络中。特别是,这些类似于现有的基于规则的检测系统可以很容易地被复杂的攻击所逃避。
为此,我们提出了一种基于ML的恶意流量检测系统Whisper,该系统利用频域特征实现了高精度和高吞吐量。利用频域特征所代表的序列特征实现有界信息损失,保证了较高的检测精度,同时约束特征的规模,实现了较高的检测吞吐量。特别是,攻击者不能轻易地干扰频域特征,因此Whisper对各种逃避攻击具有很强的鲁棒性。
我们对42种攻击类型的实验表明,与最先进的系统相比,Whisper可以准确地检测各种复杂和隐秘的攻击,最多提高18.36%,同时实现两个数量级的吞吐量。即使在各种逃避攻击下,Whisper仍然能够保持90%左右的检测精度。
存在的问题
- 传统的基于规则的恶意流量检测方法,虽能在高带宽网络(如Internet骨干网)中可以达到较高的检测精度和检测吞吐量,但却无法检测到零日攻击。
- 基于机器学习的恶意流量检测方法,虽能检测零日攻击,但是检测精度较低,无法处理高速率流量。因此,大多数这些方法只能离线部署,不能实现实时检测,特别是在高性能网络中(例如,在10千兆网络中)
- 攻击者可以通过在攻击流量中注入噪声(如良性应用程序产生的报文)来干扰和规避这些方法。分析每个包特征序列的包级检测无法实现鲁棒检测。
- 实际上,即使在没有逃避攻击的情况下,包级检测也可能无法检测到复杂的零日攻击。
- 传统的流级方法通过分析流级统计信息来检测攻击,会导致显著的检测延迟。此外,规避攻击可以轻松绕过使用粗粒度流级统计信息的传统流级检测。
总结:
新方法需要从以下几个方面进行改进:
- 能检测零日攻击
- 能保证实时检测
- 能保证模型的健壮性(即:方法本身不存在明显缺陷;难以被攻击者干扰或者绕过)
论文贡献
- 提出了第一个基于机器学习的系统,在高吞吐量网络中实现实时和健壮的检测:Whisper,一种利用频域分析的新型恶意流量检测系统。
- 通过频域特征分析提取序列特征,为Whisper的检测精度、鲁棒性和吞吐量奠定基础。
- 开发了Whisper的自动编码向量选择,减少了人工参数选择的工作量,在保证检测精度的同时避免了人工参数设置。
- 开发了一个理论分析框架来证明Whisper的特性。
- 使用英特尔DPDK构建Whisper原型,并使用不同类型的重放攻击流量的实验来验证Whisper的性能。
总结:
- 能检测零日攻击:Whisper使用机器学习的方法进行检测,能有效应对零日攻击
- 准确率:Whisper通过频域分析有效地提取和分析网络流量的序列特征,以低信息损失提取流量特征,低信息损失能保证准确率。
- 健壮性(鲁棒性):由于频域特征代表了数据包序列的细粒度顺序特征,不受注入噪声数据包的干扰,因此Whisper可以实现鲁棒检测。
- 实时检测:Whisper提取流量的频域特征。流量的频域特征可以有效地表示流量的各种分组排序模式,且特征冗余度低。低特征冗余保证了高通量流量检测。
由于丰富的特征表达和轻量级的机器学习,Whisper最终实现了高吞吐量网络中恶意流量的实时检测。
难点: 由于流量模式的大规模、复杂性和动态性,从流量中提取和分析频域特征并非易事。
1. 威胁模型和设计目标
-
威胁模型
