SuperCNN: A Superpixelwise Convolutional Neural Network for Salient Object Detection
超像素卷积神经网络:一种用于检测显著性物体的超像素卷积神经网络
文献提出了一种新颖的SuperCNN网络,使用该网络进行深度学习训练,能学习到图像的分层对比特征,检测出显著性物体, 最终再将图像二值化,突出场景图像中的重要物体。本博文为个人原创 , 阐述个人对该文献的理解,如有不足,请多多包涵, 转载需注明出处 , 谢谢
我希望能通过阅读有关computer vision 及 deep learning领域的相关文献,能让我更好更全面地去了解该领域的理论热点和学术前沿,培养我的学术思维,同时也能提高自身阅读英文文献的能力和技巧,所以这无疑是一件大有裨益的事情,好好加油!!
附上作者的原文献地址:文献地址
阅读文献的五个要点
我在阅读文献过程中,培养自己养成良好的阅读习惯,抓住文献的五个要点:
- 论文的背景和意义,目标是什么?
- 研究内容是什么?
- 是研究了一个算法还是一个理论?
- 研究方法是什么?
- 最后得出来的结论是什么?
按照这五个要点,对这篇文章进行阅读 ,下面阐述个人对该文献的理解,如有不恰当之处,欢迎指出,我虚心学习~~
该文献的五个要点
第一要点:研究背景
在摘要部分,作者简明扼要地阐述研究的背景,文章的研究背景是在目前对于显著物体检测的方法还是依赖人工标记的特征图计算,这只能捕获图像低水平的对比信息,其研究目标是通过提出一种新的卷积神经网络,来解决现状的问题,最终达到能检测到显著物体,获取到图像的分层对比特征。
第二要点:研究内容
文章指出了传统的CNN算法不适用显著物体检测,其原因有
- 显著性物体是由上下文内容决定的
- 使用传统CNN进行超像素预测存在噪声,而且在较大规模的网络结构中预测超像素图像是非常耗时的