- 将恶意流量检测系统部署为中间盒的旁路插件模块。中间盒通过端口镜像将复制的流量转发给检测系统,类似于Cisco SPAN。因此,检测系统不会干扰良性流量的转发。
- 假设检测系统对威胁没有任何先验知识,这意味着它应该能够处理零日攻击。
- 只考虑了对恶意流量的检测,不考虑防御。
- 恶意流量检测与流量分类完全不同,后者的目的是分类流量是由某个网络应用产生的,还是由某个用户产生的。
- 不考虑那些不会引起明显流量变化的被动攻击,例如窃听攻击和拦截攻击。
-
设计目标
开发一种实时鲁棒的恶意流量检测系统,该系统具有较高的检测精度和任务不可知检测。
- 稳健准确的检测。
(1)系统应该能够检测各种零日攻击。
(2)特别是,它可以捕获不同的逃避攻击,这些攻击试图通过故意向攻击流量中注入噪声数据包,即使用良性应用程序产生的各种数据包来逃避检测。- 实时检测,高吞吐量。
该系统应该能够部署在高吞吐量网络中,例如10千兆以太网,同时实现低检测延迟。
2. whisper概述
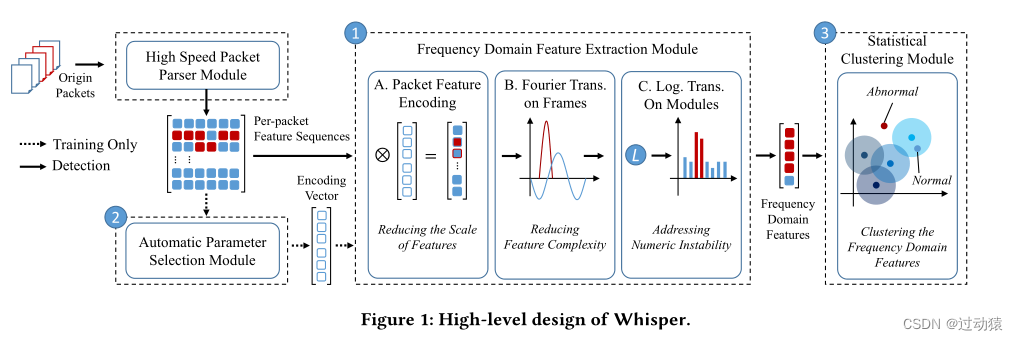
2.1 高速包解析器模块
高速报文解析模块高速提取每个报文的特征,如报文长度、到达时间间隔等,保证训练和检测两个阶段的处理效率。该模块为特征提取模块提供每个包的特征序列,用于频域特征提取,为自动参数选择模块确定编码向量。
任务:
- 高速提取每个报文的特征。
- 为特征提取模块提供每个包的特征序列。将每个包的特征序列编码为向量来实现高性能检测,以减少后续处理的开销。
- 为自动参数选择模块确定编码向量。
2.2 频率特征提取模块
在训练和检测阶段,该模块从每个包的特征序列中提取频域特征。该模块以固定的时间间隔定期从高速数据包解析器模块轮询所需的信息。在获得提取的每个包特征序列后,将每个包特征序列编码为向量,并通过频域提取序列特征。
任务:
- 提取频域特征,为统计聚类模块提供这些低冗余特征。
2.3 自动参数选择模块
该模块为特征提取模块计算编码向量。我们通过求解一个约束优化问题来确定编码向量,该问题减少了每个包的不同特征之间的相互干扰。在训练阶段,该模块获取每个数据包特征序列并求解等效SMT问题,以近似原始问题的最优解。通过启用自动参数选择,我们大大减少了参数选择的手工工作。因此,在检测阶段,可以固定并准确设置编码向量。
任务:
- 为频率特征提取模块求解最优的编码向量
2.4 统计聚类模块
在本模块中,我们利用一种轻量级统计聚类算法从特征提取模块中学习频域特征的模式。
在训练阶段,该模块计算良性流量频域特征的聚类中心和平均训练损失;
在检测阶段,该模块计算频域特征与聚类中心之间的距离。如果距离明显大于训练损失,Whisper就会将流量检测为恶意。我们在第4.3节详细介绍了基于统计聚类的检测。
任务:
- 在训练阶段,计算良性流量频域特征的聚类中心和平均训练损失。
- 在检测阶段,计算测试样本得频域特征与聚类中心之间的距离,以判断是否为恶意流量。
3. whisper设计细节
3.1 频率特征提取模块
-
报文特征编码(Packet Feature Encoding)
首先,设一个流中有N个报文,每个报文有M个特征,这样这个流就可以表示成:

为了更简洁的表示一个流,我们将每个包的特征乘上一个特征权重,获得一个新的流表示:

简单理解就是: v = S (形状为 N ∗ M ) ∗ w (形状为 M ∗ 1 ) v = S(形状为N*M) * w(形状为M * 1) v=S(形状为N∗M)∗w(形状为M∗1) -
矢量框架(Vector Framing)
接下来用步长 W s e g W_{seg} Wseg来分割向量 v v v,分割的原因在于:通过约束数据包之间的长期依赖关系来降低频域特征的复杂性。如果帧太长,频域特征在统计学习模块中会变得非常复杂。
简单理解这句话就是,使用了一个滑动窗口(该窗口长度为 W s e g W_{seg} Wseg),对每个数据包而言,仅在该数据包所在的滑动窗口内来提取该数据包与其他数据包的时间依赖关系。

这样一来,特征向量就变为了 v = [ ( v 1 , v 2 , . . . v W s e g ) , ( v W s e g + 1 , v W s e g + 2 , . . . , v W 2 s e g ) , . . . , ( v ( N f − 1 ) ∗ W s e g , . . . , v N f ∗ W s e g ) ] v = [(v_1,v_2,...v_{W_{seg}}),(v_{W_{seg+1}},v_{W_{seg+2}},...,v_{W_{2seg}}),...,(v_{(N_f-1)*W_{seg}},...,v_{N_f*W_{seg}})] v=[(v1,v2,...vWseg),(vWseg+1,vWseg+2,...,vW2seg),...,(v(Nf−1)∗Wseg,...,vNf∗Wseg)]换种表示方法就是:
f = [ f 1 , f 2 , . . . , f N f ] f = [f1, f2, ... , f_{N_f}] f=[f1,f2,...,fNf]
其中, f i = [ v ( i − 1 ) ∗ W s e g : v ( i ) ∗ W s e g ] f_i = [v_{(i-1)*W_{seg}}:v_{(i)*W_{seg}}] fi=[v(i−1)∗Wseg:v(i)∗Wseg]
也就是说,每个 f i f_i fi表示一个长度为 W s e g W_{seg} Wseg的包序列,这样的包序列一共有 N f N_f Nf个。 -
离散傅里叶变换(Discrete Fourier Transformation)

其中 f i n f_{in} fin: f i f_i fi中第 n n n个数据包的特征值 -
复数模的计算(Calculating the Module of Complex Numbers)


上述公式过程可以理解为:
最后生成了一个新的特征矩阵P,该特征矩阵形状为( N f N_f Nf, K f K_f Kf)。其中, K f = ⌊ W s e g / 2 ⌋ + 1 K_f=\lfloor W_{seg}/2 \rfloor+1 Kf=⌊Wseg/2⌋+1。对于其中每个元素 p i k p_{ik} pik,它的生成公式为: p i k = ( f i W 1 ) 2 + ( f i W 2 ) 2 p_{ik} = (f_iW_1)^2 +(f_iW_2)^2 pik=(fiW1)2+(fiW2)2
其中 W 1 W_1 W1和 W 2 W_2 W2的形状都为( W s e g W_{seg} Wseg,1), f i f_i fi的形状为(1, W s e g W_{seg} Wseg) W 1 = [ c o s 0 , c o s 2 π ∗ 1 ∗ ( k − 1 ) W s e g , c o s 2 π ∗ 2 ∗ ( k − 1 ) W s e g , . . , c o s 2 π ∗ ( W s e g − 1 ) ∗ ( k − 1 ) W s e g ] T W_1 = [cos0,cos\frac{2\pi*1*(k-1)}{W_{seg}},cos\frac{2\pi*2*(k-1)}{W_{seg}},..,cos\frac{2\pi*(W_{seg}-1)*(k-1)}{W_{seg}}]^T W1=[cos0,cosWseg2π∗1∗(k−1),cosWseg2π∗2∗(k−1),..,cosWseg2π∗(Wseg−1)∗(k−1)]T
W 2 = [ − s i n 0 , − s i n 2 π ∗ 1 ∗ ( k − 1 ) W s e g , − s i n 2 π ∗ 2 ∗ ( k − 1 ) W s e g , . . , − s i n 2 π ∗ ( W s e g − 1 ) ∗ ( k − 1 ) W s e g ] T W_2 = [-sin0,-sin\frac{2\pi*1*(k-1)}{W_{seg}},-sin\frac{2\pi*2*(k-1)}{W_{seg}},..,-sin\frac{2\pi*(W_{seg}-1)*(k-1)}{W_{seg}}]^T W2=[−sin0,−sinWseg2π∗1∗(k−1),−sinWseg2π∗2∗(k−1),..,−sinWseg2π∗(Wseg−1)∗(k−1)]T
上图中用 a i k a_{ik} aik代替了 f i W 1 f_iW_1 fiW1,用 b i k b_{ik} bik代替了 f i W 2 f_iW_2 fiW2,这样一来公式就变成了:
p i k = ( a i k ) 2 + ( b i k ) 2 p_{ik} = (a_{ik})^2 +(b_{ik})^2 pik=(aik)2+(bik)2和上图中的公式就保持一致了。
但是按上面的说法生成的P矩阵的形状应该是( N f N_f Nf, W s e g W_{seg} Wseg),为什么最终形状是( N f N_f Nf, K f K_f Kf)呢?
这是因为P这个矩阵关于 ⌊ W s e g / 2 ⌋ + 1 \lfloor W_{seg}/2 \rfloor+1 ⌊Wseg/2⌋+1这个列轴对称,所以就不需要后面的那些特征了,只需要保留前面 ⌊ W s e g / 2 ⌋ + 1 \lfloor W_{seg}/2 \rfloor+1 ⌊Wseg/2⌋+1这些列的特征即可。
这样理解离散傅里叶变换的话,可以理解为,每个包序列 f i f_i fi乘上了一组基向量(W1,W2)变换到了频域,最后获得了每个包序列的频域特征。所以最后的P矩阵可以理解为有 N f N_f Nf个包序列,每个包序列有 W s e g W_{seg} Wseg个特征
(这样就能理解为什么要分段了,因为如果不分段,那么该特征矩阵形状就变成了[1,N],这样就会使得在频域上提取一个流的时间依赖特征过长)
-
对数变换(Logarithmic Transformation)
为了使频域特征数值稳定,防止机器学习训练中的浮点溢出,我们对得到的特征矩阵P进行对数变换,使得频域特征保持在某一个实数范围内。

最后获得了一个R矩阵,形状同样为( N f N_f Nf, R f R_f Rf)
总结:该模块将最开始的特征矩阵S( N N N* M M M)变为了频域上的特征表示R( N f N_f Nf* R f R_f Rf)
该模块中提到的参数:
- N = 1500
- M = 3
- packet length(报文长度)
- protocol type(协议类型)
- arriving time interval(到达时间间隔)
- W s e g W_{seg} Wseg = 30,因此 N f = 1500 / 30 = 50 N_f = 1500/30 = 50 Nf=1500/30=50, K f = ⌊ 30 / 2 ⌋ + 1 = 16 K_f = \lfloor 30/2 \rfloor+1=16 Kf=⌊30/2⌋+1=16
-
然后对频域特征R进行最小-最大归一化操作,并将结果映射到RGB空间。对频域特征进行了可视化分析。

发现恶意流量的频域特征相关区域明显比良性流量的频域特征暗。(不知道论文为什么说“暗”,我觉得是“亮”才对)。因此可以知道,在频域上提取特征能更好的提取数据包序列的细粒度顺序特征
3.2 自动参数选择模块
接下来,我们讨论上面频率特征提取模块中报文特征编码里提到的 w w w应该如何取值的问题。
一般来说,我们将编码向量选择问题表述为约束优化问题,并将原问题转化为等效的SMT问题。我们通过求解SMT问题来逼近原问题的最优解。
-
假设每个包的所有M个特征都可以用一个连续的函数 h i ( t ) h_i(t) hi(t)来获取。换句话说,我们假设每个包的所有M个特征都是该连续函数的采样。
-
我们需要找到一个向量 w w w增强并叠加所有这些函数(即加权求和)。我们的优化目标是在函数叠加时尽量减少相互干扰(就是使得每个特征尽可能独立),并约束整体范围。
(1)首先要限定向量 w w w的数值范围,每个数值的范围为 [ W m i n , W m a x ] [W_{min},W_{max}] [Wmin,Wmax]

(2)然后再限定加权求和的整体范围,上限为B

-
限制了函数的保序性质,以确保在特征提取模块执行数据包编码时,不同类型的特征之间不会相互干扰.

-
通过最大化函数之间的距离,使特征之间的相互干扰最小化,并绑定所有函数的范围的方式,来优化向量 w w w。

-
在实践中,我们无法确定优化对象的凸度。因为我们不知道 h i ( t ) h_i(t) hi(t)函数的具体形式。因此,我们将原点约束优化问题转化为具有优化对象(18)的可满足模理论(SMT)问题(19)以逼近(17)的最优解。

感觉这个目标函数有问题,以下是我的理解:
请注意,我们将优化对象(17)中的绝对值操作改革为约束(19),因为大多数SMT求解器不支持绝对值操作。
3.3 统计聚类模块
在训练阶段,该模块计算频域特征的聚类中心和平均训练损失。注意这里只使用良性流量。
-
为了提高Whisper的鲁棒性,减少极端值引起的假阳性,我们对频域特征矩阵 R R R用窗口长度为 W w i n W_{win} Wwin的窗口进行了分割。
理解:就是如果单纯地直接对所有的特征求聚类中心,避免不了其中有个别极端值会使得聚类中心偏移,因此先对每个窗口先求一个平均值,然后再对这些平均值求聚类中心,这样一来就会多多少少消除一些特殊值的影响。