- 对于传统的CNN算法,直接用原始输入图像训练网络,是很难检测显著性的
文章的研究内容主要是提出了一种获取图像显著特征的新深度学习方法–SuperCNN网络,SuperCNN有四个属性:
- 通过馈送两个超像素序列,能学习到分层对比特征;
- SuperCNN能恢复超像素之间的上下文信息
- 大大减少对于密集标记的map所需的预测数量
- 利用多尺度网络结构,独立的区域大小可检测出显著性
第三要点:算法研究
文章研究的是一个深度学习的算法,基于传统CNN依赖的是低水平的图像特征,且不能检测到显著物体,因此提出了一种名叫SuperCNN的网络(超像素卷积神经网络),通过该神经网络能学习到图像的分层对比特征(hierarchical contrast feature) ,最后将检测到的显著性对象,得到一个正归一化值,该值被视为显著性分数,再将图像二值化,突出图像中的显著物体。
超像素卷积神经网络的结构图:
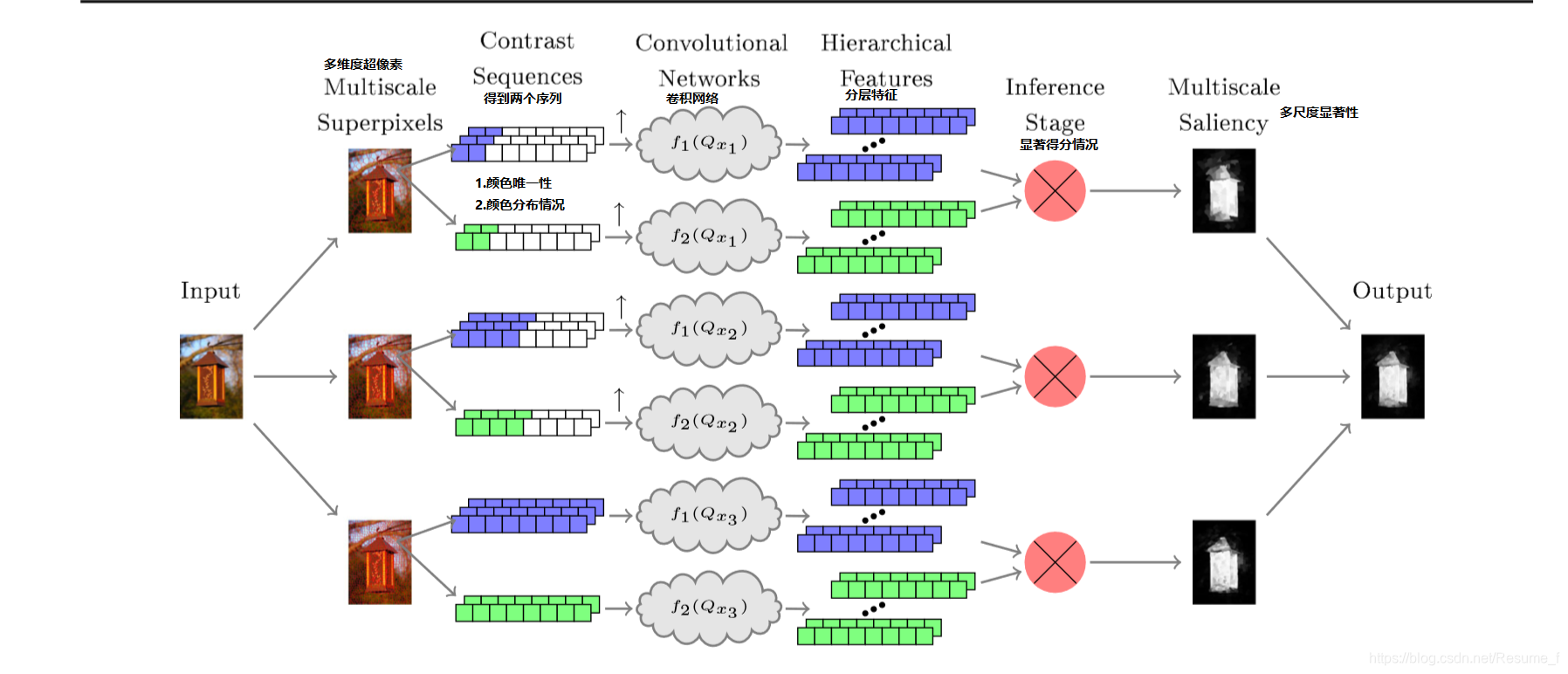
超像素卷积神经网络结构,有7层,可以说七个重要的结构,首先是将输入图像划分为多维度超像素网格区域(multiscale superpixels), 再提取出两个重要序列( Color Uniqueness Sequence 和 color distribution sequence), 分布描述颜色唯一性和颜色分布性 , 将两个序列送入卷积网络(convolutional network)中 , 得到图像的分层特征(hierarchical features) , 再采用argmax对每列进行二类分布预测 , 预测其显著性 , 最后得到输出图像。
下面对算法的具体流程进行梳理
颜色唯一性序列
颜色唯一性序列(Color Uniqueness Sequence )是用于描述某区域的颜色对比度。其数学公式为:

其中:

颜色分布序列
颜色分布序列(color distribution sequence)是对颜色唯一性的补充。它能够从背景上区分出前景物体,相对于前景的颜色更紧凑,而背景上的颜色通常在整个图像上广泛分布。其数学公式为:

其参数跟颜色唯一性序列相同 . 其中

卷积网络结构
SuperCNN具有多列可训练架构,每列提供1D序列。它是一个特征提取器,由序列层组成。其结构层次为:
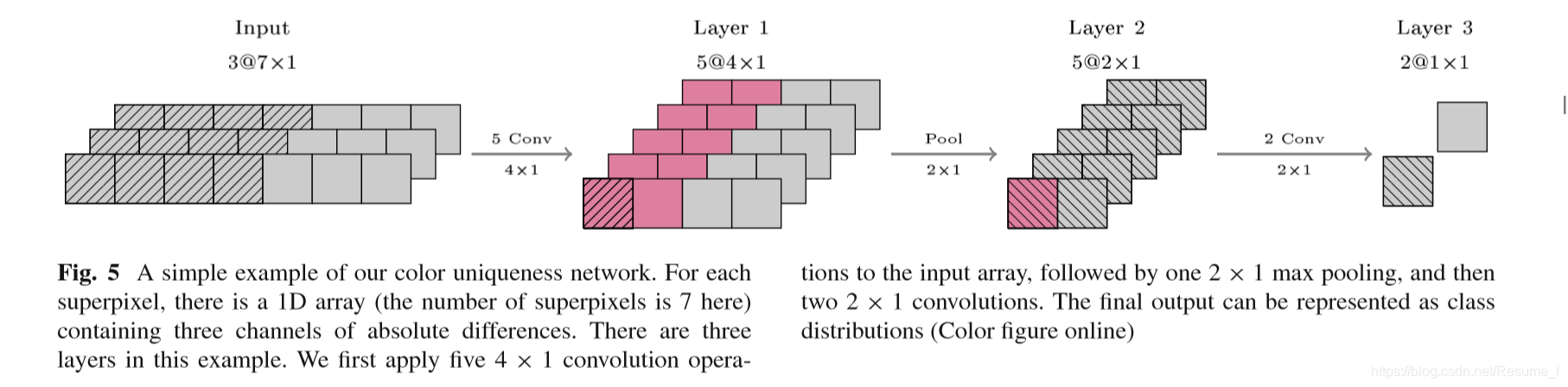
在卷积层中,有两个关键的运算属性:
- conv卷积运算:利用局部区域之间的空间相关性;
- maxpooling最大池运算:减少了计算复杂性并为微型转化(slight
translations)提供了不变性;
在convolutional network中 , fu层网络定义为:

其中权重Wu,l是连接l层和l-1层 , bu,l是偏置项。
最后 , 对于每一个特征图计算其显著性 , 适用softmax激活函数 , 将每层网络的得分转为区域显著性的标志值a , a的值在{0,1}之间,表明显著性的二值化值。

区域rx的类分布du,a由Fu通过两层神经网络预测得到的。
其损失函数为:
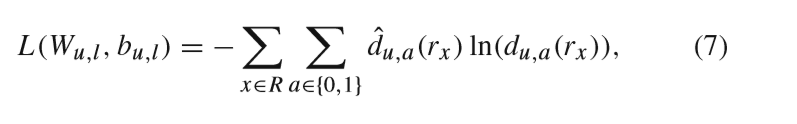
提取分层对比特征:
将分割的图像视为一维数组,并通过将空间内核( spatial kernel )引入颜色唯一性来恢复上下文信息, 除了空间信息之外,还通过颜色分布来区分显着对象。而区域内核( range kernel )被进一步应用于描述分布属性的属性对象。因此,产生了两个输入序列,并且将它们馈送到双列CNN中训练。
Saliency Inference
在Saliency Inference这一步中 , 为了确定区域的显着性,为了获取显著特征信息,采用argmax对网络中的每列进行二类分布预测 , 预测其显著性 。而表示区域rx中显著性的值被定义为:
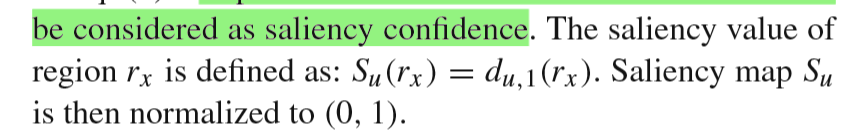
那么在整个特征图中,显著性的总值为:

文章3.3和3.4部分描述了网络的多方位结构以及减少过度配置的方案, 此处略研究
第四要点:研究方法
研究使用的数据集是MSRA-1000,该数据集为用于视觉显著性检测的MSRA-1000数据集(MSRA显著对象数据库)
对于SuperCNN算法的定性评估,文章采用了两个应用来说明,分别是图像大小调整(image resizing)和图像样式化(image stylization)
- image resizing : 是指经过检测出图像显著性物体之后,将显著物体放大,换句话说切割保留出显著物体的部分;
- image stylization : 是指经过检测出显著物体之后,将图像加强,从而起到强调场景中重要物体的作用;
第五要点:结论
文章最后得到结论:superCNN网络是一个通用显著性检测器,能适用各种场景的图像,克服了传统CNN不能用于对比信息提取和只能获取明显的特定类别的信息的问题。
文章提出的superCNN方法还是第一个使用CNN探索对比度信息的方法!
以上为个人对SuperCNN文献的理解,理解不到位,不足之处欢迎指出,本人虚心学习~~第一次写对英文文献的阅读笔记 , 终于完成了, 有点鸡冻, 上述内容纯粹个人理解 , 请多多包涵 ~