-
首先使用统计聚类算法,得到了 K C K_C KC个聚类中心,每个聚类中心用 C k C_k Ck表示,其中 k ∈ [ 1 , K C ] k\in[1,K_C] k∈[1,KC],使用L2范式计算每个 r i r_i ri与聚类中心的距离,找到其中距离最近的聚类中心,用 C ^ i \hat C_i C^i表示。

-
然后用L2范式的平均值计算训练损失。

在检测阶段,该模块计算流量频域特征与聚类中心之间的距离。
- 对于给定的频域特征R,用长度为 W w i n W_{win} Wwin的窗口进行分割,得到 N t N_t Nt个段。这和训练阶段是一致的。
- 对于 r i r_i ri而言,计算距离它最近的聚类中心的距离,作为损失。

- 评估标准:如果 l o s s i > = ϕ ∗ t r a i n _ l o s s loss_i >= \phi * train\_loss lossi>=ϕ∗train_loss,即只要该流中有一个段大于了train_loss,就说明该流偏离了良性流量的聚类中心,因此判定该流为恶意流量。
4. whisper理论分析
该节主要证明了Whisper在特征提取中比包级和流级方法有更低的信息损失,从而保证了Whisper准确提取流量特征。这里就不具体说明了,感兴趣的人可以看看。
5. whisper实验评估
实验验证了三个问题:
- 准确率:Whisper的检测精度是否比目前最先进的方法更高?
- 健壮性:即使攻击者试图通过利用良性流量来逃避Whisper的检测,Whisper是否能够健壮地检测到攻击?
- 实时性:Whisper是否实现了高检测吞吐量和低检测延迟?
-
各个模块的实现
- 高速包解析器模块:我们利用Intel Data Plane Development Kit (DPDK) 18.11.10 LTS 版本来实现数据平面函数和确保在高吞吐量网络中高性能的数据包解析。我们使用DPDK api将Whisper的线程绑定到物理核上,以降低cpu中上下文切换的成本。正如原文4.1节所讨论的,我们将解析每个数据包的三个特征,即长度、时间戳和协议类型。
[DPDK. Accessed January 2021. Data Plane Development Kit. https://www.dpdk.org/.] - 频域特征提取模块:我们利用PyTorch(版本1.6.0)在基线方法中实现原始数据包特征和自动编码器的矩阵转换(例如,编码和离散傅里叶变换)。
- 统计聚类模块:我们利用K-Means作为聚类算法,使用mlpack实现(3.4.0版本)对频域特征进行聚类。
- 自动参数选择:我们使用Z3 SMT solver(版本4.5.1)[41]来解决4.2节中的SMT问题,即确定Whisper中的编码向量。
- 高速包解析器模块:我们利用Intel Data Plane Development Kit (DPDK) 18.11.10 LTS 版本来实现数据平面函数和确保在高吞吐量网络中高性能的数据包解析。我们使用DPDK api将Whisper的线程绑定到物理核上,以降低cpu中上下文切换的成本。正如原文4.1节所讨论的,我们将解析每个数据包的三个特征,即长度、时间戳和协议类型。
-
各种参数的设置:

-
实验设置
1. Baselines(基线模型)
- 包级别检测。我们使用最先进的基于机器学习的检测方法,Kitsune[43]。它通过流状态变量提取每个包的特征,并将特征提供给自动编码器。我们使用开源的Kitsune实现[42],并使用与Whisper相同的硬件检测离线攻击。
- 流级统计聚类(FSC)。据我们所知,目前还没有实现任务不可知检测的流量级恶意流量检测的方法。因此,根据现有的研究[4,5,32,38,44,74],我们建立了22个流量级统计信息,包括Whisper中三个每个包特征的最大值、最小值、方差、平均值、范围、流持续时间和流字节数。我们对流级统计数据执行归一化。为了公平的比较,我们对Whisper使用相同的聚类算法。
- 基于自动编码器的流级频域特征。我们使用与Whisper相同的频域特征和具有128个隐藏状态和Sigmoid激活函数的自动编码器模型,这与Kitsune中的自动编码器类似。对于自动编码器的训练,我们使用Adam优化器,设置批大小为128,训练epoch为200,学习率为0.01。
2. Testbed(实验平台)
我们在一台DELL服务器上进行了Whisper、FSC和FAE实验。
该服务器配置:- 2个Intel Xeon E5645 cpu (2 × 12核)
- Ubuntu 16.04 (Linux 4.15.0 LTS)、
- 24GB内存
- 一个Intel 10 Gbps网卡(带有两个支持DPDK的端口)
- 用于光纤连接的Intel 850nm SFP+激光端口。
- 为DPDK (4GB/NUMA节点)配置了8GB大页内存。
- 为8个网卡RX队列绑定8个物理核来提取每个数据包的特征,另外8个核用于Whisper分析线程,它提取流量的频域特征并进行统计聚类。
- 总之,我们使用了24个内核中的17个来启用Whisper。
请注意,由于Kitsune不能处理高速率流量,所以我们在同一个测试台上使用离线实验来评估它。
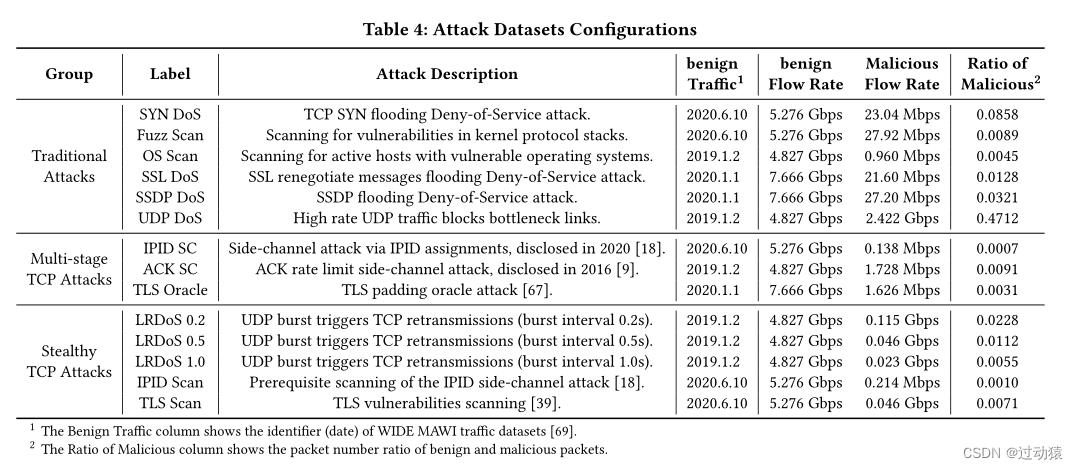
我们在另外两台配置相似的服务器上部署了DPDK流量生成器。之所以使用两个流量发生器,是因为Whisper的吞吐量超过了10gbps网卡的物理限制,即13.22 Gbps。我们用光纤连接两个流量发生器以产生高速流量。3. Datasets(数据集)
我们实验中使用的数据集如表4所示。我们使用了WIDE MA WI千兆骨干网的四个最新数据集[69]。在训练阶段,我们使用20%的良性流量来训练机器学习算法。我们使用MA WI 2020.06.10数据集中的前20%数据包,通过解决SMT问题来计算编码向量。同时,我们在测试台上重放了四组恶意流量与良性流量的组合流量。
-
传统DoS攻击和扫描攻击(Traditional DoS and Scanning Attacks)
-
多级TCP攻击(Multi-Stage TCP Attacks)
-
隐秘的TCP攻击(Stealthy TCP Attacks)
-
逃避攻击(Evasion Attacks)
4. 评估
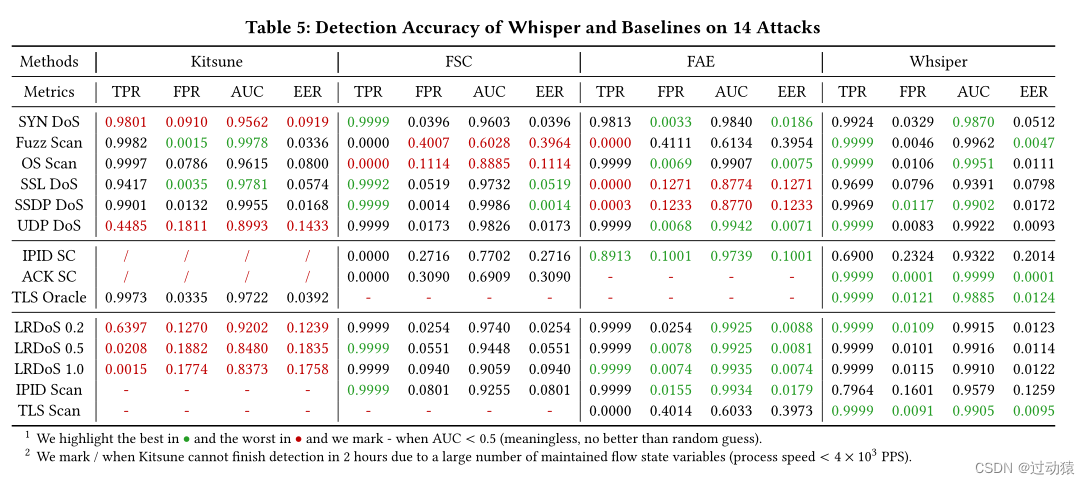
我们使用以下指标来评估检测精度:(i)真阳性率(TPR), (ii)假阳性率(FPR), (iii) ROC曲线下面积(AUC), (vi)等错误率(EER)。
此外,我们测量了吞吐量和处理延迟,以证明Whisper实现了实时检测。
-
检测准确率
-
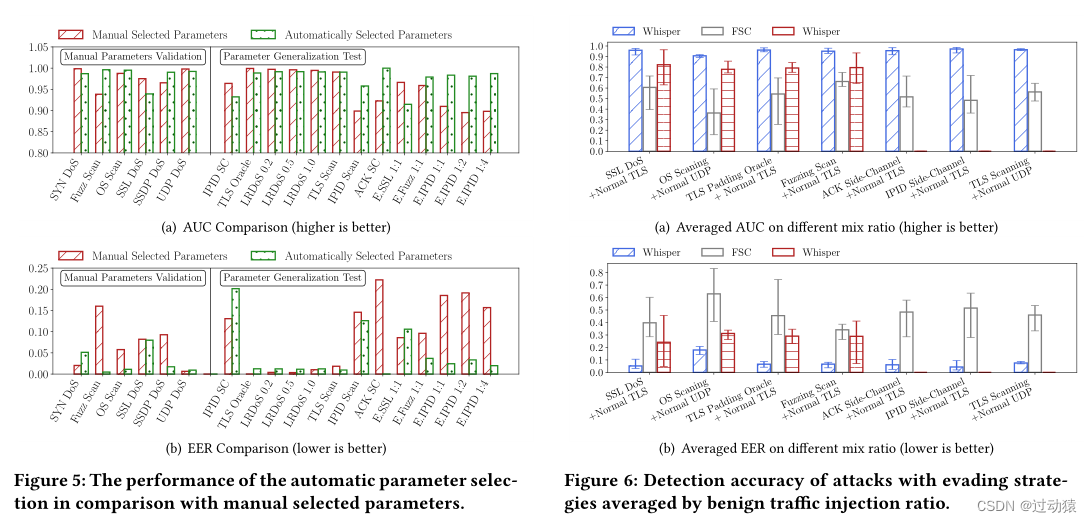
检测健壮性
为了验证Whisper的鲁棒性,我们假设攻击者知道恶意流量检测的存在。攻击者可以构造逃避攻击,即注入各种良性流量来逃避检测。在实验中,为了简单起见,我们假设攻击者将良性的TLS流量和UDP视频流量注入到恶意流量中,并将其伪装成良性流量以进行逃避。我们之所以使用TLS和UDP视频流量,是因为它在良性流量数据集中所占的比例很高,分别在35%和13%左右。注入这两种类型的流量将极大地干扰检测。我们选择并重放7种恶意流量模式,并将其混合成不同比例的良性流量,即恶意流量与良性流量的比例在1:1到1:8之间。我们没有注入更多比例的良性流量,因为1:8的比例攻击的有效性已经很低了。我们根据攻击类型聚合检测结果,如图6所示为不同注入比下的平均检测精度。详细的检测精度如图9所示(见附录E)。我们观察到,良性流量混合比高的逃避攻击更容易逃避检测。从图6中,我们得出结论,攻击者不能通过将良性流量注入恶意流量来逃避Whisper。然而,攻击者逃避了其他检测系统的检测。
例如,Whisper在躲避攻击下AUC最多减少10.46%,EER最多增加1.87倍。而Kitsune的AUC最多减少35.4%,EER最多增加7.98倍。同样,攻击者可以有效地逃避流量级别检测系统的检测,特别是注入更良性的高比例流量。在流级方法(AUC≤0.5)下,采用规避操作系统扫描和规避TLS漏洞扫描等规避攻击,最大EER增加11.59倍。由此可见,现有的流级和包级检测系统对逃避攻击的鲁棒性较差。在不同比例下,Whisper具有稳定的检测精度,例如退化的AUC范围为3.0%,对于逃避攻击具有鲁棒性。
Whisper实现鲁棒检测的原因是所使用的频域特征代表了流量的细粒度顺序特征。伪装成良性流量的恶意流量不会导致流量级别统计数据发生重大变化。因此,恶意流量在流级方法中的特征与良性流量相同。以Kitsune为代表的基于包的方法使用统计信息作为上下文信息。因此,由于不变量的特征,包级和传统的流级检测会错过这种攻击。然而,Whisper提取的恶意流量序列特征与良性流量有明显不同。
-
检测时延和吞吐量
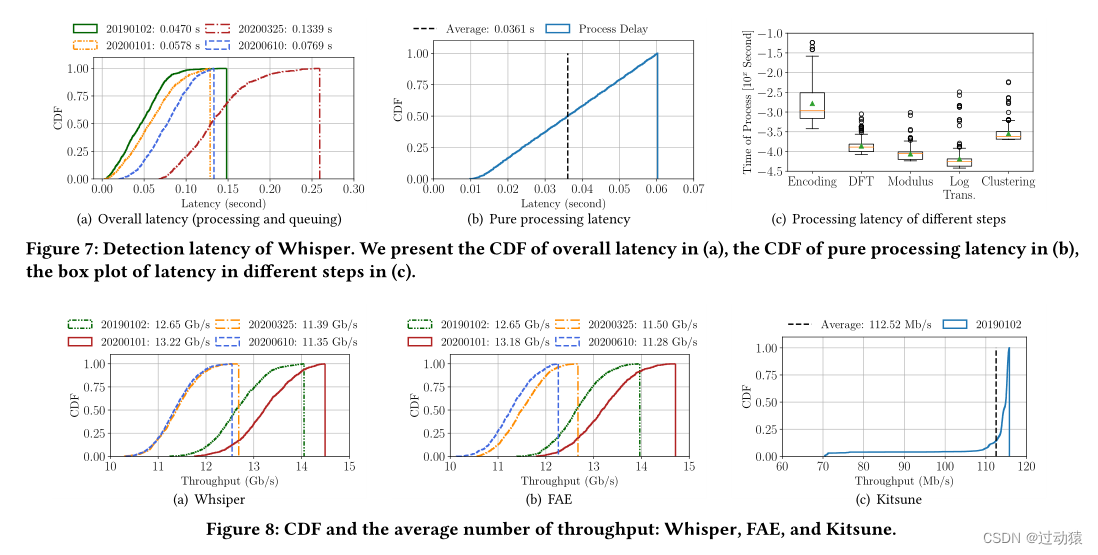
总结
论文内容
-
学到的方法
理论上的方法:
- 对特征进行频域变换,并在RGB图上进行可视化分析。如文章中3.1中提到的。
- 当对一个特征进行编码时,可以对编码向量 w w w使用SMT方法进行优化,如文章中3.2中提到的。
- 如果对所有的样本直接求聚类中心,可能会受到个别极端值的影响。此时可以设置一个窗口,对每个窗口先求一个平均值,然后再对这些平均值求聚类中心,这样一来就会多多少少消除一些影响。如文章中3.3提到的。
写论文的方法:
- 实验评估那节,要先写上该节实验证明了哪几个问题?可以从模型优势,模型对比等方面探讨。
-
论文优缺点
论文优点:
- 考虑了模型的准确率(所使用的频域特征代表了流量的细粒度顺序特征,能更深的理解数据)
- 考虑了模型的健壮性(能检测攻击者构造的逃避攻击,即注入各种良性流量来逃避检测)
- 考虑了模型的时效性(Whisper提取流量的频域特征。流量的频域特征可以有效地表示流量的各种分组排序模式,且特征冗余度低。低特征冗余保证了高通量流量检测。)
工具
- DPDK:高速包解析器的实现
- mlpack:K-means聚类实现
- Z3 SMT solver:SMT问题求解
数据集
WIDE. Accessed January 2021. MA WI Working Group Traffic Archive. http://mawi.wide.ad.jp/mawi/.